Een Service Fabric-cluster beschrijven met behulp van Cluster Resource Manager
De functie Cluster Resource Manager van Azure Service Fabric biedt verschillende mechanismen voor het beschrijven van een cluster:
- Foutdomeinen
- Upgradedomeinen
- Knooppunteigenschappen
- Knooppuntcapaciteiten
Tijdens runtime gebruikt Cluster Resource Manager deze informatie om hoge beschikbaarheid te garanderen van de services die in het cluster worden uitgevoerd. Bij het afdwingen van deze belangrijke regels wordt ook geprobeerd om het resourceverbruik binnen het cluster te optimaliseren.
Foutdomeinen
Een foutdomein is een gebied van gecoördineerde fouten. Eén computer is een foutdomein. Het kan om verschillende redenen zelf mislukken, van stroomuitval tot stationsfouten tot slechte NIC-firmware.
Machines die zijn verbonden met dezelfde Ethernet-switch, bevinden zich in hetzelfde foutdomein. Dit zijn machines die één stroombron of op één locatie delen.
Omdat het natuurlijk is dat hardwarefouten elkaar overlappen, zijn foutdomeinen inherent hiërarchisch. Ze worden weergegeven als URI's in Service Fabric.
Het is belangrijk dat foutdomeinen correct zijn ingesteld omdat Service Fabric deze informatie gebruikt om services veilig te plaatsen. Service Fabric wil geen services plaatsen, zodat het verlies van een foutdomein (veroorzaakt door de fout van een onderdeel) ertoe leidt dat een service uitvalt.
In de Azure-omgeving gebruikt Service Fabric de foutdomeingegevens van de omgeving om de knooppunten in het cluster namens u correct te configureren. Voor zelfstandige exemplaren van Service Fabric worden foutdomeinen gedefinieerd op het moment dat het cluster is ingesteld.
Waarschuwing
Het is belangrijk dat de foutdomeingegevens die aan Service Fabric worden verstrekt, juist zijn. Stel dat de knooppunten van uw Service Fabric-cluster worden uitgevoerd binnen 10 virtuele machines, die worden uitgevoerd op 5 fysieke hosts. In dit geval zijn er 10 virtuele machines, maar er zijn slechts 5 verschillende foutdomeinen op het hoogste niveau. Het delen van dezelfde fysieke host zorgt ervoor dat VM's hetzelfde hoofdfoutdomein delen, omdat de VM's een gecoördineerde fout ervaren als de fysieke host mislukt.
Service Fabric verwacht dat het foutdomein van een knooppunt niet wordt gewijzigd. Andere mechanismen voor hoge beschikbaarheid van de VM's, zoals HA-VM's, kunnen conflicten veroorzaken met Service Fabric. Deze mechanismen maken gebruik van transparante migratie van VM's van de ene host naar de andere. Ze configureren de actieve code niet opnieuw of melden de actieve code in de virtuele machine. Daarom worden ze niet ondersteund als omgevingen voor het uitvoeren van Service Fabric-clusters.
Service Fabric moet de enige technologie voor hoge beschikbaarheid zijn die wordt gebruikt. Mechanismen zoals live-VM-migratie en SAN's zijn niet nodig. Als deze mechanismen worden gebruikt in combinatie met Service Fabric, verminderen ze de beschikbaarheid en betrouwbaarheid van toepassingen. De reden hiervoor is dat ze extra complexiteit introduceren, gecentraliseerde bronnen van fouten toevoegen en betrouwbaarheids- en beschikbaarheidsstrategieën gebruiken die conflicteren met die in Service Fabric.
In de volgende afbeelding kleuren we alle entiteiten die bijdragen aan foutdomeinen en geven we alle verschillende foutdomeinen weer die het resultaat zijn. In dit voorbeeld hebben we datacenters (DC), racks ('R') en blades ('B'). Als elke blade meer dan één virtuele machine bevat, is er mogelijk een andere laag in de foutdomeinhiërarchie.
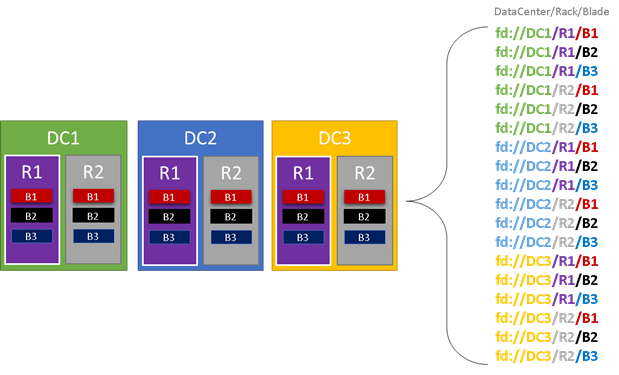
Tijdens runtime houdt Service Fabric-cluster Resource Manager rekening met de foutdomeinen in de indelingen van het cluster en plannen. De stateful replica's of stateless exemplaren voor een service worden gedistribueerd, zodat ze zich in afzonderlijke foutdomeinen bevinden. Het distribueren van de service tussen foutdomeinen zorgt ervoor dat de beschikbaarheid van de service niet wordt aangetast wanneer een foutdomein op een willekeurig niveau van de hiërarchie mislukt.
Cluster Resource Manager geeft niet aan hoeveel lagen er zijn in de foutdomeinhiërarchie. Er wordt geprobeerd ervoor te zorgen dat het verlies van één deel van de hiërarchie geen invloed heeft op services die erin worden uitgevoerd.
Het is het beste als hetzelfde aantal knooppunten zich op elk niveau van diepte in de foutdomeinhiërarchie bevindt. Als de 'structuur' van foutdomeinen niet in balans is in uw cluster, is het moeilijker voor Cluster Resource Manager om de beste toewijzing van services te achterhalen. Onevenwichtige foutdomeinindelingen betekenen dat het verlies van sommige domeinen de beschikbaarheid van services meer beïnvloedt dan andere domeinen. Als gevolg hiervan wordt Cluster Resource Manager gescheurd tussen twee doelen:
- Het wil de machines in dat 'zware' domein gebruiken door er services op te plaatsen.
- Het wil services in andere domeinen plaatsen, zodat het verlies van een domein geen problemen veroorzaakt.
Hoe zien onevenwichtige domeinen eruit? In het volgende diagram ziet u twee verschillende clusterindelingen. In het eerste voorbeeld worden de knooppunten gelijkmatig verdeeld over de foutdomeinen. In het tweede voorbeeld heeft één foutdomein veel meer knooppunten dan de andere foutdomeinen.
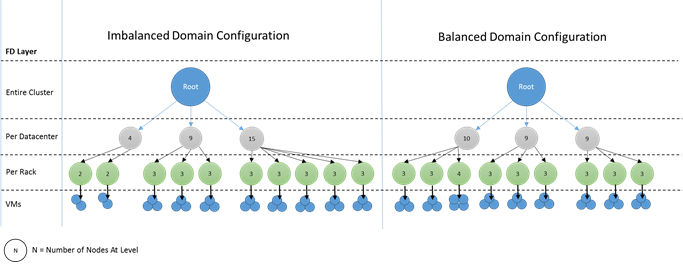
In Azure wordt de keuze van welk foutdomein een knooppunt bevat voor u beheerd. Afhankelijk van het aantal knooppunten dat u inricht, kunt u echter nog steeds foutdomeinen krijgen met meer knooppunten dan in andere knooppunten.
Stel dat u vijf foutdomeinen in het cluster hebt, maar zeven knooppunten inricht voor een knooppunttype (NodeType). In dit geval eindigen de eerste twee foutdomeinen met meer knooppunten. Als u meer NodeType-exemplaren met slechts een aantal exemplaren implementeert, wordt het probleem erger. Daarom raden we aan dat het aantal knooppunten in elk knooppunttype een veelvoud is van het aantal foutdomeinen.
Upgradedomeinen
Upgradedomeinen zijn een andere functie waarmee Service Fabric-clusterbronbeheer inzicht krijgt in de indeling van het cluster. Upgradedomeinen definiëren sets knooppunten die tegelijkertijd worden bijgewerkt. Upgradedomeinen helpen Cluster Resource Manager beheerbewerkingen te begrijpen en te organiseren, zoals upgrades.
Upgradedomeinen zijn veel vergelijkbaar met foutdomeinen, maar met een aantal belangrijke verschillen. Ten eerste definiëren gebieden van gecoördineerde hardwarefouten foutdomeinen. Upgradedomeinen worden daarentegen gedefinieerd door beleid. U kunt bepalen hoeveel u wilt, in plaats van de omgeving het nummer te laten dicteren. U kunt net zoveel upgradedomeinen hebben als knooppunten. Een ander verschil tussen foutdomeinen en upgradedomeinen is dat upgradedomeinen niet hiërarchisch zijn. In plaats daarvan zijn ze meer een eenvoudige tag.
In het volgende diagram ziet u drie upgradedomeinen die zijn gestreept over drie foutdomeinen. Er wordt ook één mogelijke plaatsing weergegeven voor drie verschillende replica's van een stateful service, waarbij elk in verschillende fout- en upgradedomeinen terechtkomt. Met deze plaatsing kan een foutdomein verloren gaan tijdens een service-upgrade en nog steeds één kopie van de code en gegevens hebben.
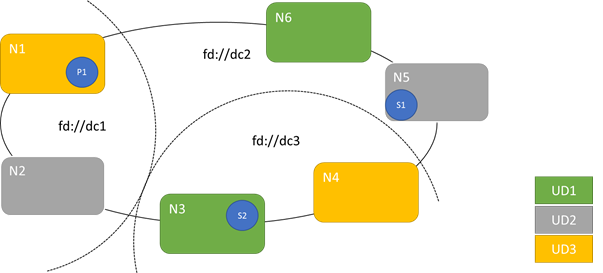
Er zijn voor- en nadelen voor het hebben van grote aantallen upgradedomeinen. Meer upgradedomeinen betekenen dat elke stap van de upgrade gedetailleerder is en van invloed is op een kleiner aantal knooppunten of services. Minder services moeten tegelijk worden verplaatst, waardoor er minder verloop in het systeem wordt ingevoerd. Dit heeft de neiging om de betrouwbaarheid te verbeteren, omdat minder van de service wordt beïnvloed door elk probleem dat tijdens de upgrade wordt geïntroduceerd. Meer upgradedomeinen betekenen ook dat u minder beschikbare buffer nodig hebt op andere knooppunten om de impact van de upgrade af te handelen.
Als u bijvoorbeeld vijf upgradedomeinen hebt, verwerken de knooppunten in elk domein ongeveer 20 procent van uw verkeer. Als u dat upgradedomein moet uitschakelen voor een upgrade, moet de belasting meestal ergens heen. Omdat u vier resterende upgradedomeinen hebt, moet elk ongeveer 25 procent van het totale verkeer ruimte hebben. Meer upgradedomeinen betekenen dat u minder buffer nodig hebt op de knooppunten in het cluster.
Overweeg of u in plaats daarvan 10 upgradedomeinen hebt. In dat geval zou elk upgradedomein slechts ongeveer 10 procent van het totale verkeer verwerken. Wanneer een upgrade door het cluster wordt uitgevoerd, moet elk domein slechts ongeveer 11 procent van het totale verkeer ruimte hebben. Met meer upgradedomeinen kunt u over het algemeen uw knooppunten met een hoger gebruik uitvoeren, omdat u minder gereserveerde capaciteit nodig hebt. Hetzelfde geldt voor foutdomeinen.
Het nadeel van het hebben van veel upgradedomeinen is dat upgrades meestal langer duren. Service Fabric wacht een korte periode nadat een upgradedomein is voltooid en voert controles uit voordat de volgende wordt bijgewerkt. Deze vertragingen maken het detecteren van problemen mogelijk die door de upgrade zijn geïntroduceerd voordat de upgrade wordt voortgezet. Het compromis is acceptabel omdat slechte wijzigingen niet van invloed zijn op te veel van de service tegelijk.
De aanwezigheid van te weinig upgradedomeinen heeft veel negatieve bijwerkingen. Hoewel elk upgradedomein uitvalt en wordt bijgewerkt, is een groot deel van uw totale capaciteit niet beschikbaar. Als u bijvoorbeeld slechts drie upgradedomeinen hebt, neemt u ongeveer een derde van uw totale service- of clustercapaciteit tegelijk uit. Het is niet wenselijk om zoveel van uw service tegelijk uit te voeren, omdat u voldoende capaciteit nodig hebt in de rest van uw cluster om de werkbelasting te verwerken. Het onderhouden van die buffer betekent dat deze knooppunten tijdens de normale werking minder worden geladen dan anders. Hierdoor worden de kosten voor het uitvoeren van uw service verhoogd.
Er is geen echte limiet voor het totale aantal fout- of upgradedomeinen in een omgeving, of beperkingen voor hoe ze overlappen. Maar er zijn veelvoorkomende patronen:
- Foutdomeinen en upgradedomeinen toegewezen 1:1
- Eén upgradedomein per knooppunt (fysiek of virtueel besturingssysteemexemplaren)
- Een 'striped' of 'matrix'-model waarbij de foutdomeinen en upgradedomeinen een matrix vormen met machines die meestal onder de diagonalen worden uitgevoerd
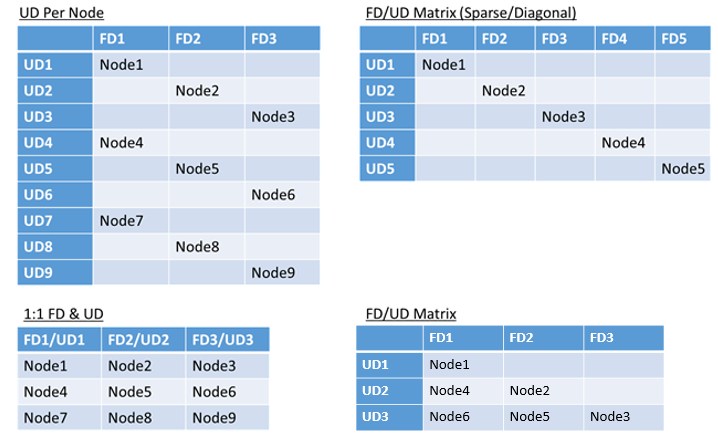
Er is geen beste antwoord voor welke indeling u moet kiezen. Elk heeft voor- en nadelen. Het 1FD:1UD-model is bijvoorbeeld eenvoudig in te stellen. Het model van één upgradedomein per knooppuntmodel is het meest vergelijkbaar met wat mensen worden gebruikt. Tijdens upgrades wordt elk knooppunt onafhankelijk bijgewerkt. Dit is vergelijkbaar met hoe kleine sets machines in het verleden handmatig zijn bijgewerkt.
Het meest voorkomende model is de FD/UD-matrix, waarbij de foutdomeinen en upgradedomeinen een tabel en knooppunten vormen die langs de diagonale worden geplaatst. Dit is het model dat standaard wordt gebruikt in Service Fabric-clusters in Azure. Voor clusters met veel knooppunten ziet alles eruit als een dicht matrixpatroon.
Notitie
Service Fabric-clusters die worden gehost in Azure bieden geen ondersteuning voor het wijzigen van de standaardstrategie. Alleen zelfstandige clusters bieden die aanpassing.
Fout- en upgradedomeinbeperkingen en resulterend gedrag
Standaardbenadering
Standaard houdt Cluster Resource Manager services verdeeld over fout- en upgradedomeinen. Dit is gemodelleerd als een beperking. De beperking voor fout- en upgradedomeinen geeft aan: 'Voor een bepaalde servicepartitie mag er nooit een verschil groter zijn dan één in het aantal serviceobjecten (stateless service-exemplaren of stateful servicereplica's) tussen twee domeinen op hetzelfde niveau van de hiërarchie.
Stel dat deze beperking een garantie voor 'maximumverschil' biedt. De beperking voor fout- en upgradedomeinen voorkomt bepaalde verplaatsingen of regelingen die de regel schenden.
Stel dat we een cluster hebben met zes knooppunten, geconfigureerd met vijf foutdomeinen en vijf upgradedomeinen.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Stel nu dat we een service maken met een TargetReplicaSetSize -waarde (of, voor een stateless service, InstanceCount) van vijf. De replica's landen op N1-N5. N6 wordt zelfs nooit gebruikt, ongeacht hoeveel services u maakt. Maar waarom? Laten we eens kijken naar het verschil tussen de huidige indeling en wat er zou gebeuren als N6 wordt gekozen.
Dit is de indeling die we hebben en het totale aantal replica's per fout en upgradedomein:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Deze indeling wordt verdeeld in termen van knooppunten per foutdomein en upgradedomein. Het is ook evenwichtig in termen van het aantal replica's per fout en upgradedomein. Elk domein heeft hetzelfde aantal knooppunten en hetzelfde aantal replica's.
Laten we eens kijken wat er zou gebeuren als we N6 zouden gebruiken in plaats van N2. Hoe zouden de replica's dan worden gedistribueerd?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Deze indeling schendt onze definitie van de garantie voor het maximale verschil voor de beperking van het foutdomein. FD0 heeft twee replica's, terwijl FD1 nul heeft. Het verschil tussen FD0 en FD1 is in totaal twee, wat groter is dan het maximumverschil van één. Omdat de beperking wordt geschonden, staat Cluster Resource Manager deze rangschikking niet toe.
Als we ook N2 en N6 hebben gekozen (in plaats van N1 en N2), krijgen we het volgende:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Deze indeling is evenwichtig in termen van foutdomeinen. Maar nu schendt het de beperking van het upgradedomein, omdat UD0 nul replica's heeft en UD1 twee heeft. Deze indeling is ook ongeldig en wordt niet gekozen door Cluster Resource Manager.
Deze benadering voor de distributie van stateful replica's of stateless exemplaren biedt de best mogelijke fouttolerantie. Als één domein uitvalt, gaat het minimale aantal replica's/exemplaren verloren.
Aan de andere kant kan deze benadering te strikt zijn en mag het cluster niet alle resources gebruiken. Voor bepaalde clusterconfiguraties kunnen bepaalde knooppunten niet worden gebruikt. Dit kan ertoe leiden dat Service Fabric uw services niet plaatst, wat resulteert in waarschuwingsberichten. In het vorige voorbeeld kunnen sommige clusterknooppunten niet worden gebruikt (N6 in het voorbeeld). Zelfs als u knooppunten aan dat cluster (N7-N10) hebt toegevoegd, worden replica's/exemplaren alleen op N1-N5 geplaatst vanwege beperkingen voor fout- en upgradedomeinen.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Alternatieve benadering
Cluster Resource Manager ondersteunt een andere versie van de beperking voor fout- en upgradedomeinen. Het maakt plaatsing mogelijk en garandeert nog steeds een minimumniveau van veiligheid. De alternatieve beperking kan als volgt worden aangegeven: 'Voor een bepaalde servicepartitie moet replicadistributie tussen domeinen ervoor zorgen dat de partitie geen quorumverlies ondervindt.' Stel dat deze beperking een garantie 'quorumveilig' biedt.
Notitie
Voor een stateful service definiëren we quorumverlies in een situatie waarin een meerderheid van de partitiereplica's tegelijkertijd uitvalt. Als TargetReplicaSetSize bijvoorbeeld vijf is, vertegenwoordigt een set van drie replica's quorum. Als TargetReplicaSetSize zes is, zijn vier replica's nodig voor quorum. In beide gevallen kunnen niet meer dan twee replica's tegelijkertijd offline zijn als de partitie normaal wil blijven functioneren.
Voor een staatloze service is er geen sprake van quorumverlies. Staatloze services blijven normaal functioneren, zelfs als een meerderheid van de exemplaren tegelijkertijd uitvalt. Daarom richten we ons op stateful services in de rest van dit artikel.
Laten we teruggaan naar het vorige voorbeeld. Met de quorumveilige versie van de beperking zijn alle drie de indelingen geldig. Zelfs als FD0 is mislukt in de tweede indeling of UD1 is mislukt in de derde indeling, zou de partitie nog steeds quorum hebben. (Een meerderheid van de replica's is nog steeds op.) Met deze versie van de beperking kan N6 bijna altijd worden gebruikt.
De benadering 'quorum veilig' biedt meer flexibiliteit dan de 'maximale verschil'-benadering. De reden hiervoor is dat het eenvoudiger is om replicadistributies te vinden die geldig zijn in vrijwel elke clustertopologie. Deze aanpak kan echter niet de beste fouttolerantiekenmerken garanderen, omdat sommige fouten slechter zijn dan andere.
In het ergste geval kan een meerderheid van de replica's verloren gaan met de fout van één domein en één extra replica. In plaats van drie fouten die nodig zijn om quorum met vijf replica's of exemplaren te verliezen, kunt u nu een meerderheid met slechts twee fouten verliezen.
Adaptieve benadering
Omdat beide benaderingen sterke en zwakke punten hebben, hebben we een adaptieve benadering geïntroduceerd die deze twee strategieën combineert.
Notitie
Dit is het standaardgedrag dat begint met Service Fabric versie 6.2.
De adaptieve benadering maakt standaard gebruik van de logica 'maximumverschil' en schakelt alleen over naar de logica 'quorum veilig' wanneer dat nodig is. Cluster Resource Manager bepaalt automatisch welke strategie nodig is door te kijken hoe het cluster en de services zijn geconfigureerd.
ClusterBron Manager moet de logica 'op basis van quorum' gebruiken voor een service die aan beide voorwaarden voldoet:
- TargetReplicaSetSize voor de service is gelijkmatig deelbaar door het aantal foutdomeinen en het aantal upgradedomeinen.
- Het aantal knooppunten is kleiner dan of gelijk aan het aantal foutdomeinen vermenigvuldigd met het aantal upgradedomeinen.
Houd er rekening mee dat Cluster Resource Manager deze benadering gebruikt voor staatloze en stateful services, ook al is quorumverlies niet relevant voor staatloze services.
We gaan terug naar het vorige voorbeeld en gaan ervan uit dat een cluster nu acht knooppunten heeft. Het cluster is nog steeds geconfigureerd met vijf foutdomeinen en vijf upgradedomeinen, en de TargetReplicaSetSize-waarde van een service die op dat cluster wordt gehost, blijft vijf.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Omdat aan alle vereiste voorwaarden wordt voldaan, gebruikt Cluster Resource Manager de logica op basis van quorum bij het distribueren van de service. Dit maakt het gebruik van N6-N8 mogelijk. Een mogelijke servicedistributie in dit geval kan er als volgt uitzien:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 0 | 1 | - |
Als de TargetReplicaSetSize-waarde van uw service wordt teruggebracht tot vier (bijvoorbeeld), ziet Cluster Resource Manager die wijziging. Deze wordt hervat met behulp van de logica 'maximumverschil', omdat TargetReplicaSetSize niet meer kan worden gedeeld door het aantal foutdomeinen en upgradedomeinen. Als gevolg hiervan treden bepaalde replicaverplaatsingen op om de resterende vier replica's te distribueren op knooppunten N1-N5. Op die manier wordt de 'maximale verschil'-versie van het foutdomein en de upgradedomeinlogica niet geschonden.
Als in de vorige indeling de waarde TargetReplicaSetSize vijf is en N1 uit het cluster wordt verwijderd, wordt het aantal upgradedomeinen gelijk aan vier. Cluster Resource Manager gaat opnieuw de logica 'maximumverschil' gebruiken omdat het aantal upgradedomeinen de TargetReplicaSetSize-waarde van de service niet gelijkmatig deelt. Als gevolg hiervan moet replica R1, wanneer deze opnieuw is gebouwd, op N4 terechtkomen, zodat de beperking voor de fout en het upgradedomein niet wordt geschonden.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | N.v.t. | N.v.t. | N.v.t. | N.v.t. | N.v.t. | N.v.t. |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Fout- en upgradedomeinen configureren
In door Azure gehoste Service Fabric-implementaties worden foutdomeinen en upgradedomeinen automatisch gedefinieerd. Service Fabric haalt de omgevingsgegevens van Azure op en gebruikt deze.
Als u uw eigen cluster maakt (of een bepaalde topologie in ontwikkeling wilt uitvoeren), kunt u zelf het foutdomein opgeven en domeingegevens bijwerken. In dit voorbeeld definiëren we een lokaal ontwikkelingscluster met negen knooppunten dat drie datacenters omvat (elk met drie racks). Dit cluster heeft ook drie upgradedomeinen die zijn gestreept in deze drie datacenters. Hier volgt een voorbeeld van de configuratie in ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
In dit voorbeeld wordt ClusterConfig.json gebruikt voor zelfstandige implementaties:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Notitie
Wanneer u clusters definieert via Azure Resource Manager, wijst Azure foutdomeinen en upgradedomeinen toe. De definitie van uw knooppunttypen en virtuele-machineschaalsets in uw Azure Resource Manager-sjabloon bevat dus geen informatie over foutdomein of upgradedomein.
Knooppunteigenschappen en plaatsingsbeperkingen
Soms (in feite, meestal) wilt u ervoor zorgen dat bepaalde workloads alleen worden uitgevoerd op bepaalde typen knooppunten in het cluster. Voor sommige workloads zijn bijvoorbeeld GPU's of HD's vereist, en andere mogelijk niet.
Een goed voorbeeld van het richten van hardware op bepaalde workloads is bijna elke n-laag-architectuur. Bepaalde machines fungeren als de front-end- of API-kant van de toepassing en worden blootgesteld aan de clients of internet. Verschillende machines, vaak met verschillende hardwareresources, verwerken het werk van de reken- of opslaglagen. Deze worden meestal niet rechtstreeks blootgesteld aan clients of internet.
Service Fabric verwacht dat in sommige gevallen bepaalde workloads mogelijk moeten worden uitgevoerd op bepaalde hardwareconfiguraties. Voorbeeld:
- Een bestaande n-tier-toepassing is 'opgeheven en verplaatst' naar een Service Fabric-omgeving.
- Een workload moet worden uitgevoerd op specifieke hardware om redenen van prestatie-, schaal- of beveiligingsisolatie.
- Een workload moet worden geïsoleerd van andere workloads om redenen van beleid of resourceverbruik.
Om dit soort configuraties te ondersteunen, bevat Service Fabric tags die u op knooppunten kunt toepassen. Deze tags worden knooppunteigenschappen genoemd. Plaatsingsbeperkingen zijn de instructies die zijn gekoppeld aan afzonderlijke services die u selecteert voor een of meer knooppunteigenschappen. Plaatsingsbeperkingen bepalen waar services moeten worden uitgevoerd. De set beperkingen kan worden uitgebreid. Elk sleutel-waardepaar kan werken.
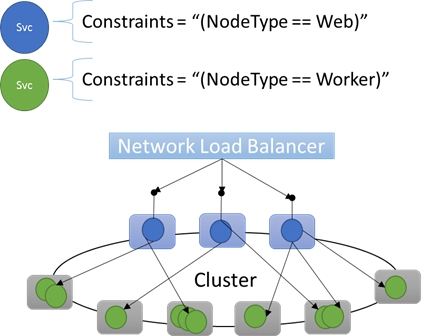
Ingebouwde knooppunteigenschappen
Service Fabric definieert enkele standaardknooppunteigenschappen die automatisch kunnen worden gebruikt, zodat u deze niet hoeft te definiëren. De standaardeigenschappen die op elk knooppunt zijn gedefinieerd, zijn NodeType en NodeName.
U kunt bijvoorbeeld een plaatsingsbeperking schrijven als "(NodeType == NodeType03)". NodeType is een veelgebruikte eigenschap. Het is handig omdat het overeenkomt met 1:1 met een type machine. Elk type machine komt overeen met een type workload in een traditionele n-tier-toepassing.
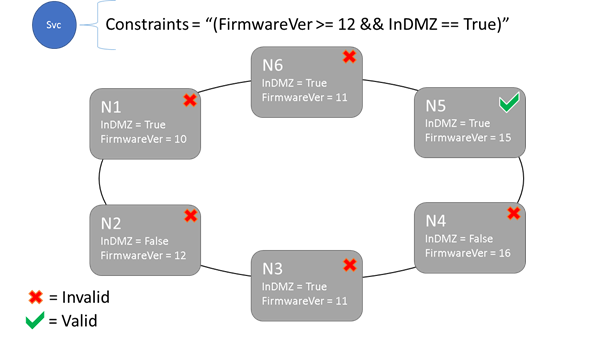
Plaatsingsbeperkingen en syntaxis van knooppunteigenschap
De waarde die is opgegeven in de knooppunteigenschap kan een tekenreeks, Booleaanse waarde of een teken lang zijn. De instructie bij de service wordt een plaatsingsbeperking genoemd omdat deze beperking beperkt tot waar de service in het cluster kan worden uitgevoerd. De beperking kan elke Boole-instructie zijn die werkt op de knooppunteigenschappen in het cluster. De geldige selectors in deze Boole-instructies zijn:
Voorwaardelijke controles voor het maken van bepaalde instructies:
Instructie Syntaxis "gelijk aan" "==" "niet gelijk aan" "!=" "groter dan" ">" "groter dan of gelijk aan" ">=" "kleiner dan" "<" "kleiner dan of gelijk aan" "<=" Booleaanse instructies voor groepering en logische bewerkingen:
Instructie Syntaxis "en" "&&" "or" "||" "niet" "!" "groeperen als één instructie" "()"
Hier volgen enkele voorbeelden van eenvoudige beperkingsinstructies:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Alleen knooppunten waarop de algemene instructie voor plaatsingsbeperkingen resulteert in Waar, kan de service erop worden geplaatst. Knooppunten waarvoor geen eigenschap is gedefinieerd, komen niet overeen met een plaatsingsbeperking die de eigenschap bevat.
Stel dat de volgende knooppunteigenschappen zijn gedefinieerd voor een knooppunttype in ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
In het volgende voorbeeld ziet u knooppunteigenschappen die zijn gedefinieerd via ClusterConfig.json voor zelfstandige implementaties of Template.json voor door Azure gehoste clusters.
Notitie
In uw Azure Resource Manager-sjabloon wordt het knooppunttype meestal geparameteriseerd. Het ziet eruit in plaats van "[parameters('vmNodeType1Name')]" NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
U kunt als volgt beperkingen voor serviceplaatsing voor een service maken:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Als alle knooppunten van NodeType01 geldig zijn, kunt u dat knooppunttype ook selecteren met de beperking "(NodeType == NodeType01)".
De plaatsingsbeperkingen van een service kunnen dynamisch worden bijgewerkt tijdens runtime. Als dat nodig is, kunt u een service verplaatsen in het cluster, vereisten toevoegen en verwijderen, enzovoort. Service Fabric zorgt ervoor dat de service up-and-available blijft, zelfs wanneer deze typen wijzigingen worden aangebracht.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Plaatsingsbeperkingen worden opgegeven voor elk benoemd service-exemplaar. Updates vinden altijd plaats van (overschrijven) wat eerder is opgegeven.
De clusterdefinitie definieert de eigenschappen op een knooppunt. Voor het wijzigen van de eigenschappen van een knooppunt is een upgrade naar de clusterconfiguratie vereist. Voor het upgraden van de eigenschappen van een knooppunt moet elk betrokken knooppunt opnieuw worden opgestart om de nieuwe eigenschappen te rapporteren. Service Fabric beheert deze rolling upgrades.
Clusterresources beschrijven en beheren
Een van de belangrijkste taken van elke orchestrator is om het resourceverbruik in het cluster te beheren. Het beheren van clusterresources kan een aantal verschillende dingen betekenen.
Ten eerste zorgt u ervoor dat machines niet overbelast zijn. Dit betekent dat machines niet meer services uitvoeren dan ze kunnen verwerken.
Ten tweede is er balans en optimalisatie, die essentieel zijn voor het efficiënt uitvoeren van services. Kosteneffectieve of prestatiegevoelige serviceaanbiedingen kunnen niet toestaan dat sommige knooppunten hot zijn terwijl andere koud zijn. Hot-knooppunten leiden tot conflicten tussen resources en slechte prestaties. Koude knooppunten vertegenwoordigen verspilde resources en verhoogde kosten.
Service Fabric vertegenwoordigt resources als metrische gegevens. Metrische gegevens zijn een logische of fysieke resource die u wilt beschrijven voor Service Fabric. Voorbeelden van metrische gegevens zijn WorkQueueDepth of MemoryInMb. Zie Resourcebeheer voor informatie over de fysieke resources die Service Fabric op knooppunten kan beheren. Zie dit artikel voor informatie over de standaard metrische gegevens die worden gebruikt door Cluster Resource Manager en het configureren van aangepaste metrische gegevens.
Metrische gegevens verschillen van plaatsingsbeperkingen en knooppunteigenschappen. Knooppunteigenschappen zijn statische descriptors van de knooppunten zelf. Metrische gegevens beschrijven resources die knooppunten hebben en die services verbruiken wanneer ze worden uitgevoerd op een knooppunt. Een knooppunteigenschap kan HasSSD zijn en kan worden ingesteld op waar of onwaar. De hoeveelheid ruimte die beschikbaar is op die SSD en hoeveel wordt verbruikt door services, is een metrische waarde zoals 'DriveSpaceInMb'.
Net als bij plaatsingsbeperkingen en knooppunteigenschappen begrijpt Service Fabric Cluster Resource Manager niet wat de namen van de metrische gegevens betekenen. Namen van metrische gegevens zijn alleen tekenreeksen. Het is een goede gewoonte om eenheden te declareren als onderdeel van de metrische namen die u maakt wanneer ze mogelijk niet eenduidig zijn.
Capaciteit
Als u alle resourceverdeling hebt uitgeschakeld, zorgt Service Fabric Cluster Resource Manager er nog steeds voor dat er geen knooppunt over de capaciteit gaat. Het beheren van capaciteitsoverschrijdingen is mogelijk, tenzij het cluster te vol is of de werkbelasting groter is dan elk knooppunt. Capaciteit is een andere beperking die Cluster Resource Manager gebruikt om te begrijpen hoeveel van een resource een knooppunt heeft. De resterende capaciteit wordt ook bijgehouden voor het cluster als geheel.
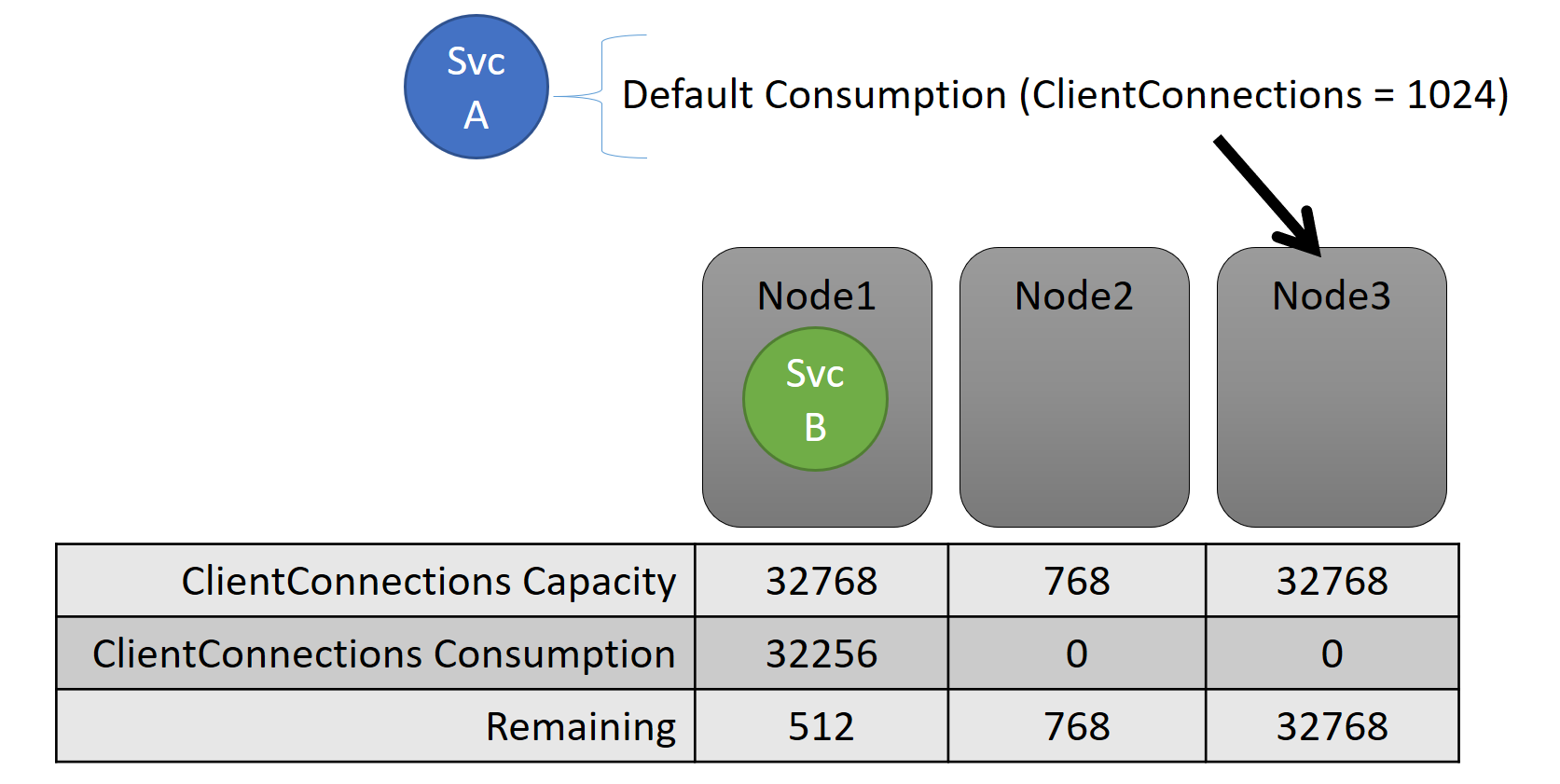
Zowel de capaciteit als het verbruik op serviceniveau worden uitgedrukt in metrische gegevens. De metrische waarde kan bijvoorbeeld 'ClientConnections' zijn en een knooppunt kan een capaciteit hebben voor 'ClientConnections' van 32.768. Andere knooppunten kunnen andere limieten hebben. Een service die op dat knooppunt wordt uitgevoerd, kan zeggen dat het momenteel 32.256 van de metrische waarde ClientConnections verbruikt.
Tijdens runtime houdt Cluster Resource Manager de resterende capaciteit in het cluster en op knooppunten bij. Als u capaciteit wilt bijhouden, trekt Cluster Resource Manager het gebruik van elke service af van de capaciteit van een knooppunt waarop de service wordt uitgevoerd. Met deze informatie kan Cluster Resource Manager bepalen waar replica's moeten worden opgeslagen of verplaatst, zodat knooppunten geen capaciteit overslaan.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
U kunt capaciteiten zien die zijn gedefinieerd in het clustermanifest. Hier volgt een voorbeeld voor ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Hier volgt een voorbeeld van capaciteiten die zijn gedefinieerd via ClusterConfig.json voor zelfstandige implementaties of Template.json voor door Azure gehoste clusters:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
De belasting van een service verandert vaak dynamisch. Stel dat de belasting van een replica van ClientConnections is gewijzigd van 1024 in 2048. Het knooppunt waarop het werd uitgevoerd, had vervolgens slechts 512 resterende capaciteit voor die metrische waarde. Nu de plaatsing van de replica of het exemplaar ongeldig is, omdat er onvoldoende ruimte is op dat knooppunt. Cluster Resource Manager moet het knooppunt weer onder de capaciteit krijgen. Dit vermindert de belasting van het knooppunt dat de capaciteit heeft door een of meer replica's of exemplaren van dat knooppunt naar andere knooppunten te verplaatsen.
Cluster Resource Manager probeert de kosten van het verplaatsen van replica's te minimaliseren. Meer informatie over verplaatsingskosten en over herverdelingsstrategieën en -regels.
Clustercapaciteit
Hoe zorgt de Resource Manager van het Service Fabric-cluster ervoor dat het hele cluster niet te vol is? Met dynamische belasting is er niet veel te doen. Services kunnen hun belastingpieken onafhankelijk van de acties die Cluster Resource Manager uitvoert, hebben. Als gevolg hiervan is uw cluster met veel hoofdruimte vandaag mogelijk onderkracht als er morgen een piek is.
Besturingselementen in Cluster Resource Manager helpen problemen te voorkomen. Het eerste wat u kunt doen, is voorkomen dat er nieuwe workloads worden gemaakt waardoor het cluster vol raakt.
Stel dat u een staatloze service maakt en dat er enige belasting aan is gekoppeld. De service geeft om de metrische gegevens 'DiskSpaceInMb'. De service verbruikt vijf eenheden van 'DiskSpaceInMb' voor elk exemplaar van de service. U wilt drie exemplaren van de service maken. Dit betekent dat u 15 eenheden van DiskSpaceInMb nodig hebt om aanwezig te zijn in het cluster, zodat u zelfs deze service-exemplaren kunt maken.
Cluster Resource Manager berekent voortdurend de capaciteit en het verbruik van elke metrische waarde, zodat deze de resterende capaciteit in het cluster kan bepalen. Als er onvoldoende ruimte is, weigert Cluster Resource Manager de aanroep om een service te maken.
Omdat de vereiste slechts 15 eenheden beschikbaar is, kunt u deze ruimte op veel verschillende manieren toewijzen. Er kan bijvoorbeeld één resterende capaciteitseenheid zijn op 15 verschillende knooppunten of drie resterende capaciteitseenheden op vijf verschillende knooppunten. Als Cluster Resource Manager dingen opnieuw kan rangschiken, zodat er vijf eenheden beschikbaar zijn op drie knooppunten, wordt de service op de service geïnstalleerd. Het opnieuw rangschikken van het cluster is meestal mogelijk, tenzij het cluster bijna vol is of de bestaande services om een of andere reden niet kunnen worden geconsolideerd.
Knooppuntbuffer- en overboekingscapaciteit
Als een knooppuntcapaciteit voor een metrische waarde is opgegeven, plaatst Cluster Resource Manager nooit replica's op een knooppunt als de totale belasting boven de opgegeven knooppuntcapaciteit zou gaan. Dit kan soms voorkomen dat nieuwe replica's worden geplaatst of mislukte replica's worden vervangen als het cluster bijna vol is en een replica met een grote belasting moet worden geplaatst, vervangen of verplaatst.
Als u meer flexibiliteit wilt bieden, kunt u knooppuntbuffer- of overboekingscapaciteit opgeven. Wanneer knooppuntbuffer- of overboekingscapaciteit is opgegeven voor een metrische waarde, probeert Cluster Resource Manager replica's zodanig te plaatsen of te verplaatsen dat de buffer- of overboekingscapaciteit ongebruikt blijft, maar kan de buffer- of overboekingscapaciteit indien nodig worden gebruikt voor acties die de beschikbaarheid van de service vergroten, zoals:
- Nieuwe replicaplaatsing of vervanging van mislukte replica's
- Plaatsing tijdens upgrades
- Het oplossen van schendingen van zachte en harde beperkingen
- Defragmentatie
Knooppuntbuffercapaciteit vertegenwoordigt een gereserveerd gedeelte van de capaciteit onder de opgegeven knooppuntcapaciteit en overboekingscapaciteit vertegenwoordigt een deel van de extra capaciteit boven de opgegeven knooppuntcapaciteit. In beide gevallen probeert Cluster Resource Manager deze capaciteit vrij te houden.
Als een knooppunt bijvoorbeeld een opgegeven capaciteit heeft voor het metrische CpuU-gebruik van 100 en het knooppuntbufferpercentage voor die metrische waarde is ingesteld op 20%, zijn de totale en niet-gebufferde capaciteiten respectievelijk 100 en 80 en de Cluster Resource Manager niet meer dan 80 eenheden van belasting op het knooppunt in normale omstandigheden.

De knooppuntbuffer moet worden gebruikt wanneer u een deel van de knooppuntcapaciteit wilt reserveren dat alleen wordt gebruikt voor acties die de beschikbaarheid van de service verhogen die hierboven worden vermeld.
Als daarentegen het knooppuntoverschrijdingspercentage wordt gebruikt en op 20% wordt ingesteld, zijn de totale en niet-gebufferde capaciteiten respectievelijk 120 en 100.
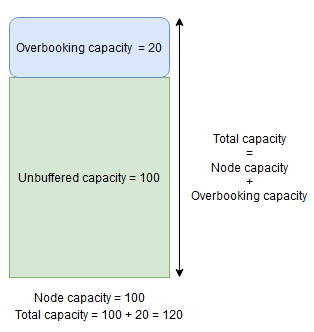
Overboekingscapaciteit moet worden gebruikt wanneer u clusterbronbeheer wilt toestaan om replica's op een knooppunt te plaatsen, zelfs als het totale resourcegebruik de capaciteit zou overschrijden. Dit kan worden gebruikt om extra beschikbaarheid te bieden voor services ten koste van prestaties. Als overboeking wordt gebruikt, moet de logica van gebruikerstoepassingen kunnen functioneren met minder fysieke resources dan nodig is.
Als knooppuntbuffer- of overboekingscapaciteiten zijn opgegeven, worden in Cluster Resource Manager geen replica's verplaatst of geplaatst als de totale belasting op het doelknooppunt de totale capaciteit overneemt (knooppuntcapaciteit in geval van knooppuntbuffer en knooppuntcapaciteit + overboekingscapaciteit in geval van overboeking).
Overboekingscapaciteit kan ook worden opgegeven om oneindig te zijn. In dit geval probeert Cluster Resource Manager de totale belasting op het knooppunt onder de opgegeven knooppuntcapaciteit te houden, maar is het mogelijk toegestaan om een veel grotere belasting op het knooppunt te plaatsen, wat kan leiden tot ernstige prestatievermindering.
Een metrische waarde kan niet zowel knooppuntbuffer- als overboekingscapaciteit hebben opgegeven op hetzelfde moment.
Hier volgt een voorbeeld van het opgeven van knooppuntbuffer- of overboekingscapaciteiten in ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Hier volgt een voorbeeld van het opgeven van knooppuntbuffer- of overboekingscapaciteiten via ClusterConfig.json voor zelfstandige implementaties of Template.json voor door Azure gehoste clusters:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Volgende stappen
- Zie het overzicht van de architectuur en informatiestroom in Cluster Resource Manager voor meer informatie over de architectuur en informatiestroom in Cluster Resource Manager.
- Het definiëren van metrische gegevens over de fragmentatie is een manier om de belasting van knooppunten samen te voegen in plaats van deze uit te spreiden. Zie Defragmentatie van metrische gegevens en belasting in Service Fabric voor meer informatie over het configureren van de fragmentatie.
- Begin vanaf het begin en krijg een inleiding tot Service Fabric Cluster Resource Manager.
- Zie Taakverdeling van uw Service Fabric-cluster voor meer informatie over hoe Cluster Resource Manager de belasting in het cluster beheert en verdeelt.