Inleiding tot de statuscontrole Service Fabric
Azure Service Fabric introduceert een statusmodel dat uitgebreide, flexibele en uitbreidbare statusevaluatie en rapportage biedt. Met het model kan bijna realtime worden gecontroleerd op de status van het cluster en de services die erin worden uitgevoerd. U kunt eenvoudig statusinformatie verkrijgen en potentiële problemen corrigeren voordat ze trapsgewijs worden veroorzaakt en enorme storingen veroorzaken. In het typische model verzenden services rapporten op basis van hun lokale weergaven en worden die gegevens samengevoegd om een algemene weergave op clusterniveau te bieden.
Service Fabric-onderdelen gebruiken dit uitgebreide statusmodel om hun huidige status te rapporteren. U kunt hetzelfde mechanisme gebruiken om de status van uw toepassingen te rapporteren. Als u investeert in gezondheidsrapportage van hoge kwaliteit die uw aangepaste voorwaarden vastlegt, kunt u problemen voor uw actieve toepassing veel eenvoudiger detecteren en oplossen.
Notitie
We hebben het statussubsysteem gestart om tegemoet te komen aan een behoefte aan bewaakte upgrades. Service Fabric biedt bewaakte toepassings- en clusterupgrades die zorgen voor volledige beschikbaarheid, geen downtime en minimale tot geen tussenkomst van de gebruiker. Om deze doelen te bereiken, controleert de upgrade de status op basis van geconfigureerd upgradebeleid. Een upgrade kan alleen worden uitgevoerd wanneer de status de gewenste drempelwaarden respecteert. Anders wordt de upgrade automatisch teruggedraaid of onderbroken om beheerders de kans te geven de problemen op te lossen. Zie dit artikel voor meer informatie over toepassingsupgrades.
Statusarchief
Het statusarchief bewaart statusgerelateerde informatie over entiteiten in het cluster voor eenvoudig ophalen en evalueren. Het wordt geïmplementeerd als een permanente stateful service van Service Fabric om hoge beschikbaarheid en schaalbaarheid te garanderen. Het statusarchief maakt deel uit van de infrastructuur-/systeemtoepassing en is beschikbaar wanneer het cluster actief is.
Statusentiteiten en -hiërarchie
De statusentiteiten zijn ingedeeld in een logische hiërarchie die interacties en afhankelijkheden tussen verschillende entiteiten vastlegt. Het statusarchief bouwt automatisch statusentiteiten en -hiërarchie op basis van rapporten die zijn ontvangen van Service Fabric-onderdelen.
De statusentiteiten weerspiegelen de Service Fabric-entiteiten. (Statustoepassingsentiteit komt bijvoorbeeld overeen met een toepassingsexemplaar dat is geïmplementeerd in het cluster, terwijl de entiteit statusknooppunt overeenkomt met een Service Fabric-clusterknooppunt.) De statushiërarchie legt de interacties van de systeementiteiten vast en het is de basis voor geavanceerde statusevaluatie. Meer informatie over de belangrijkste Service Fabric-concepten vindt u in het technische overzicht van Service Fabric. Zie het Service Fabric-toepassingsmodel voor meer informatie over de toepassing.
Met de statusentiteiten en -hiërarchie kunnen het cluster en de toepassingen effectief worden gerapporteerd, fouten worden opgespoord en bewaakt. Het statusmodel biedt een nauwkeurige, gedetailleerde weergave van de status van de vele bewegende onderdelen in het cluster.
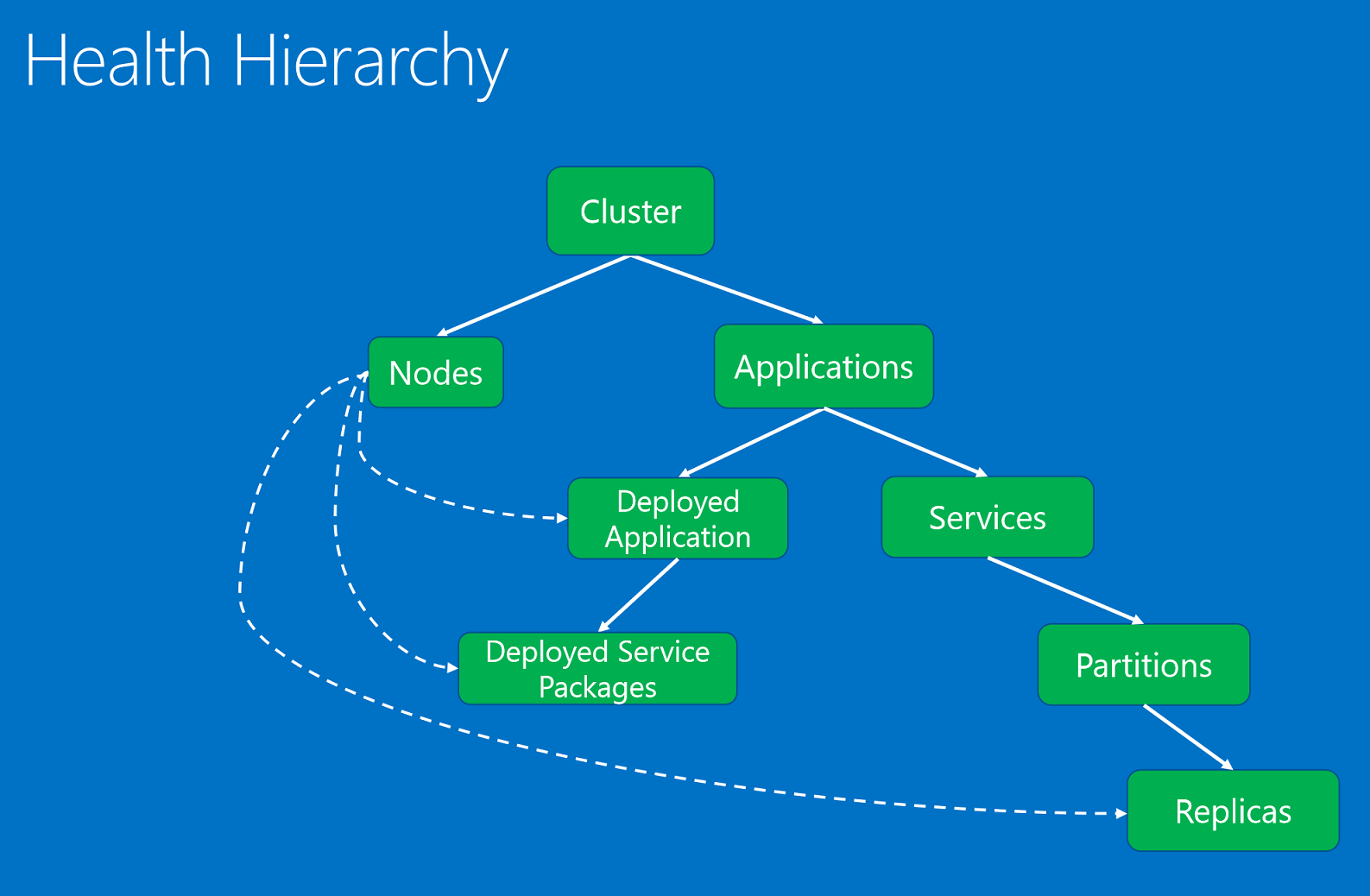 De statusentiteiten, geordend in een hiërarchie op basis van bovenliggende en onderliggende relaties.
De statusentiteiten, geordend in een hiërarchie op basis van bovenliggende en onderliggende relaties.
De statusentiteiten zijn:
- Cluster. Vertegenwoordigt de status van een Service Fabric-cluster. Clusterstatusrapporten beschrijven voorwaarden die van invloed zijn op het hele cluster. Deze voorwaarden zijn van invloed op meerdere entiteiten in het cluster of het cluster zelf. Op basis van de voorwaarde kan de journalist het probleem niet beperken tot een of meer beschadigde kinderen. Voorbeelden hiervan zijn de hersenen van het cluster splitsen vanwege netwerkpartitionering of communicatieproblemen.
- Knooppunt. Vertegenwoordigt de status van een Service Fabric-knooppunt. Statusrapporten van knooppunten beschrijven voorwaarden die van invloed zijn op de functionaliteit van het knooppunt. Deze zijn doorgaans van invloed op alle geïmplementeerde entiteiten die erop worden uitgevoerd. Voorbeelden hiervan zijn onvoldoende schijfruimte (of andere eigenschappen voor de hele machine, zoals geheugen, verbindingen) en wanneer een knooppunt uitvalt. De knooppuntentiteit wordt geïdentificeerd door de naam van het knooppunt (tekenreeks).
- Toepassing. Vertegenwoordigt de status van een toepassingsexemplaren die in het cluster worden uitgevoerd. Toepassingsstatusrapporten beschrijven voorwaarden die van invloed zijn op de algehele status van de toepassing. Ze kunnen niet worden beperkt tot afzonderlijke kinderen (services of geïmplementeerde toepassingen). Voorbeelden hiervan zijn de end-to-end-interactie tussen verschillende services in de toepassing. De toepassingsentiteit wordt geïdentificeerd door de naam van de toepassing (URI).
- Service. Vertegenwoordigt de status van een service die wordt uitgevoerd in het cluster. Servicestatus rapporten beschrijven voorwaarden die van invloed zijn op de algehele status van de service. De journalist kan het probleem niet beperken tot een beschadigde partitie of replica. Voorbeelden zijn een serviceconfiguratie (zoals poort of externe bestandsshare) die problemen veroorzaakt voor alle partities. De service-entiteit wordt geïdentificeerd door de servicenaam (URI).
- Partitie. Vertegenwoordigt de status van een servicepartitie. Statusrapporten van partities beschrijven voorwaarden die van invloed zijn op de hele replicaset. Voorbeelden hiervan zijn wanneer het aantal replica's lager is dan het doelaantal en wanneer een partitie in quorumverlies is. De partitie-entiteit wordt geïdentificeerd door de partitie-id (GUID).
- Replica. Vertegenwoordigt de status van een stateful servicereplica of een stateless service-exemplaar. De replica is de kleinste eenheid waarop watchdogs en systeemonderdelen kunnen rapporteren voor een toepassing. Voor stateful services zijn voorbeelden een primaire replica die geen bewerkingen naar secundaire bestanden en trage replicatie kan repliceren. Een staatloze instantie kan ook rapporteren wanneer deze geen resources meer heeft of verbindingsproblemen ondervindt. De replica-entiteit wordt geïdentificeerd door de partitie-id (GUID) en de replica- of exemplaar-id (lang).
- DeployedApplication. Vertegenwoordigt de status van een toepassing die wordt uitgevoerd op een knooppunt. Geïmplementeerde toepassingsstatusrapporten beschrijven voorwaarden die specifiek zijn voor de toepassing op het knooppunt die niet kunnen worden beperkt tot servicepakketten die op hetzelfde knooppunt zijn geïmplementeerd. Voorbeelden hiervan zijn fouten wanneer het toepassingspakket niet kan worden gedownload op dat knooppunt en problemen met het instellen van toepassingsbeveiligingsprinciplen op het knooppunt. De geïmplementeerde toepassing wordt geïdentificeerd door de naam van de toepassing (URI) en de naam van het knooppunt (tekenreeks).
- DeployedServicePackage. Vertegenwoordigt de status van een servicepakket dat wordt uitgevoerd op een knooppunt in het cluster. Er worden voorwaarden beschreven die specifiek zijn voor een servicepakket dat geen invloed heeft op de andere servicepakketten op hetzelfde knooppunt voor dezelfde toepassing. Voorbeelden zijn een codepakket in het servicepakket dat niet kan worden gestart en een configuratiepakket dat niet kan worden gelezen. Het geïmplementeerde servicepakket wordt geïdentificeerd door de naam van de toepassing (URI), de knooppuntnaam (tekenreeks), de naam van het servicemanifest (tekenreeks) en de activerings-id van het servicepakket (tekenreeks).
De granulariteit van het statusmodel maakt het eenvoudig om problemen te detecteren en op te lossen. Als een service bijvoorbeeld niet reageert, is het haalbaar om te melden dat het exemplaar van de toepassing niet in orde is. Rapportage op dat niveau is echter niet ideaal, omdat het probleem mogelijk niet van invloed is op alle services binnen die toepassing. Het rapport moet worden toegepast op de beschadigde service of op een specifieke onderliggende partitie als er meer informatie naar die partitie verwijst. De gegevens worden automatisch weergegeven via de hiërarchie en er wordt een beschadigde partitie zichtbaar gemaakt op service- en toepassingsniveaus. Deze aggregatie helpt de hoofdoorzaak van het probleem sneller vast te stellen en op te lossen.
De statushiërarchie bestaat uit bovenliggende en onderliggende relaties. Een cluster bestaat uit knooppunten en toepassingen. Toepassingen hebben services en geïmplementeerde toepassingen. Geïmplementeerde toepassingen hebben servicepakketten geïmplementeerd. Services hebben partities en elke partitie heeft een of meer replica's. Er is een speciale relatie tussen knooppunten en geïmplementeerde entiteiten. Een beschadigd knooppunt zoals gerapporteerd door het instantiesysteemonderdeel, de Failover Manager-service, is van invloed op de geïmplementeerde toepassingen, servicepakketten en replica's die erop zijn geïmplementeerd.
De statushiërarchie vertegenwoordigt de meest recente status van het systeem op basis van de meest recente statusrapporten. Dit is bijna realtime informatie. Interne en externe watchdogs kunnen rapporteren over dezelfde entiteiten op basis van toepassingsspecifieke logica of aangepaste bewaakte omstandigheden. Gebruikersrapporten bestaan naast de systeemrapporten.
Plan om te investeren in het rapporteren en reageren op status tijdens het ontwerpen van een grote cloudservice. Deze investering vooraf maakt de service eenvoudiger om fouten op te sporen, te bewaken en te gebruiken.
Statussen
Service Fabric gebruikt drie statussen om te beschrijven of een entiteit in orde is of niet: OK, waarschuwing en fout. Elk rapport dat naar het statusarchief wordt verzonden, moet een van deze statussen opgeven. Het resultaat van de statusevaluatie is een van deze statussen.
De mogelijke statussen zijn:
- OK. De entiteit is in orde. Er zijn geen bekende problemen gemeld over het of de onderliggende items (indien van toepassing).
- Waarschuwing. De entiteit heeft een aantal problemen, maar kan nog steeds correct werken. Er zijn bijvoorbeeld vertragingen, maar ze veroorzaken nog geen functionele problemen. In sommige gevallen kan de waarschuwingsvoorwaarde zichzelf oplossen zonder externe tussenkomst. In deze gevallen vergroten gezondheidsrapporten bewustzijn en bieden ze inzicht in wat er aan de hand is. In andere gevallen kan de waarschuwingsvoorwaarde afnemen in een ernstig probleem zonder tussenkomst van de gebruiker.
- Fout. De entiteit is beschadigd. Er moet actie worden ondernomen om de status van de entiteit te herstellen, omdat deze niet goed kan functioneren.
- Onbekend. De entiteit bestaat niet in het statusarchief. Dit resultaat kan worden verkregen uit de gedistribueerde query's waarmee resultaten van meerdere onderdelen worden samengevoegd. De get node list-query gaat bijvoorbeeld naar FailoverManager, ClusterManager en HealthManager. Haal de query voor de lijst met toepassingen op naar ClusterManager en HealthManager. Met deze query's worden resultaten van meerdere systeemonderdelen samengevoegd. Als een ander systeemonderdeel een entiteit retourneert die niet aanwezig is in het statusarchief, heeft het samengevoegde resultaat een onbekende status. Een entiteit is niet in het archief omdat statusrapporten nog niet zijn verwerkt of de entiteit na verwijdering is opgeschoond.
Statusbeleid
Het statusarchief past statusbeleid toe om te bepalen of een entiteit in orde is op basis van de rapporten en de onderliggende items.
Notitie
Statusbeleid kan worden opgegeven in het clustermanifest (voor cluster- en knooppuntstatusevaluatie) of in het toepassingsmanifest (voor toepassingsevaluatie en een van de onderliggende elementen). Aanvragen voor statusevaluatie kunnen ook aangepaste beleidsregels voor statusevaluatie doorgeven, die alleen voor die evaluatie worden gebruikt.
Service Fabric past standaard strikte regels toe (alles moet in orde zijn) voor de hiërarchische relatie tussen bovenliggende en onderliggende items. Als zelfs een van de kinderen één beschadigde gebeurtenis heeft, wordt het bovenliggende item beschouwd als beschadigd.
Clusterstatusbeleid
Het clusterstatusbeleid wordt gebruikt om de status van het cluster en de status van het knooppunt te evalueren. Het beleid kan worden gedefinieerd in het clustermanifest. Als deze niet aanwezig is, wordt het standaardbeleid (nul getolereerde fouten) gebruikt.
Het clusterstatusbeleid bevat:
OverweegWarningAsError. Hiermee geeft u op of waarschuwingsstatusrapporten moeten worden behandeld als fouten tijdens de statusevaluatie. Standaard: onwaar.
MaxPercentUnhealthyApplications. Hiermee geeft u het maximaal getolereerde percentage toepassingen op dat niet in orde kan zijn voordat het cluster als fout wordt beschouwd.
MaxPercentUnhealthyNodes. Hiermee geeft u het maximaal getolereerde percentage van knooppunten op dat niet in orde kan zijn voordat het cluster als fout wordt beschouwd. In grote clusters zijn sommige knooppunten altijd niet beschikbaar voor reparaties, dus dit percentage moet worden geconfigureerd om dat te tolereren.
ApplicationTypeHealthPolicyMap. De statusbeleidstoewijzing van het toepassingstype kan worden gebruikt tijdens de evaluatie van de clusterstatus om speciale toepassingstypen te beschrijven. Standaard worden alle toepassingen in een pool geplaatst en geëvalueerd met MaxPercentUnhealthyApplications. Als sommige toepassingstypen anders moeten worden behandeld, kunnen ze uit de globale pool worden gehaald. In plaats daarvan worden ze geëvalueerd op basis van de percentages die zijn gekoppeld aan de naam van het toepassingstype in de kaart. In een cluster zijn er bijvoorbeeld duizenden toepassingen van verschillende typen en enkele toepassingsexemplaren van een speciaal toepassingstype. De besturingstoepassingen mogen nooit fouten veroorzaken. U kunt globale MaxPercentUnhealthyApplications opgeven tot 20% om bepaalde fouten te tolereren, maar voor het toepassingstype ControlApplicationType stelt u de MaxPercentUnhealthyApplications in op 0. Op deze manier wordt het cluster geëvalueerd als sommige van de vele toepassingen niet in orde zijn, maar onder het globale percentage niet in orde is. Een waarschuwingsstatus heeft geen invloed op de clusterupgrade of andere bewaking die wordt geactiveerd door de status van de fout. Maar zelfs één besturingstoepassing die fout optreedt, maakt een cluster beschadigd, waardoor het terugdraaien of onderbreken van de clusterupgrade wordt geactiveerd, afhankelijk van de upgradeconfiguratie. Voor de toepassingstypen die in de kaart zijn gedefinieerd, worden alle toepassingsexemplaren uit de globale groep toepassingen gehaald. Ze worden geëvalueerd op basis van het totale aantal toepassingen van het toepassingstype, met behulp van de specifieke MaxPercentUnhealthyApplications van de kaart. Alle overige toepassingen blijven in de globale pool en worden geëvalueerd met MaxPercentUnhealthyApplications.
Het volgende voorbeeld is een fragment uit een clustermanifest. Als u vermeldingen in de toewijzing van het toepassingstype wilt definiëren, moet u de parameternaam vooraf laten gaan door 'ApplicationTypeMaxPercentUnhealthyApplications-', gevolgd door de naam van het toepassingstype.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. De statusbeleidstoewijzing van het knooppunttype kan worden gebruikt tijdens de evaluatie van de clusterstatus om speciale knooppunttypen te beschrijven. De knooppunttypen worden geëvalueerd op basis van de percentages die zijn gekoppeld aan de naam van het knooppunttype in de kaart. Het instellen van deze waarde heeft geen invloed op de globale pool van knooppunten die worden gebruikt voorMaxPercentUnhealthyNodes. Een cluster heeft bijvoorbeeld honderden knooppunten van verschillende typen en een aantal knooppunttypen die belangrijk werk hosten. Er mogen geen knooppunten in dat type zijn. U kunt globaalMaxPercentUnhealthyNodesopgeven tot 20% om bepaalde fouten voor alle knooppunten te tolereren, maar voor het knooppunttypeSpecialNodeTypestelt u deMaxPercentUnhealthyNodeswaarde in op 0. Op deze manier wordt het cluster geëvalueerd als sommige van de vele knooppunten niet in orde zijn, maar onder het globale beschadigde percentage. Een waarschuwingsstatus heeft geen invloed op de clusterupgrade of andere bewaking die wordt geactiveerd door de status Fout. Maar zelfs één knooppunt van het typeSpecialNodeTypefoutstatus maakt het cluster beschadigd en activeert terugdraaien of onderbreken van de clusterupgrade, afhankelijk van de upgradeconfiguratie. Als u daarentegen de globaleMaxPercentUnhealthyNodeswaarde instelt op 0 en hetSpecialNodeTypemaximale percentage beschadigde knooppunten instelt op 100, met één knooppunt van het typeSpecialNodeTypefoutstatus, wordt het cluster nog steeds in een foutstatus geplaatst, omdat de globale beperking in dit geval strenger is.Het volgende voorbeeld is een fragment uit een clustermanifest. Als u vermeldingen in de toewijzing van het knooppunttype wilt definiëren, moet u de parameternaam vooraf laten gaan door "NodeTypeMaxPercentUnhealthyNodes-", gevolgd door de naam van het knooppunttype.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Statusbeleid voor toepassingen
In het toepassingsstatusbeleid wordt beschreven hoe de evaluatie van gebeurtenissen en aggregatie van onderliggende statussen wordt uitgevoerd voor toepassingen en hun kinderen. Deze kan worden gedefinieerd in het toepassingsmanifest, ApplicationManifest.xml, in het toepassingspakket. Als er geen beleid is opgegeven, gaat Service Fabric ervan uit dat de entiteit niet in orde is als deze een statusrapport of een onderliggend element heeft met de status waarschuwing of foutstatus. De configureerbare beleidsregels zijn:
- OverweegWarningAsError. Hiermee geeft u op of waarschuwingsstatusrapporten moeten worden behandeld als fouten tijdens de statusevaluatie. Standaard: onwaar.
- MaxPercentUnhealthyDeployedApplications. Hiermee geeft u het maximaal getolereerde percentage geïmplementeerde toepassingen op dat niet in orde kan zijn voordat de toepassing als fout wordt beschouwd. Dit percentage wordt berekend door het aantal beschadigde geïmplementeerde toepassingen te delen over het aantal knooppunten waarop de toepassingen momenteel in het cluster zijn geïmplementeerd. De berekening wordt afgerond om één fout op kleine aantallen knooppunten te tolereren. Standaardpercentage: nul.
- DefaultServiceTypeHealthPolicy. Hiermee geeft u het statusbeleid voor het standaardservicetype op, dat het standaardstatusbeleid voor alle servicetypen in de toepassing vervangt.
- ServiceTypeHealthPolicyMap. Biedt een overzicht van servicestatusbeleid per servicetype. Deze beleidsregels vervangen het standaardstatusbeleid voor servicetypen voor elk opgegeven servicetype. Als een toepassing bijvoorbeeld een staatloze gatewayservicetype en een stateful engine-servicetype heeft, kunt u het statusbeleid voor de evaluatie anders configureren. Wanneer u beleid per servicetype opgeeft, kunt u meer gedetailleerde controle krijgen over de status van de service.
Statusbeleid voor servicetypen
Het statusbeleid van het servicetype geeft aan hoe de services en de onderliggende services moeten worden geëvalueerd en samengevoegd. Het beleid bevat:
- MaxPercentUnhealthyPartitionsPerService. Hiermee geeft u het maximaal getolereerde percentage beschadigde partities op voordat een service als beschadigd wordt beschouwd. Standaardpercentage: nul.
- MaxPercentUnhealthyReplicasPerPartition. Hiermee geeft u het maximaal getolereerde percentage beschadigde replica's op voordat een partitie als beschadigd wordt beschouwd. Standaardpercentage: nul.
- MaxPercentUnhealthyServices. Hiermee geeft u het maximaal getolereerde percentage beschadigde services op voordat de toepassing als beschadigd wordt beschouwd. Standaardpercentage: nul.
Het volgende voorbeeld is een fragment uit een toepassingsmanifest:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Statusevaluatie
Gebruikers en geautomatiseerde services kunnen op elk gewenst moment de status van elke entiteit evalueren. Als u de status van een entiteit wilt evalueren, worden in het statusarchief alle statusrapporten over de entiteit samengevoegd en worden alle onderliggende items geëvalueerd (indien van toepassing). Het algoritme voor statusaggregatie maakt gebruik van statusbeleid dat aangeeft hoe statusrapporten moeten worden geëvalueerd en hoe onderliggende statussen worden geaggregeerd (indien van toepassing).
Aggregatie van statusrapport
Eén entiteit kan meerdere statusrapporten hebben die door verschillende rapportgevers (systeemonderdelen of watchdogs) op verschillende eigenschappen worden verzonden. De aggregatie maakt gebruik van het gekoppelde statusbeleid, met name het lid ConsiderWarningAsError van het toepassings- of clusterstatusbeleid. ConsiderWarningAsError geeft aan hoe waarschuwingen moeten worden geëvalueerd.
De geaggregeerde status wordt geactiveerd door de slechtste statusrapporten van de entiteit. Als er ten minste één foutstatusrapport is, is de geaggregeerde status een fout.
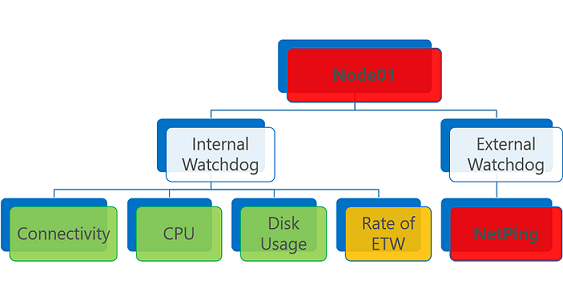
Een statusentiteit met een of meer foutstatusrapporten wordt geëvalueerd als Fout. Hetzelfde geldt voor een verlopen statusrapport, ongeacht de status.
Als er geen foutenrapporten en een of meer waarschuwingen zijn, is de geaggregeerde status een waarschuwing of fout, afhankelijk van de vlag van het beleid ConsiderWarningAsError.
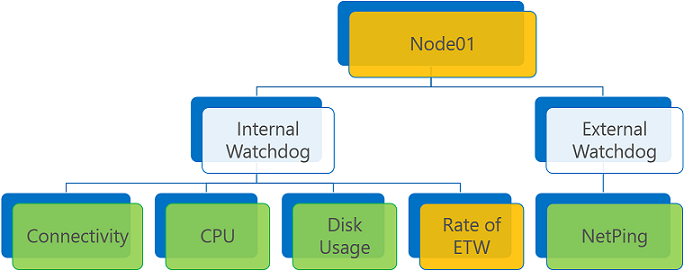
Aggregatie van statusrapporten met waarschuwingsrapport en ConsiderWarningAsError ingesteld op false (standaard).
Onderliggende statusaggregatie
De geaggregeerde status van een entiteit weerspiegelt de onderliggende statussen (indien van toepassing). Het algoritme voor het samenvoegen van onderliggende statusstatussen maakt gebruik van het statusbeleid dat van toepassing is op basis van het entiteitstype.
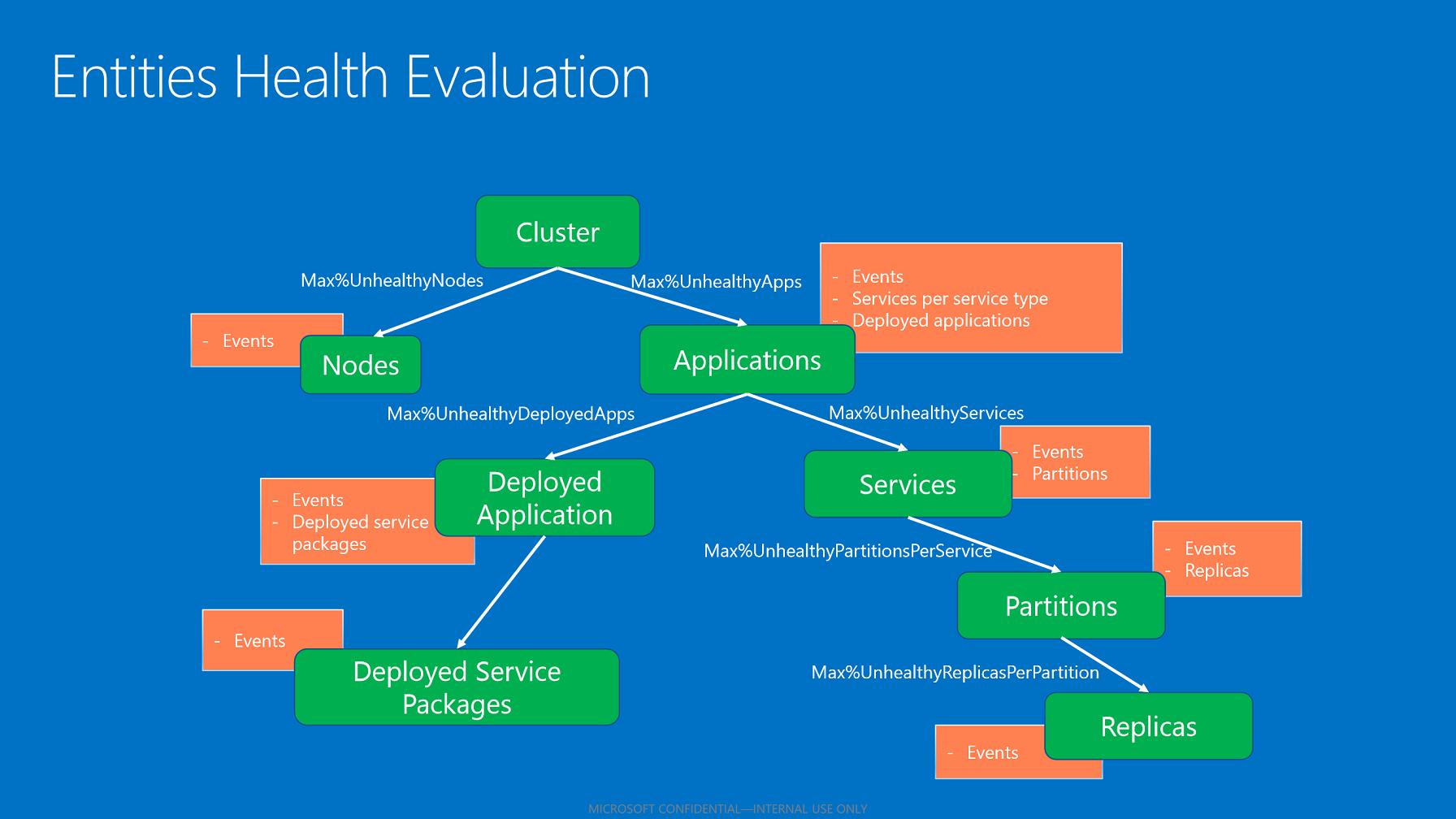
Onderliggende aggregatie op basis van statusbeleid.
Nadat het statusarchief alle kinderen heeft geëvalueerd, worden de statussen samengevoegd op basis van het geconfigureerde maximumpercentage van beschadigde kinderen. Dit percentage is afkomstig van het beleid op basis van de entiteit en het onderliggende type.
- Als alle kinderen OK-statussen hebben, is de geaggregeerde status van het kind OK.
- Als kinderen zowel OK- als waarschuwingsstatussen hebben, is de geaggregeerde status van het kind een waarschuwing.
- Als er kinderen zijn met foutstatussen die niet voldoen aan het maximaal toegestane percentage beschadigde kinderen, is de geaggregeerde status van de bovenliggende status een fout.
- Als de kinderen met foutstatussen het maximaal toegestane percentage beschadigde kinderen respecteren, is de geaggregeerde status van de bovenliggende status waarschuwing.
Statusrapportage
Systeemonderdelen, System Fabric-toepassingen en interne/externe watchdogs kunnen rapporteren aan service fabric-entiteiten. De rapportgevers maken lokale vaststellingen van de status van de bewaakte entiteiten, op basis van de voorwaarden die ze bewaken. Ze hoeven geen globale status of geaggregeerde gegevens te bekijken. Het gewenste gedrag is om eenvoudige reporters en geen complexe organismen te hebben die veel dingen moeten bekijken om af te stellen welke informatie moet worden verzonden.
Als u statusgegevens naar het statusarchief wilt verzenden, moet een journalist de betreffende entiteit identificeren en een statusrapport maken. Als u het rapport wilt verzenden, gebruikt u de FabricClient.HealthClient.ReportHealth-API , rapportstatus-API's die worden weergegeven op de Partition of CodePackageActivationContext objecten, PowerShell-cmdlets of REST.
Statusrapporten
De statusrapporten voor elk van de entiteiten in het cluster bevatten de volgende informatie:
SourceId. Een tekenreeks die de rapportfunctie van de status gebeurtenis uniek identificeert.
Entiteits-id. Identificeert de entiteit waar het rapport wordt toegepast. Dit verschilt op basis van het entiteitstype:
- Cluster. Geen.
- Knoop. Naam van knooppunt (tekenreeks).
- Toepassing. Toepassingsnaam (URI). Vertegenwoordigt de naam van het toepassingsexemplaren dat in het cluster is geïmplementeerd.
- Dienst. Servicenaam (URI). Vertegenwoordigt de naam van het service-exemplaar dat in het cluster is geïmplementeerd.
- Verdelen. Partitie-id (GUID). Vertegenwoordigt de unieke partitie-id.
- Replica. De stateful servicereplica-id of de staatloze service-exemplaar-id (INT64).
- DeployedApplication. Toepassingsnaam (URI) en knooppuntnaam (tekenreeks).
- DeployedServicePackage. Toepassingsnaam (URI), knooppuntnaam (tekenreeks) en servicemanifestnaam (tekenreeks).
Eigenschap. Een tekenreeks (geen vaste opsomming) waarmee de rapportgever de status gebeurtenis kan categoriseren voor een specifieke eigenschap van de entiteit. Reporter A kan bijvoorbeeld de status van de eigenschap 'Opslag' van Node01 rapporteren en rapportgever B kan de status van de eigenschap 'Connectiviteit' van Node01 rapporteren. In het statusarchief worden deze rapporten behandeld als afzonderlijke status gebeurtenissen voor de Entiteit Node01.
Beschrijving. Een tekenreeks waarmee een reporter gedetailleerde informatie over de status gebeurtenis kan opgeven. SourceId, Property en HealthState moeten het rapport volledig beschrijven. De beschrijving voegt door mensen leesbare informatie over het rapport toe. De tekst maakt het eenvoudiger voor beheerders en gebruikers om inzicht te krijgen in het statusrapport.
HealthState. Een opsomming die de status van het rapport beschrijft. De geaccepteerde waarden zijn OK, Waarschuwing en Fout.
TimeToLive. Een periode die aangeeft hoe lang het statusrapport geldig is. In combinatie met RemoveWhenExpired laat het statusarchief weten hoe verlopen gebeurtenissen moeten worden geëvalueerd. De waarde is standaard oneindig en het rapport is voor altijd geldig.
RemoveWhenExpired. Een Booleaanse waarde. Als dit is ingesteld op waar, wordt het verlopen statusrapport automatisch verwijderd uit het statusarchief en heeft het rapport geen invloed op de statusevaluatie van de entiteit. Wordt gebruikt wanneer het rapport alleen geldig is voor een opgegeven periode en de journalist hoeft het niet expliciet te wissen. Het wordt ook gebruikt om rapporten uit het statusarchief te verwijderen (bijvoorbeeld een watchdog wordt gewijzigd en stopt met het verzenden van rapporten met eerdere bron en eigenschap). Het kan een rapport met een korte TimeToLive samen met RemoveWhenExpired verzenden om eventuele eerdere statussen uit het statusarchief op te ruimen. Als de waarde is ingesteld op false, wordt het verlopen rapport behandeld als een fout bij de statusevaluatie. De foutieve waarde geeft aan het statusarchief dat de bron periodiek op deze eigenschap moet rapporteren. Als dat niet zo is, moet er iets mis zijn met de watchdog. De status van de watchdog wordt vastgelegd door de gebeurtenis als een fout te beschouwen.
SequenceNumber. Een positief geheel getal dat steeds groter moet worden, vertegenwoordigt het de volgorde van de rapporten. Het wordt gebruikt door het statusarchief om verlopen rapporten te detecteren die te laat worden ontvangen vanwege netwerkvertragingen of andere problemen. Een rapport wordt geweigerd als het volgnummer kleiner is dan of gelijk is aan het laatst toegepaste getal voor dezelfde entiteit, bron en eigenschap. Als deze niet is opgegeven, wordt het volgnummer automatisch gegenereerd. Het is alleen nodig om het volgnummer in te voeren wanneer u rapporteert over statusovergangen. In dit geval moet de bron onthouden welke rapporten worden verzonden en de informatie voor herstel bij failover behouden.
Deze vier stukjes information--SourceId, entiteits-id, Eigenschap en HealthState zijn vereist voor elk statusrapport. De SourceId-tekenreeks mag niet beginnen met het voorvoegsel System., dat is gereserveerd voor systeemrapporten. Voor dezelfde entiteit is er slechts één rapport voor dezelfde bron en eigenschap. Meerdere rapporten voor dezelfde bron en eigenschap overschrijven elkaar, hetzij aan de clientzijde van de status (als ze in batch zijn) of aan de kant van het statusarchief. De vervanging is gebaseerd op volgnummers; Nieuwere rapporten (met hogere reeksnummers) vervangen oudere rapporten.
Statusevenementen
Intern bewaart het statusarchief status gebeurtenissen, die alle informatie uit de rapporten en aanvullende metagegevens bevatten. De metagegevens bevatten de tijd waarop het rapport aan de statusclient is gegeven en de tijd waarop het aan de serverzijde is gewijzigd. De statusgebeurtenissen worden geretourneerd door statusquery's.
De toegevoegde metagegevens bevatten:
- SourceUtcTimestamp. Het tijdstip waarop het rapport werd gegeven aan de statusclient (Coordinated Universal Time).
- LastModifiedUtcTimestamp. Het tijdstip waarop het rapport voor het laatst is gewijzigd aan de serverzijde (Coordinated Universal Time).
- IsExpired. Een vlag om aan te geven of het rapport is verlopen toen de query werd uitgevoerd door het statusarchief. Een gebeurtenis kan alleen worden verlopen als RemoveWhenExpired onwaar is. Anders wordt de gebeurtenis niet geretourneerd door een query en wordt deze verwijderd uit de store.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. De laatste keer voor overgangen ok/waarschuwing/fout. Deze velden geven de geschiedenis van de statusovergangen voor de gebeurtenis.
De statusovergangsvelden kunnen worden gebruikt voor slimmere waarschuwingen of 'historische' statusinformatie. Ze maken scenario's mogelijk, zoals:
- Waarschuwing wanneer een eigenschap gedurende meer dan X minuten een waarschuwing/fout heeft gehad. Als u de voorwaarde gedurende een bepaalde periode controleert, voorkomt u waarschuwingen over tijdelijke voorwaarden. Een waarschuwing als de status meer dan vijf minuten is gewaarschuwd, kan bijvoorbeeld worden vertaald in (HealthState == Warning and Now - LastWarningTransitionTime > 5 minuten).
- Waarschuwing alleen voor voorwaarden die in de afgelopen X minuten zijn gewijzigd. Als een rapport al fout was vóór de opgegeven tijd, kan het worden genegeerd omdat het eerder al is gesignaleerd.
- Als een eigenschap tussen waarschuwing en fout schakelt, bepaalt u hoe lang deze niet in orde is (niet ok). Een waarschuwing als de eigenschap bijvoorbeeld langer dan vijf minuten niet in orde is, kan worden vertaald in (HealthState != OK en Now - LastOkTransitionTime > 5 minuten).
Voorbeeld: Toepassingsstatus rapporteren en evalueren
In het volgende voorbeeld wordt een statusrapport via PowerShell verzonden op de toepassingsinfrastructuur :/WordCount van de bron MyWatchdog. Het statusrapport bevat informatie over de statuseigenschap 'beschikbaarheid' in een foutstatus, met oneindig TimeToLive. Vervolgens wordt een query uitgevoerd op de toepassingsstatus, die geaggregeerde statusfouten en de gerapporteerde statusgebeurtenissen in de lijst met statusgebeurtenissen retourneert.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Gebruik van statusmodel
Met het statusmodel kunnen cloudservices en het onderliggende Service Fabric-platform worden geschaald, omdat bewaking en statusbepaling worden verdeeld over de verschillende monitors binnen het cluster. Andere systemen hebben één gecentraliseerde service op clusterniveau die alle mogelijk nuttige informatie parseert die door services wordt verzonden. Deze aanpak belemmert hun schaalbaarheid. Ze kunnen ook geen specifieke informatie verzamelen om problemen en potentiële problemen zo dicht mogelijk bij de hoofdoorzaak te identificeren.
Het statusmodel wordt intensief gebruikt voor bewaking en diagnose, voor het evalueren van cluster- en toepassingsstatus en voor bewaakte upgrades. Andere services gebruiken statusgegevens om automatische reparaties uit te voeren, de statusgeschiedenis van het cluster te bouwen en waarschuwingen te geven voor bepaalde voorwaarden.
Volgende stappen
Service Fabric-statusrapporten weergeven
Systeemstatusrapporten gebruiken voor probleemoplossing
Servicestatus rapporteren en controleren
Aangepaste Service Fabric-statusrapporten toevoegen