Zoekresultaten vormgeven of de samenstelling van zoekresultaten wijzigen in Azure AI Search
In dit artikel wordt de samenstelling van zoekresultaten uitgelegd en wordt uitgelegd hoe u zoekresultaten vormgeeft aan uw scenario's. Zoekresultaten worden geretourneerd in een queryantwoord. De vorm van een antwoord wordt bepaald door parameters in de query zelf. Deze parameters omvatten:
- Aantal overeenkomsten gevonden in de index (
count) - Aantal overeenkomsten dat wordt geretourneerd in het antwoord (standaard 50, configureerbaar via
top) of per pagina (skipentop) - Een zoekscore voor elk resultaat, gebruikt voor rangschikking (
@search.score) - Velden die zijn opgenomen in zoekresultaten (
select) - Sorteerlogica (
orderby) - Termen markeren binnen een resultaat, overeenkomend op de gehele of gedeeltelijke term in de hoofdtekst
- Optionele elementen uit de semantische ranker (
answersbovenaan,captionsvoor elke overeenkomst)
Zoekresultaten kunnen velden op het hoogste niveau bevatten, maar het grootste deel van het antwoord bestaat uit overeenkomende documenten in een matrix.
Clients en API's voor het definiëren van het queryantwoord
U kunt de volgende clients gebruiken om een queryantwoord te configureren:
- Search Explorer in Azure Portal, met behulp van de JSON-weergave, zodat u elke ondersteunde parameter kunt opgeven
- Documenten - POST (REST API's)
- Methode SearchClient.Search (Azure SDK voor .NET)
- Methode SearchClient.Search (Azure SDK voor Python)
- Methode SearchClient.Search (Azure voor JavaScript)
- Methode SearchClient.Search (Azure voor Java)
Resultaatsamenstelling
Resultaten zijn meestal tabellair, samengesteld uit velden van alle retrievable velden of beperkt tot alleen die velden die zijn opgegeven in de select parameter. Rijen zijn de overeenkomende documenten, meestal gerangschikt in volgorde van relevantie, tenzij uw querylogica de relevantieclassificatie uitsluit.
U kunt kiezen welke velden in de zoekresultaten staan. Hoewel een zoekdocument mogelijk een groot aantal velden bevat, zijn er meestal slechts enkele nodig om elk document in resultaten weer te geven. Voeg in een queryaanvraag toe select=<field list> om op te geven welke retrievable velden in het antwoord moeten worden weergegeven.
Kies velden die contrast en differentiatie bieden tussen documenten, zodat er voldoende informatie beschikbaar is om een clickthrough-antwoord op het deel van de gebruiker uit te nodigen. Op een e-commercesite kan het een productnaam, beschrijving, merk, kleur, grootte, prijs en beoordeling zijn. Voor de ingebouwde index hotels-sample is dit mogelijk de velden 'select' in het volgende voorbeeld:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Tips voor onverwachte resultaten
Af en toe is de query-uitvoer niet wat u verwacht te zien. U kunt bijvoorbeeld merken dat sommige resultaten duplicaten lijken te zijn of dat een resultaat dat bovenaan moet worden weergegeven, lager in de resultaten staat. Wanneer queryresultaten onverwacht zijn, kunt u deze querywijzigingen proberen om te zien of de resultaten worden verbeterd:
Wijzig
searchMode=any(standaard) om overeenkomsten op alle criteria tesearchMode=allvereisen in plaats van een van de criteria. Dit geldt met name wanneer booleaanse operators de query bevatten.Experimenteer met verschillende lexicale analysen of aangepaste analyse om te zien of het queryresultaat wordt gewijzigd. De standaardanalyse breekt woorden met afbreekstreepjes op en vermindert woorden tot hoofdformulieren, wat meestal de robuustheid van een queryreactie verbetert. Als u echter afbreekstreepjes wilt behouden of als tekenreeksen speciale tekens bevatten, moet u mogelijk aangepaste analysefuncties configureren om ervoor te zorgen dat de index tokens in de juiste indeling bevat. Zie Gedeeltelijke zoektermen en patronen met speciale tekens (afbreekstreepjes, jokertekens, regex, patronen) voor meer informatie.
Overeenkomsten tellen
De count parameter retourneert het aantal documenten in de index dat als overeenkomst voor de query wordt beschouwd. Als u het aantal wilt retourneren, voegt u deze toe count=true aan de queryaanvraag. Er is geen maximumwaarde opgelegd door de zoekservice. Afhankelijk van uw query en de inhoud van uw documenten, kan het aantal zo hoog zijn als elk document in de index.
Het aantal is nauwkeurig wanneer de index stabiel is. Als het systeem documenten actief toevoegt, bijwerkt of verwijdert, is het aantal bij benadering, met uitzondering van documenten die niet volledig zijn geïndexeerd.
Het aantal wordt niet beïnvloed door routineonderhoud of andere workloads in de zoekservice. Als u echter meerdere partities en één replica hebt, kunt u korte termijnschommelingen ervaren in het aantal documenten (enkele minuten) omdat de partities opnieuw worden opgestart.
Tip
Als u indexeringsbewerkingen wilt controleren, kunt u controleren of de index het verwachte aantal documenten bevat door een lege zoekquery search=* toe te voegencount=true. Het resultaat is het volledige aantal documenten in uw index.
Bij het testen van querysyntaxis count=true kunt u snel zien of uw wijzigingen meer of minder resultaten opleveren, wat nuttige feedback kan zijn.
Aantal resultaten in het antwoord
Azure AI Search maakt gebruik van paging aan de serverzijde om te voorkomen dat query's te veel documenten tegelijk ophalen. Queryparameters die het aantal resultaten in een antwoord bepalen, zijn top en skip.
top verwijst naar het aantal zoekresultaten op een pagina.
skip is een interval van top, en het vertelt de zoekmachine hoeveel resultaten moeten worden overgeslagen voordat de volgende set wordt opgehaald.
Het standaardpaginaformaat is 50, terwijl het maximale paginaformaat 1000 is. Als u een waarde opgeeft die groter is dan 1000 en er meer dan 1000 resultaten in uw index worden gevonden, worden alleen de eerste 1000 resultaten geretourneerd. Als het aantal overeenkomsten groter is dan het paginaformaat, bevat het antwoord informatie om de volgende pagina met resultaten op te halen. Voorbeeld:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
De belangrijkste overeenkomsten worden bepaald door de zoekscore, ervan uitgaande dat de query zoeken in volledige tekst of semantisch is. Anders zijn de belangrijkste overeenkomsten een willekeurige volgorde voor exacte overeenkomstquery's (waarbij uniform @search.score=1.0 willekeurige classificatie aangeeft).
Ingesteld top om de standaardwaarde van 50 te overschrijven. Als u een hybride query gebruikt, kunt u in nieuwere preview-API's maxTextRecallSize opgeven om maximaal 10.000 documenten te retourneren.
Als u de paging wilt beheren van alle documenten die in een resultatenset worden geretourneerd, gebruikt top en skip samen. Deze query retourneert de eerste set van 15 overeenkomende documenten plus een telling van het totale aantal overeenkomsten.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Deze query retourneert de tweede set, waarbij de eerste 15 wordt overgeslagen om de volgende 15 (16 tot en met 30) te krijgen:
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
De resultaten van gepagineerde query's zijn niet gegarandeerd stabiel als de onderliggende index verandert. Bij het wisselen wordt de waarde van skip elke pagina gewijzigd, maar elke query is onafhankelijk en werkt deze op de huidige weergave van de gegevens zoals deze zich in de index op het moment van de query bevinden (met andere woorden, er is geen caching of momentopname van resultaten, zoals die in een database voor algemeen gebruik).
Hier volgt een voorbeeld van hoe u duplicaten krijgt. Stel dat u een index met vier documenten hebt:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Stel nu dat u wilt dat resultaten twee tegelijk worden geretourneerd, gesorteerd op beoordeling. U voert deze query uit om de eerste pagina met resultaten op te halen: $top=2&$skip=0&$orderby=rating deschet produceren van de volgende resultaten:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
In de service wordt ervan uitgegaan dat er een vijfde document wordt toegevoegd aan de index tussen queryoproepen: { "id": "5", "rating": 4 }. Kort daarna voert u een query uit om de tweede pagina op te halen: $top=2&$skip=2&$orderby=rating descen haalt u de volgende resultaten op:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
U ziet dat document 2 twee keer wordt opgehaald. Dit komt doordat het nieuwe document 5 een hogere waarde heeft voor classificatie, zodat het sorteert voor document 2 en op de eerste pagina terechtkomt. Hoewel dit gedrag mogelijk onverwacht is, is het gebruikelijk dat een zoekmachine zich gedraagt.
Door een groot aantal resultaten bladeren
Een alternatieve techniek voor pagieren is het gebruik van een sorteervolgorde en bereikfilter als tijdelijke oplossing voor skip.
In deze tijdelijke oplossing worden sorteren en filteren toegepast op een document-id-veld of een ander veld dat uniek is voor elk document. Het unieke veld moet de zoekindex hebben filterable en sortable toeschrijven.
Geef een query uit om een volledige pagina met gesorteerde resultaten te retourneren.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Kies het laatste resultaat dat wordt geretourneerd door de zoekquery. Hier ziet u een voorbeeldresultaat met alleen een id-waarde.
{ "id": "50" }Gebruik deze id-waarde in een bereikquery om de volgende pagina met resultaten op te halen. Dit id-veld moet unieke waarden hebben, anders kan paginering dubbele resultaten bevatten.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Paginering eindigt wanneer de query nul resultaten retourneert.
Notitie
De filterable kenmerken en sortable kenmerken kunnen alleen worden ingeschakeld wanneer een veld voor het eerst aan een index wordt toegevoegd. Ze kunnen niet worden ingeschakeld voor een bestaand veld.
Resultaten ordenen
In een zoekquery voor volledige tekst kunnen resultaten worden gerangschikt op:
- een zoekscore
- een semantische rerankerscore
- een sorteervolgorde voor een
sortableveld
U kunt ook eventuele overeenkomsten in specifieke velden verbeteren door een scoreprofiel toe te voegen.
Volgorde op zoekscore
Voor zoekquery's in volledige tekst worden resultaten automatisch gerangschikt op een zoekscore met behulp van een BM25-algoritme, berekend op basis van termfrequentie, documentlengte en gemiddelde documentlengte.
Het @search.score bereik is niet-afhankelijk of 0 tot (maar niet inclusief) 1,00 op oudere services.
Voor beide algoritmes geeft een @search.score gelijk aan 1,00 een niet-gescorede of ongerankeerde resultatenset aan, waarbij de score 1,0 uniform is voor alle resultaten. Niet-gescorede resultaten treden op wanneer het queryformulier fuzzy zoekopdrachten, jokertekens of regex-query's of een lege zoekopdracht (search=*) is. Als u een classificatiestructuur moet opleggen boven niet-gescorede resultaten, kunt u een orderby expressie overwegen om dat doel te bereiken.
Volgorde door de semantische reranker
Als u een semantische rangschikking gebruikt, bepaalt de @search.rerankerScore sorteervolgorde van uw resultaten.
Het @search.rerankerScore bereik is 1 tot 4,00, waarbij een hogere score een sterkere semantische overeenkomst aangeeft.
Bestellen met orderby
Als consistente volgorde een toepassingsvereiste is, kunt u een orderby expressie voor een veld definiëren. Alleen velden die zijn geïndexeerd als 'sorteerbaar' kunnen worden gebruikt om resultaten te ordenen.
Velden die vaak worden gebruikt in een orderby insluitingsclassificatie, -datum en -locatie. Filteren op locatie vereist dat de filterexpressie de geo.distance() functie aanroept, naast de veldnaam.
Numerieke velden (Edm.Double, Edm.Int32, Edm.Int64) worden gesorteerd in numerieke volgorde (bijvoorbeeld 1, 2, 10, 11, 20).
Tekenreeksvelden (Edm.StringsubveldenEdm.ComplexType) worden gesorteerd in ascii-sorteervolgorde of Unicode-sorteervolgorde, afhankelijk van de taal.
Numerieke inhoud in tekenreeksvelden wordt alfabetisch gesorteerd (1, 10, 11, 2, 20).
Hoofdletters worden voor kleine letters gesorteerd (APPLE, Apple, BANAAN, Banaan, appel, banaan). U kunt een tekstnormizer toewijzen om de tekst vooraf te verwerken voordat u sorteert om dit gedrag te wijzigen. Het gebruik van de tokenizer voor kleine letters in een veld heeft geen invloed op het sorteergedrag omdat Azure AI Search sorteert op een niet-analysed exemplaar van het veld.
Tekenreeksen die leiden met diakritische tekens worden als laatste weergegeven (Äpfel, Öffnen, Üben)
Relevantie verhogen met behulp van een scoreprofiel
Een andere benadering die de consistentie van de volgorde bevordert, is het gebruik van een aangepast scoreprofiel. Scoreprofielen geven u meer controle over de rangschikking van items in zoekresultaten, met de mogelijkheid om overeenkomsten in specifieke velden te verbeteren. De extra scorelogica kan helpen kleine verschillen tussen replica's te overschrijven, omdat de zoekscores voor elk document verder van elkaar liggen. We raden het classificatie-algoritme voor deze benadering aan.
Markeren
Treffermarkeringen verwijzen naar tekstopmaak (zoals vet of gele markeringen) die zijn toegepast op overeenkomende termen in een resultaat, zodat u de overeenkomst eenvoudig kunt herkennen. Markeren is handig voor langere inhoudsvelden, zoals een beschrijvingsveld, waarbij de overeenkomst niet direct duidelijk is.
U ziet dat markering wordt toegepast op afzonderlijke termen. Er is geen markeringsmogelijkheid voor de inhoud van een heel veld. Als u een woordgroep wilt markeren, moet u de overeenkomende termen (of woordgroepen) opgeven in een door aanhalingstekenreeks. Deze techniek wordt verder beschreven in deze sectie.
Instructies voor het markeren van treffers worden weergegeven in de queryaanvraag. Query's die query-uitbreiding in de engine activeren, zoals fuzzy en zoekopdrachten met jokertekens, bieden beperkte ondersteuning voor het markeren van treffers.
Vereisten voor het markeren van treffers
- Velden moeten of
Edm.StringCollection(Edm.String) - Velden moeten worden toegeschreven aan
searchable
Markering opgeven in de aanvraag
Als u gemarkeerde termen wilt retourneren, neemt u de markeringsparameter op in de queryaanvraag. De parameter wordt ingesteld op een door komma's gescheiden lijst met velden.
Standaard is <em>de opmaakmarkering, maar u kunt de tag overschrijven met behulp van highlightPreTag en highlightPostTag parameters. De clientcode verwerkt het antwoord (bijvoorbeeld het toepassen van een vet lettertype of een gele achtergrond).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Standaard retourneert Azure AI Search maximaal vijf markeringen per veld. U kunt dit getal aanpassen door een streepje toe te voegen gevolgd door een geheel getal. Retourneert bijvoorbeeld "highlight": "description-10" maximaal 10 gemarkeerde termen voor overeenkomende inhoud in het beschrijvingsveld.
Gemarkeerde resultaten
Wanneer markeringen worden toegevoegd aan de query, bevat het antwoord een @search.highlights voor elk resultaat, zodat uw toepassingscode zich op die structuur kan richten. De lijst met velden die zijn opgegeven voor 'markeren' zijn opgenomen in het antwoord.
In een trefwoordzoekopdracht wordt elke term afzonderlijk gescand. Een query voor 'goddelijke geheimen' retourneert overeenkomsten in elk document met een van beide termen.
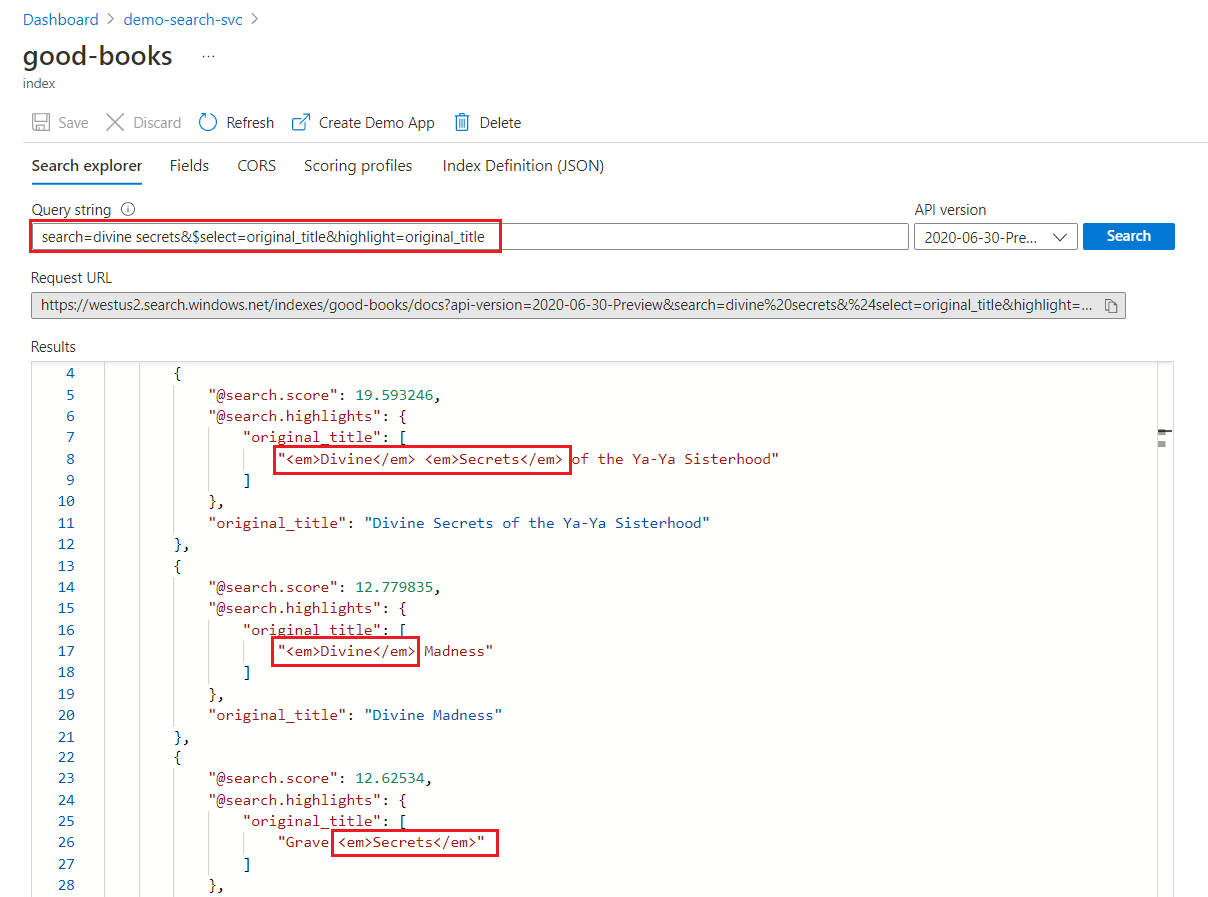
Trefwoorden zoeken markeren
In een gemarkeerd veld wordt opmaak toegepast op hele termen. Bij een overeenkomst met "The Divine Secrets of the Ya-Ya Sisterhood" wordt de opmaak bijvoorbeeld op elke term afzonderlijk toegepast, ook al zijn ze opeenvolgend.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Zoektermen markeren
Opmaak voor hele termen geldt zelfs voor een woordgroepszoekopdracht, waarbij meerdere termen tussen dubbele aanhalingstekens staan. Het volgende voorbeeld is dezelfde query, behalve dat "goddelijke geheimen" wordt ingediend als een tussenhaling geplaatste woordgroep (sommige REST-clients vereisen dat u de binnenste aanhalingstekens met een backslash \"escapet):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Omdat de criteria nu beide termen hebben, wordt er slechts één overeenkomst gevonden in de zoekindex. Het antwoord op de vorige query ziet er als volgt uit:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Woordgroepen markeren op oudere services
Search-service s die vóór 15 juli 2020 zijn gemaakt, implementeren een andere markeringservaring voor woordgroepenquery's.
Voor de volgende voorbeelden gaat u uit van een queryreeks die de tussenhalingstekens 'super bowl' bevat. Vóór juli 2020 is een term in de zin gemarkeerd:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Voor zoekservices die na juli 2020 zijn gemaakt, worden alleen zinnen geretourneerd die overeenkomen met de volledige woordgroepsquery:@search.highlights
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Volgende stappen
Als u snel een zoekpagina voor uw client wilt genereren, kunt u de volgende opties overwegen:
Maak een demo-app in Azure Portal en maak een HTML-pagina met een zoekbalk, facetnavigatie en een miniatuurgebied als u afbeeldingen hebt.
Zoeken toevoegen aan een ASP.NET Core-app (MVC) is een zelfstudie en codevoorbeeld waarmee een functionele client wordt gebouwd.
Zoeken toevoegen aan web-apps is een C#-zelfstudie en codevoorbeeld dat gebruikmaakt van de React JavaScript-bibliotheken voor de gebruikerservaring. De app wordt geïmplementeerd met behulp van Azure Static Web Apps en implementeert paginering.