Relevantie in trefwoorden zoeken (BM25-score)
In dit artikel wordt het BM25-algoritme voor relevantiescores uitgelegd dat wordt gebruikt voor het berekenen van zoekscores voor volledige tekst. BM25 relevantie is exclusief voor zoeken in volledige tekst. Filterquery's, automatisch aanvullen en voorgestelde query's, zoekopdrachten met jokertekens en fuzzy zoekquery's worden niet beoordeeld of gerangschikt op relevantie.
Scorealgoritmen die worden gebruikt in zoeken in volledige tekst
Azure AI Search biedt de volgende scorealgoritmen voor zoeken in volledige tekst:
| Algoritme | Gebruik | Bereik |
|---|---|---|
BM25Similarity |
Vast algoritme voor alle zoekservices die na juli 2020 zijn gemaakt. U kunt dit algoritme configureren, maar u kunt niet overschakelen naar een oudere algoritme (klassiek). | Onbegrensd. |
ClassicSimilarity |
Standaard voor oudere zoekservices die vóór juli 2020 zijn. Op oudere services kunt u zich aanmelden voor BM25 en een BM25-algoritme per index kiezen. | 0 < 1.00 |
Zowel BM25 als klassiek zijn TF-IDF-achtige ophaalfuncties die gebruikmaken van de termfrequentie (TF) en de inverse documentfrequentie (IDF) als variabelen om relevantiescores te berekenen voor elk documentquerypaar, dat vervolgens wordt gebruikt voor het rangschikken van resultaten. Hoewel BM25 conceptueel vergelijkbaar is met klassiek, is BM25 geroot in het ophalen van probabilistische informatie die intuïtievere overeenkomsten produceert, zoals gemeten door gebruikersonderzoek.
BM25 biedt geavanceerde aanpassingsopties, zoals het toestaan van de gebruiker om te bepalen hoe de relevantiescore wordt geschaald met de term frequentie van overeenkomende termen.
Hoe BM25-classificatie werkt
Score voor relevantie verwijst naar de berekening van een zoekscore (@search.score) die fungeert als een indicator van de relevantie van een item in de context van de huidige query. Het bereik is niet gebonden. Hoe hoger de score, hoe relevanter het item.
De zoekscore wordt berekend op basis van statistische eigenschappen van de tekenreeksinvoer en de query zelf. Azure AI Search zoekt documenten die overeenkomen met zoektermen (sommige of alle, afhankelijk van searchMode), waarbij documenten die veel exemplaren van de zoekterm bevatten, gunstig zijn. De zoekscore neemt nog hoger uit als de term zelden voorkomt in de gegevensindex, maar gebruikelijk in het document. De basis voor deze benadering voor het berekenen van relevantie wordt TF-IDF of term frequentie-inverse documentfrequentie genoemd.
Zoekscores kunnen in een resultatenset worden herhaald. Wanneer meerdere treffers dezelfde zoekscore hebben, is de volgorde van dezelfde gescoorde items niet gedefinieerd en niet stabiel. Voer de query opnieuw uit en u ziet mogelijk de shiftpositie van items, met name als u de gratis service of een factureerbare service met meerdere replica's gebruikt. Gezien twee items met een identieke score, is er geen garantie dat er eerst een wordt weergegeven.
Als u de koppeling tussen herhalende scores wilt verbreken, kunt u een $orderby component toevoegen aan de eerste volgorde op score en vervolgens sorteren op een ander sorteerbaar veld (bijvoorbeeld $orderby=search.score() desc,Rating desc).
Alleen velden die zijn gemarkeerd als searchable in de index of searchFields in de query, worden gebruikt voor scoren. Alleen velden die zijn gemarkeerd als retrievable, of velden die zijn opgegeven in select de query, worden geretourneerd in zoekresultaten, samen met hun zoekscore.
Notitie
A @search.score = 1 geeft een niet-gescoorde of niet-gerangschikte resultatenset aan. De score is uniform voor alle resultaten. Niet-gescoorde resultaten treden op wanneer het queryformulier fuzzy zoekopdrachten, jokertekens of regex-query's of een lege zoekopdracht is (search=*soms gekoppeld aan filters, waarbij het filter de primaire methode is voor het retourneren van een overeenkomst).
Het volgende videosegment verwijst snel naar een uitleg van de algemeen beschikbare classificatiealgoritmen die worden gebruikt in Azure AI Search. U kunt de volledige video bekijken voor meer achtergrond.
Scores in tekstresultaten
Wanneer de resultaten worden gerangschikt, @search.score bevat de eigenschap de waarde die wordt gebruikt om de resultaten te ordenen.
De volgende tabel identificeert de score-eigenschap, het algoritme en het bereik.
| Zoekmethode | Parameter | Score-algoritme | Bereik |
|---|---|---|---|
| zoeken in volledige tekst | @search.score |
BM25-algoritme, met behulp van de parameters die zijn opgegeven in de index. | Onbegrensd. |
Scorevariatie
Zoekscores geven een algemeen gevoel van relevantie weer, waarbij de sterkte van overeenkomst ten opzichte van andere documenten in dezelfde resultatenset wordt weergegeven. Maar scores zijn niet altijd consistent van de ene query naar de volgende, dus als u met query's werkt, ziet u mogelijk kleine verschillen in de volgorde van zoekdocumenten. Er zijn verschillende verklaringen waarom dit kan gebeuren.
| Oorzaak | Beschrijving |
|---|---|
| Identieke scores | Als meerdere documenten dezelfde score hebben, kan een van deze documenten eerst worden weergegeven. |
| Volatiliteit van gegevens | Indexinhoud varieert wanneer u documenten toevoegt, wijzigt of verwijdert. Termfrequenties veranderen naarmate indexupdates na verloop van tijd worden verwerkt, wat van invloed is op de zoekscores van overeenkomende documenten. |
| Meerdere replica's | Voor services die meerdere replica's gebruiken, worden query's parallel uitgevoerd op elke replica. De indexstatistieken die worden gebruikt om een zoekscore te berekenen, worden per replica berekend, waarbij de resultaten zijn samengevoegd en gerangschikt in het queryantwoord. Replica's zijn meestal spiegels van elkaar, maar statistieken kunnen verschillen vanwege kleine verschillen in status. Eén replica kan bijvoorbeeld documenten hebben verwijderd die bijdragen aan hun statistieken, die uit andere replica's zijn samengevoegd. Verschillen in statistieken per replica zijn doorgaans merkbaarder in kleinere indexen. In de volgende sectie vindt u meer informatie over deze voorwaarde. |
Sharding-effecten op queryresultaten
Een shard is een segment van een index. Met Azure AI Search wordt een index onderverdeeld in shards om het proces van het toevoegen van partities sneller te maken (door shards naar nieuwe zoekeenheden te verplaatsen). In een zoekservice is shardbeheer een implementatiedetail en niet-configureerbaar, maar wetende dat een index is sharded helpt om inzicht te hebben in de incidentele afwijkingen in rangschikking en gedrag voor automatisch aanvullen:
Classificatieafwijkingen: zoekscores worden eerst berekend op shardniveau en vervolgens samengevoegd in één resultatenset. Afhankelijk van de kenmerken van shard-inhoud, kunnen overeenkomsten van de ene shard hoger zijn dan overeenkomsten in een andere. Als u intuïtieve classificaties in zoekresultaten ziet, is dit waarschijnlijk het gevolg van de effecten van sharding, vooral als indexen klein zijn. U kunt deze classificatieafwijkingen vermijden door ervoor te kiezen om scores globaal te berekenen in de hele index, maar dit leidt wel tot een prestatiestraf.
Afwijkingen voor automatisch aanvullen: Query's voor automatisch aanvullen, waarbij overeenkomsten worden gemaakt op de eerste tekens van een gedeeltelijk ingevoerde term, accepteren een fuzzy parameter die kleine afwijkingen in de spelling vergeeft. Voor automatisch aanvullen is fuzzy matching beperkt tot termen in de huidige shard. Als een shard bijvoorbeeld 'Microsoft' bevat en een gedeeltelijke term 'micro' wordt ingevoerd, komt de zoekmachine overeen met 'Microsoft' in die shard, maar niet in andere shards die de resterende onderdelen van de index bevatten.
In het volgende diagram ziet u de relatie tussen replica's, partities, shards en zoekeenheden. Hier ziet u een voorbeeld van hoe één index wordt verdeeld over vier zoekeenheden in een service met twee replica's en twee partities. Elk van de vier zoekeenheden slaat slechts de helft van de shards van de index op. De zoekeenheden in de linkerkolom slaan de eerste helft van de shards op, bestaande uit de eerste partitie, terwijl die in de rechterkolom de tweede helft van de shards opslaan, bestaande uit de tweede partitie. Omdat er twee replica's zijn, zijn er twee kopieën van elke index-shard. In de zoekeenheden in de bovenste rij wordt één kopie opgeslagen, bestaande uit de eerste replica, terwijl die in de onderste rij een andere kopie opslaan, bestaande uit de tweede replica.
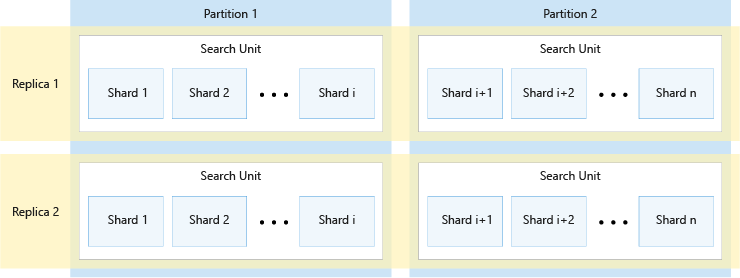
Het bovenstaande diagram is slechts één voorbeeld. Veel combinaties van partities en replica's zijn mogelijk, maximaal 36 zoekeenheden.
Notitie
Het aantal replica's en partities wordt gelijkmatig verdeeld in 12 (met name 1, 2, 3, 4, 6, 12). Azure AI Search verdeelt elke index vooraf in 12 shards, zodat deze in gelijke delen over alle partities kan worden verdeeld. Als uw service bijvoorbeeld drie partities heeft en u een index maakt, bevat elke partitie vier shards van de index. Hoe Azure AI Search een index shards is, is een implementatiedetail, afhankelijk van wijzigingen in toekomstige releases. Hoewel het getal vandaag 12 is, moet u niet verwachten dat dat getal altijd 12 in de toekomst is.
Scorestatistieken en plaksessies
Voor schaalbaarheid distribueert Azure AI Search elke index horizontaal via een shardingproces, wat betekent dat delen van een index fysiek gescheiden zijn.
Standaard wordt de score van een document berekend op basis van statistische eigenschappen van de gegevens in een shard. Deze benadering is over het algemeen geen probleem voor een grote hoeveelheid gegevens en biedt betere prestaties dan het berekenen van de score op basis van informatie in alle shards. Dat gezegd hebbende, kan het gebruik van deze prestatieoptimalisatie ertoe leiden dat twee zeer vergelijkbare documenten (of zelfs identieke documenten) uiteindelijk verschillende relevantiescores krijgen als ze in verschillende shards terechtkomen.
Als u de score liever wilt berekenen op basis van de statistische eigenschappen voor alle shards, kunt u dit doen door dit toe te voegen als een queryparameter (of als hoofdtekstparameter van de queryaanvraag toe te voegen"scoringStatistics": "global").scoringStatistics=global
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Als scoringStatistics u deze gebruikt, zorgt u ervoor dat alle shards in dezelfde replica dezelfde resultaten opleveren. Dat gezegd hebbende, kunnen verschillende replica's enigszins verschillen van elkaar, omdat ze altijd worden bijgewerkt met de meest recente wijzigingen in uw index. In sommige scenario's wilt u mogelijk dat uw gebruikers consistentere resultaten krijgen tijdens een 'querysessie'. In dergelijke scenario's kunt u een sessionId onderdeel van uw query's opgeven. Dit sessionId is een unieke tekenreeks die u maakt om te verwijzen naar een unieke gebruikerssessie.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Zolang hetzelfde sessionId wordt gebruikt, wordt er een best-inspanning gedaan om dezelfde replica te targeten, waardoor de consistentie van de resultaten wordt verhoogd die uw gebruikers zullen zien.
Notitie
Het herhaaldelijk hergebruiken van dezelfde sessionId waarden kan de taakverdeling van de aanvragen tussen replica's verstoren en de prestaties van de zoekservice nadelig beïnvloeden. De waarde die wordt gebruikt als sessionId, kan niet beginnen met een _-teken.
Relevantie afstemmen
In Azure AI Search kunt u voor trefwoorden zoeken en het tekstgedeelte van een hybride query parameters voor BM25-algoritme configureren, plus de relevantie van de zoekopdracht afstemmen en de zoekscores verhogen via de volgende mechanismen.
| Methode | Implementatie | Beschrijving |
|---|---|---|
| CONFIGURATIE van BM25-algoritme | Zoekindex | Configureer hoe de lengte en termfrequentie van het document van invloed zijn op de relevantiescore. |
| Scoreprofielen | Zoekindex | Geef criteria op voor het stimuleren van de zoekscore van een overeenkomst op basis van inhoudskenmerken. U kunt bijvoorbeeld overeenkomsten verhogen op basis van hun omzetpotentieel, nieuwere items promoten of misschien items verhogen die te lang in de voorraad zijn geweest. Een scoreprofiel maakt deel uit van de indexdefinitie, samengesteld uit gewogen velden, functies en parameters. U kunt een bestaande index bijwerken met scoreprofielwijzigingen, zonder dat er een index opnieuw hoeft te worden opgebouwd. |
| Semantische rangschikking | Queryaanvraag | Past het lezen van machines toe op zoekresultaten, wat meer semantisch relevante resultaten naar boven bevordert. |
| parameter featuresMode | Queryaanvraag | Deze parameter wordt meestal gebruikt voor het uitpakken van een BM25-score, maar kan worden gebruikt voor in code die een aangepaste scoreoplossing biedt. |
parameter featuresMode (preview)
Zoekdocumentenaanvragen ondersteunen een featuresMode-parameter die meer informatie biedt over een BM25-relevantiescore op veldniveau. Terwijl het @searchScore wordt berekend voor het hele document (hoe relevant dit document is in de context van deze query), geeft featuresMode informatie weer over afzonderlijke velden, zoals uitgedrukt in een @search.features structuur. De structuur bevat alle velden die in de query worden gebruikt (specifieke velden via searchFields in een query of alle velden die zijn toegeschreven als doorzoekbaar in een index).
Geef voor elk veld @search.features de volgende waarden op:
- Aantal unieke tokens gevonden in het veld
- Overeenkomstscore of een meting van hoe vergelijkbaar de inhoud van het veld is, ten opzichte van de queryterm
- Termfrequentie of het aantal keren dat de queryterm is gevonden in het veld
Voor een query die is gericht op de velden 'beschrijving' en 'titel', ziet een antwoord dat @search.features er als volgt uitziet:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
U kunt deze gegevenspunten gebruiken in aangepaste scoreoplossingen of de informatie gebruiken om problemen met zoekrelevantie op te sporen.
De parameter featuresMode wordt niet gedocumenteerd in de REST API's, maar u kunt deze gebruiken voor een preview-REST API-aanroep om documenten te zoeken naar tekstzoekopdrachten (trefwoorden) die bm25-rangschikken.
Aantal gerangschikte resultaten in een queryantwoord in volledige tekst
Als u geen paginering gebruikt, retourneert de zoekmachine standaard de top 50 hoogste classificatieovereenkomsten voor zoeken in volledige tekst. U kunt de top parameter gebruiken om een kleiner of groter aantal items te retourneren (maximaal 1000 in één antwoord). U kunt paginaresultaten gebruiken skip en next weergeven. Paging bepaalt het aantal resultaten op elke logische pagina en ondersteunt inhoudsnavigatie. Zie De zoekresultaten van Shape voor meer informatie.
Als uw volledige tekstquery deel uitmaakt van een hybride query, kunt u instellen dat het aantal resultaten aan de tekstzijde van de query wordt verhoogd maxTextRecallSize of verkleind.
Zoeken in volledige tekst is onderhevig aan een maximumlimiet van 1000 overeenkomsten (zie API-antwoordlimieten). Zodra er 1000 overeenkomsten zijn gevonden, zoekt de zoekmachine niet meer naar meer.