Quickstart: Een Apache Kafka-cluster maken in Azure HDInsight met behulp van Azure Portal
Apache Kafka is een open-source, gedistribueerd streamingplatform. Het wordt vaak gebruikt als een berichtenbroker, omdat het een functionaliteit biedt die vergelijkbaar is met een publicatie-/abonnementswachtrij voor berichten.
In deze quickstart leert u hoe u met Azure Portal een Apache Kafka-cluster maakt. U leert ook hoe u de inbegrepen hulpprogramma's gebruikt voor het verzenden en ontvangen van berichten via Apache Kafka. Zie Clusters instellen in HDInsight voor uitgebreide uitleg over de beschikbare configuraties. Zie Clusters maken in de portal voor meer informatie over het gebruik van de portal om clusters te maken.
Waarschuwing
HDInsight-clusters worden pro rato per minuut gefactureerd, ongeacht of u er wel of niet gebruik van maakt. Verwijder uw cluster daarom als u er klaar mee bent. Zie how to delete an HDInsight cluster (een HDInsight-cluster verwijderen).
De Apache Kafka-API is alleen toegankelijk voor resources binnen hetzelfde virtuele netwerk. In deze quickstart benadert u het cluster rechtstreeks via SSH. Als u andere services, netwerken of virtuele machines wilt verbinden met Apache Kafka, moet u eerst een virtueel netwerk maken en vervolgens de resources maken in het netwerk. Zie het document Verbinding maken met Apache Kafka via een virtueel netwerk voor meer informatie. Zie Een virtueel netwerk plannen voor Azure HDInsight voor meer algemene informatie over het plannen van virtuele netwerken voor HDInsight.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
Een SSH-client. Zie voor meer informatie Verbinding maken met HDInsight (Apache Hadoop) via SSH.
Een Apache Kafka-cluster maken
Gebruik de volgende stappen om een Apache Kafka-cluster te maken in HDInsight:
Meld u aan bij het Azure-portaal.
Selecteer + Een resource maken in het menu aan de bovenkant.
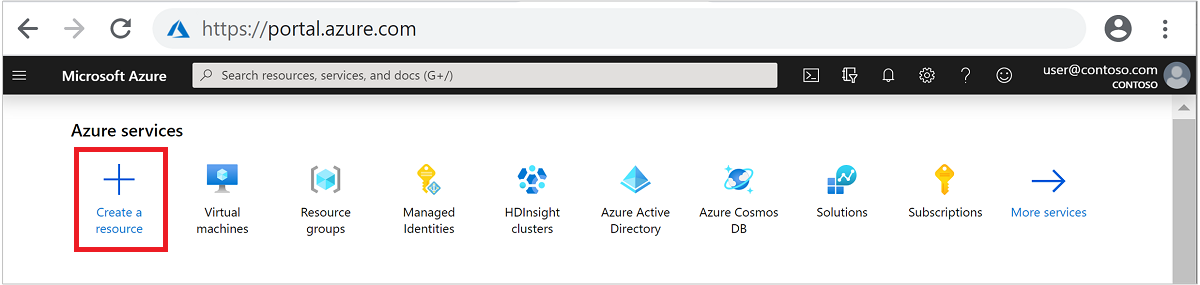
Selecteer Analytics>Azure HDInsight om naar de pagina HDInsight-cluster maken te gaan.
Geef op het tabblad Basis de volgende gegevens op:
Eigenschappen Beschrijving Abonnement Selecteer in de vervolgkeuzelijst het Azure-abonnement dat wordt gebruikt voor het cluster. Resourcegroep Maak een resourcegroep of selecteer een bestaande resourcegroep. Een resourcegroep is een container met Azure-onderdelen. In dit geval bevat de resourcegroep het HDInsight-cluster en het afhankelijke Azure Storage-account. Clusternaam Voer een wereldwijd unieke naam in. De naam mag bestaan uit maximaal 59 tekens, inclusief letters, cijfers en afbreekstreepjes. De eerste en laatste tekens van de naam mogen geen streepjes zijn. Regio Selecteer in de vervolgkeuzelijst een regio waarin het cluster wordt gemaakt. Kies een regio zo dicht mogelijk bij u in de buurt voor betere prestaties. Clustertype Selecteer Clustertype selecteren om een lijst te openen. Selecteer Kafka als clustertype in de lijst. Versie De standaardversie voor het clustertype wordt opgegeven. Selecteer een optie in de vervolgkeuzelijst als u een andere versie wilt opgeven. Gebruikersnaam/Wachtwoord voor clusteraanmeldgegevens De standaardaanmeldingsnaam is admin. Het wachtwoord moet minstens tien tekens lang zijn en moet ten minste één cijfer, één hoofdletter en één kleine letter, één niet-alfanumerieke teken (behalve tekens' ` ") bevatten. Zorg ervoor dat u geen algemene wachtwoorden opgeeft , zoalsPass@word1.SSH-gebruikersnaam (Secure Shell) De standaardgebruikersnaam is sshuser. U kunt hier echter een andere naam opgeven als u dat wilt.Het wachtwoord voor clusteraanmelding gebruiken voor SSH Schakel dit selectievakje in als u voor de SSH-gebruiker het wachtwoord wilt gebruiken dat u hebt opgegeven voor Wachtwoord voor clusteraanmeldgegevens. 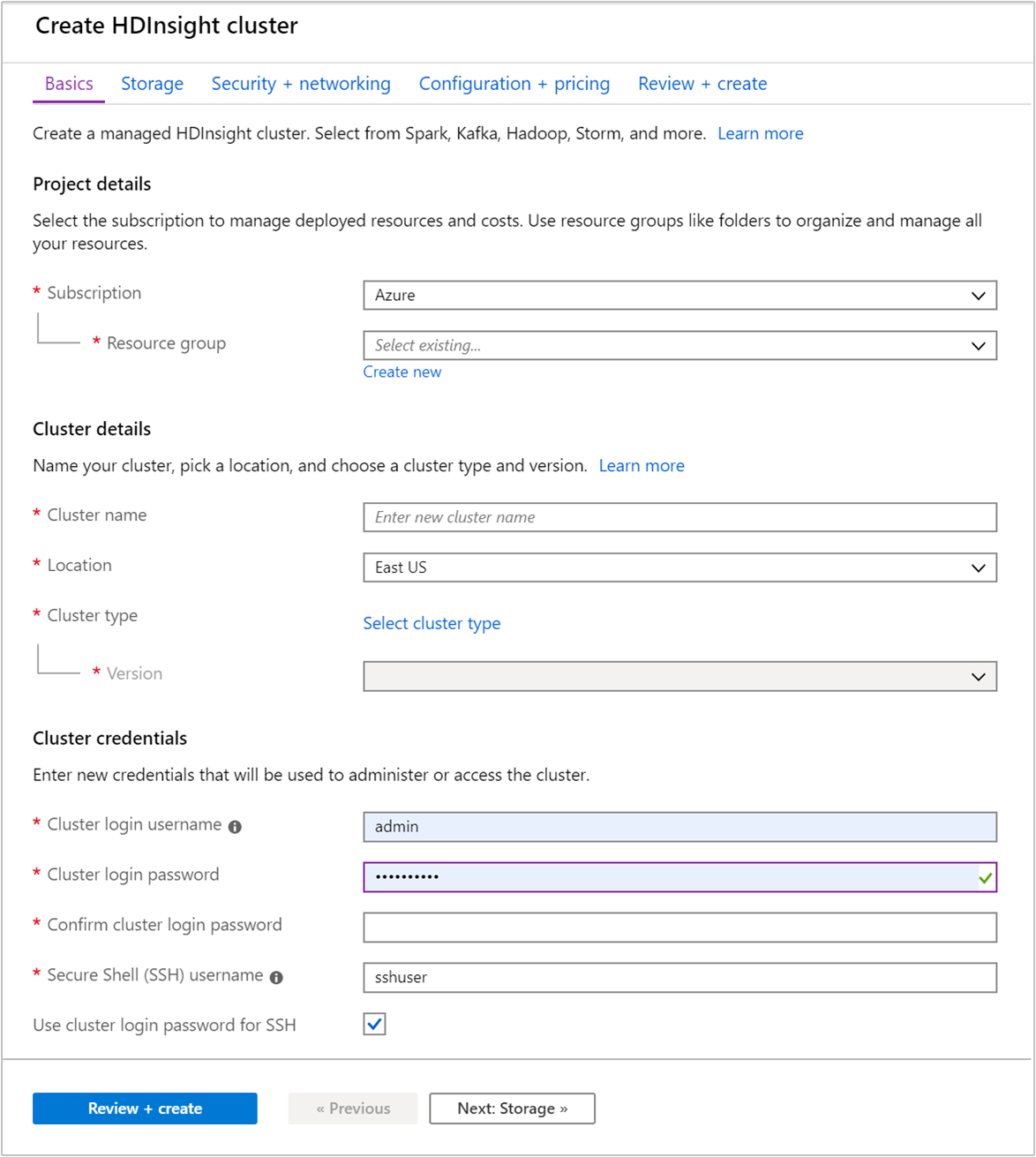
Elke Azure-regio (locatie) heeft foutdomeinen. Een foutdomein is een logische groepering van de onderliggende hardware in een Azure-datacenter. Elk foutdomein deelt een algemene voedingsbron en netwerkswitch. De virtuele machines en beheerde schijven die de knooppunten in een HDInsight-cluster implementeren zijn verdeeld over deze foutdomeinen. Deze architectuur beperkt de potentiële impact van problemen met de fysieke hardware.
Voor hoge beschikbaarheid van gegevens wordt u geadviseerd om een regio (locatie) te selecteren die drie foutdomeinen heeft. Raadpleeg het document Beschikbaarheid van virtuele Linux-machines voor informatie over het aantal foutdomeinen in een regio.
Selecteer het tabblad Volgende: Opslag >> om naar de opslaginstellingen te gaan.
Geef op het tabblad Opslag de volgende waarden op:
Eigenschappen Beschrijving Type van primaire opslag Gebruik de standaardwaarde Azure Storage. Selectiemethode Gebruik de standaardwaarde Selecteer in lijst. Primair opslagaccount Gebruik de vervolgkeuzelijst om een bestaand opslagaccount te selecteren of selecteer Nieuwe maken. Als u een nieuw account maakt, moet de naam 3 tot 24 tekens lang zijn en mag deze alleen cijfers en kleine letters bevatten Container Gebruik de waarde die automatisch is ingevuld. 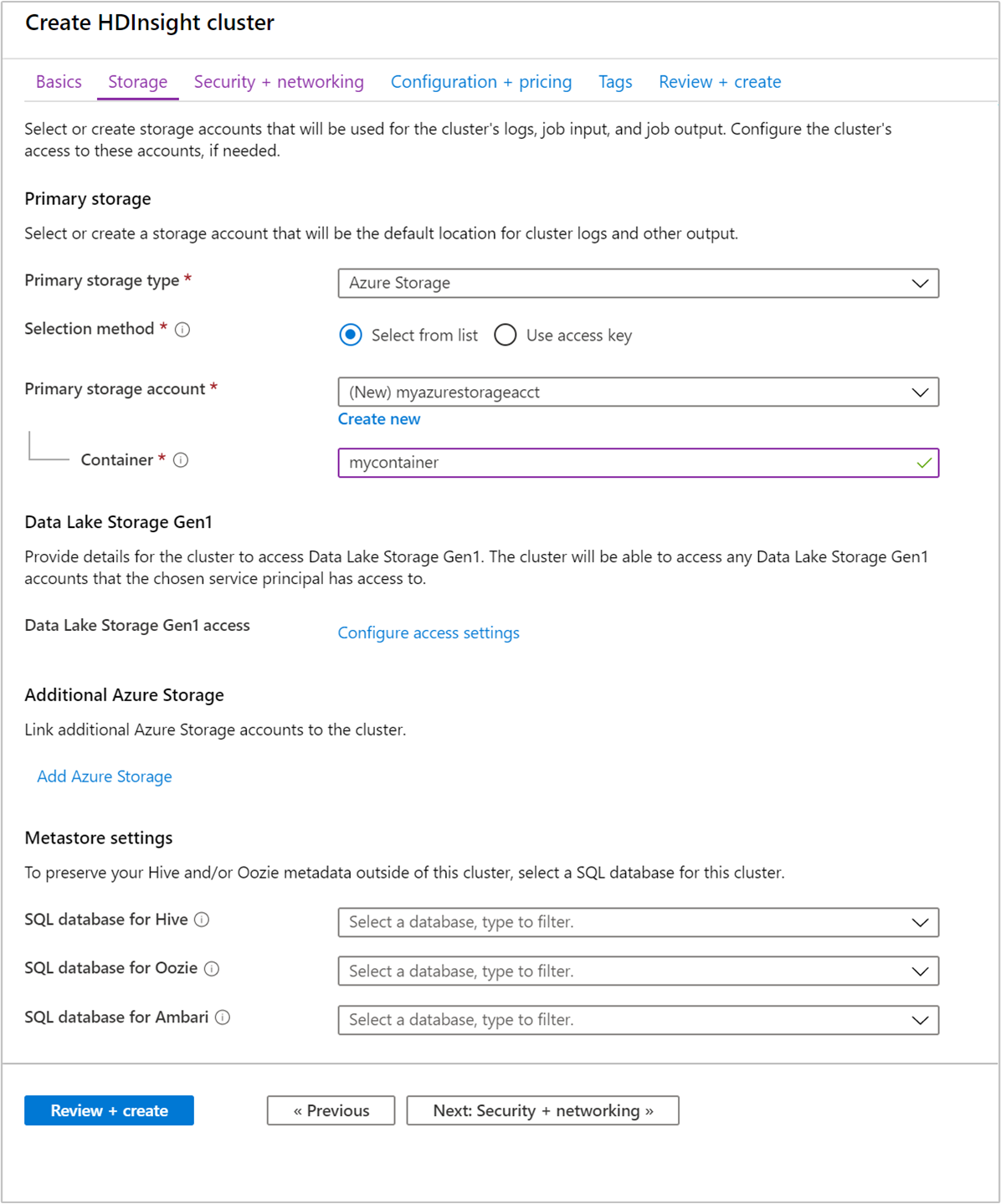
Selecteer het tabblad Beveiliging en netwerken.
Laat voor deze quickstart de standaardbeveiligingsinstellingen staan. Ga naar Een HDInsight-cluster configureren met Enterprise Security Package met behulp van Microsoft Entra Domain Services voor meer informatie over Enterprise Security Package. Ga naar Schijfversleuteling met door de klant beheerde sleutels voor informatie over het gebruik van uw eigen sleutel voor Apache Kafka Disk Encryption.
Als u uw cluster verbinding wilt laten maken met een virtueel netwerk, selecteert u een virtueel netwerk in de vervolgkeuzelijst Virtueel netwerk.
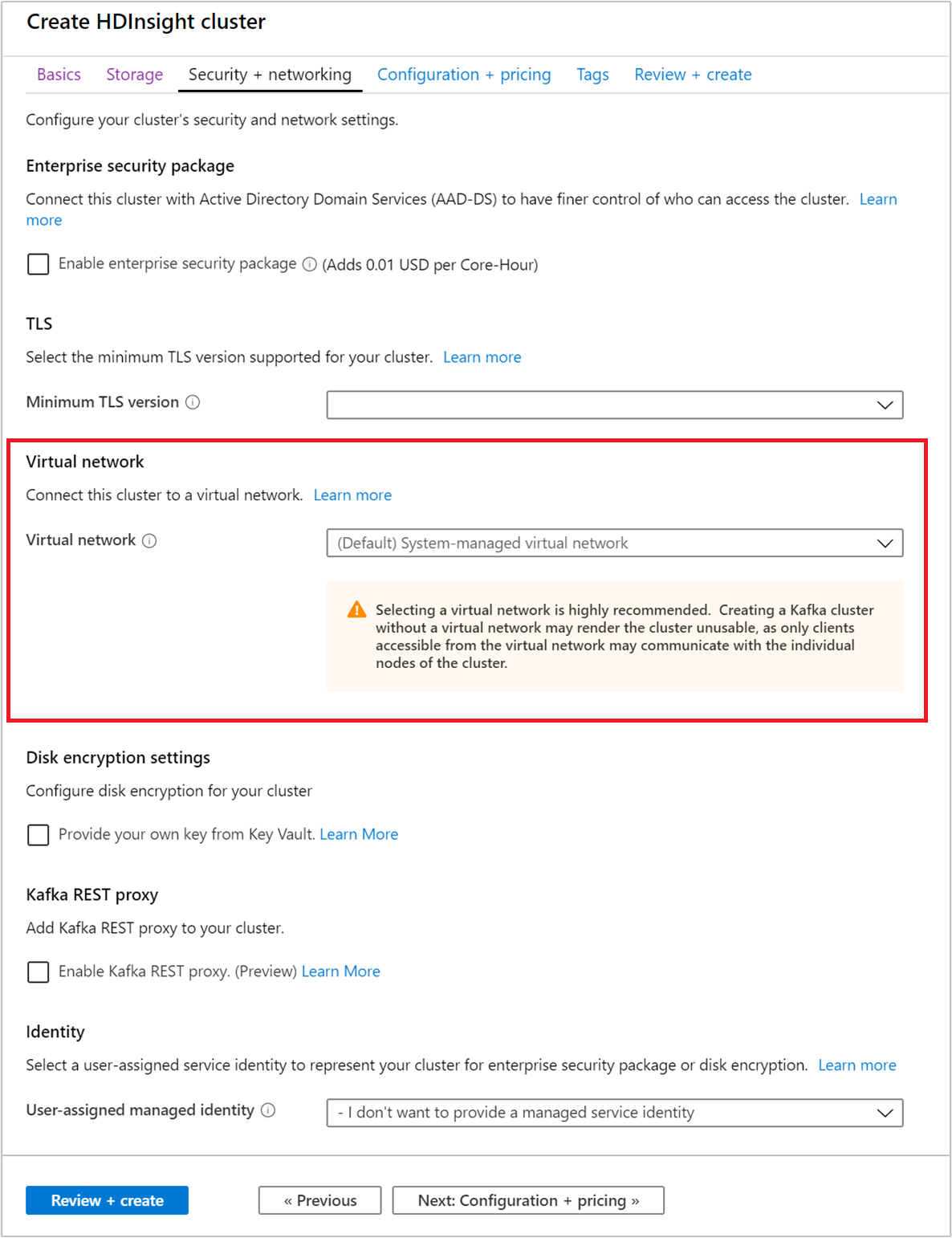
Selecteer het tabblad Configuratie en prijzen.
Om de beschikbaarheid van Apache Kafka in HDInsight te waarborgen, moet u het aantal werkknooppunten voor het werkknooppunt instellen op minimaal 3. De standaardwaarde is 4.
Met de waarde voor Standard-schijven per werkknooppunt wordt de schaalbaarheid van Apache Kafka in HDInsight geconfigureerd. Apache Kafka in HDInsight gebruikt de lokale schijf van de virtuele machines in het cluster voor het opslaan van gegevens. Omdat Apache Kafka veel gebruikmaakt van invoer/uitvoer, wordt Azure Managed Disks gebruikt voor een hoge doorvoer en meer opslag per knooppunt. Het type beheerde schijf is Standaard (HDD) of Premium (SSD). Het type schijf is afhankelijk van de VM-grootte die wordt gebruikt door de werkknooppunten (Apache Kafka-brokers). Premium-schijven worden automatisch gebruikt met VM's uit de DS- en GS-serie. Alle andere VM-typen gebruiken standaardschijven.
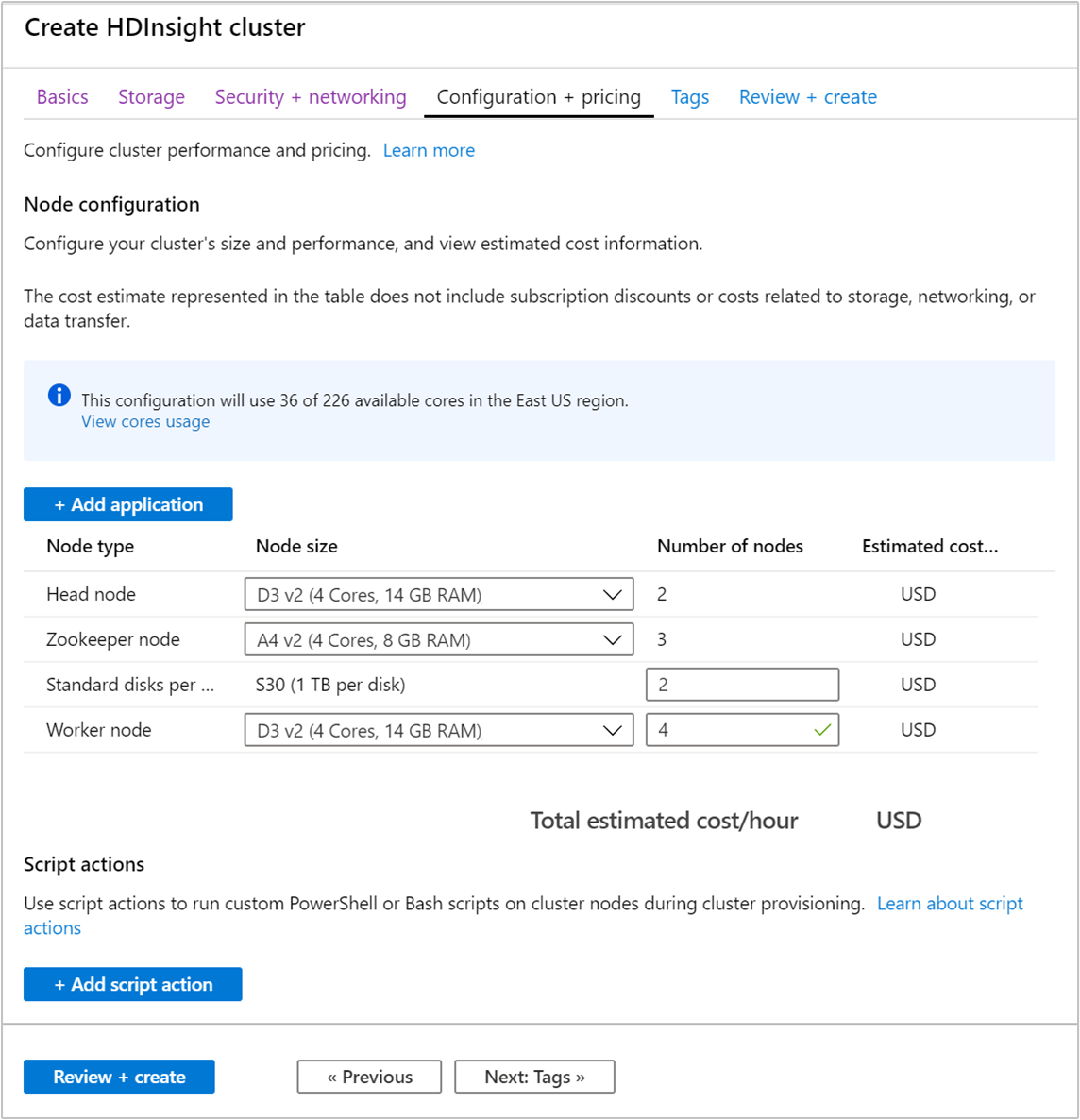
Selecteer het tabblad Beoordelen en maken.
Controleer de configuratie van het cluster. Wijzig onjuiste instellingen. Selecteer als laatste Maken om het cluster te maken.
Het kan tot 20 minuten duren om het cluster te maken.
Verbinding maken met het cluster
Gebruik de ssh-opdracht om verbinding te maken met uw cluster. Bewerk de onderstaande opdracht door CLUSTERNAME te vervangen door de naam van uw cluster. Voer vervolgens deze opdracht in:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVoer het wachtwoord voor de SSH-gebruiker in wanneer hierom wordt gevraagd.
Zodra er verbinding is gemaakt, ziet u informatie die er ongeveer als volgt uitziet:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Informatie over de Apache Zookeeper- en Broker-hosts ophalen
Als u met Kafka werkt, moet u de Zookeeper- en Broker-hosts kennen. Deze hosts worden gebruikt met de Apache Kafka-API en veel van de hulpprogramma's die bij Kafka worden meegeleverd.
In deze sectie vraagt u de hostgegevens op uit de Apache Ambari REST API in het cluster.
Installeer jq, een opdrachtregel-JSON-processor. Dit hulpprogramma wordt gebruikt om JSON-documenten te parseren en is handig bij het parseren van de hostgegevens. Voer in de open SSH-verbinding de volgende opdracht in om
jqte installeren:sudo apt -y install jqwachtwoordvariabele instellen. Vervang
PASSWORDdoor het aanmeldwachtwoord voor het cluster en voer de volgende opdracht in:export PASSWORD='PASSWORD'Extraheer de clusternaam met de juiste letters. De daadwerkelijke lettergrootte van de clusternaam kan anders zijn dan verwacht, afhankelijk van hoe het cluster is gemaakt. Met deze opdracht wordt de daadwerkelijke lettergrootte opgehaald en opgeslagen in een variabele. Voer de volgende opdracht in:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Notitie
Als u dit proces van buiten het cluster uitvoert, is er een andere procedure voor het opslaan van de clusternaam. Haal de clusternaam op in kleine letters uit de Azure-portal. Vervang vervolgens de clusternaam voor
<clustername>in de volgende opdracht en voer deze uit:export clusterName='<clustername>'.Gebruik de onderstaande opdracht om een omgevingsvariabele in te stellen met hostinformatie van Zookeeper. Met de opdracht worden alle Zookeeper-hosts opgehaald, waarna alleen de eerste twee vermeldingen worden geretourneerd. De reden hiervoor is dat u een bepaalde mate van redundantie wilt voor het geval één host onbereikbaar is.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Notitie
Voor deze opdracht is toegang tot Ambari vereist. Als uw cluster zich achter een NSG bevindt, voert u deze opdracht uit vanaf een computer die toegang heeft tot Ambari.
Gebruik de volgende opdracht om te controleren of de omgevingsvariabele juist is ingesteld:
echo $KAFKAZKHOSTSMet deze opdracht wordt informatie geretourneerd die lijkt op de volgende tekst:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Gebruik de volgende opdracht om een omgevingsvariabele in te stellen met brokerhostinformatie van Apache Kafka:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Notitie
Voor deze opdracht is toegang tot Ambari vereist. Als uw cluster zich achter een NSG bevindt, voert u deze opdracht uit vanaf een computer die toegang heeft tot Ambari.
Gebruik de volgende opdracht om te controleren of de omgevingsvariabele juist is ingesteld:
echo $KAFKABROKERSMet deze opdracht wordt informatie geretourneerd die lijkt op de volgende tekst:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Apache Kafka-onderwerpen beheren
Kafka slaat gegevensstromen op in zogenaamde onderwerpen (topics). U kunt het hulpprogramma kafka-topics.sh gebruiken om onderwerpen te beheren.
Als u een onderwerp wilt maken, gebruikt u de volgende opdracht in de SSH-verbinding:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSMet deze opdracht wordt verbinding gemaakt met Broker met behulp van de hostgegevens die zijn opgeslagen in
$KAFKABROKERS. Vervolgens wordt er een Apache Kafka-onderwerp gemaakt met de naam test.Gegevens die zijn opgeslagen in dit onderwerp worden gepartitioneerd in acht partities.
Elke partitie wordt gerepliceerd naar drie werkknooppunten in het cluster.
Als u het cluster hebt gemaakt in een Azure-regio met drie foutdomeinen, gebruikt u een replicatiefactor van drie. Gebruik anders een replicatiefactor van vier.
In regio's met drie foutdomeinen zorgt een replicatiefactor van drie ervoor dat replica's worden verdeeld over de foutdomeinen. In regio's met twee foutdomeinen zorgt een replicatiefactor van vier ervoor dat replica's worden verdeeld over de domeinen.
Raadpleeg het document Beschikbaarheid van virtuele Linux-machines voor informatie over het aantal foutdomeinen in een regio.
Apache Kafka kan niet overweg met Azure-foutdomeinen. Bij het maken van partitiereplica's voor onderwerpen worden replica's mogelijk niet goed gedistribueerd voor hoge beschikbaarheid.
Gebruik het partitieherverdelingsprogramma van Apache Kafka voor gegarandeerde hoge beschikbaarheid. Dit hulpprogramma moet vanuit een SSH-verbinding naar het hoofdknooppunt van het Apache Kafka-cluster worden uitgevoerd.
Om de hoogst mogelijke beschikbaarheid van uw Apache Kafka-gegevens te waarborgen, moet u de partitiereplica's voor uw onderwerp opnieuw indelen wanneer:
U een nieuw onderwerp of nieuwe partitie maakt
U een cluster omhoog schaalt
Gebruik de volgende opdracht om een lijst met onderwerpen op te vragen:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSMet deze opdracht worden de onderwerpen weergegeven die beschikbaar zijn in het Apache Kafka-cluster.
Gebruik de volgende opdracht om een onderwerp te verwijderen:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSMet deze opdracht verwijdert u het onderwerp met de naam
topicname.Waarschuwing
Als u het onderwerp
testverwijdert dat u eerder hebt gemaakt, moet u het opnieuw maken. Het onderwerp wordt namelijk gebruikt in stappen verderop in dit document.
Gebruik de volgende opdracht voor meer informatie over de opdrachten die beschikbaar zijn met het hulpprogramma kafka-topics.sh:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Records maken en gebruiken
Kafka slaat records op in onderwerpen. Records worden geproduceerd door producenten en worden gebruikt door consumenten. Producenten en consumenten communiceren met de Kafka-brokerservice. Elk werkknooppunt in uw HDInsight-cluster is een Apache Kafka-brokerhost.
Gebruik de volgende stappen om records op te slaan in het testonderwerp dat u eerder hebt gemaakt. Lees deze vervolgens met behulp van een verbruiker:
Als u records wilt wegschrijven naar het onderwerp, gebruikt u het hulpprogramma
kafka-console-producer.shvanuit de SSH-verbinding:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testNa deze opdracht komt u aan bij een lege regel.
Typ een tekstbericht op de lege regel en druk op Enter. Voer op deze manier enkele berichten in en gebruik vervolgens Ctrl+C om terug te keren naar de normale prompt. Elke regel wordt als afzonderlijke record naar het Apache Kafka-onderwerp verzonden.
Als u records wilt lezen uit het onderwerp, gebruikt u het hulpprogramma
kafka-console-consumer.shvanuit de SSH-verbinding:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningMet deze opdracht haalt u de records van het onderwerp op en geeft u deze weer. Met
--from-beginningwordt de consument gevraagd om bij het begin van de stream te beginnen, zodat alle records worden opgehaald.Vervang
--bootstrap-server $KAFKABROKERSdoor--zookeeper $KAFKAZKHOSTSals u een oudere versie van Kafka gebruikt.Gebruik Ctrl + C om de consument te stoppen.
U kunt ook programmatisch producenten en consumenten maken. Zie het document Producer and Consumer API van Apache Kafka met HDInsight voor een voorbeeld van het gebruik van deze API.
Resources opschonen
Als u de resources die in deze snelstart zijn gemaakt, wilt opschonen, verwijdert u de resourcegroep. Als u de resourcegroep verwijdert, worden ook het bijbehorende HDInsight-cluster en eventuele andere resources die aan de resourcegroep zijn gekoppeld, verwijderd.
Ga als volgt te werk om de resourcegroep te verwijderen in Azure Portal:
- Vouw het menu aan de linkerkant in Azure Portal uit om het menu met services te openen en kies Resourcegroepen om de lijst met resourcegroepen weer te geven.
- Zoek de resourcegroep die u wilt verwijderen en klik met de rechtermuisknop op de knop Meer (... ) aan de rechterkant van de vermelding.
- Selecteer Resourcegroep verwijderen en bevestig dit.
Waarschuwing
Door een Apache Kafka-cluster in HDInsight te verwijderen, worden alle gegevens verwijderd die zijn opgeslagen in Kafka.