LLMOps-werkstromen in Azure Databricks
Dit artikel vormt een aanvulling op MLOps-werkstromen in Databricks door informatie toe te voegen die specifiek is voor LLMOps-werkstromen. Zie The Big Book of MLOps voor meer informatie.
Hoe verandert de MLOps-werkstroom voor LLM's?
LLM's zijn een klasse NLP-modellen (Natural Language Processing) die hun voorafgaande taken aanzienlijk hebben overschreden in verschillende taken, zoals het beantwoorden van open vragen, samenvatting en uitvoering van instructies.
Ontwikkeling en evaluatie van LLM's verschillen op een aantal belangrijke manieren van traditionele ML-modellen. In deze sectie vindt u een kort overzicht van enkele belangrijke eigenschappen van LLM's en de gevolgen voor MLOps.
| Belangrijkste eigenschappen van LLM's | Gevolgen voor MLOps |
|---|---|
| LLM's zijn beschikbaar in veel formulieren. - Algemene bedrijfseigen en OSS-modellen die worden geopend met behulp van betaalde API's. - Opensource-modellen buiten de plank die variëren van algemeen tot specifieke toepassingen. - Aangepaste modellen die zijn afgestemd op specifieke toepassingen. - Aangepaste vooraf getrainde toepassingen. |
Ontwikkelingsproces: Projecten ontwikkelen vaak stapsgewijs, beginnend met bestaande, externe of opensource-modellen en eindigend met aangepaste, afgestemde modellen. |
| Veel LLM's gebruiken algemene query's en instructies in natuurlijke taal als invoer. Deze query's kunnen zorgvuldig ontworpen prompts bevatten om de gewenste antwoorden te genereren. |
Ontwikkelingsproces: Het ontwerpen van tekstsjablonen voor het uitvoeren van query's op LLM's is vaak een belangrijk onderdeel van het ontwikkelen van nieuwe LLM-pijplijnen. ML-artefacten verpakken: veel LLM-pijplijnen maken gebruik van bestaande LLM's of LLM-servereindpunten. De ML-logica die voor deze pijplijnen is ontwikkeld, kan zich richten op promptsjablonen, agents of ketens in plaats van het model zelf. De ML-artefacten die zijn verpakt en naar productie zijn gepromoveerd, kunnen deze pijplijnen zijn, in plaats van modellen. |
| Veel LLM's kunnen prompts krijgen met voorbeelden, context of andere informatie om de query te beantwoorden. | Infrastructuur leveren: bij het uitbreiden van LLM-query's met context, kunt u aanvullende hulpprogramma's zoals vectordatabases gebruiken om te zoeken naar relevante context. |
| API's van derden bieden eigen en opensource-modellen. | API-governance: Gecentraliseerd API-governance gebruiken biedt de mogelijkheid om eenvoudig te schakelen tussen API-providers. |
| LLM's zijn zeer grote Deep Learning-modellen, vaak variërend van gigabytes tot honderden gigabytes. |
Infrastructuur bedienen: LLM's vereisen mogelijk GPU's voor realtime modelservers en snelle opslag voor modellen die dynamisch moeten worden geladen. Kosten-/prestatie-compromissen: omdat grotere modellen meer rekenkracht vereisen en duurder zijn, zijn technieken voor het verminderen van de modelgrootte en berekening mogelijk vereist. |
| LLM's zijn moeilijk te evalueren met behulp van traditionele ML-metrische gegevens, omdat er vaak geen enkel 'juiste' antwoord is. | Menselijke feedback: Menselijke feedback is essentieel voor het evalueren en testen van LLM's. U moet feedback van gebruikers rechtstreeks opnemen in het MLOps-proces, inclusief voor testen, bewaking en toekomstige afstemming. |
Commonalities tussen MLOps en LLMOps
Veel aspecten van MLOps-processen veranderen niet voor LLM's. De volgende richtlijnen zijn bijvoorbeeld ook van toepassing op LLM's:
- Gebruik afzonderlijke omgevingen voor ontwikkeling, fasering en productie.
- Gebruik Git voor versiebeheer.
- Beheer modelontwikkeling met MLflow en gebruik Modellen in Unity Catalog om de levenscyclus van het model te beheren.
- Gegevens opslaan in een Lakehouse-architectuur met behulp van Delta tables.
- Uw bestaande CI/CD-infrastructuur mag geen wijzigingen vereisen.
- De modulaire structuur van MLOps blijft hetzelfde, met pijplijnen voor featurization, modeltraining, modeldeductie, enzovoort.
Referentiearchitectuurdiagrammen
In deze sectie worden twee LLM-toepassingen gebruikt om enkele van de aanpassingen aan de referentiearchitectuur van traditionele MLOps te illustreren. De diagrammen tonen de productiearchitectuur voor 1) een rag-toepassing (ophalen-augmented generation) met behulp van een API van derden en 2) een RAG-toepassing met behulp van een zelf-hostend, verfijnd model. Beide diagrammen geven een optionele vectordatabase weer. Dit item kan worden vervangen door rechtstreeks een query uit te voeren op de LLM via het eindpunt voor modelverdiening.
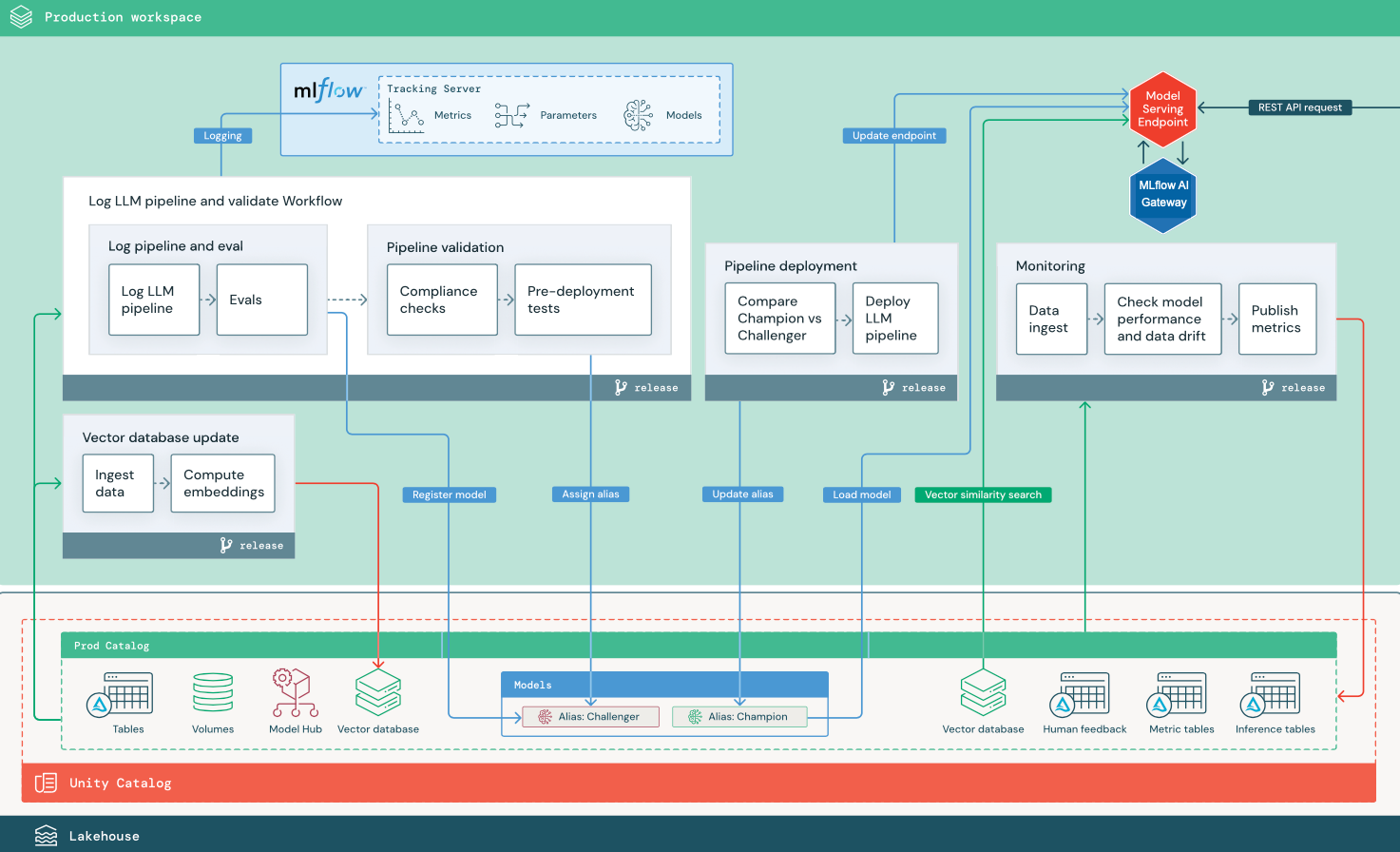
RAG met een LLM-API van derden
In het diagram ziet u een productiearchitectuur voor een RAG-toepassing die verbinding maakt met een LLM-API van derden met behulp van externe Databricks-modellen.
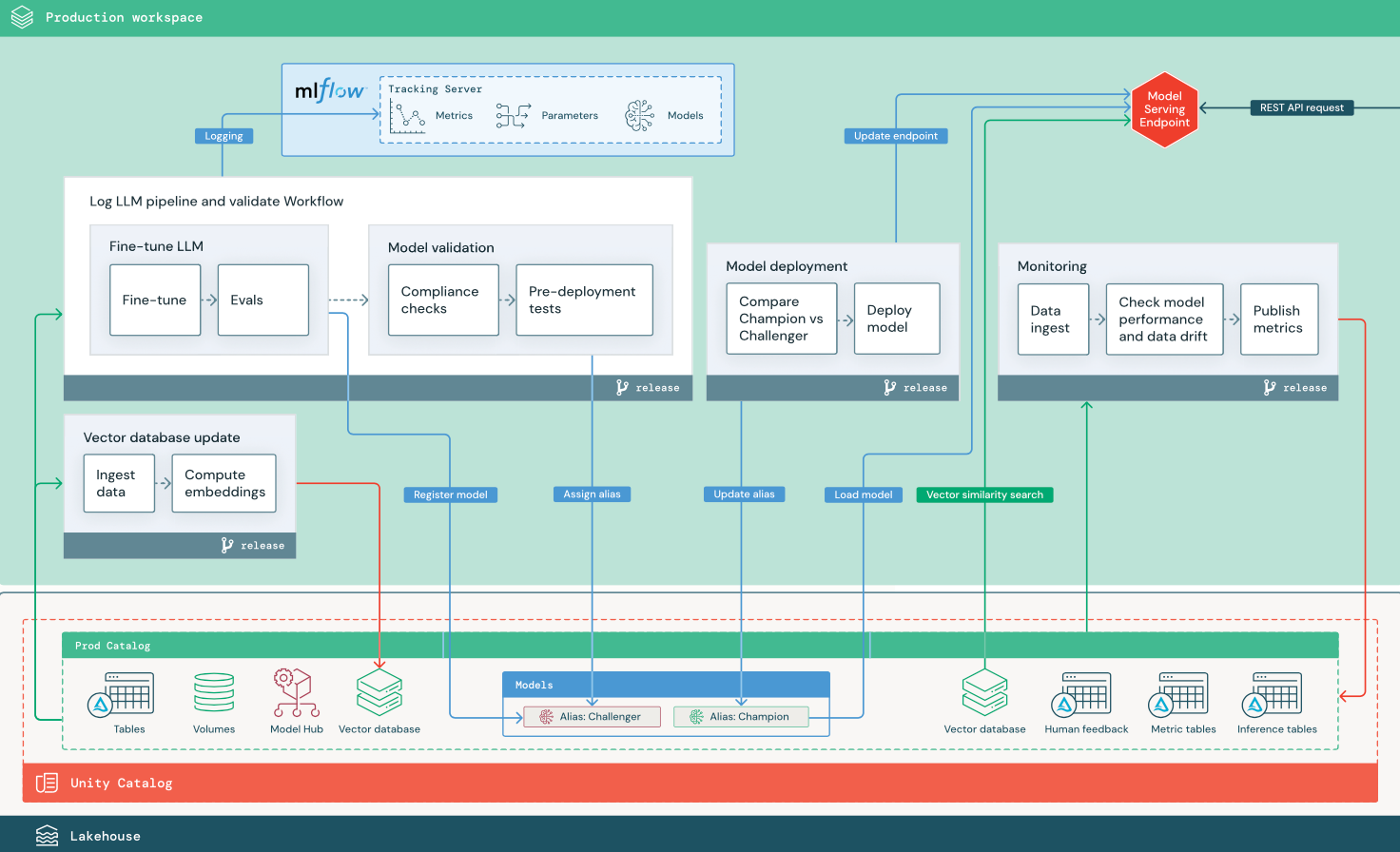
RAG met een verfijnd opensource-model
In het diagram ziet u een productiearchitectuur voor een RAG-toepassing waarmee een opensource-model wordt verfijnd.
LLMOps-wijzigingen in mlOps-productiearchitectuur
In deze sectie worden de belangrijkste wijzigingen in de MLOps-referentiearchitectuur voor LLMOps-toepassingen gemarkeerd.
Modelhub
LLM-toepassingen maken vaak gebruik van bestaande, vooraf getrainde modellen die zijn geselecteerd vanuit een interne of externe modelhub. Het model kan als zodanig worden gebruikt of nauwkeurig worden afgestemd.
Databricks bevat een selectie van hoogwaardige, vooraf getrainde basismodellen in Unity Catalog en in Databricks Marketplace. U kunt deze vooraf getrainde modellen gebruiken om toegang te krijgen tot geavanceerde AI-mogelijkheden, zodat u tijd en kosten bespaart voor het bouwen van uw eigen aangepaste modellen. Zie Vooraf getrainde modellen in Unity Catalog en Marketplacevoor meer informatie.
Vectordatabase
Sommige LLM-toepassingen maken gebruik van vectordatabases voor snelle overeenkomsten, bijvoorbeeld om context- of domeinkennis te bieden in LLM-query's. Databricks biedt een geïntegreerde vectorzoekfunctionaliteit waarmee u delta-table in Unity Catalog als vectordatabase kunt gebruiken. De vectorzoekindex wordt automatisch gesynchroniseerd met de Delta-table. Zie Vector Search voor meer informatie.
U kunt een modelartefact maken waarmee de logica wordt ingekapseld om informatie op te halen uit een vectordatabase en die de geretourneerde gegevens als context aan de LLM levert. Vervolgens kunt u het model registreren met behulp van de MLflow LangChain- of PyFunc-modelmaak.
LLM verfijnen
Omdat LLM-modellen duur en tijdrovend zijn om helemaal opnieuw te maken, verfijnen LLM-toepassingen vaak een bestaand model om de prestaties in een bepaald scenario te verbeteren. In de referentiearchitectuur worden verfijning en modelimplementatie weergegeven als afzonderlijke Databricks-taken. Het valideren van een nauwkeurig afgestemd model voordat u implementeert, is vaak een handmatig proces.
Databricks biedt Foundation Model Fine-tuning, waarmee u uw eigen gegevens kunt gebruiken om een bestaande LLM aan te passen en de prestaties voor uw specifieke toepassing te optimize. Zie Foundation Model Fine-tuning voor meer informatie.
Modellering
In de RAG met behulp van een API-scenario van derden is een belangrijke architectonische wijziging dat de LLM-pijplijn externe API-aanroepen uitvoert, van het eindpunt modelverdiening naar interne of EXTERNE LLM-API's. Dit voegt complexiteit, mogelijke latentie en extra referentiebeheer toe.
Databricks biedt Mosaic AI Model Serving, dat een geïntegreerde interface biedt voor het implementeren, beheren en opvragen van AI-modellen. Zie Mosaic AI Model Serving voor meer informatie.
Menselijke feedback bij bewaking en evaluatie
Menselijke feedbacklussen zijn essentieel in de meeste LLM-toepassingen. Menselijke feedback moet worden beheerd als andere gegevens, idealiter opgenomen in bewaking op basis van bijna realtime streaming.
De app Mosaic AI Agent Framework-beoordeling helpt u bij het verzamelen van feedback van menselijke revisoren. Voor meer informatie, zie Get feedback over de kwaliteit van een agentische toepassing.