AI Gateway configureren op model voor eindpunten
In dit artikel leert u hoe u Mosaic AI Gateway configureert op een model dat het eindpunt bedient.
Vereisten
- Een Databricks-werkruimte in een externe modellen die worden ondersteund of ingerichte doorvoer ondersteunde regio.
- Een model dat eindpunt bedient.
- Als u een eindpunt voor externe modellen wilt maken, voert u stap 1 en 2 van Een extern model maken voor eindpunten.
- Zie Provisioned Throughput Foundation Model API'svoor het maken van een eindpunt voor ingerichte doorvoer.
AI Gateway configureren met behulp van de gebruikersinterface
In deze sectie wordt beschreven hoe u AI Gateway configureert tijdens het maken van het eindpunt met behulp van de gebruikersinterface van de server. Als u dit liever programmatisch doet, raadpleegt u het notebookvoorbeeld.
In de sectie AI Gateway van de pagina voor het maken van eindpunten kunt u AI Gateway-functies afzonderlijk configureren. Zie Ondersteunde functies waarvoor functies beschikbaar zijn op extern model voor eindpunten en ingerichte doorvoereindpunten.
| Functie | Inschakelen | DETAILS |
|---|---|---|
| Gebruik bijhouden | Selecteer Schakel gebruiksregistratie in om gegevensstatistieken bij te houden en te controleren. | - U moet Unity Catalog hebben ingeschakeld. - Accountbeheerders moeten het systeemtabelschema inschakelen voordat ze de systeemtabellen gebruiken: system.serving.endpoint_usage waarmee tokenaantallen worden vastgelegd voor elke aanvraag naar het eindpunt en system.serving.served_entities waarin metagegevens voor elk basismodel worden opgeslagen.- Zie tabelschema's voor het bijhouden van gebruik - Alleen accountbeheerders zijn gemachtigd om de served_entities tabel of endpoint_usage tabel weer te geven of op te vragen, ook al moet de gebruiker die het eindpunt beheert, gebruik bijhouden inschakelen. Zie Toegang verlenen tot systeemtabellen- Het aantal invoer- en uitvoertoken wordt geschat als ( text_length+1)/4 als het tokenaantal niet door het model wordt geretourneerd. |
| Logboekregistratie van nettolading | Selecteer Inferentietabellen inschakelen om automatisch verzoeken en antwoorden van uw eindpunt te registreren in Delta-tabellen die worden beheerd door Unity Catalog. | - U moet Unity Catalog hebben ingeschakeld en CREATE_TABLE toegang hebben in het opgegeven catalogusschema.- Inferentietabellen die zijn ingeschakeld door AI Gateway hebben een ander schema dan inferentietabellen die zijn gemaakt voor modelbedienings-eindpunten die aangepaste modellen ondersteunen. Zie deductietabelschema met AI Gateway-functionaliteit. - Logboekregistratiegegevens van nettolading vullen deze tabellen minder dan een uur na het uitvoeren van een query op het eindpunt. - Nettoladingen die groter zijn dan 1 MB, worden niet geregistreerd. - De nettolading van het antwoord aggregeert het antwoord van alle geretourneerde segmenten. - Streaming wordt ondersteund. In streamingscenario's vat de antwoordlading het antwoord van de geretourneerde segmenten samen. |
| AI-kaders | Zie AI-kaders configureren in de gebruikersinterface. | - Kaders voorkomen dat het model communiceert met onveilige en schadelijke inhoud die wordt gedetecteerd in modelinvoer en -uitvoer. - Uitvoerbeveiligingen worden niet ondersteund voor het insluiten van modellen of voor streaming. |
| Frequentielimieten | U kunt aanvraagfrequentielimieten afdwingen om verkeer voor uw eindpunt per gebruiker en per eindpunt te beheren | - Frequentielimieten worden gedefinieerd in query's per minuut (QPM). - De standaardwaarde is Geen limiet voor zowel per gebruiker als per eindpunt. |
| Verkeersroutering | Zie Meerdere externe modellen naar een eindpunt gebruiken om verkeersroutering op uw eindpunt te configureren. |
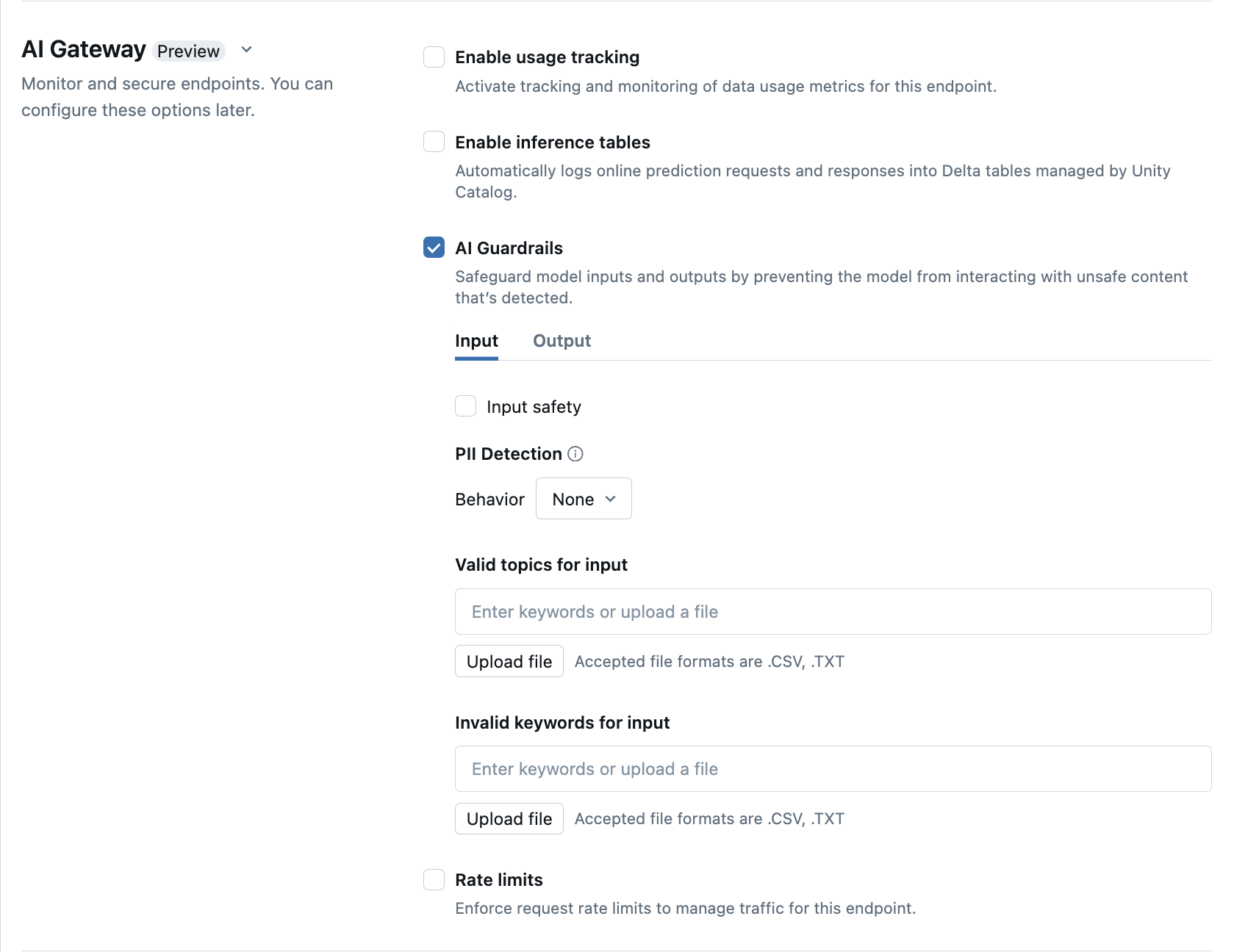
AI-kaders configureren in de gebruikersinterface
In de volgende tabel ziet u hoe u ondersteunde kadersconfigureert.
| Veiligheidsrail | Inschakelen | DETAILS |
|---|---|---|
| Veiligheid | Selecteer Safety om beveiliging in te schakelen om te voorkomen dat uw model communiceert met onveilige en schadelijke inhoud. | |
| Detectie van persoonsgegevens (PII) | Selecteer PII-detectie om PII-gegevens te detecteren, zoals namen, adressen, creditcardnummers. | |
| Geldige onderwerpen | U kunt onderwerpen rechtstreeks in dit veld typen. Als u meerdere items hebt, moet u na elk onderwerp op Enter drukken. U kunt ook een .csv of .txt meer bestanden uploaden. |
Er kunnen maximaal 50 geldige onderwerpen worden opgegeven. Elk onderwerp mag niet langer zijn dan 100 tekens |
| Ongeldige trefwoorden | U kunt onderwerpen rechtstreeks in dit veld typen. Als u meerdere items hebt, moet u na elk onderwerp op Enter drukken. U kunt ook een .csv of .txt meer bestanden uploaden. |
Er kunnen maximaal 50 ongeldige trefwoorden worden opgegeven. Elk trefwoord mag niet langer zijn dan 100 tekens. |
tabelschema's voor het bijhouden van gebruik
De system.serving.served_entities systeemtabel voor het bijhouden van gebruik heeft het volgende schema:
| Kolomnaam | Beschrijving | Type |
|---|---|---|
served_entity_id |
De unieke id van de service-entiteit. | STRING |
account_id |
De klantaccount-id voor Delta Sharing. | STRING |
workspace_id |
De werkruimte-id van de klant van het service-eindpunt. | STRING |
created_by |
De id van de maker. | STRING |
endpoint_name |
De naam van het servereindpunt. | STRING |
endpoint_id |
De unieke id van het service-eindpunt. | STRING |
served_entity_name |
De naam van de dienste entiteit. | STRING |
entity_type |
Type van de entiteit die wordt geleverd. Kan zijnFEATURE_SPEC, EXTERNAL_MODEL, of FOUNDATION_MODELCUSTOM_MODEL |
STRING |
entity_name |
De onderliggende naam van de entiteit. Anders dan een served_entity_name door de gebruiker opgegeven naam.
entity_name is bijvoorbeeld de naam van het Unity Catalog-model. |
STRING |
entity_version |
De versie van de entiteit geleverd. | STRING |
endpoint_config_version |
De versie van de eindpuntconfiguratie. | INT |
task |
Het taaktype. De waarde kan llm/v1/chat, llm/v1/completionsof llm/v1/embeddings zijn. |
STRING |
external_model_config |
Configuraties voor externe modellen. Bijvoorbeeld {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Configuraties voor basismodellen. Bijvoorbeeld{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
Configuraties voor aangepaste modellen. Bijvoorbeeld{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Configuraties voor functiespecificaties. Bijvoorbeeld { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Tijdstempel van wijziging voor de dienstentiteit. | TIMESTAMP |
endpoint_delete_time |
Tijdstempel van entiteitsverwijdering. Het eindpunt is de container voor de service-entiteit. Nadat het eindpunt is verwijderd, wordt de service-entiteit ook verwijderd. | TIMESTAMP |
De system.serving.endpoint_usage systeemtabel voor het bijhouden van gebruik heeft het volgende schema:
| Kolomnaam | Beschrijving | Type |
|---|---|---|
account_id |
De account-id van de klant. | STRING |
workspace_id |
De werkruimte-id van de klant van het service-eindpunt. | STRING |
client_request_id |
De gebruiker heeft de aanvraag-id opgegeven die kan worden opgegeven in de hoofdtekst van de aanvraag voor het model. | STRING |
databricks_request_id |
Een door Azure Databricks gegenereerde aanvraag-id die is gekoppeld aan alle aanvragen voor het verwerken van modellen. | STRING |
requester |
De id van de gebruiker of service-principal waarvan de machtigingen worden gebruikt voor de aanroepaanvraag van het service-eindpunt. | STRING |
status_code |
De HTTP-statuscode die is geretourneerd uit het model. | GEHEEL GETAL |
request_time |
De tijdstempel waarop de aanvraag wordt ontvangen. | TIMESTAMP |
input_token_count |
Het tokenaantal van de invoer. | LANG |
output_token_count |
Het tokenaantal van de uitvoer. | LANG |
input_character_count |
Het aantal tekens van de invoertekenreeks of prompt. | LANG |
output_character_count |
Het aantal tekens van de uitvoertekenreeks van het antwoord. | LANG |
usage_context |
De gebruiker heeft een kaart met id's van de eindgebruiker of de klanttoepassing opgegeven waarmee het eindpunt wordt aangeroepen. Zie Gebruik verder definiëren met usage_context. | MAP |
request_streaming |
Of de aanvraag zich in de stroommodus bevindt. | BOOLEAN |
served_entity_id |
De unieke ID die wordt gebruikt om te koppelen aan de system.serving.served_entities dimensietabel om informatie over het eindpunt en de bediende entiteit op te zoeken. |
STRING |
Gebruik verder definiëren met usage_context
Wanneer u een query uitvoert op een extern model waarvoor gebruikstracering is ingeschakeld, kunt u de parameter opgeven met het usage_context type Map[String, String]. De mapping van de gebruikscontext verschijnt in de gebruiksvolgorde tabel in de usage_context kolom. De usage_context kaartgrootte mag niet groter zijn dan 10 KiB.
Accountbeheerders kunnen verschillende rijen aggregeren op basis van de gebruikscontext om inzichten te verkrijgen en deze informatie te koppelen aan de informatie in de logtabel voor payload. U kunt bijvoorbeeld toevoegen end_user_to_charge aan de usage_context functie voor het bijhouden van kostentoeschrijving voor eindgebruikers.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
AI Gateway-functies op eindpunten bijwerken
U kunt AI Gateway-functies bijwerken op model-serveer-eindpunten waarop ze eerder waren ingeschakeld en op eindpunten waar dat niet het geval was. Het duurt ongeveer 20-40 seconden voordat updates voor AI Gateway-configuraties worden toegepast, maar het kan maximaal 60 seconden duren voordat updates worden beperkt.
Hieronder ziet u hoe u AI Gateway-functies bijwerkt op een model dat eindpunten bedient met behulp van de bedieningsinterface.
In de sectie Gateway van de eindpuntpagina kunt u zien welke functies zijn ingeschakeld. Als u deze functies wilt bijwerken, klikt u op AI Gateway-bewerken.
AI Gateway-functies 
Voorbeeld van notitieblok
In het volgende notebook ziet u hoe u programmatisch de functies van Databricks Mosaic AI Gateway kunt inschakelen en gebruiken om modellen van verschillende aanbieders te beheren en sturen. Zie het volgende voor REST API-details: