Deductietabellen voor bewakings- en foutopsporingsmodellen
Belangrijk
Deze functie is beschikbaar als openbare preview.
Belangrijk
In dit artikel worden onderwerpen beschreven die van toepassing zijn op deductietabellen voor aangepaste modellen. Gebruik voor externe modellen of geconfigureerde doorvoerworkloads AI Gateway-ingeschakelde inferentietabellen .
In dit artikel worden inferentietabellen beschreven voor het bewaken van bediende modellen. In het volgende diagram ziet u een typische werkstroom met deductietabellen. De deductietabel legt automatisch binnenkomende aanvragen en uitgaande antwoorden vast voor een model dat het eindpunt verwerkt en registreert deze als een Unity Catalog Delta-tabel. U kunt de gegevens in deze tabel gebruiken om ML-modellen te bewaken, fouten op te sporen en te verbeteren.
Inferentietabellenwerkstroom
Wat zijn deductietabellen?
Het bewaken van de prestaties van modellen in productiewerkstromen is een belangrijk aspect van de levenscyclus van HET AI- en ML-model. Deductietabellen vereenvoudigen bewaking en diagnostiek voor modellen door continu de aanvraaginvoer en -antwoorden (voorspellingen) vanaf Mosaic AI Model Serving-eindpunten te loggen en deze op te slaan in een Delta-tabel in Unity Catalog. Vervolgens kunt u alle mogelijkheden van het Databricks-platform gebruiken, zoals Databricks SQL-query's, notebooks en Lakehouse Monitoring om uw modellen te bewaken, fouten op te sporen en te optimaliseren.
U kunt deductietabellen inschakelen voor elk bestaand of nieuw gemaakt model voor eindpunten en aanvragen voor dat eindpunt worden vervolgens automatisch geregistreerd bij een tabel in UC.
Enkele algemene toepassingen voor deductietabellen zijn het volgende:
- Gegevens en modelkwaliteit bewaken. U kunt uw modelprestaties en gegevensdrift continu bewaken met Behulp van Lakehouse Monitoring. Lakehouse Monitoring genereert automatisch dashboards voor gegevens- en modelkwaliteit die u met belanghebbenden kunt delen. Daarnaast kunt u waarschuwingen inschakelen om te weten wanneer u uw model opnieuw moet trainen op basis van verschuivingen in binnenkomende gegevens of verminderingen van modelprestaties.
- Problemen met productie opsporen. Inferentietabellen loggen gegevens zoals HTTP-statuscodes, uitvoeringstijden van modellen en JSON-gegevens voor aanvragen en antwoorden. U kunt deze prestatiegegevens gebruiken voor foutopsporing. U kunt ook de historische gegevens in deductietabellen gebruiken om modelprestaties te vergelijken met historische aanvragen.
- Maak een trainingscorpus. Door deductietabellen samen te voegen met basiswaarlabels, kunt u een trainingslichaam maken dat u kunt gebruiken om uw model opnieuw te trainen of af te stemmen en te verbeteren. Met Databricks-taken kunt u een doorlopende feedbacklus instellen en het opnieuw trainen automatiseren.
Eisen
- Voor uw werkruimte moet Unity Catalog zijn ingeschakeld.
- Zowel de maker van het eindpunt als de modifier moet de machtiging Kan beheren hebben voor het eindpunt. Zie Toegangsbeheerlijsten.
- Zowel de maker van het eindpunt als de aanpasser moeten de volgende machtigingen hebben in Unity Catalog.
-
USE CATALOGmachtigingen voor de opgegeven catalogus. -
USE SCHEMAmachtigingen voor het opgegeven schema. -
CREATE TABLEmachtigingen in het schema.
-
Deductietabellen in- en uitschakelen
In deze sectie wordt beschreven hoe u deductietabellen kunt in- of uitschakelen met behulp van de Databricks-gebruikersinterface. U kunt ook de API gebruiken; zie Deductietabellen inschakelen voor model die eindpunten leveren met behulp van de API- voor instructies.
De eigenaar van de deductietabellen is de gebruiker die het eindpunt heeft gemaakt. Alle toegangsbeheerlijsten (ACL's) in de tabel volgen de standaardmachtigingen voor Unity Catalog en kunnen worden gewijzigd door de eigenaar van de tabel.
Waarschuwing
De deductietabel kan beschadigd raken als u een van de volgende handelingen uitvoert:
- Wijzig het tabelschema.
- Wijzig de tabelnaam.
- Verwijder de tabel.
- Machtigingen voor de Unity Catalog-catalogus of -schema verliezen.
In dit geval toont de auto_capture_config van de eindpuntstatus een FAILED status voor de payloadtabel. Als dit gebeurt, moet u een nieuw eindpunt maken om deductietabellen te blijven gebruiken.
Gebruik de volgende stappen om deductietabellen in te schakelen tijdens het maken van een eindpunt:
Klik op Serveren in de AI-gebruikersinterface van Databricks Mosaic.
Klik op Een service-eindpunt maken.
Selecteer Inferentietabellen inschakelen.
Selecteer in de vervolgkeuzelijsten de gewenste catalogus en het gewenste schema waarin u de tabel wilt plaatsen.
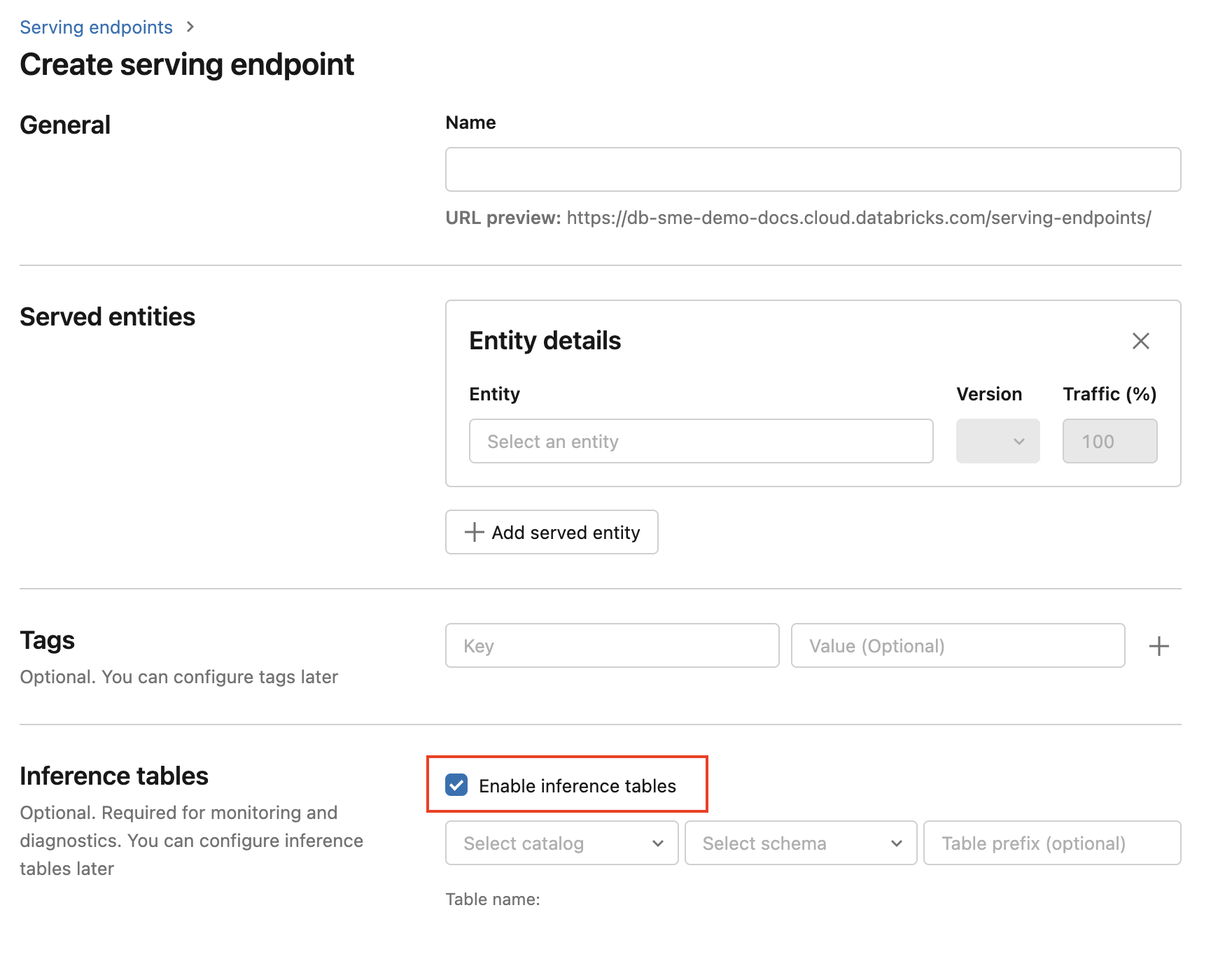
De standaardtabelnaam is
<catalog>.<schema>.<endpoint-name>_payload. Desgewenst kunt u een aangepast tabelvoorvoegsel invoeren.Klik op Een service-eindpunt maken.
U kunt deductietabellen ook inschakelen op een bestaand eindpunt. Ga als volgt te werk om een bestaande eindpuntconfiguratie te bewerken:
- Navigeer naar de eindpuntpagina.
- Klik op Configuratie bewerken.
- Volg de vorige instructies, te beginnen met stap 3.
- Wanneer u klaar bent, klikt u op Eindpunt bijwerken.
Volg deze instructies om deductietabellen uit te schakelen:
- Navigeer naar de eindpuntpagina.
- Klik op Configuratie bewerken.
- Klik op Inferentietabel inschakelen om het vinkje te verwijderen.
- Zodra u tevreden bent met de eindpuntspecificaties, klikt u op bijwerken.
werkstroom: modelprestaties bewaken met behulp van deductietabellen
Volg deze stappen om modelprestaties te bewaken met behulp van deductietabellen:
- Schakel inferentietabellen in op uw eindpunt, hetzij tijdens het maken van het eindpunt of door ze later bij te werken.
- Plan een workflow om de JSON-payloads in de inferentietabel te verwerken door ze uit te pakken volgens het eindpuntschema.
- (Optioneel) Voeg de uitgepakte aanvragen en antwoorden toe met basislabels voor waarheid, zodat metrische gegevens van de modelkwaliteit kunnen worden berekend.
- Maak een monitor over de resulterende Delta-tabel en vernieuw de metrische gegevens.
De startersnotebooks implementeren deze werkstroom.
Starter-notebook voor het monitoren van een inferentietabel
In het volgende notebook worden de bovenstaande stappen geïmplementeerd om verzoeken uit een Lakehouse Monitoring-infragetabel te verwerken. Het notebook kan op aanvraag worden uitgevoerd of volgens een periodiek schema met behulp van Databricks Jobs.
Startersnotitieblok voor inferentietabel Lakehouse Monitoring
Starter-notebook voor het monitoren van de tekstkwaliteit van eindpunten die worden gebruikt door LLM's.
In het volgende notebook worden aanvragen uit een deductietabel uitgepakt, wordt een set metrische gegevens voor tekstevaluatie berekend (zoals leesbaarheid en toxiciteit) en wordt bewaking van deze metrische gegevens mogelijk. Het notebook kan indien gewenst worden uitgevoerd of volgens een terugkerend schema met behulp van Databricks Jobs.
LLM-inferentietabel Lakehouse Monitoring Starter Notebook
Resultaten in de deductietabel opvragen en analyseren
Nadat uw aangeboden modellen gereed zijn, worden alle aanvragen die aan uw modellen worden gedaan, automatisch geregistreerd in de inferentietabel, samen met de reacties. U kunt de tabel in de gebruikersinterface bekijken, een query uitvoeren op de tabel vanuit DBSQL of een notebook of een query uitvoeren op de tabel met behulp van de REST API.
Als u de tabel in de gebruikersinterface wilt weergeven: Klik op de eindpuntpagina op de naam van de deductietabel om de tabel te openen in Catalog Explorer.

Om een query uit te voeren op de tabel vanuit DBSQL of een Databricks-notebook: U kunt code uitvoeren die vergelijkbaar is met het volgende om een query uit te voeren op de deductietabel.
SELECT * FROM <catalog>.<schema>.<payload_table>
Als u deductietabellen hebt ingeschakeld met behulp van de gebruikersinterface, is payload_table de tabelnaam die u hebt toegewezen toen u het eindpunt maakte. Als u deductietabellen hebt ingeschakeld met behulp van de API, wordt payload_table gerapporteerd in de sectie state van het auto_capture_config-antwoord. Zie voor een voorbeeld inferentietabellen inschakelen op modelserve-eindpunten met behulp van de API.
Prestatienotitie
Nadat u het eindpunt hebt aanroepen, ziet u dat de aanroep is geregistreerd bij de deductietabel binnen een uur na het verzenden van een scoreaanvraag. Bovendien garandeert Azure Databricks dat logboekbezorging ten minste één keer plaatsvindt, dus het is mogelijk, hoewel onwaarschijnlijk, dat er dubbele logboeken worden verzonden.
Unity Catalog-inferentietabelschema
Elke aanvraag en elk antwoord dat wordt geregistreerd bij een deductietabel, wordt geschreven naar een Delta-tabel met het volgende schema:
Notitie
Als u het eindpunt aanroept met een batch invoer, wordt de hele batch geregistreerd als één rij.
| Kolomnaam | Beschrijving | Type |
|---|---|---|
databricks_request_id |
Een door Azure Databricks gegenereerde aanvraag-id die is gekoppeld aan alle aanvragen voor het verwerken van modellen. | STRING |
client_request_id |
Een optionele aanvraag-id die door de client wordt gegenereerd en kan worden opgegeven in het aanvraagverzoek van de model-servicedienst. Zie Specificeer client_request_id voor meer informatie. |
STRING |
date |
De UTC-datum waarop de aanvraag voor het verwerken van het model is ontvangen. | DATUM |
timestamp_ms |
De tijdstempel in epoch milliseconden op het moment dat de aanvraag voor het verwerken van het model werd ontvangen. | LANG |
status_code |
De HTTP-statuscode die door het model is teruggegeven. | INT |
sampling_fraction |
De steekproeffractie die wordt gebruikt in het geval dat de aanvraag is uitgevallen. Deze waarde ligt tussen 0 en 1, waarbij 1 aangeeft dat 100% binnenkomende aanvragen zijn opgenomen. | DUBBEL |
execution_time_ms |
De uitvoeringstijd in milliseconden waarvoor het model deductie heeft uitgevoerd. Dit omvat geen overheadnetwerklatenties en vertegenwoordigt alleen de tijd die het model nodig heeft om voorspellingen te genereren. | LANG |
request |
De JSON-hoofdtekst van de onbewerkte aanvraag die is verzonden naar het eindpunt van de modelfunctie. | STRING |
response |
De onbewerkte antwoord-JSON-hoofdtekst die is geretourneerd door het model dat het eindpunt levert. | STRING |
request_metadata |
Een overzicht van metagegevens die verband houden met het modelserveerpunt dat aan het verzoek is gekoppeld. Deze kaart bevat de eindpuntnaam, modelnaam en modelversie die wordt gebruikt voor uw eindpunt. | Map<TEKENREEKS, TEKENREEKS> |
Specificeren client_request_id
Het client_request_id veld is een optionele waarde die de gebruiker kan opgeven in de hoofdtekst van de aanvraag voor het model. Hierdoor kan de gebruiker een eigen id opgeven voor een aanvraag die wordt weergegeven in de uiteindelijke inferentietabel onder de client_request_id en die kan worden gebruikt voor het samenvoegen van uw aanvraag met andere tabellen die gebruikmaken van de client_request_id, zoals het samenvoegen van grondwaarheidslabels. Om een client_request_id op te geven, neemt u deze op als een sleutel op toplevel van de aanvraagpayload. Als er geen client_request_id is opgegeven, wordt de waarde weergegeven als null in de rij die overeenkomt met de aanvraag.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
De client_request_id kan later worden gebruikt voor het samenvoegen van referentielabels, op voorwaarde dat er andere tabellen zijn met labels die zijn gekoppeld aan de client_request_id.
Beperkingen
- Door de klant beheerde sleutels worden niet ondersteund.
- Voor eindpunten die basismodellenhosten, worden deductietabellen alleen ondersteund voor ingerichte doorvoer workloads.
- Azure Firewall kan leiden tot fouten bij het maken van de Unity Catalog Delta-tabel, dus wordt niet standaard ondersteund. Neem contact op met uw Databricks-accountteam om dit in te schakelen.
- Wanneer deductietabellen zijn ingeschakeld, is de limiet voor de totale maximale gelijktijdigheid voor alle aangeboden modellen in één eindpunt 128. Neem contact op met uw Azure Databricks-accountteam om een verhoging van deze limiet aan te vragen.
- Als een deductietabel meer dan 500K-bestanden bevat, worden er geen extra gegevens geregistreerd. Om te voorkomen dat u deze limiet overschrijdt, kunt u OPTIMIZE uitvoeren of retentie instellen op uw tabel door oudere gegevens te verwijderen. Als u het aantal bestanden in de tabel wilt controleren, voert u
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>uit. - De levering van logboeken van afleidingstabellen is momenteel op basis van beste inspanning, maar u mag verwachten dat de logboeken binnen 1 uur na een aanvraag beschikbaar zijn. Neem contact op met uw Databricks-accountteam voor meer informatie.
Zie Model serving-limieten en regio's voor beperkingen van algemene model serving-eindpunten.