Incrementeel gegevens uit meerdere tabellen in SQL Server naar een database in Azure SQL Database kopiëren met behulp van de Azure-portal
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie maakt u een Azure Data Factory met een pijplijn waarmee deltagegevens uit meerdere tabellen in een SQL Server-database naar een database in Azure SQL Database worden geladen.
In deze zelfstudie voert u de volgende stappen uit:
- Bereid de bron- en doelserver gegevensopslag voor.
- Een data factory maken.
- Een zelf-hostende Integration Runtime maken.
- De Integration Runtime installeren.
- Maak gekoppelde services.
- Maak bron-, sink- en grenswaardegegevenssets.
- Maken, starten en controleren van een pijplijn.
- Controleer de resultaten.
- Gegevens in brontabellen toevoegen of bijwerken.
- De pijplijn opnieuw uitvoeren en controleren.
- De eindresultaten bekijken.
Overzicht
Dit zijn de belangrijke stappen voor het maken van deze oplossing:
Selecteer de grenswaardekolom.
Selecteer één kolom in elke tabel van de brongegevensopslag, die kan worden gebruikt om de nieuwe of bijgewerkte records voor elke uitvoering te segmenteren. Normaal gesproken nemen de gegevens in deze geselecteerde kolom (bijvoorbeeld, last_modify_time of id) toe wanneer de rijen worden gemaakt of bijgewerkt. De maximale waarde in deze kolom wordt gebruikt als grenswaarde.
Bereid een gegevensopslag voor om de grenswaarde in op te slaan.
In deze zelfstudie slaat u de grenswaarde op in een SQL-database.
Maak een pijplijn met de volgende activiteiten:
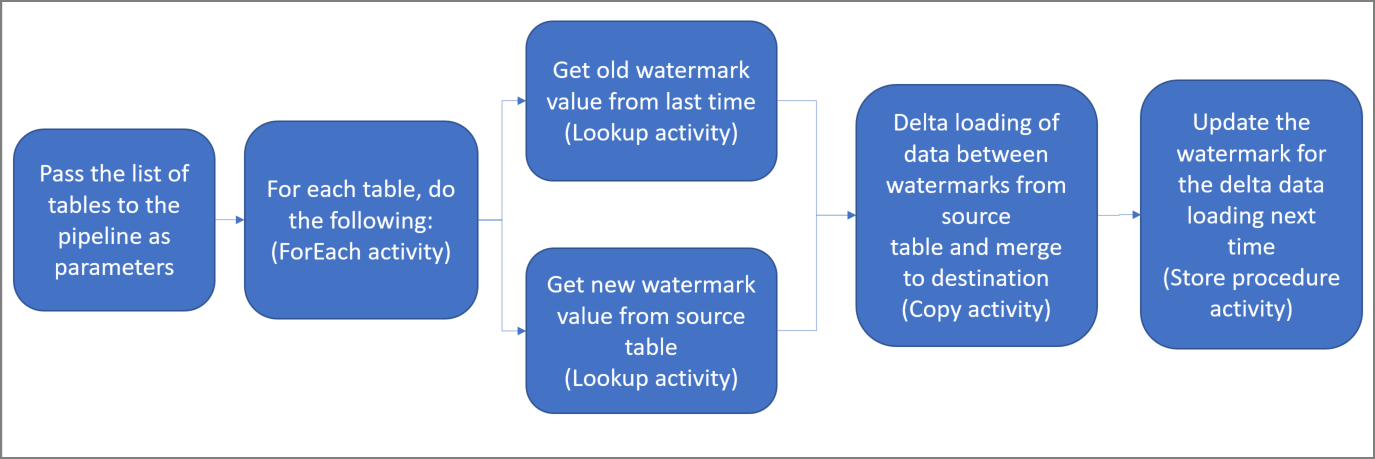
a. Maak een ForEach-activiteit die door een lijst met namen van gegevensbrontabellen loopt, die als parameter is doorgegeven aan de pijplijn. Voor elke brontabel roept deze de volgende activiteiten voor het laden van de deltagegevens voor deze tabel op.
b. Maak twee opzoekactiviteiten. Gebruik de eerste opzoekactiviteit om de laatste grenswaarde op te halen. Gebruik de tweede opzoekactiviteit om de nieuwe grenswaarde op te halen. Deze grenswaarden worden doorgegeven aan de kopieeractiviteit.
c. Maak een kopieeractiviteit waarmee rijen uit de brongegevensopslag worden gekopieerd met een waarde uit de grenswaardekolom die groter is dan de oude grenswaarde en kleiner dan de nieuwe grenswaarde. Vervolgens worden de deltagegevens uit de brongegevensopslag als een nieuw bestand gekopieerd naar een Azure Blob-opslag.
d. Maak een opgeslagen-procedureactiviteit waarmee de grenswaarde wordt bijgewerkt voor de pijplijn die de volgende keer wordt uitgevoerd.
Hier volgt de diagramoplossing op hoog niveau:
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- SQL Server. In deze zelfstudie gebruikt u een SQL Server-database als een brongegevensopslag.
- Azure SQL-database. U gebruikt een database in Azure SQL Database als de sink-gegevensopslag. Als u geen database in SQL Database hebt, raadpleegt u het artikel Een database in Azure SQL Database maken om er een te maken.
Brontabellen maken in uw SQL Server-database
Open SQL Server Management Studio en maak verbinding met de SQL Server-database.
Klik in Server Explorer met de rechtermuisknop op de database en kies Nieuwe query.
Voer de volgende SQL-opdracht uit op uw database om tabellen te maken met de naam
customer_tableenproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Doeltabellen in uw database maken
Open SQL Server Management Studio en maak verbinding met uw database in Azure SQL Database.
Klik in Server Explorer met de rechtermuisknop op de database en kies Nieuwe query.
Voer de volgende SQL-opdracht uit op uw database om tabellen te maken met de naam
customer_tableenproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Nog een tabel in uw database maken om de bovengrenswaarde op te slaan
Voer de volgende SQL-opdracht uit op uw database om een tabel met de naam
watermarktablete maken om de bovengrenswaarde op te slaan:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Initiële watermerkwaarden voor beide brontabellen in de watermerktabel invoegen.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Een opgeslagen procedure maken in uw database
Voer de volgende opdracht uit om een opgeslagen procedure te maken in uw database. Deze opgeslagen procedure werkt de bovengrenswaarde bij elke pijplijnuitvoering bij.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Gegevenstypen en aanvullende opgeslagen procedures maken in uw database
Voer de volgende query uit om twee opgeslagen procedures en twee gegevenstypen in uw database te maken. Deze worden gebruikt voor het samenvoegen van de gegevens uit de brontabellen in doeltabellen.
Om het begin van de beleving toegankelijk te houden, gebruiken we deze opgeslagen procedures direct. Hiermee worden de deltagegevens doorgegeven via een tabelvariabele en vervolgens samengevoegd in het doelarchief. Let op: er wordt geen “groot” aantal deltarijen (meer dan 100) verwacht dat moet worden opgeslagen in de tabelvariabele.
Als u een groot aantal deltarijen in het doelarchief moet samenvoegen, kunt u het beste de kopieeractiviteit gebruiken om alle deltagegevens te kopiëren naar een tijdelijke “faseringstabel” in het doelarchief. Vervolgens moet u uw eigen opgeslagen procedure maken zonder tabelvariabelen te gebruiken om ze te kunnen samenvoegen vanuit de “faseringstabel” in de “definitieve tabel”.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Een data factory maken
Start de webbrowser Microsoft Edge of Google Chrome. Op dit moment wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Selecteer in het linkermenu Een resource maken>Integratie>Data Factory:
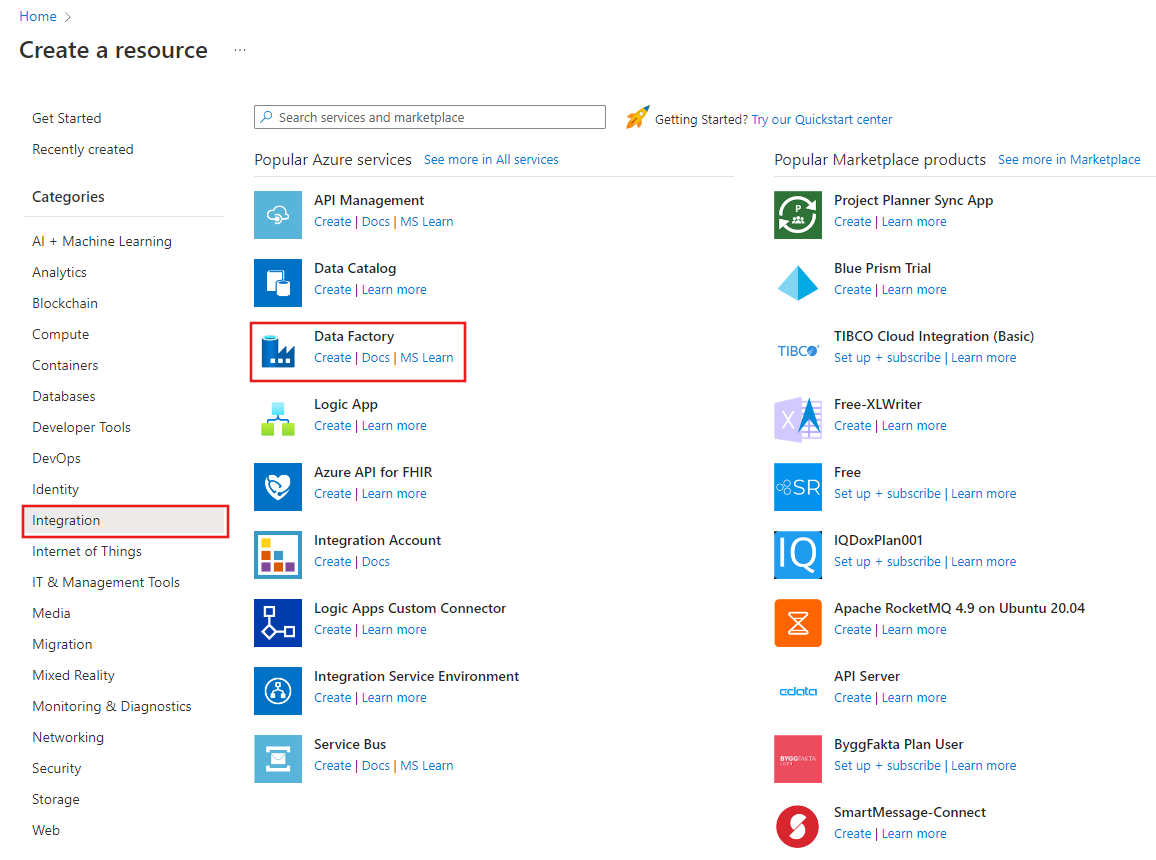
Voer op de pagina Nieuwe gegevensfactoryADFTutorialBulkCopyDF in als de naam.
De naam van de Azure-gegevensfactory moet wereldwijd uniek zijn. Als u een rood uitroepteken ziet met het volgende foutbericht, wijzigt u de naam van de gegevensfactory (bijvoorbeeld uwnaamADFIncCopyTutorialDF) en probeert u het opnieuw. Zie het artikel Data factory - Naamgevingsregels voor meer informatie over naamgevingsregels voor Data Factory-artefacten.
Data factory name "ADFIncCopyTutorialDF" is not availableSelecteer het Azure-abonnement waarin u de gegevensfactory wilt maken.
Voer een van de volgende stappen uit voor de Resourcegroep:
- Selecteer Bestaande gebruiken en selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
- Selecteer Nieuwe maken en voer de naam van een resourcegroep in.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer V2 als de versie.
Selecteer de locatie voor de gegevensfactory. In de vervolgkeuzelijst worden alleen ondersteunde locaties weergegeven. De gegevensopslagexemplaren (Azure Storage, Azure SQL Database, enzovoort) en berekeningen (HDInsight, enzovoort) die worden gebruikt in Data Factory, kunnen zich in andere regio's bevinden.
Klik op Create.
Wanneer het maken is voltooid, ziet u de pagina Data Factory zoals in de afbeelding wordt weergegeven.
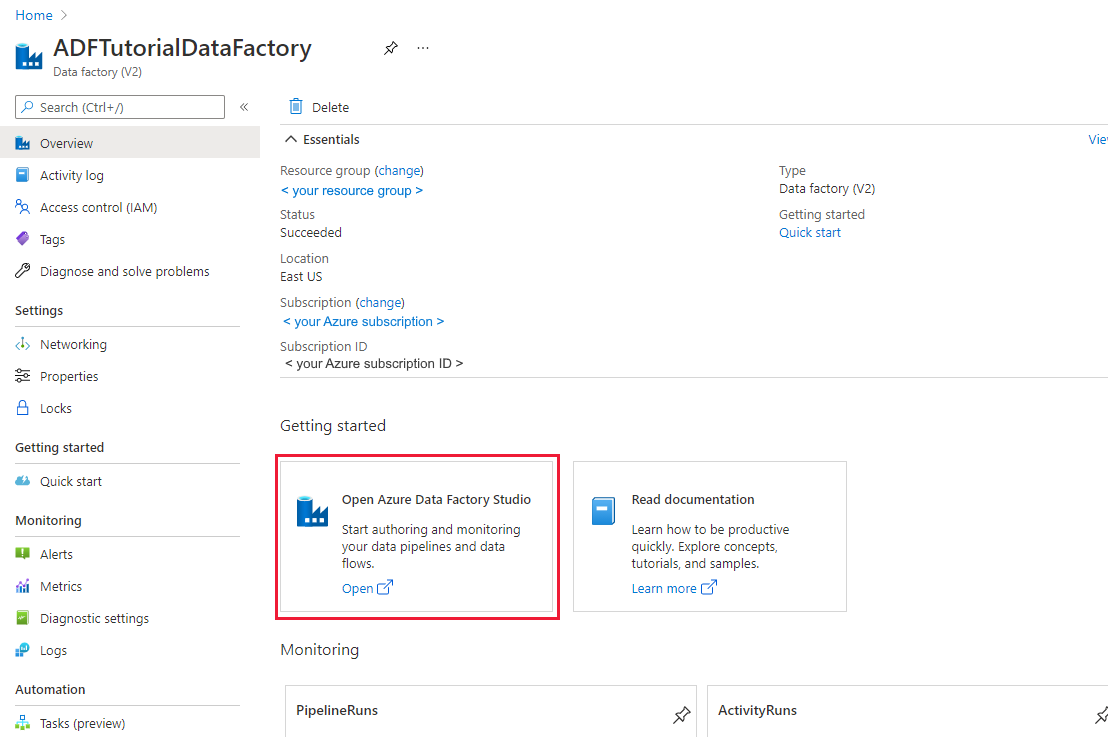
Selecteer Openen op de tegel Azure Data Factory Studio openen om de Gebruikersinterface (UI) van Azure Data Factory op een afzonderlijk tabblad te starten.
Zelf-hostende integratie-runtime maken
Als u gegevens uit een gegevensopslag in een particulier netwerk (on-premises) naar een Azure-gegevensarchief verplaatst, installeert u een zelf-hostende integratieruntime (IR) in uw on-premises-omgeving. De zelf-hostende IR verplaatst gegevens tussen uw particuliere netwerk en Azure.
Selecteer op de startpagina van de Gebruikersinterface van Azure Data Factory het tabblad Beheren in het meest linkse deelvenster.
Selecteer Integration Runtimes in het linkerdeelvenster en selecteer vervolgens +Nieuw.
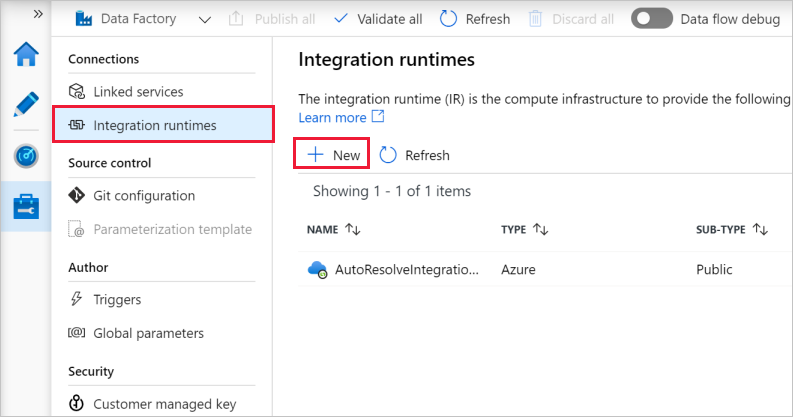
In het venster Instellen van Integration Runtime selecteert u de optie Gegevensverplaatsings- en verzendactiviteiten naar externe berekeningen uitvoeren en klikt u op Doorgaan.
Selecteer zelf-hostend en klik op Doorgaan.
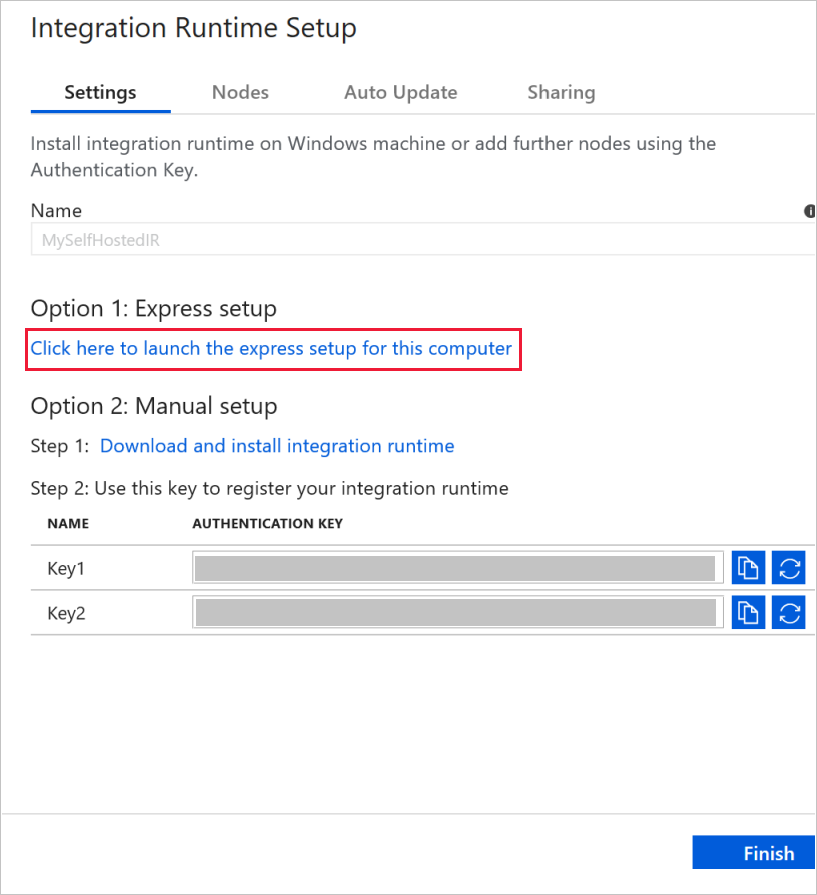
Voer MySelfHostedIR in bij Naam en klik op Maken.
Klik in de sectie Optie 1: snelle installatie op Klik hier om de snelle installatie voor deze computer te starten.
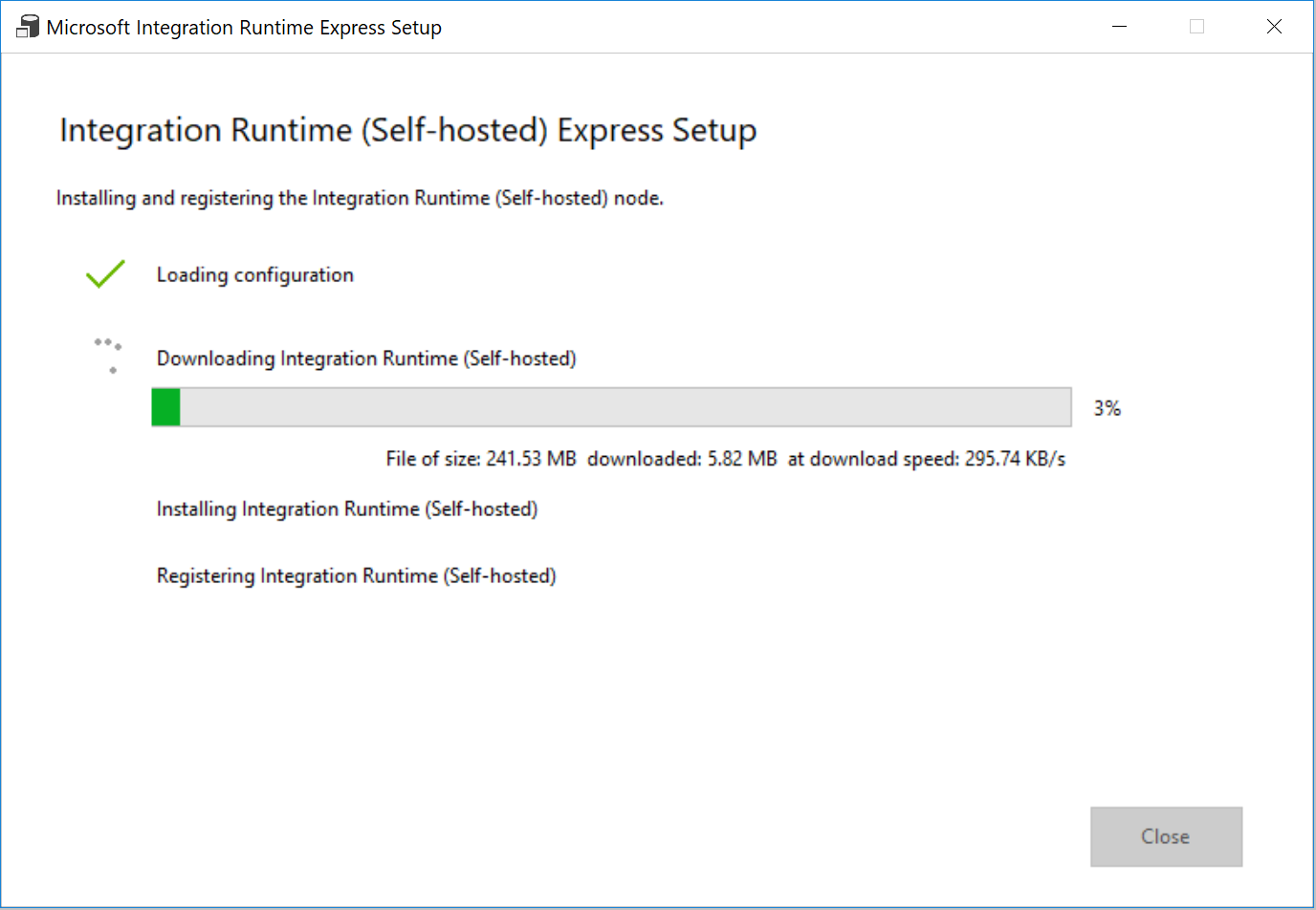
Klik in het venster Snelle installatie van integratieruntime (zelf-hostend) op Sluiten.
Klik in de webbrowser in het venster Installatie van integratieruntime op Voltooien.
Controleer of u MySelfHostedIR in de lijst met integratieruntimes ziet.
Gekoppelde services maken
U maakt gekoppelde services in een gegevensfactory om uw gegevensarchieven en compute-services aan de gegevensfactory te koppelen. In deze sectie maakt u gekoppelde services in uw SQL Server-database en uw database in Azure SQL Database.
De gekoppelde service voor SQL Server maken
In deze stap gaat u uw SQL Server-database aan de data factory koppelen.
Schakel in het venster Verbindingen over van het tabblad Integratieruntimes tab naar het tabblad Gekoppelde Services en klik op + Nieuw.
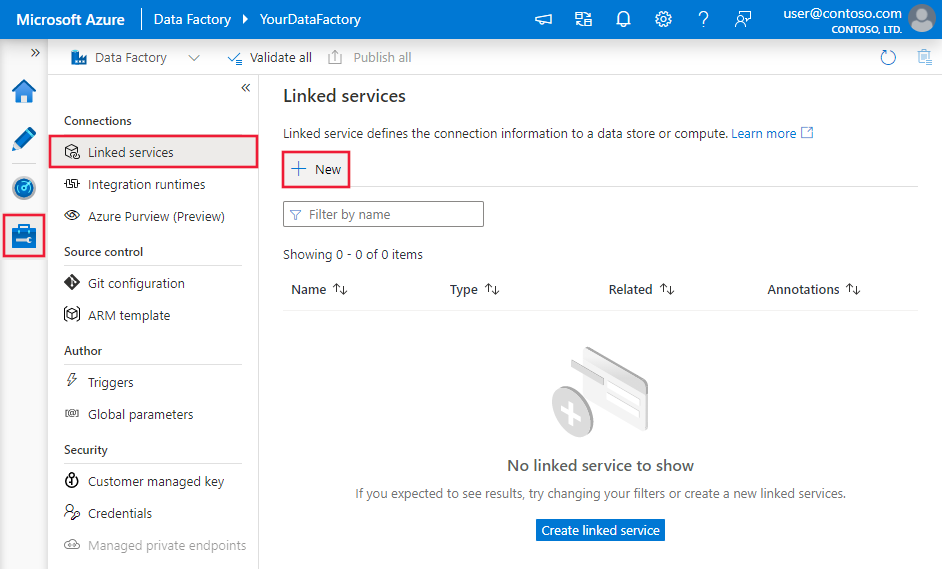
In het venster Nieuwe gekoppelde service selecteert u Microsoft SQL Server en klikt u op Doorgaan.
Voer in het venster New Linked Service de volgende stappen uit:
- Voer SqlServerLinkedService in als Naam.
- Selecteer MySelfHostedIR bij Connect via integration runtime. Dit is een belangrijke stap. De standaard integratieruntime kan geen verbinding maken met een on-premises-gegevensarchief. Gebruik de zelf-hostende integratieruntime die u eerder hebt gemaakt.
- Bij Servernaam voert u de naam in van de computer die de SQL Server-database bevat.
- Bij Naam database voert u de naam in van de database in uw Microsoft SQL Server met de brongegevens. U hebt een tabel gemaakt en gegevens in deze database ingevoegd als onderdeel van de vereisten.
- Bij Verificatietype selecteert u het type van de verificatie dat u wilt gebruiken voor verbinding met de database.
- Bij Gebruikersnaam voert u de naam in van de gebruiker met toegang tot de SQL Server-database. Als u een slash wilt gebruiken (
\) in de naam van uw gebruikersaccount of server, moet u het escapeteken (\) gebruiken. Een voorbeeld ismydomain\\myuser. - Voer bij Wachtwoord het wachtwoord voor de gebruiker in.
- Als u wilt testen of de Data Factory verbinding kan maken met uw SQL Server-database, klikt u op Verbinding testen. Los alle fouten op totdat de verbinding is geslaagd.
- Klik op Voltooien om de gekoppelde service op te slaan.
De gekoppelde Azure SQL Database-service maken
In de laatste stap maakt u een gekoppelde service om uw Microsoft SQL Server-brondatabase aan de gegevensfactory te koppelen. In deze stap koppelt u uw doel/sink-database aan uw data factory.
Schakel in het venster Verbindingen over van het tabblad Integratieruntimes tab naar het tabblad Gekoppelde Services en klik op + Nieuw.
In het venster New Linked Service selecteert u Azure SQL Database en klikt u op Doorgaan.
Voer in het venster New Linked Service de volgende stappen uit:
- Voer AzureSqlDatabaseLinkedService in als Naam.
- Bij de Servernaam selecteert u de naam van uw server in de vervolgkeuzelijst.
- Bij de Databasenaam selecteert u de database waarin u customer_table en project_table als onderdeel van de vereisten heeft gemaakt.
- Bij Gebruikersnaam voert u de naam in van de gebruiker met toegang tot de database.
- Voer bij Wachtwoord het wachtwoord voor de gebruiker in.
- Als u wilt testen of de Data Factory verbinding kan maken met uw SQL Server-database, klikt u op Verbinding testen. Los alle fouten op totdat de verbinding is geslaagd.
- Klik op Voltooien om de gekoppelde service op te slaan.
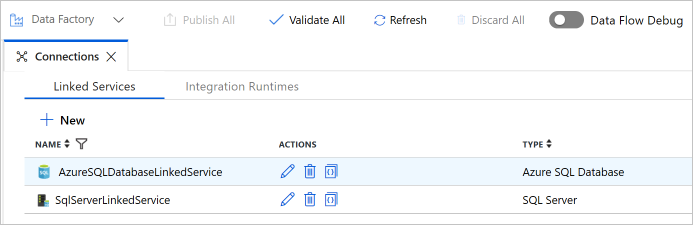
Controleer of u twee gekoppelde services in de lijst kunt zien.
Gegevenssets maken
In deze stap maakt u gegevenssets die de gegevensbron, het gegevensdoel en de plaats voor het opslaan van de bovengrens aangeven.
Een brongegevensset maken
Klik op + (plus) in het linkervenster en klik op Gegevensset.
Selecteer in het venster Nieuwe gegevensset de optie SQL Server en klik op Doorgaan.
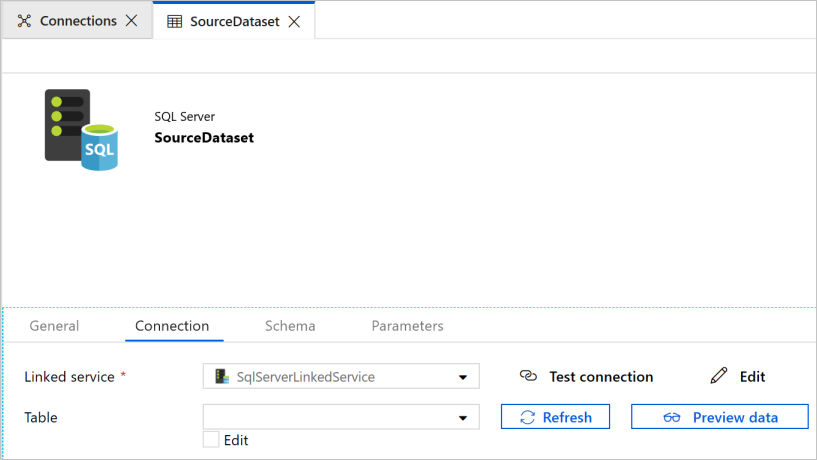
Uit ziet een nieuw tabblad dat geopend wordt in de webbrowser voor het configureren van de gegevensset. U ziet ook een gegevensset in de structuurweergave. Voer in het tabblad Algemeen in het venster Eigenschappen onderaan SourceDataset in als Naam.
Ga in het venster Eigenschappen naar het tabblad Verbindingen en klik op SqlServerLinkedService voor Gekoppelde service. U selecteert hier geen tabel. De kopieeractiviteit in de pijplijn gebruikt een SQL-query voor het laden van de gegevens in plaats van de hele tabel te laden.
Een sinkgegevensset maken
Klik op + (plus) in het linkervenster en klik op Gegevensset.
Selecteer in het venster Nieuwe gegevensset de optie Azure SQL Database en klik op Doorgaan.
Uit ziet een nieuw tabblad dat geopend wordt in de webbrowser voor het configureren van de gegevensset. U ziet ook een gegevensset in de structuurweergave. Voer in het tabblad Algemeen in het venster Eigenschappen onderaan SinkDataset in als Naam.
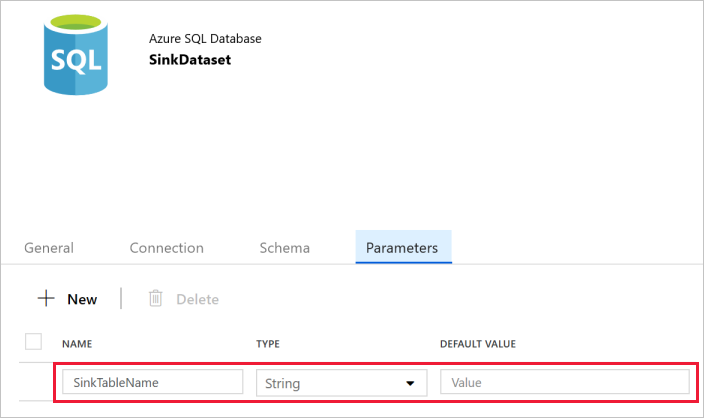
Ga naar het tabblad Parameters in het venster Eigenschappen en voer de volgende stappen uit:
Klik op Nieuw in de sectie Parameters maken/bijwerken.
Voer SinkTableName in bij de naam en Tekenreeks voor het type. Deze gegevensset gebruikt SinkTableName als parameter. De parameter SinkTableName wordt in runtime dynamisch ingesteld door de pijplijn. De ForEach-activiteit in de pijplijn doorloopt een lijst met namen van tabellen en geeft de tabelnaam door aan deze gegevensset in elke iteratie.
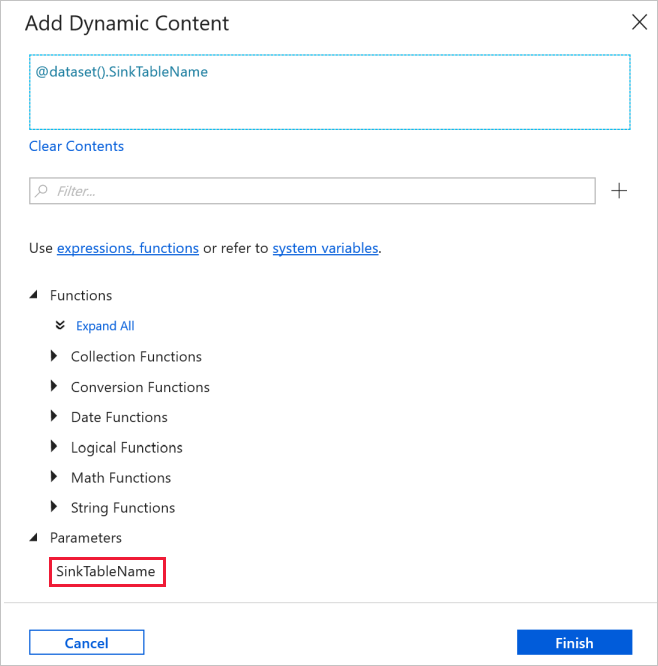
Ga in het venster Eigenschappen naar het tabblad Verbinding en selecteer AzureSqlDatabaseLinkedService bij Gekoppelde service. Klik voor de eigenschap Tabel op Dynamische inhoud toevoegen.
Selecteer in het venster Dynamische inhoud toevoegen de optie SinkTableName in de sectie Parameters.
Nadat u op Voltooien hebt geklikt, ziet u '@dataset(). SinkTableName' als tabelnaam.
Een gegevensset maken voor een grenswaarde
In deze stap maakt u een gegevensset voor het opslaan van een bovengrenswaarde.
Klik op + (plus) in het linkervenster en klik op Gegevensset.
Selecteer in het venster Nieuwe gegevensset de optie Azure SQL Database en klik op Doorgaan.
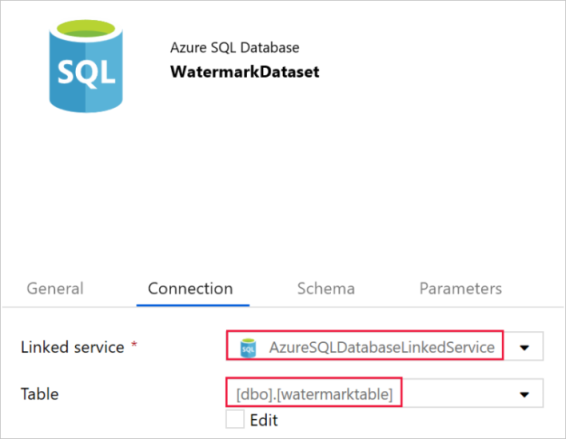
Voer in het tabblad Algemeen in het venster Eigenschappen onderaan WatermarkDataset in als Naam.
Open het tabblad Connection en voer de volgende stappen uit:
Selecteer AzureSqlDatabaseLinkedService als Gekoppelde service.
Selecteer [dbo].[watermarktable] als Tabel.
Een pipeline maken
In deze pijplijn wordt een lijst met tabelnamen gebruikt als parameter. De ForEach-activiteit doorloopt de lijst met namen van tabellen en voert de volgende bewerkingen uit:
Gebruik de opzoekactiviteit voor het ophalen van de oude bovengrenswaarde (de initiële waarde, of de waarde die is gebruikt in de laatste iteratie).
Gebruik de opzoekactiviteit voor het ophalen van de nieuwe bovengrenswaarde (de maximale waarde van de bovengrenskolom in de brontabel).
Gebruik de kopieeractiviteit voor het kopiëren van gegevens tussen deze twee bovengrenswaarden uit de brondatabase naar de doeldatabase.
Gebruik de opgeslagen-procedureactiviteit voor het bijwerken van de oude bovengrenswaarde die in de eerste stap van de volgende iteratie moet worden gebruikt.
Maak de pijplijn
Klik op + (plus) in het linkervenster en klik op Pipeline.
Geef op het tabblad Algemeen bij Eigenschappen IncrementalCopyPipeline op als Naam. Vouw het paneel vervolgens samen door in de rechterbovenhoek op het pictogram Eigenschappen te klikken.
Voer op het tabblad Parameters de volgende stappen uit:
- Klik op + Nieuw.
- Voer tableList in als Name-parameter.
- Selecteer Matrix als het Type parameter.
Vouw in de werkset Activiteiten de optie Iteratie en voorwaarden uit en sleep de ForEach-activiteit naar het ontwerpoppervlak voor pijplijnen. Voer in het tabblad Algemeen van het venster EigenschappenIterateSQLTables in.
Ga naar het tabblad Settings en voer
@pipeline().parameters.tableListin bij Items. De ForEach-activiteit doorloopt de lijst met tabellen en voert de volgende incrementele kopiebewerkingen uit.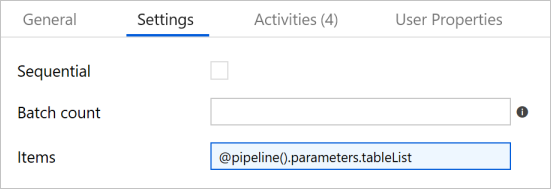
Selecteer de activiteit ForEach in de pijplijn als dat nog niet is gebeurd. Klik op de knop Bewerken (potloodpictogram).
Vouw in de Activiteiten-werkset de optie Algemeen uit. Gebruik vervolgens slepen-en-neerzetten om de opzoekactiviteit te verplaatsen naar het ontwerpoppervlak voor pijplijnen. en voer LookupOldWaterMarkActivity in bij Naam.
Ga naar het tabblad Instellingen in het venster Eigenschappen en voer de volgende stappen uit:
Selecteer WatermarkDataset in het veld Brongegevensset.
Selecteer Query bij Use Query.
Voer bij Query de volgende SQL-query in.
select * from watermarktable where TableName = '@{item().TABLE_NAME}'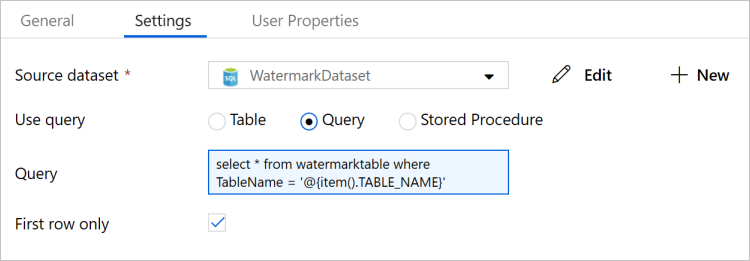
Sleep de activiteit Opzoeken uit de Activiteiten-werkset en voer LookupNewWaterMarkActivity in als Naam.
Schakel over naar het tabblad Instellingen.
Selecteer SourceDataset in het veld Source Dataset.
Selecteer Query bij Use Query.
Voer bij Query de volgende SQL-query in.
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}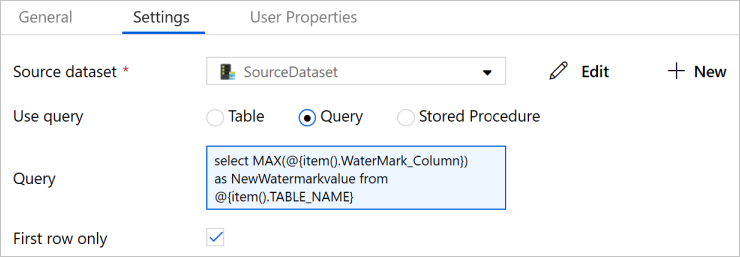
Sleep de activiteit Kopiëren uit de Activiteiten-werkset en voer IncrementalCopyActivity in als Naam.
Verbind Opzoek-activiteiten één voor één met de activiteit Kopiëren. Om te verbinden, start u met het slepen van het groene vak gekoppeld aan de Opzoek-activiteit en zet u dit neer op de activiteit Kopiëren. Laat de muisknop los als u ziet dat de randkleur van de kopieeractiviteit is gewijzigd in blauw.
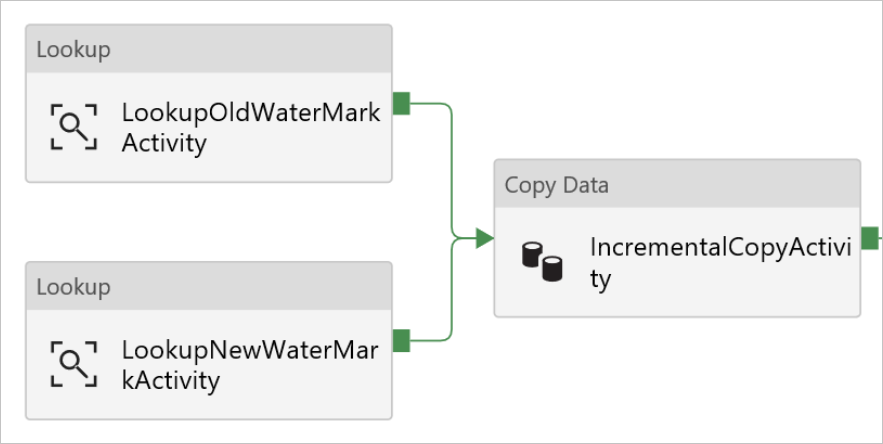
U ziet dat de activiteit Kopiëren in de pijplijn is mislukt. Ga naar het tabblad Bron in het venster Eigenschappen.
Selecteer SourceDataset in het veld Source Dataset.
Selecteer Query bij Use Query.
Voer bij Query de volgende SQL-query in.
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'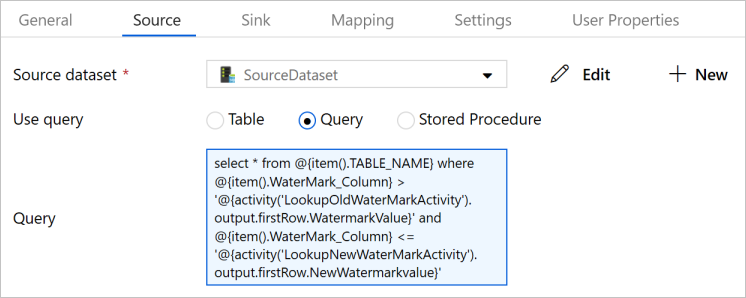
Open het tabblad Sink en selecteer SinkDataset in het veld Sink Dataset.
Voer de volgende stappen uit:
Voer in de sectie Eigenschappen van gegevensset als SinkTableName-parameter
@{item().TABLE_NAME}in.Voer bij de eigenschap Naam opgeslagen procedure
@{item().StoredProcedureNameForMergeOperation}in.Voer bij de eigenschap Tabeltype
@{item().TableType}in.Voer bij Naam tabeltypeparameter
@{item().TABLE_NAME}in.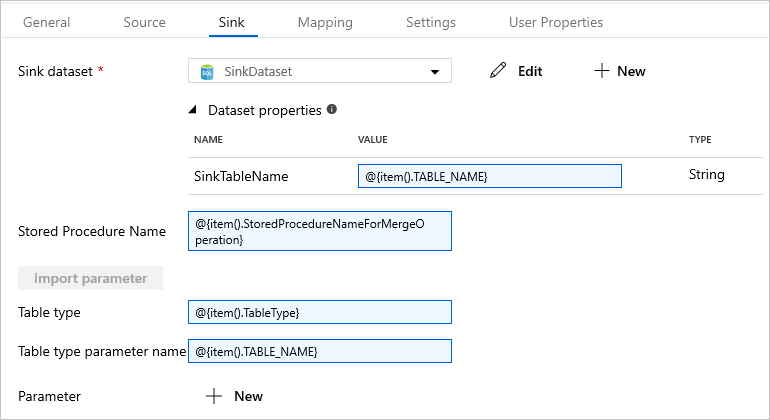
Sleep de Stored Procedure-activiteit vanuit de werkset Activities naar het ontwerpoppervlak voor pijplijnen. Verbind de Kopieer-activiteit met de Opgeslagen procedure-activiteit.
Selecteer de Opgeslagen procedure-activiteit in de pijplijn en voer StoredProceduretoWriteWatermarkActivity in als Naam in het tabblad Algemeen van het venster Eigenschappen.
Ga naar het tabblad SQL-account en selecteer AzureSqlDatabaseLinkedService als Gekoppelde Service.

Open het tabblad Stored Procedure en voer de volgende stappen uit:
Selecteer
[dbo].[usp_write_watermark]als Opgeslagen procedurenaam.Selecteer Importparameter.
Geef de volgende waarden op voor de parameters:
Name Type Weergegeven als LastModifiedtime Datum en tijd @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}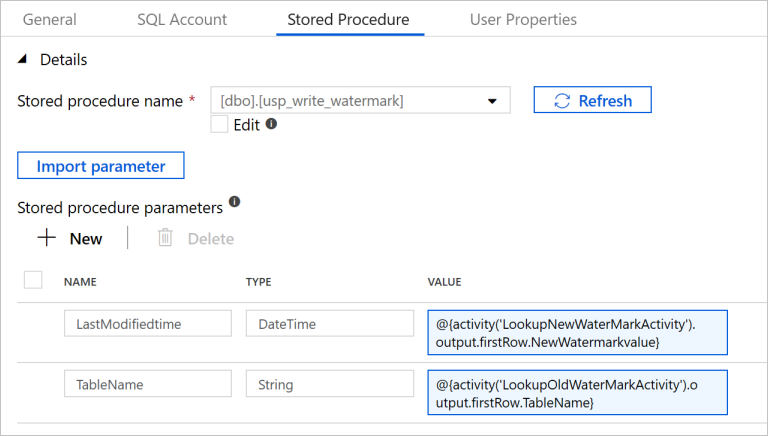
Selecteer Alles publiceren als u de entiteiten die u hebt gemaakt, wilt publiceren naar de Data Factory-service.
Wacht totdat het bericht Successfully published wordt weergegeven. Om de meldingen te zien, klikt u op de link Meldingen weergeven. Sluit het meldingenvenster door op X te klikken.
De pijplijn uitvoeren
Klik in de werkbalk voor de pijplijn op Trigger toevoegen en klik vervolgens op Nu activeren.
Voer in het venster Pijplijn uitvoeren de volgende waarde in voor de parameter tableList en klik op Voltooien.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]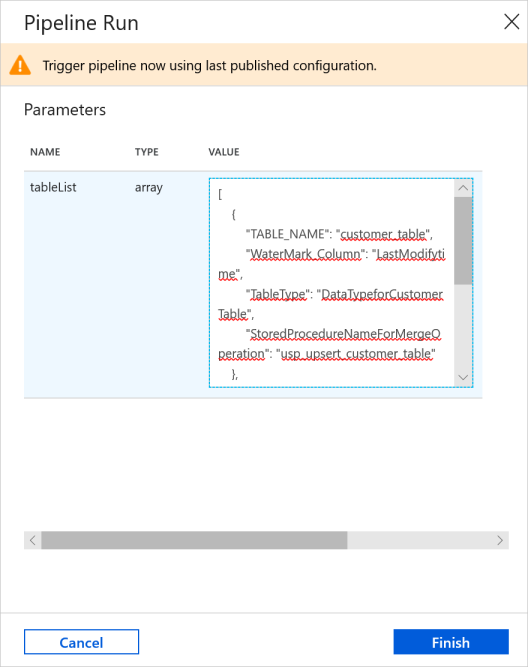
De pijplijn bewaken
Ga naar het tabblad Controleren aan de linkerkant. U kunt de status van de pijplijnuitvoering zien die is geactiveerd met de handmatige trigger. U kunt via koppelingen in de kolom NAAM PIJPLIJN details van activiteiten bekijken en de pijplijn opnieuw uitvoeren.
Selecteer de koppeling in de kolom NAAM PIJPLIJN om de uitvoering van activiteiten te zien die zijn gekoppeld aan de pijplijnuitvoering. Selecteer de koppeling Details (pictogram van een bril) in de kolom NAAM ACTIVITEIT om details van de uitvoeringen van een activiteit te zien.
Selecteer Alle pijplijnuitvoeringen bovenaan om terug te gaan naar de weergave Pijplijnuitvoeringen. Selecteer Vernieuwen om de weergave te vernieuwen.
De resultaten bekijken
Voer in SQL Server Management Studio de volgende query's uit op de SQL-doeldatabase om te controleren of de gegevens van de brontabellen naar de doeltabellen zijn gekopieerd:
Query
select * from customer_table
Uitvoer
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Query
select * from project_table
Uitvoer
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Query
select * from watermarktable
Uitvoer
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
U ziet dat de bovengrenswaarden voor beide tabellen zijn bijgewerkt.
Meer gegevens toevoegen aan de brontabellen
Voer de volgende query uit op de SQL Server-brondatabase om een bestaande rij bij te werken in customer_table. Voeg een nieuwe rij in project_table in.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Voer de pijplijn uit
Schakel in het browservenster over naar het tabblad Bewerken aan de linkerkant.
Klik in de werkbalk voor de pijplijn op Trigger toevoegen en klik vervolgens op Nu activeren.
Voer in het venster Pijplijn uitvoeren de volgende waarde in voor de parameter tableList en klik op Voltooien.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
De pijplijn opnieuw controleren
Ga naar het tabblad Controleren aan de linkerkant. U kunt de status van de pijplijnuitvoering zien die is geactiveerd met de handmatige trigger. U kunt via koppelingen in de kolom NAAM PIJPLIJN details van activiteiten bekijken en de pijplijn opnieuw uitvoeren.
Selecteer de koppeling in de kolom NAAM PIJPLIJN om de uitvoering van activiteiten te zien die zijn gekoppeld aan de pijplijnuitvoering. Selecteer de koppeling Details (pictogram van een bril) in de kolom NAAM ACTIVITEIT om details van de uitvoeringen van een activiteit te zien.
Selecteer Alle pijplijnuitvoeringen bovenaan om terug te gaan naar de weergave Pijplijnuitvoeringen. Selecteer Vernieuwen om de weergave te vernieuwen.
De eindresultaten bekijken
Voer in SQL Server Management Studio de volgende query's uit op de SQL-doeldatabase om te controleren dat de bijgewerkte/nieuwe gegevens van de brontabellen naar de doeltabellen zijn gekopieerd.
Query
select * from customer_table
Uitvoer
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Let op de nieuwe waarden van Name en LastModifytime voor de PersonID voor nummer 3.
Query
select * from project_table
Uitvoer
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Let erop dat de invoer van NewProject toegevoegd is aan project_table.
Query
select * from watermarktable
Uitvoer
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
U ziet dat de bovengrenswaarden voor beide tabellen zijn bijgewerkt.
Gerelateerde inhoud
In deze zelfstudie hebt u de volgende stappen uitgevoerd:
- Bereid de bron- en doelserver gegevensopslag voor.
- Een data factory maken.
- Een zelf-hostende integration runtime (IR) maken.
- De Integration Runtime installeren.
- Maak gekoppelde services.
- Maak bron-, sink- en grenswaardegegevenssets.
- Maken, starten en controleren van een pijplijn.
- Controleer de resultaten.
- Gegevens in brontabellen toevoegen of bijwerken.
- De pijplijn opnieuw uitvoeren en controleren.
- De eindresultaten bekijken.
Ga naar de volgende zelfstudie voor meer informatie over het transformeren van gegevens met behulp van een Spark-cluster in Azure: