Transformatie met Azure Databricks
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
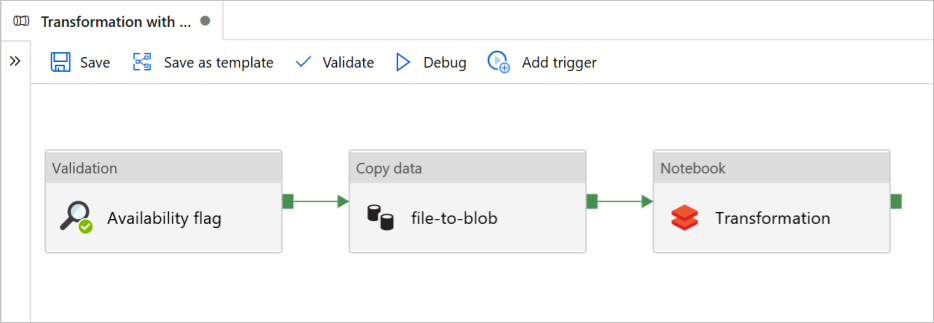
In deze zelfstudie maakt u een end-to-end-pijplijn met de activiteiten Validatie, Gegevens kopiëren en Notebook in Azure Data Factory.
Validatie zorgt ervoor dat uw brongegevensset gereed is voor downstreamverbruik voordat u de kopieer- en analysetaak activeert.
Kopieer gegevens dupliceren de brongegevensset naar de sinkopslag, die is gekoppeld als DBFS in het Azure Databricks-notebook. Op deze manier kan de gegevensset rechtstreeks worden gebruikt door Spark.
Notebook activeert het Databricks-notebook waarmee de gegevensset wordt getransformeerd. De gegevensset wordt ook toegevoegd aan een verwerkte map of Azure Synapse Analytics.
Ter vereenvoudiging maakt de sjabloon in deze zelfstudie geen geplande trigger. U kunt er indien nodig een toevoegen.
Vereisten
Een Azure Blob Storage-account met een container die als sink wordt aangeroepen
sinkdata.Noteer de naam van het opslagaccount, de containernaam en de toegangssleutel. U hebt deze waarden later in de sjabloon nodig.
Een Azure Databricks-werkruimte.
Een notebook importeren voor transformatie
Een transformatienotitieblok importeren in uw Databricks-werkruimte:
Meld u aan bij uw Azure Databricks-werkruimte.
Klik met de rechtermuisknop op een map in uw werkruimte en selecteer Importeren.
Selecteer Importeren uit: URL. Typ in
https://adflabstaging1.blob.core.windows.net/share/Transformations.htmlhet tekstvak .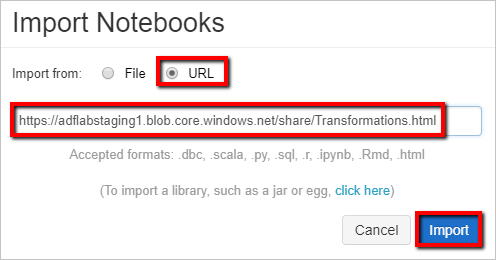
Nu gaan we het transformatienotitieblok bijwerken met uw opslagverbindingsgegevens.
Ga in het geïmporteerde notebook naar opdracht 5 , zoals wordt weergegeven in het volgende codefragment.
- Vervang
<storage name>en<access key>door uw eigen opslagverbindingsgegevens. - Gebruik het opslagaccount met de
sinkdatacontainer.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Vervang
Genereer een Databricks-toegangstoken voor Data Factory voor toegang tot Databricks.
- Selecteer in uw Azure Databricks-werkruimte uw Azure Databricks-gebruikersnaam in de bovenste balk en selecteer vervolgens Instellingen in de vervolgkeuzelijst.
- Selecteer Ontwikkelaar.
- Selecteer Beheren naast Access-tokens.
- Selecteer Nieuw token genereren.
- (Optioneel) Voer een opmerking in waarmee u dit token in de toekomst kunt identificeren en de standaardlevensduur van het token van 90 dagen kunt wijzigen. Als u een token zonder levensduur wilt maken (niet aanbevolen), laat u het vak Levensduur (dagen) leeg (leeg).
- Selecteer Genereren.
- Kopieer het weergegeven token naar een veilige locatie en selecteer Vervolgens Gereed.
Sla het toegangstoken op voor later gebruik bij het maken van een gekoppelde Databricks-service. Het toegangstoken ziet er ongeveer als volgt uit dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Deze sjabloon gebruiken
Ga naar de transformatie met de Azure Databricks-sjabloon en maak nieuwe gekoppelde services voor de volgende verbindingen.
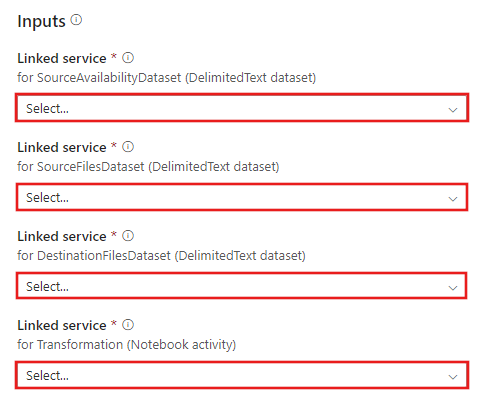
Bronblobverbinding : voor toegang tot de brongegevens.
Voor deze oefening kunt u de openbare blobopslag gebruiken die de bronbestanden bevat. Raadpleeg de volgende schermopname voor de configuratie. Gebruik de volgende SAS-URL om verbinding te maken met bronopslag (alleen-lezentoegang):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D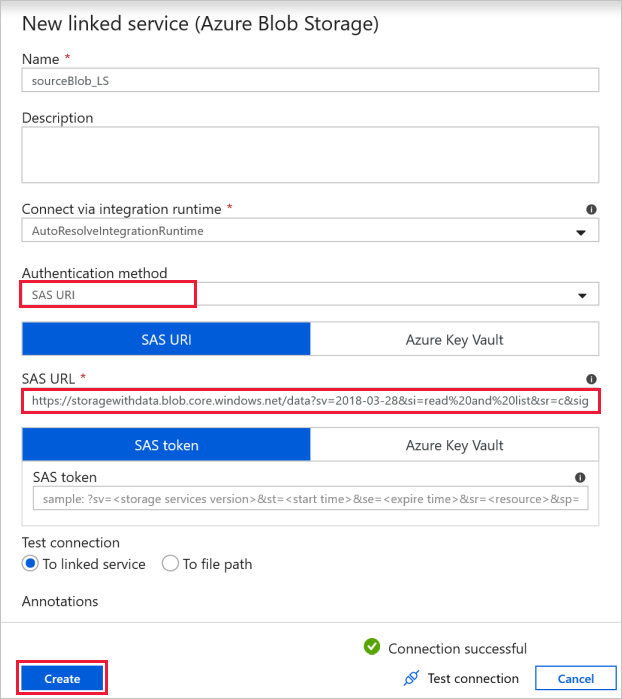
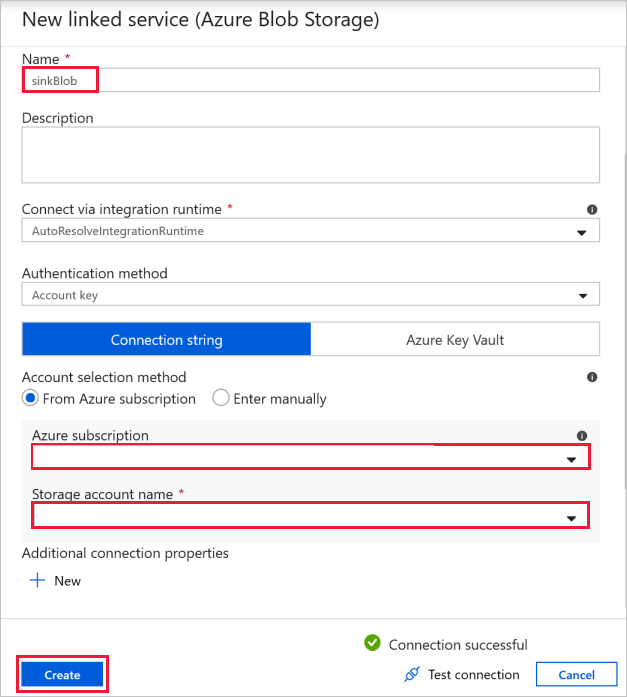
Doelblobverbinding : om de gekopieerde gegevens op te slaan.
Selecteer uw sink-opslagblob in het venster Nieuwe gekoppelde service .
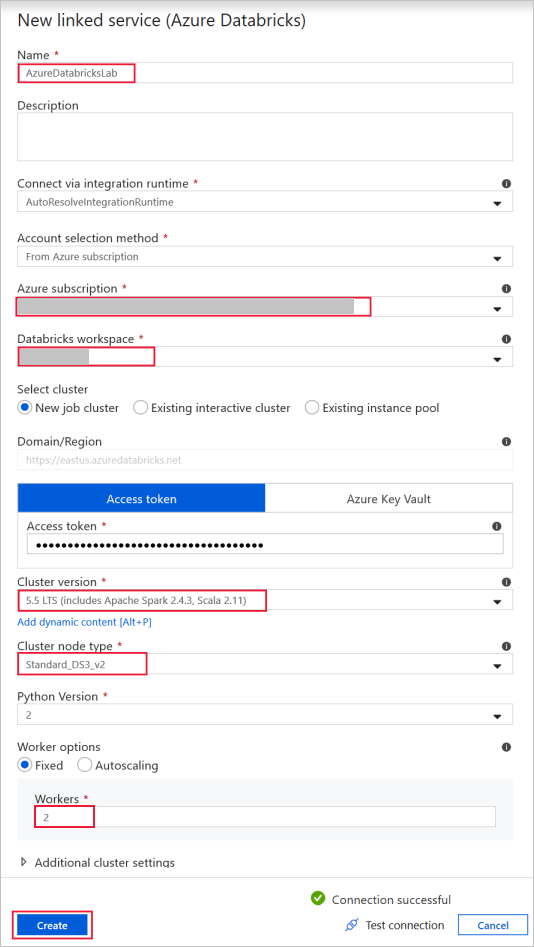
Azure Databricks : om verbinding te maken met het Databricks-cluster.
Maak een databricks-gekoppelde service met behulp van de toegangssleutel die u eerder hebt gegenereerd. U kunt ervoor kiezen om een interactief cluster te selecteren als u er een hebt. In dit voorbeeld wordt de optie Nieuw taakcluster gebruikt.
Selecteer Deze sjabloon gebruiken. U ziet een pijplijn die is gemaakt.
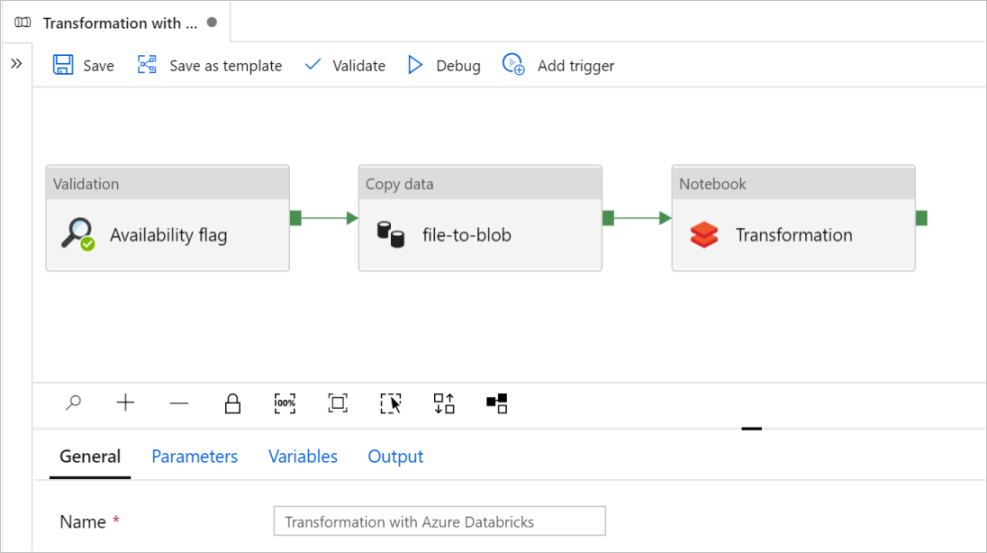
Inleiding tot en configuratie van pijplijnen
In de nieuwe pijplijn worden de meeste instellingen automatisch geconfigureerd met standaardwaarden. Controleer de configuraties van uw pijplijn en breng de benodigde wijzigingen aan.
Controleer in de vlag Beschikbaarheid van validatieactiviteitof de waarde van de brongegevenssetis ingesteld op
SourceAvailabilityDatasetdie u eerder hebt gemaakt.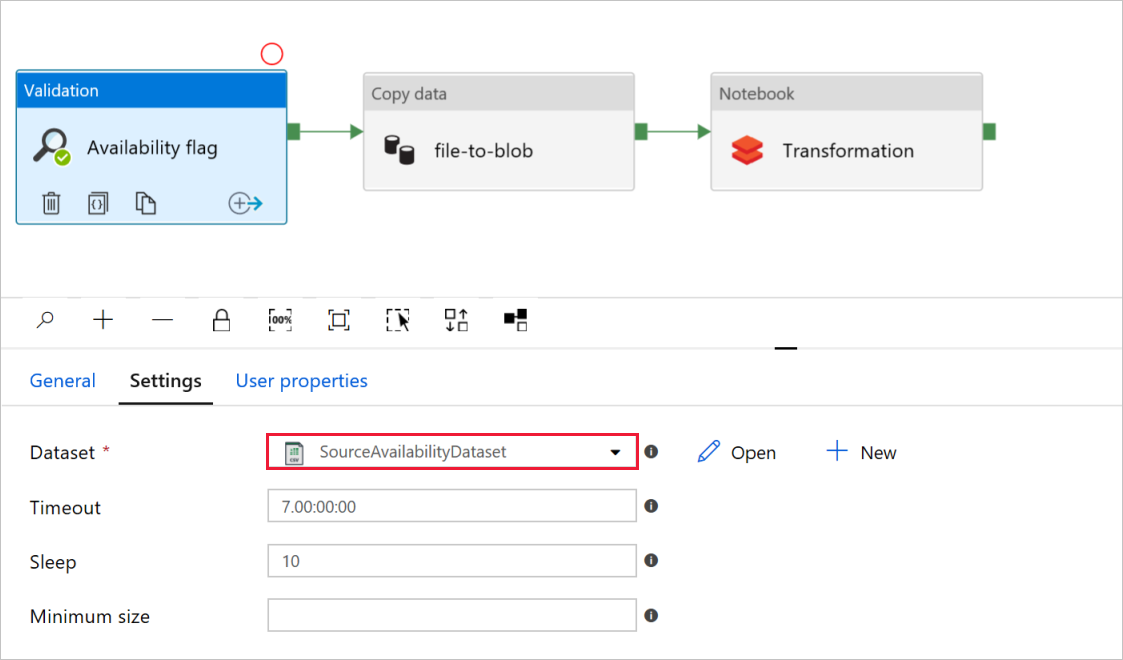
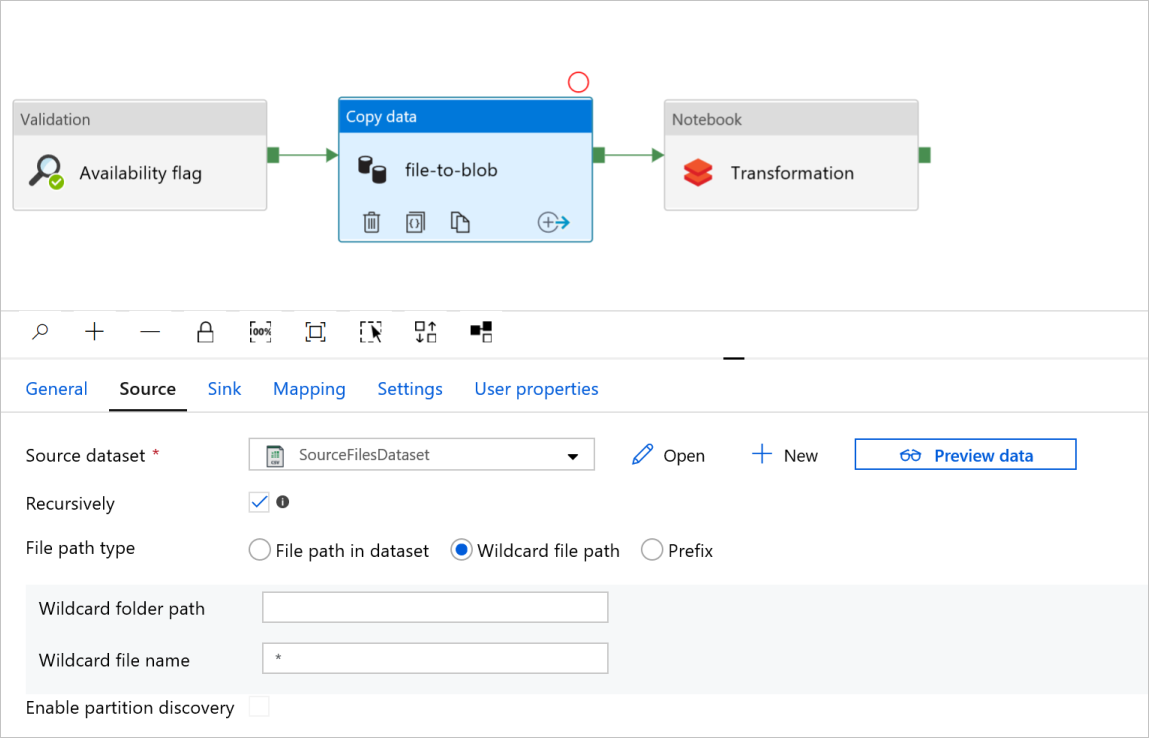
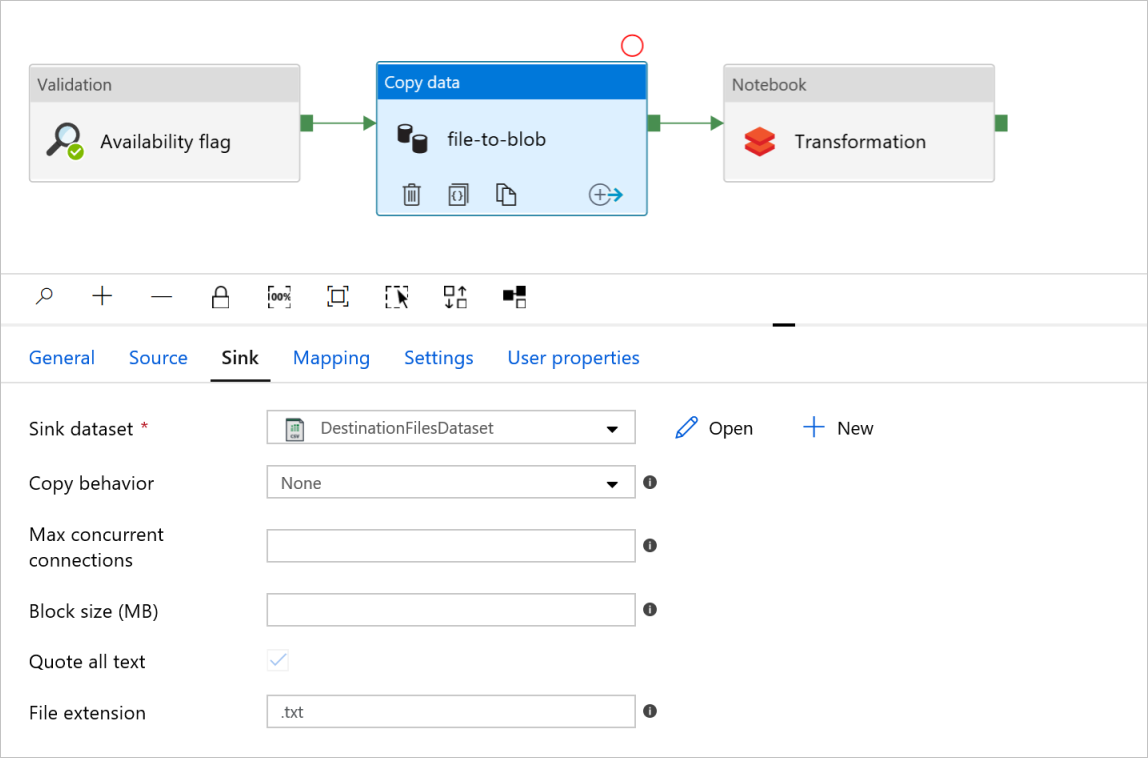
Controleer de tabbladen Bron en Sink in het activiteitenbestand naar de blob Kopiëren. Wijzig indien nodig de instellingen.
Tabblad Bron
Tabblad Sink
Controleer en werk indien nodig de paden en instellingen bij in de transformatie van notebookactiviteiten.
De gekoppelde Databricks-service moet vooraf worden ingevuld met de waarde uit een vorige stap, zoals wordt weergegeven:
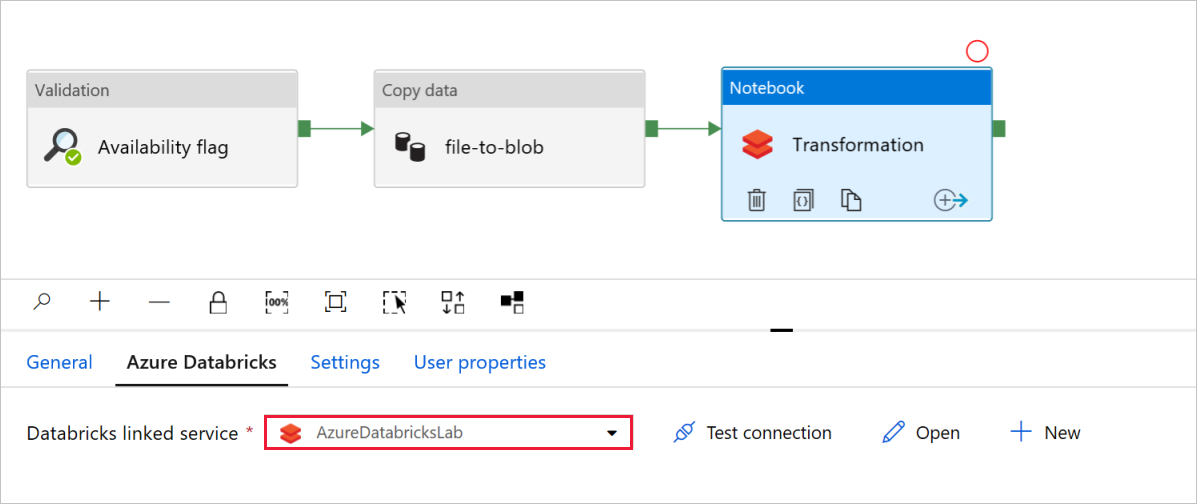
Ga als volgende te werk om de notebookinstellingen te controleren:
Selecteer het tabblad Instellingen . Controleer voor notebookpad of het standaardpad juist is. Mogelijk moet u bladeren en het juiste notitieblokpad kiezen.
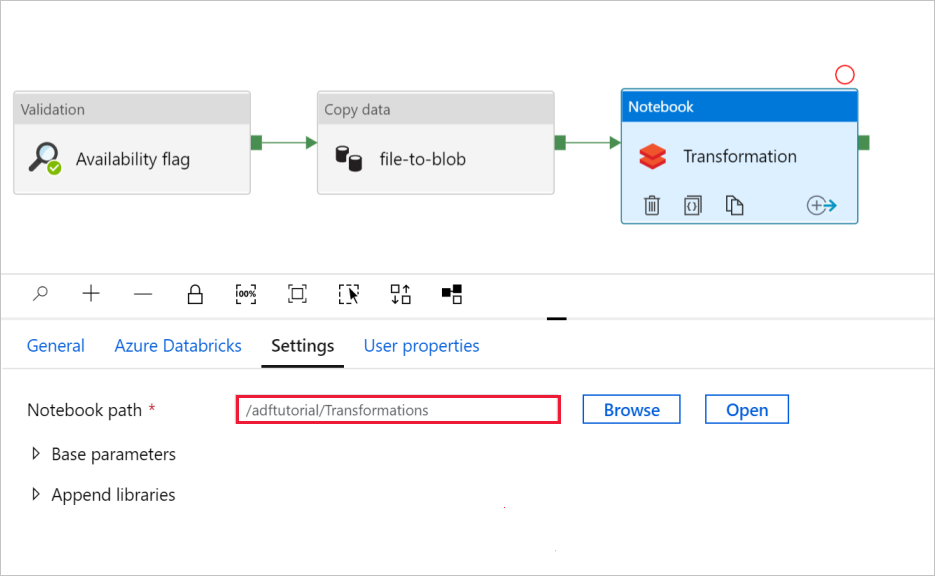
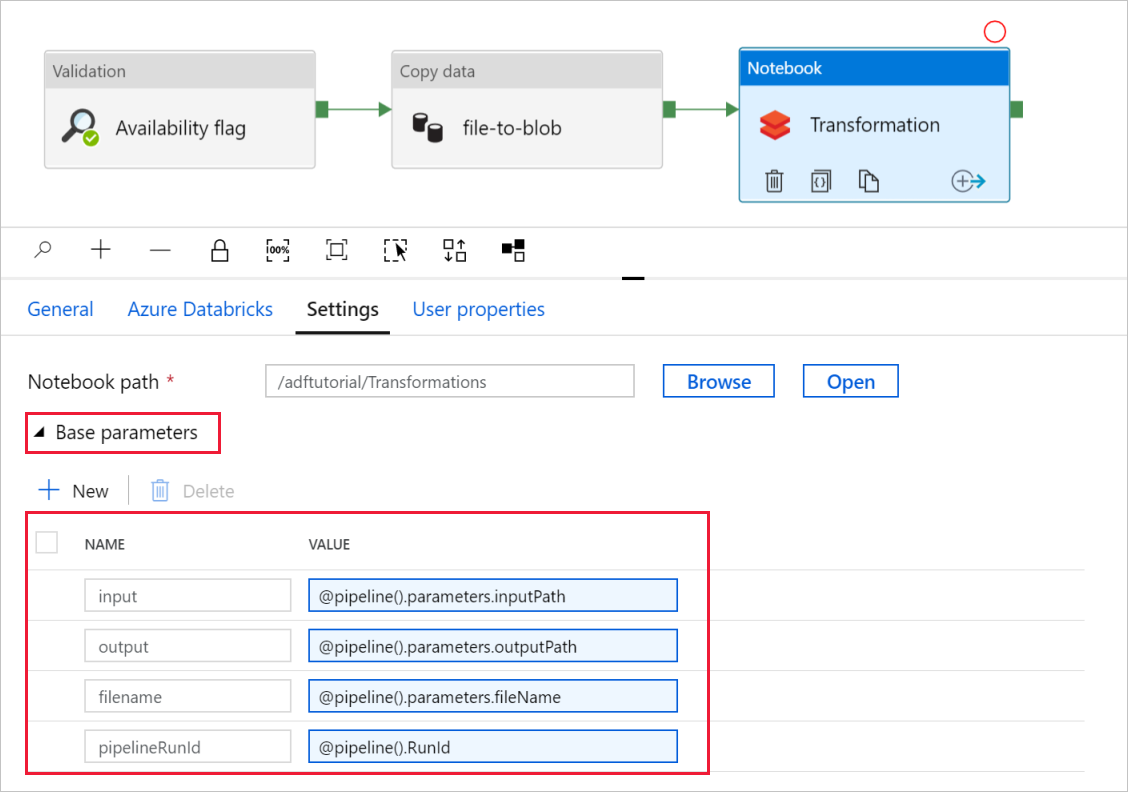
Vouw de selector Basisparameters uit en controleer of de parameters overeenkomen met wat wordt weergegeven in de volgende schermopname. Deze parameters worden doorgegeven aan het Databricks-notebook vanuit Data Factory.
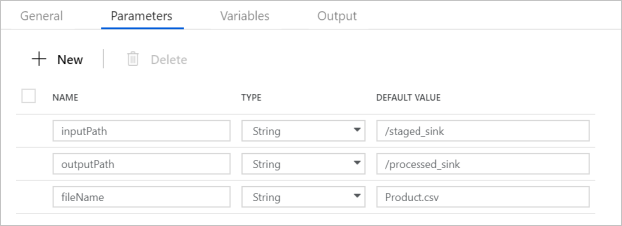
Controleer of de pijplijnparameters overeenkomen met wat wordt weergegeven in de volgende schermopname:
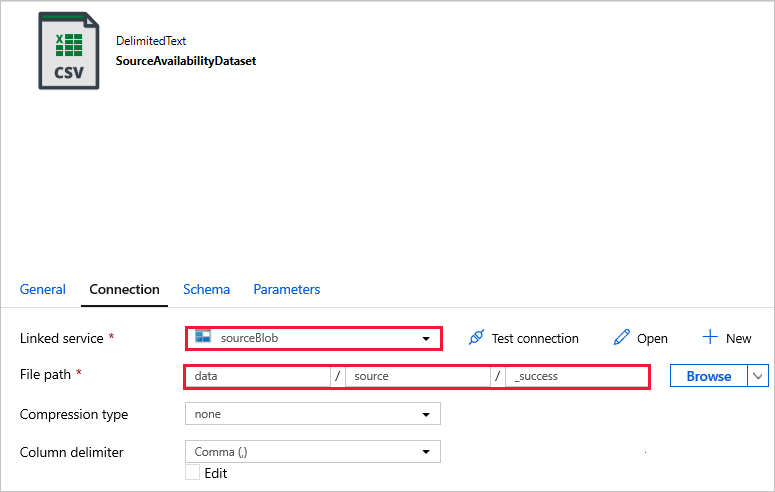
Maak verbinding met uw gegevenssets.
Notitie
In de onderstaande gegevenssets is het bestandspad automatisch opgegeven in de sjabloon. Als er wijzigingen vereist zijn, moet u ervoor zorgen dat u het pad voor zowel de container als de map opgeeft voor het geval er een verbindingsfout optreedt.
SourceAvailabilityDataset : om te controleren of de brongegevens beschikbaar zijn.
SourceFilesDataset : voor toegang tot de brongegevens.
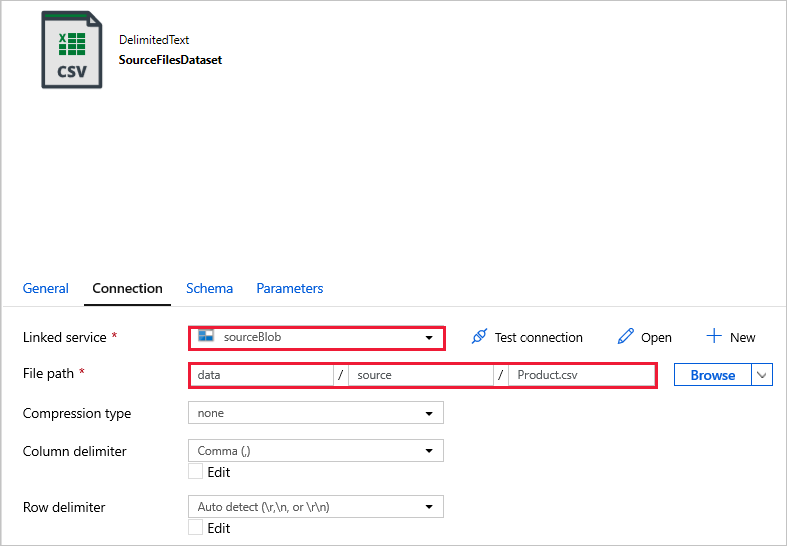
DestinationFilesDataset : om de gegevens te kopiëren naar de doellocatie van de sink. Gebruik de volgende waarden:
Gekoppelde service -
sinkBlob_LS, gemaakt in een vorige stap.Bestandspad -
sinkdata/staged_sink.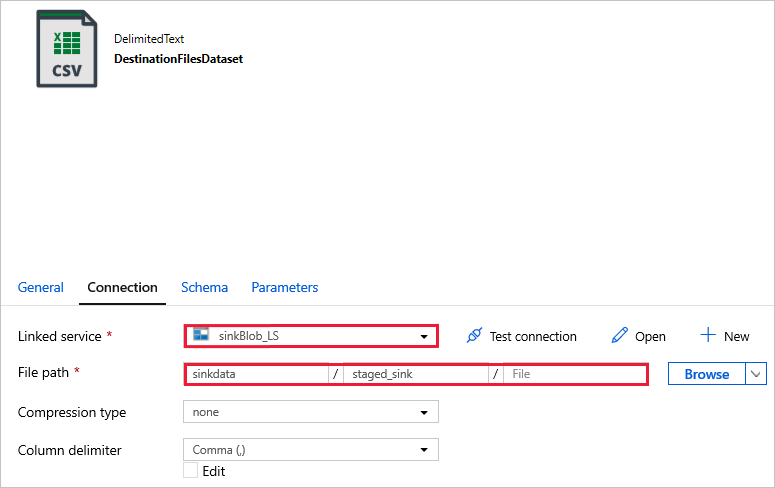
Selecteer Fouten opsporen om de pijplijn uit te voeren. U vindt de koppeling naar Databricks-logboeken voor gedetailleerdere Spark-logboeken.
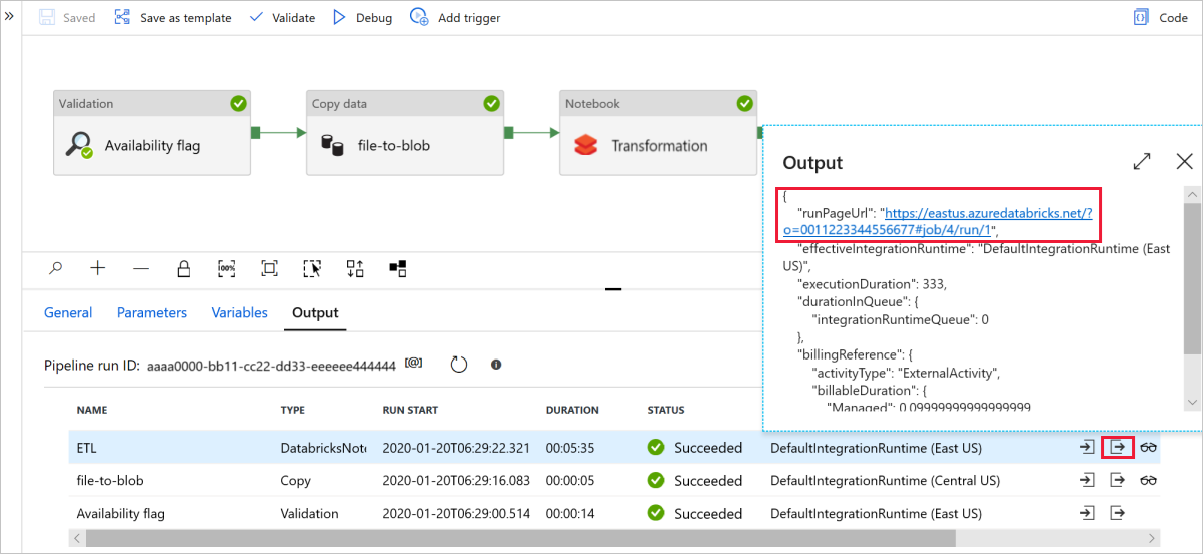
U kunt het gegevensbestand ook verifiëren met behulp van Azure Storage Explorer.
Notitie
Voor het correleren met Data Factory-pijplijnuitvoeringen voegt dit voorbeeld de pijplijnuitvoerings-id van de data factory toe aan de uitvoermap. Dit helpt bij het bijhouden van bestanden die door elke uitvoering worden gegenereerd.