Query's uitvoeren op gegevens in Azure Data Lake met behulp van Azure Data Explorer
Azure Data Lake Storage is een zeer schaalbare en kosteneffectieve Data Lake-oplossing voor big data-analyse. Het combineert de kracht van een bestandssysteem met hoge prestaties met enorme schaal en zuinigheid, zodat u minder tijd nodig hebt om inzicht te krijgen. Data Lake Storage Gen2 breidt Azure Blob Storage mogelijkheden uit en is geoptimaliseerd voor analyseworkloads.
Azure Data Explorer integreert met Azure Blob Storage en Azure Data Lake Storage (Gen1 en Gen2) en biedt snelle, in cache opgeslagen en geïndexeerde toegang tot gegevens die zijn opgeslagen in externe opslag. U kunt gegevens analyseren en er query's op uitvoeren zonder voorafgaande opname in Azure Data Explorer. U kunt ook tegelijkertijd een query uitvoeren op opgenomen en niet-opgenomen externe gegevens. Zie een externe tabel maken met behulp van de wizard Azure Data Explorer webinterface voor meer informatie. Zie externe tabellen voor een kort overzicht.
Tip
De beste queryprestaties vereisen gegevensopname in Azure Data Explorer. De mogelijkheid om query's uit te voeren op externe gegevens zonder voorafgaande opname, mag alleen worden gebruikt voor historische gegevens of gegevens die zelden worden opgevraagd. Optimaliseer de prestaties van uw externe gegevensquery's voor de beste resultaten.
Een externe tabel maken
Stel dat u veel CSV-bestanden hebt met historische informatie over producten die zijn opgeslagen in een magazijn en dat u een snelle analyse wilt uitvoeren om de vijf populairste producten van vorig jaar te vinden. In dit voorbeeld zien de CSV-bestanden er als volgt uit:
| Tijdstempel | ProductId | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3,5 inch DS/HD diskette |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
De bestanden worden opgeslagen in Azure Blob Storage mycompanystorage onder een container met de naam archivedproducts, gepartitioneerd op datum:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Als u rechtstreeks een KQL-query op deze CSV-bestanden wilt uitvoeren, gebruikt u de .create external table opdracht om een externe tabel in Azure Data Explorer te definiëren. Zie opdrachten voor externe tabellen voor meer informatie over de opdrachtopties voor het maken van externe tabellen.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
De externe tabel is nu zichtbaar in het linkerdeelvenster van de azure Data Explorer-webinterface:
Machtigingen voor externe tabellen
- De databasegebruiker kan een externe tabel maken. De maker van de tabel wordt automatisch de tabelbeheerder.
- De cluster-, database- of tabelbeheerder kan een bestaande tabel bewerken.
- Elke databasegebruiker of -lezer kan een query uitvoeren op een externe tabel.
Query's uitvoeren op een externe tabel
Zodra een externe tabel is gedefinieerd, kan de external_table() functie worden gebruikt om ernaar te verwijzen. De rest van de query is standaard Kusto-querytaal.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Query's uitvoeren op externe en opgenomen gegevens samen
U kunt een query uitvoeren op zowel externe tabellen als opgenomen gegevenstabellen binnen dezelfde query. U kunt join of union de externe tabel met andere gegevens uit Azure Data Explorer, SQL-servers of andere bronnen. Gebruik een let( ) statement om een verkorte naam toe te wijzen aan een externe tabelreferentie.
In het onderstaande voorbeeld is Products een opgenomen gegevenstabel en Is ArchivedProducts een externe tabel die we eerder hebben gedefinieerd:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Query's uitvoeren op hiërarchische gegevensindelingen
Met Azure Data Explorer kunt u query's uitvoeren op hiërarchische indelingen, zoals JSON, Parquet, Avroen ORC. Als u een hiërarchisch gegevensschema wilt toewijzen aan een extern tabelschema (als dit anders is), gebruikt u opdrachten voor externe tabeltoewijzingen. Als u bijvoorbeeld een query wilt uitvoeren op JSON-logboekbestanden met de volgende indeling:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
De definitie van de externe tabel ziet er als volgt uit:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Definieer een JSON-toewijzing waarmee gegevensvelden worden toegewezen aan externe tabeldefinitievelden:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Wanneer u een query uitvoert op de externe tabel, wordt de toewijzing aangeroepen en worden relevante gegevens toegewezen aan de kolommen van de externe tabel:
external_table('ApiCalls') | take 10
Zie gegevenstoewijzingen voor meer informatie over de toewijzingssyntaxis.
Externe tabel Query TaxiRides in het Help-cluster
Gebruik het testcluster help om verschillende mogelijkheden van Azure Data Explorer uit te proberen. Het Help-cluster bevat een externe tabeldefinitie voor een taxigegevensset in New York City met miljarden taxiritten.
Externe tabel TaxiRides maken
In deze sectie ziet u de query die wordt gebruikt voor het maken van de externe tabel TaxiRides in het Help-cluster . Omdat deze tabel al is gemaakt, kunt u deze sectie overslaan en rechtstreeks een query uitvoeren op taxiRides externe tabelgegevens.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
U kunt de gemaakte tabel TaxiRides vinden in het linkerdeelvenster van de Azure Data Explorer-webinterface:
Query TaxiRides externe tabelgegevens
Meld u aan bij https://dataexplorer.azure.com/clusters/help/databases/Samples.
Query TaxiRides externe tabel zonder partitionering
Voer deze query uit op de externe tabel TaxiRides om ritten voor elke dag van de week weer te geven in de hele gegevensset.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Deze query toont de drukste dag van de week. Omdat de gegevens niet zijn gepartitioneerd, kan het enkele minuten duren voordat de query resultaten retourneert.
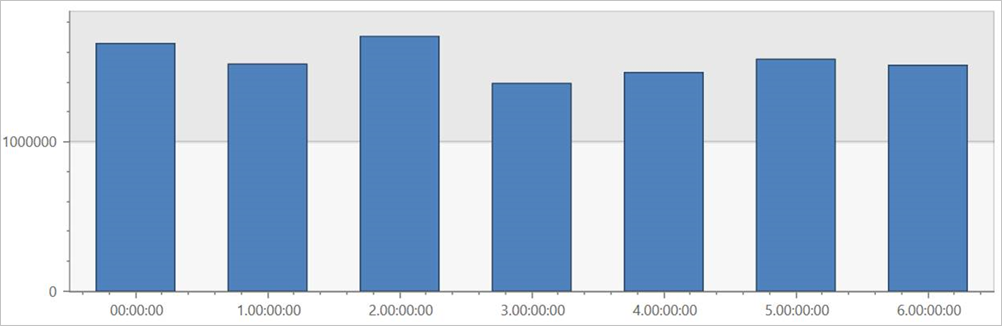
Externe tabel Query TaxiRides met partitionering
Voer deze query uit op de externe tabel TaxiRides om taxitypen (geel of groen) weer te geven die in januari 2017 zijn gebruikt.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Deze query maakt gebruik van partitionering, waardoor de querytijd en -prestaties worden geoptimaliseerd. De query filtert op een gepartitioneerde kolom (pickup_datetime) en retourneert resultaten binnen enkele seconden.
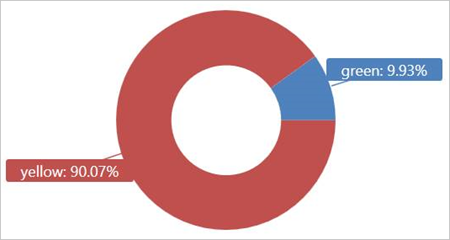
U kunt andere query's schrijven om uit te voeren op de externe tabel TaxiRides en meer informatie over de gegevens.
Queryprestaties optimaliseren
Optimaliseer de queryprestaties in de lake met behulp van de volgende best practices voor het uitvoeren van query's op externe gegevens.
Gegevensindeling
- Gebruik om de volgende redenen een kolomindeling voor analytische query's:
- Alleen de kolommen die relevant zijn voor een query kunnen worden gelezen.
- Met kolomcoderingstechnieken kunt u de gegevensgrootte aanzienlijk verminderen.
- Azure Data Explorer ondersteunt parquet- en ORC-kolomindelingen. Parquet-indeling wordt voorgesteld vanwege een geoptimaliseerde implementatie.
Azure-regio
Controleer of externe gegevens zich in dezelfde Azure-regio bevinden als uw Azure Data Explorer-cluster. Deze installatie vermindert de kosten en de tijd voor het ophalen van gegevens.
Bestandsgrootte
De optimale bestandsgrootte is honderden Mb (maximaal 1 GB) per bestand. Vermijd veel kleine bestanden waarvoor onnodige overhead nodig is, zoals een langzamer proces voor bestandsinventarisatie en beperkt gebruik van de kolomindeling. Het aantal bestanden moet groter zijn dan het aantal CPU-kernen in uw Azure Data Explorer-cluster.
Compressie
Gebruik compressie om de hoeveelheid gegevens te verminderen die uit de externe opslag wordt opgehaald. Voor parquet-indeling gebruikt u het interne Parquet-compressiemechanisme waarmee kolomgroepen afzonderlijk worden gecomprimeerd, zodat u ze afzonderlijk kunt lezen. Als u het gebruik van het compressiemechanisme wilt valideren, controleert u of de bestanden de volgende namen hebben: <bestandsnaam.gz.parquet> of <bestandsnaam.snappy.parquet> en niet <bestandsnaam.parquet.gz>.
Partitionering
Organiseer uw gegevens met behulp van mappartities waarmee de query irrelevante paden kan overslaan. Houd bij het plannen van partitionering rekening met de bestandsgrootte en algemene filters in uw query's, zoals tijdstempel of tenant-id.
VM-grootte
Selecteer VM-SKU's met meer kernen en hogere netwerkdoorvoer (geheugen is minder belangrijk). Zie De juiste VM-SKU voor uw Azure Data Explorer-cluster selecteren voor meer informatie.