Tolerantie en herstel na noodgevallen in Azure Web PubSub Service
Tolerantie en herstel na noodgevallen is een algemene behoefte voor online systemen. Azure Web PubSub Service garandeert al een beschikbaarheid van 99,9%, maar het is nog steeds een regionale service. Wanneer er sprake is van een storing in de hele regio, is het essentieel dat de service realtime berichten in een andere regio blijft verwerken.
Voor regionaal herstel na noodgevallen raden we de volgende twee benaderingen aan:
- Geo-replicatie inschakelen (eenvoudige manier). Met deze functie wordt automatisch regionale failover voor u afgehandeld. Wanneer deze optie is ingeschakeld, blijft er slechts één Azure SignalR-exemplaar en worden er geen codewijzigingen geïntroduceerd. Controleer geo-replicatie op details.
- Gebruik meerdere eindpunten. In dit document leert u hoe u dit doet
Architectuur met hoge beschikbaarheid voor Web PubSub-service
Er zijn twee typische patronen met de Web PubSub-service:
- Een is client-serverpatroon dat clients gebeurtenissen verzenden naar de server en server pusht berichten naar de clients.
- Een ander is client-clientpatroon dat clients pub/subberichten via de Web PubSub-service naar andere clients verzenden.
In de onderstaande secties worden verschillende manieren beschreven voor deze twee patronen voor herstel na noodgevallen
Architectuur met hoge beschikbaarheid voor client-serverpatroon
Als u tolerantie tussen regio's voor de Web PubSub-service wilt hebben, moet u meerdere service-exemplaren instellen in verschillende regio's. Dus wanneer één regio niet actief is, kunnen de andere worden gebruikt als back-up.
Een typische instelling voor scenario's voor meerdere regio's is het hebben van twee (of meer) paren web pubsub-service-exemplaren en app-servers.
Binnen elke gekoppelde app-server en Web PubSub-service bevinden zich in dezelfde regio en stelt de Web PubSub-service de gebeurtenis-handler upstream in op de app-server in dezelfde regio.
Om de architectuur beter te illustreren, roepen we de Web PubSub-service de primaire service aan op de app-server in hetzelfde paar. En we noemen Web PubSub-services in andere paren als de secundaire services voor de app-server.
De toepassingsserver kan de API voor servicestatuscontrole gebruiken om te detecteren of de primaire en secundaire services in orde zijn of niet. Voor een Web PubSub-service die wordt aangeroepen demo, retourneert het eindpunt https://demo.webpubsub.azure.com/api/health bijvoorbeeld 200 wanneer de service in orde is. De app-server kan periodiek de eindpunten aanroepen of de eindpunten op aanvraag aanroepen om te controleren of de eindpunten in orde zijn. WebSocket-clients onderhandelen meestal eerst met de toepassingsserver om de URL te verkrijgen die verbinding maakt met de Web PubSub-service. De toepassing gebruikt deze onderhandelingsstap om een failover van de clients uit te voeren naar andere gezonde secundaire services. Gedetailleerde stappen zoals hieronder:
- Wanneer een client met de app-server onderhandelt , moet de app-server alleen primaire Web PubSub-service-eindpunten retourneren, zodat clients alleen verbinding maken met primaire eindpunten.
- Wanneer het primaire exemplaar niet beschikbaar is, moet u onderhandelen over een gezond secundair eindpunt, zodat de client nog steeds verbindingen kan maken en de client verbinding maakt met het secundaire eindpunt.
- Wanneer het primaire exemplaar is ingeschakeld, moet u onderhandelen over het goede primaire eindpunt, zodat clients nu verbinding kunnen maken met het primaire eindpunt
- Wanneer app-server berichten uitzendt, moet deze berichten uitzenden naar alle goede eindpunten, inclusief zowel primaire als secundaire.
- App-server kan verbindingen sluiten die zijn verbonden met secundaire eindpunten om te forceren dat de clients opnieuw verbinding maken met het gezonde primaire eindpunt.
Met deze topologie kan bericht van één server nog steeds aan alle clients worden geleverd, omdat alle app-servers en Web PubSub-service-exemplaren onderling zijn verbonden.
We hebben de strategie nog niet geïntegreerd in de SDK, dus voorlopig moet de toepassing deze strategie zelf implementeren.
Kortom, wat de toepassingszijde moet implementeren is:
- Statuscontrole. De toepassing kan controleren of de service in orde is met behulp van servicestatuscontrole-API regelmatig op de achtergrond of op aanvraag voor elke onderhandelingsoproep .
- Onderhandelen over logica. De toepassing retourneert standaard een gezond primair eindpunt. Wanneer het primaire eindpunt niet beschikbaar is, retourneert de toepassing een gezond secundair eindpunt.
- Broadcast-logica. Wanneer berichten naar meerdere clients worden verzonden, moet de toepassing ervoor zorgen dat berichten worden uitgezonden naar alle goede eindpunten.
Hieronder volgt een diagram waarin deze topologie wordt weergegeven:
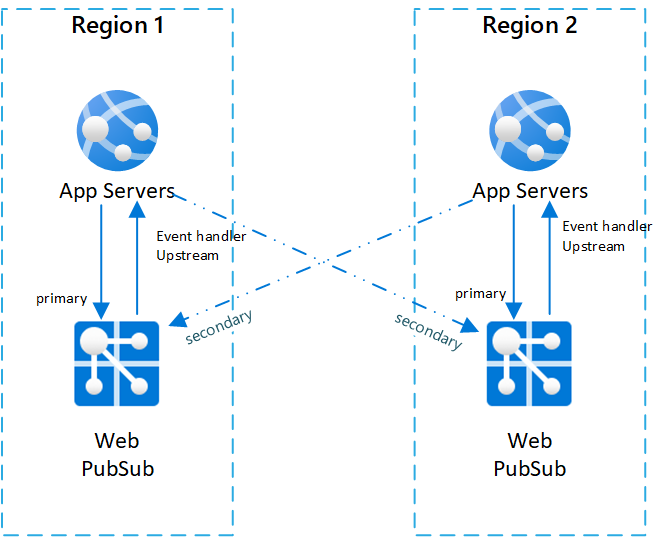
Failover-volgorde en best practice
U hebt nu de instelling van de juiste systeem-topologie. Wanneer het ene Web PubSub-service-exemplaar uitvalt, wordt onlineverkeer doorgestuurd naar andere exemplaren. Dit is wat er gebeurt wanneer een primaire instantie niet actief is (en na enige tijd herstelt):
- Het primaire service-exemplaar is niet beschikbaar, alle clients die met dit exemplaar zijn verbonden, worden verwijderd.
- Nieuwe clients of opnieuw verbinding maken met de app-server
- App-server detecteert dat het primaire service-exemplaar niet beschikbaar is en onderhandelt niet meer over het retourneren van dit eindpunt en begint met het retourneren van een gezond secundair eindpunt.
- Clients maken verbinding met het secundaire exemplaar.
- Het secundaire exemplaar neemt nu alle online verkeer over. Alle berichten van de server aan clients kunnen nog steeds worden afgeleverd als de secundaire is verbonden met alle app-servers. Client-naar-server-gebeurtenisberichten worden echter alleen verzonden naar de upstream-app-server in dezelfde regio.
- Nadat het primaire exemplaar is hersteld en weer online is, detecteert de app-server dat het primaire exemplaar weer in orde is. Het primaire eindpunt wordt nu opnieuw geretourneerd zodat nieuwe clients weer met primair worden verbonden. Bestaande clients worden echter niet verwijderd en blijven verbonden met secundaire clients totdat ze zichzelf loskoppelen.
In de onderstaande diagrammen ziet u hoe failover wordt uitgevoerd:
Fig.1 Vóór failover 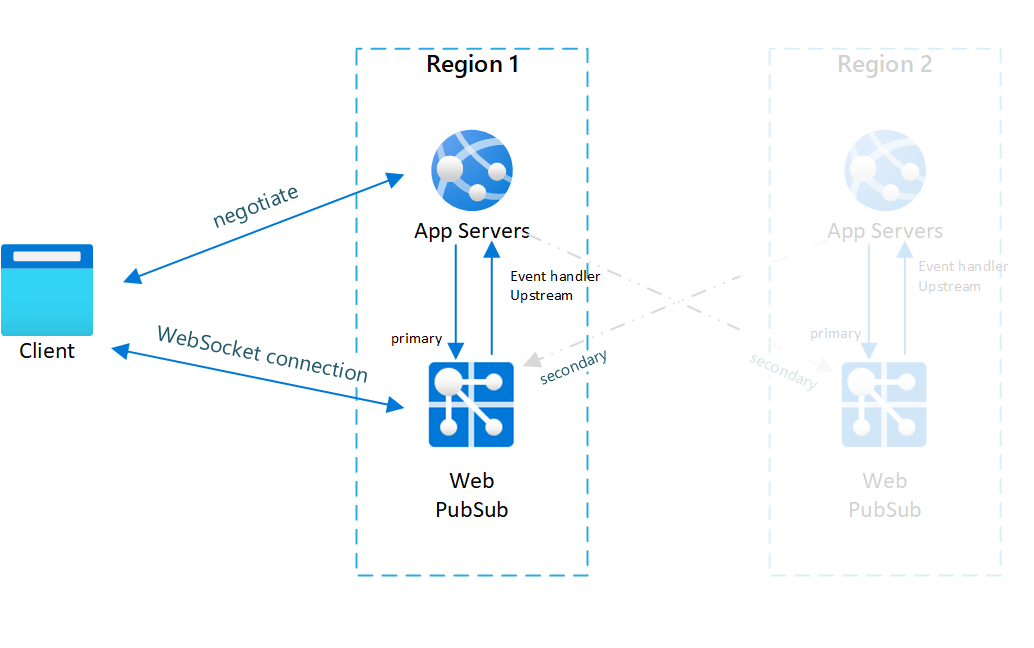
Fig.2 Na failover 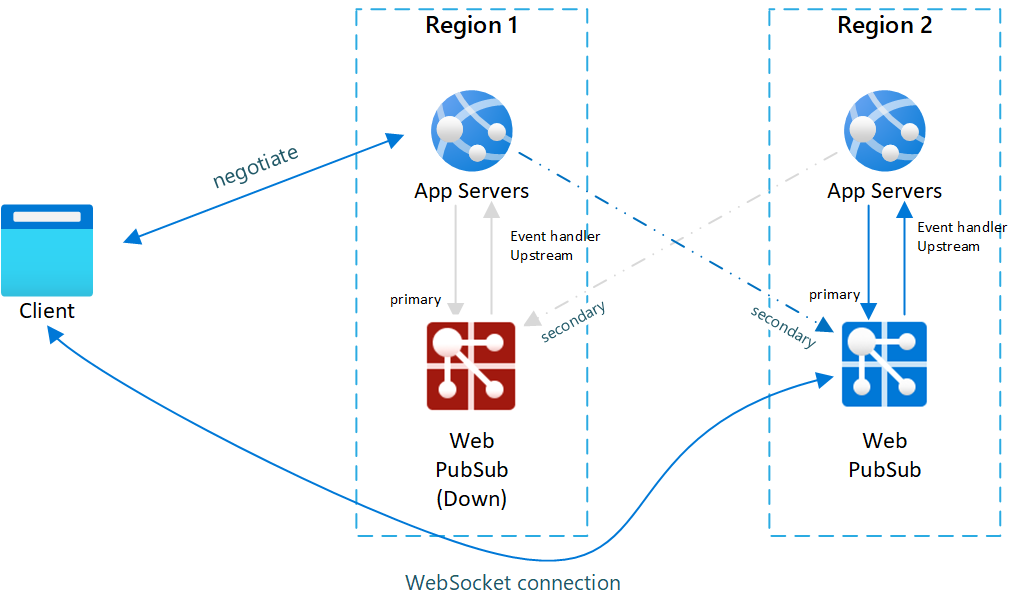
Fig.3 Korte tijd na primaire herstelbewerkingen 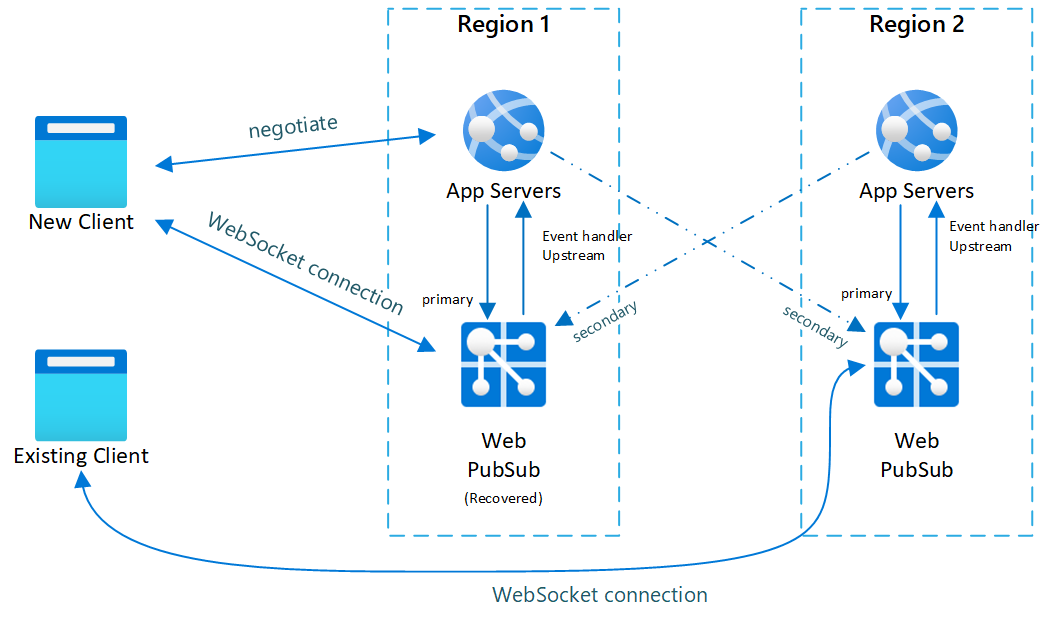
U kunt in normale gevallen alleen primaire app-server en Web PubSub-service online verkeer (in blauw) zien.
Na een failover worden de secundaire app-server en de Web PubSub-service ook actief. Nadat de primaire Web PubSub-service weer online is, maken nieuwe clients verbinding met primaire Web PubSub. Maar bestaande clients hebben nog steeds verbinding naar secundair, waardoor beide exemplaren verkeer hebben.
Nadat alle bestaande clients de verbinding verbreken, is uw systeem weer normaal (figuur 1).
Er zijn twee belangrijke patronen voor het implementeren van een regio-overkoepelende architectuur voor hoge beschikbaarheid:
- Het eerste is om een paar app-server- en Web PubSub-service-exemplaren te hebben die al het onlineverkeer gebruiken en een ander paar als back-up hebben (actief/passief genoemd, geïllustreerd in Fig.1).
- De andere is om twee (of meer) paren app-servers en Web PubSub-service-exemplaren te hebben, die elk deel uitmaken van het onlineverkeer en dienen als back-up voor andere paren (actief/actief genoemd, vergelijkbaar met Fig.3).
De Web PubSub-service kan beide patronen ondersteunen. Het belangrijkste verschil is hoe u app-servers implementeert. Als app-servers actief/passief zijn, is de Web PubSub-service ook actief/passief (omdat de primaire app-server alleen het primaire Web PubSub-service-exemplaar retourneert). Als app-servers actief/actief zijn, is de Web PubSub-service ook actief/actief (omdat alle app-servers hun eigen primaire Web PubSub-exemplaren retourneren, zodat ze allemaal verkeer kunnen krijgen).
Let op, ongeacht de patronen die u wilt gebruiken, u moet elk Web PubSub-service-exemplaar als primaire rol verbinden met een app-server.
Vanwege de aard van de WebSocket-verbinding (het is een lange verbinding), ondervinden clients ook een storing in de verbinding wanneer zich een noodgeval voordoet en failover plaatsvindt. U moet dergelijke gevallen aan clientzijde afhandelen om de situatie transparant te maken voor uw eindgebruikers. Bijvoorbeeld, opnieuw verbinden nadat een verbinding is gesloten.
Architectuur met hoge beschikbaarheid voor client-clientpatroon
Voor client-clientpatroon is het momenteel nog niet mogelijk om een noodherstel na noodgeval met meerdere exemplaren te ondersteunen. Als u hoge beschikbaarheidsvereisten hebt, kunt u overwegen om geo-replicatie te gebruiken.
Een failover testen
Volg de stappen om de failover te activeren:
- Schakel openbare netwerktoegang uit op het tabblad Netwerken voor de primaire resource in de portal. Als voor de resource een privénetwerk is ingeschakeld, gebruikt u regels voor toegangsbeheer om al het verkeer te weigeren.
- Start de primaire resource opnieuw op.
Volgende stappen
In dit artikel hebt u geleerd hoe u uw toepassing configureert om tolerantie te bereiken voor de Web PubSub-service.
Gebruik deze resources om te beginnen met het bouwen van uw eigen toepassing: