Notitie
Dit artikel is afhankelijk van een opensource-bibliotheek die wordt gehost op GitHub op: https://github.com/mspnp/spark-monitoring.
De oorspronkelijke bibliotheek ondersteunt Azure Databricks Runtimes 10.x (Spark 3.2.x) en eerder.
Databricks heeft een bijgewerkte versie bijgedragen ter ondersteuning van Azure Databricks Runtimes 11.0 (Spark 3.3.x) en hoger op de l4jv2 vertakking op: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Houd er rekening mee dat de release 11.0 niet achterwaarts compatibel is vanwege de verschillende logboekregistratiesystemen die worden gebruikt in de Databricks Runtimes. Zorg ervoor dat u de juiste build gebruikt voor uw Databricks Runtime. De bibliotheek en GitHub-opslagplaats bevinden zich in de onderhoudsmodus. Er zijn geen plannen voor verdere releases en ondersteuning voor problemen is alleen best-effort. Neem contact op azure-spark-monitoring-help@databricks.commet eventuele aanvullende vragen over de bibliotheek of de roadmap voor het bewaken en vastleggen van uw Azure Databricks-omgevingen.
Deze oplossing demonstreert waarneembaarheidspatronen en metrische gegevens om de verwerkingsprestaties van een big data-systeem te verbeteren dat gebruikmaakt van Azure Databricks.
Architectuur

Een Visio-bestand van deze architectuur downloaden.
Workflow
De oplossing omvat de volgende stappen:
De server verzendt een groot GZIP-bestand dat is gegroepeerd op klant naar de bronmap in Azure Data Lake Storage.
Data Lake Storage verzendt vervolgens een uitgepakt klantbestand naar Azure Event Grid, waardoor de klantbestandsgegevens in verschillende berichten worden omgezet.
Azure Event Grid verzendt de berichten naar de Azure Queue Storage-service, waarin ze in een wachtrij worden opgeslagen.
Azure Queue Storage verzendt de wachtrij naar het Azure Databricks Data Analytics-platform voor verwerking.
Met Azure Databricks worden wachtrijgegevens uitgepakt en verwerkt in een verwerkt bestand dat wordt teruggestuurd naar Data Lake Storage:
Als het verwerkte bestand geldig is, wordt het in de map Landing geplaatst.
Anders wordt het bestand in de mapstructuur Ongeldig weergegeven. In eerste instantie gaat het bestand in de submap Opnieuw proberen en probeert Data Lake Storage het verwerken van bestanden van klanten opnieuw te verwerken (stap 2). Als een paar nieuwe pogingen nog steeds leidt tot Azure Databricks die verwerkte bestanden retourneren die niet geldig zijn, wordt het verwerkte bestand in de submap Fout weergegeven.
Omdat Azure Databricks in de vorige stap gegevens uitpakt en verwerkt, worden ook toepassingslogboeken en metrische gegevens naar Azure Monitor verzonden voor opslag.
Een Azure Log Analytics-werkruimte past Kusto-query's toe op de toepassingslogboeken en metrische gegevens van Azure Monitor voor probleemoplossing en uitgebreide diagnostische gegevens.
Onderdelen
- Azure Data Lake Storage is een set mogelijkheden die is toegewezen aan big data-analyses.
- Met Azure Event Grid kan een ontwikkelaar eenvoudig toepassingen bouwen met op gebeurtenissen gebaseerde architecturen.
- Azure Queue Storage is een service voor het opslaan van grote aantallen berichten. Hiermee hebt u overal ter wereld toegang tot berichten via geverifieerde aanroepen via HTTP of HTTPS. U kunt wachtrijen gebruiken om een achterstand van werk te maken om asynchroon te verwerken.
- Azure Databricks is een platform voor gegevensanalyse dat is geoptimaliseerd voor het Azure-cloudplatform. Een van de twee omgevingen die Azure Databricks biedt voor het ontwikkelen van gegevensintensieve toepassingen is Azure Databricks Workspace, een op Apache Spark gebaseerde unified analytics-engine voor grootschalige gegevensverwerking.
- Azure Monitor verzamelt en analyseert app-telemetrie, zoals metrische prestatiegegevens en activiteitenlogboeken.
- Azure Log Analytics is een hulpprogramma dat wordt gebruikt om logboekquery's met gegevens te bewerken en uit te voeren.
Scenariodetails
Uw ontwikkelteam kan gebruik maken van waarneembaarheidspatronen en metrische gegevens om knelpunten te vinden en de prestaties van een big data-systeem te verbeteren. Uw team moet belastingstests uitvoeren voor een grote hoeveelheid metrische gegevens in een toepassing op grote schaal.
Dit scenario biedt richtlijnen voor het afstemmen van prestaties. Omdat het scenario een prestatievraag voor logboekregistratie per klant vormt, gebruikt het Azure Databricks, waarmee deze items robuust kunnen worden bewaakt:
- Metrische gegevens voor aangepaste toepassingen
- Gebeurtenissen van streamingquery's
- Toepassingslogboekberichten
Azure Databricks kan deze bewakingsgegevens verzenden naar verschillende logboekregistratieservices, zoals Azure Log Analytics.
In dit scenario wordt een overzicht gegeven van de opname van een grote set gegevens die is gegroepeerd op klant en is opgeslagen in een GZIP-archiefbestand. Gedetailleerde logboeken zijn niet beschikbaar vanuit Azure Databricks buiten de realtime Apache Spark-gebruikersinterface™, dus uw team heeft een manier nodig om alle gegevens voor elke klant op te slaan en vervolgens te benchmarken en vergelijken. Met een scenario voor grote gegevens is het belangrijk om een optimale combinatie-uitvoerdergroep en VM-grootte (virtual machine) te vinden voor de snelste verwerkingstijd. Voor dit bedrijfsscenario is de algehele toepassing afhankelijk van de snelheid van opname- en queryvereisten, zodat de systeemdoorvoer niet onverwacht afneemt met een toenemend werkvolume. Het scenario moet garanderen dat het systeem voldoet aan serviceovereenkomsten (SLA's) die zijn vastgelegd met uw klanten.
Potentiële gebruikscases
Scenario's die kunnen profiteren van deze oplossing zijn onder andere:
- Systeemstatuscontrole.
- Prestatieonderhoud.
- Dagelijkse systeemgebruik bewaken.
- Trends opsporen die toekomstige problemen kunnen veroorzaken als dit niet is opgelost.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Houd rekening met deze punten bij het overwegen van deze architectuur:
Azure Databricks kan automatisch de rekenresources toewijzen die nodig zijn voor een grote taak, waardoor problemen worden voorkomen die andere oplossingen introduceren. Met automatische schaalaanpassing op Apache Spark die is geoptimaliseerd voor Databricks, kan overmatige inrichting bijvoorbeeld leiden tot een suboptimaal gebruik van resources. Of u weet mogelijk niet hoeveel uitvoerders vereist zijn voor een taak.
Een wachtrijbericht in Azure Queue Storage kan maximaal 64 kB groot zijn. Een wachtrij kan miljoenen wachtrijberichten bevatten, tot aan de totale capaciteitslimiet van een opslagaccount.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie de controlelijst ontwerpbeoordeling voor Kostenoptimalisatie voor meer informatie.
Gebruik de Azure-prijscalculator om de kosten voor het implementeren van deze oplossing te schatten.
Dit scenario implementeren
Notitie
De implementatiestappen die hier worden beschreven, zijn alleen van toepassing op Azure Databricks, Azure Monitor en Azure Log Analytics. De implementatie van de andere onderdelen wordt niet behandeld in dit artikel.
Als u alle logboeken en informatie over het proces wilt ophalen, stelt u Azure Log Analytics en de Azure Databricks-bewakingsbibliotheek in. De bewakingsbibliotheek streamt gebeurtenissen op Apache Spark-niveau en metrische gegevens van Spark Structured Streaming van uw taken naar Azure Monitor. U hoeft geen wijzigingen aan te brengen in uw toepassingscode voor deze gebeurtenissen en metrische gegevens.
De stappen voor het instellen van prestatieafstemming voor een big data-systeem zijn als volgt:
Maak in Azure Portal een Azure Databricks-werkruimte. Kopieer de Azure-abonnements-id (een GUID (Globally Unique Identifier) en sla deze op, de naam van de resourcegroep, de naam van de Databricks-werkruimte en de URL van de werkruimteportal voor later gebruik.
Ga in een webbrowser naar de URL van de Databricks-werkruimte en genereer een persoonlijk databricks-toegangstoken. Kopieer en sla de tokentekenreeks op die wordt weergegeven (die begint met
dapien een hexadecimale waarde van 32 tekens) voor later gebruik.Kloon de mspnp/spark-monitoring GitHub-opslagplaats naar uw lokale computer. Deze opslagplaats bevat de broncode voor de volgende onderdelen:
- De Azure Resource Manager-sjabloon (ARM-sjabloon) voor het maken van een Azure Log Analytics-werkruimte, waarmee ook vooraf gemaakte query's worden geïnstalleerd voor het verzamelen van metrische Spark-gegevens
- Azure Databricks-bewakingsbibliotheken
- De voorbeeldtoepassing voor het verzenden van metrische toepassingsgegevens en toepassingslogboeken van Azure Databricks naar Azure Monitor
Maak met behulp van de Azure CLI-opdracht voor het implementeren van een ARM-sjabloon een Azure Log Analytics-werkruimte met vooraf gedefinieerde metrische Spark-query's. Kopieer en sla in de uitvoer van de opdracht de gegenereerde naam op voor de nieuwe Log Analytics-werkruimte (in de indeling spark-monitoring-randomized-string><).
Kopieer en sla uw Log Analytics-werkruimte-id en -sleutel op in Azure Portal voor later gebruik.
Installeer de Community Edition van IntelliJ IDEA, een integrated development environment (IDE) met ingebouwde ondersteuning voor de Java Development Kit (JDK) en Apache Maven. Voeg de Scala-invoegtoepassing toe.
Bouw met Behulp van IntelliJ IDEA de Azure Databricks-bewakingsbibliotheken. Als u de daadwerkelijke buildstap wilt uitvoeren, selecteert u Het hulpprogramma weergeven>van Windows>Maven om het venster Maven-hulpprogramma's weer te geven en selecteert u vervolgens het maven-doel>mvn-pakket uitvoeren.
Installeer de Azure Databricks CLI met behulp van een installatieprogramma voor Python-pakketten en stel verificatie in met het persoonlijke toegangstoken van Databricks dat u eerder hebt gekopieerd.
Configureer de Azure Databricks-werkruimte door het Init-script van Databricks te wijzigen met de Databricks- en Log Analytics-waarden die u eerder hebt gekopieerd, en gebruik vervolgens de Azure Databricks CLI om het init-script en de Azure Databricks-bewakingsbibliotheken naar uw Databricks-werkruimte te kopiëren.
Maak en configureer een Azure Databricks-cluster in uw Databricks-werkruimteportal.
Bouw in IntelliJ IDEA de voorbeeldtoepassing met behulp van Maven. Voer vervolgens in uw Databricks-werkruimteportal de voorbeeldtoepassing uit om voorbeeldlogboeken en metrische gegevens voor Azure Monitor te genereren.
Terwijl de voorbeeldtaak wordt uitgevoerd in Azure Databricks, gaat u naar Azure Portal om de gebeurtenistypen (toepassingslogboeken en metrische gegevens) in de Log Analytics-interface weer te geven en er query's op uit te voeren:
- Selecteer aangepaste tabellenlogboeken om het tabelschema voor Spark-listener-gebeurtenissen (SparkListenerEvent_CL), Spark-logboekregistratie-gebeurtenissen (SparkLoggingEvent_CL) en metrische Spark-gegevens (SparkMetric_CL) weer te geven.>
- Selecteer Query Explorer>Opgeslagen query's>spark-metrische gegevens om de query's weer te geven en uit te voeren die zijn toegevoegd toen u de Log Analytics-werkruimte maakte.
Lees meer over het weergeven en uitvoeren van vooraf samengestelde en aangepaste query's in de volgende sectie.
Query's uitvoeren op de logboeken en metrische gegevens in Azure Log Analytics
Vooraf gemaakte query's openen
Hieronder vindt u de vooraf gemaakte querynamen voor het ophalen van metrische Spark-gegevens.
- % CPU-tijd per uitvoerder
- % deserialiseren tijd per uitvoerder
- % JVM-tijd per uitvoerder
- % serialiseertijd per uitvoerder
- Overloop van schijfbytes
- Fouttraceringen (ongeldige record of ongeldige bestanden)
- Bestandssysteem bytes lezen per executor
- Bestandssysteembytes schrijven per uitvoerder
- Taakfouten per taak
- Taaklatentie per taak (batchduur)
- Taakdoorvoer
- Uitvoerders uitvoeren
- Bytes in willekeurige volgorde lezen
- Bytes lezen per uitvoerder in willekeurige volgorde
- Bytes in willekeurige volgorde lezen naar schijf per uitvoerder
- Direct geheugen van client in willekeurige volgorde
- Shuffle Client Memory Per Executor
- Willekeurige schijfbytes overlopen per uitvoerder
- Heap-geheugen per uitvoerder in willekeurige volgorde
- Overloop van geheugenbytes per uitvoerder in willekeurige volgorde
- Faselatentie per fase (faseduur)
- Fasedoorvoer per fase
- Streamingfouten per stream
- Streaminglatentie per stream
- Invoerrijen voor streamingdoorvoer per seconde
- Verwerkte rijen voor streamingdoorvoer per seconde
- Taakuitvoering per host optellen
- Tijd voor deserialisatie van taken
- Taakfouten per fase
- Rekentijd van taakuitvoering (tijd voor scheeftrekken van gegevens)
- Gelezen taakinvoerbytes
- Taaklatentie per fase (duur van taken)
- Serialisatietijd van taakresultaten
- Vertragingslatentie van taakplanner
- Gelezen taken in willekeurige bytes
- Taak in willekeurige volgorde geschreven bytes
- Leestijd van taak in willekeurige volgorde
- Schrijftijd van taak in willekeurige volgorde
- Taakdoorvoer (som van taken per fase)
- Taken per uitvoerder (som van taken per uitvoerder)
- Taken per fase
Aangepaste query's schrijven
U kunt ook uw eigen query's schrijven in Kusto-querytaal (KQL). Selecteer het bovenste middelste deelvenster, dat bewerkbaar is en pas de query aan uw behoeften aan.
Met de volgende twee query's worden gegevens opgehaald uit de Spark-logboekregistratie-gebeurtenissen:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Deze twee voorbeelden zijn query's in het metrische Spark-logboek:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Queryterminologie
In de volgende tabel worden enkele termen beschreven die worden gebruikt bij het maken van een query van toepassingslogboeken en metrische gegevens.
| Term | Id | Opmerkingen |
|---|---|---|
| Cluster_init | Toepassings-id | |
| Queue | Uitvoerings-id | Eén uitvoerings-id is gelijk aan meerdere batches. |
| Batch | Batch-id | Eén batch is gelijk aan twee taken. |
| Project | Taak-id | Eén taak is gelijk aan twee fasen. |
| Fase | Fase-id | Eén fase heeft 100-200 taak-id's, afhankelijk van de taak (lezen, willekeurige volgorde of schrijven). |
| Opdrachten | Taak-id | Eén taak is toegewezen aan één uitvoerder. Eén taak wordt toegewezen om een partitionBy voor één partitie uit te voeren. Voor ongeveer 200 klanten moeten er 200 taken zijn. |
De volgende secties bevatten de typische metrische gegevens die in dit scenario worden gebruikt voor het bewaken van de doorvoer van het systeem, de uitvoeringsstatus van spark-taken en het gebruik van systeemresources.
Systeemdoorvoer
| Naam | Meting | Eenheden |
|---|---|---|
| Stroomdoorvoer | Gemiddelde invoersnelheid ten opzichte van het gemiddelde verwerkte tarief per minuut | Rijen per minuut |
| Taakduur | Gemiddelde duur van spark-taken per minuut | Duur per minuut |
| Aantal taken | Gemiddeld aantal beëindigde Spark-taken per minuut | Aantal taken per minuut |
| Duur van fase | Gemiddelde duur van voltooide fasen per minuut | Duur per minuut |
| Aantal fasen | Gemiddeld aantal voltooide fasen per minuut | Aantal fasen per minuut |
| Taakduur | Gemiddelde duur van voltooide taken per minuut | Duur per minuut |
| Aantal taken | Gemiddeld aantal voltooide taken per minuut | Aantal taken per minuut |
Uitvoeringsstatus van Spark-taak
| Naam | Meting | Eenheden |
|---|---|---|
| Aantal Scheduler-pools | Aantal afzonderlijke scheduler-pools per minuut (aantal wachtrijen dat wordt uitgevoerd) | Aantal plannerpools |
| Aantal actieve uitvoerders | Aantal actieve uitvoerders per minuut | Aantal actieve uitvoerders |
| Fouttracering | Alle foutenlogboeken met Error niveau en de bijbehorende taken/fase-id (weergegeven in thread_name_s) |
Gebruik van systeembronnen
| Naam | Meting | Eenheden |
|---|---|---|
| Gemiddeld CPU-gebruik per uitvoerder/algemeen | Percentage CPU dat per uitvoerder per minuut wordt gebruikt | % per minuut |
| Gemiddeld gebruikt direct geheugen (MB) per host | Gemiddeld gebruikt direct geheugen per uitvoerders per minuut | MB per minuut |
| Overloopgeheugen per host | Gemiddeld overgelopen geheugen per uitvoerder | MB per minuut |
| De impact op scheeftrekken van gegevens controleren op de duur | Meetbereik en verschil van het 70e-90e percentiel en het 90e-100e percentiel in de duur van taken | Nettoverschil tussen 100%, 90% en 70%; percentageverschil tussen 100%, 90% en 70% |
Bepaal hoe de klantinvoer, die is gecombineerd in een GZIP-archiefbestand, koppelt aan een bepaald Azure Databricks-uitvoerbestand, omdat Azure Databricks de hele batchbewerking als een eenheid verwerkt. Hier past u granulariteit toe op de tracering. U gebruikt ook aangepaste metrische gegevens om één uitvoerbestand te traceren naar het oorspronkelijke invoerbestand.
Zie Visualisaties in de dashboards op deze website voor gedetailleerdere definities van elke metrische waarde of zie de sectie Metrische gegevens in de Apache Spark-documentatie.
Opties voor het afstemmen van prestaties evalueren
Basislijndefinitie
U en uw ontwikkelteam moeten een basislijn instellen, zodat u toekomstige statussen van de toepassing kunt vergelijken.
Meet de prestaties van uw toepassing kwantitatief. In dit scenario is de belangrijkste metrische waarde de latentie van taken, wat typisch is voor de meeste gegevensvoorverwerking en -opname. Probeer de verwerkingstijd te versnellen en de focus te richten op het meten van latentie, zoals in het onderstaande diagram:
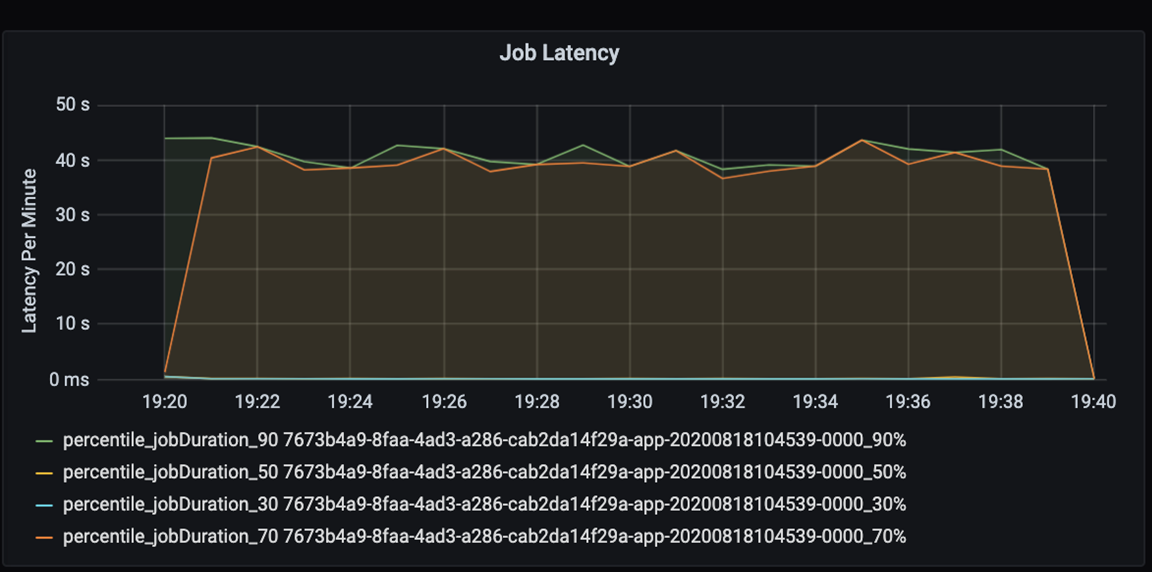
Meet de uitvoeringslatentie voor een taak: een grove weergave van de algehele taakprestaties en de uitvoeringsduur van de taak van begin tot voltooiing (microbatchtijd). In de bovenstaande grafiek duurt het ongeveer 40 seconden om de taak te verwerken met de 19:30 markering.
Als u deze 40 seconden nader bekijkt, ziet u de onderstaande gegevens voor fasen:
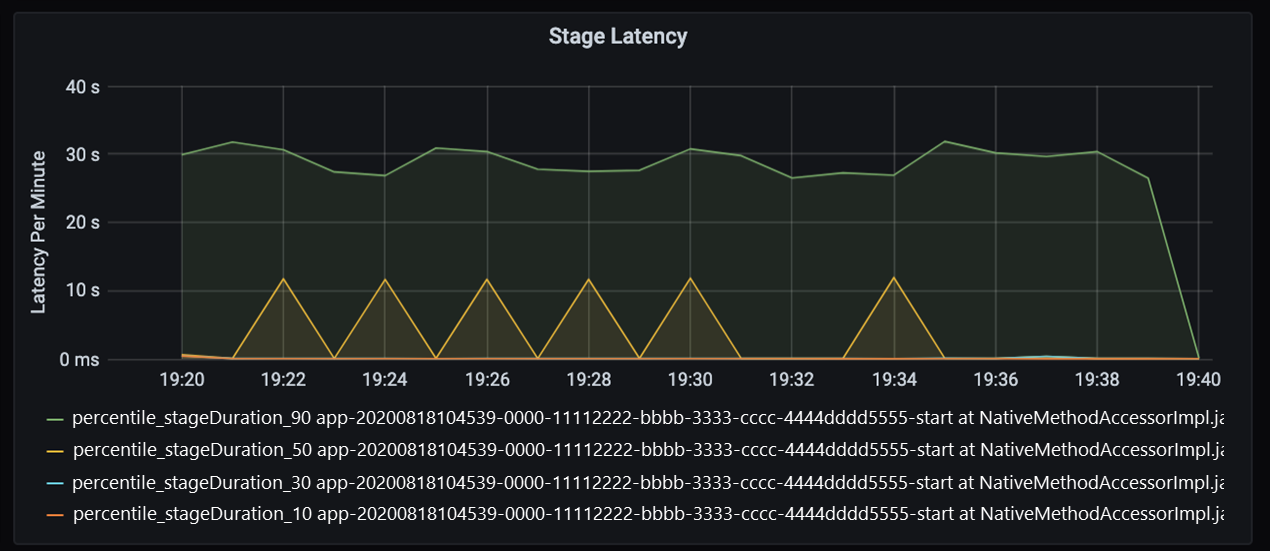
Bij de markering van 19:30 zijn er twee fasen: een oranje fase van 10 seconden en een groene fase van 30 seconden. Controleer of een fasepieken, omdat een piek een vertraging in een fase aangeeft.
Onderzoek wanneer een bepaalde fase langzaam wordt uitgevoerd. In het partitioneringsscenario zijn er meestal ten minste twee fasen: één fase om een bestand te lezen en de andere fase om het bestand te verdelen, partitioneren en schrijven. Als u een hoge faselatentie hebt, meestal in de schrijffase, kan er een knelpunt optreden tijdens het partitioneren.
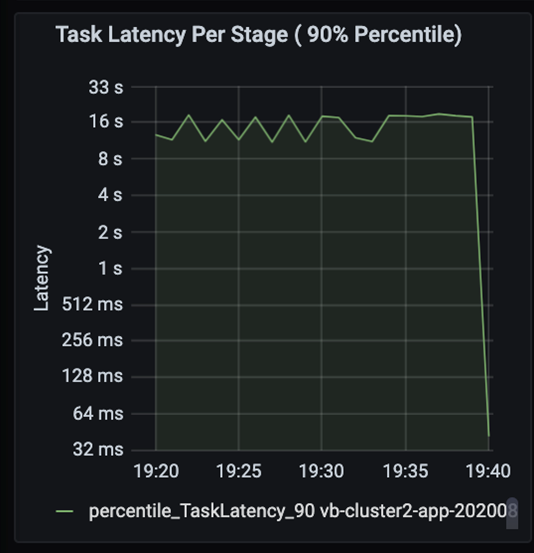
Bekijk de taken als de fasen in een taak die opeenvolgend worden uitgevoerd, waarbij eerdere fasen latere fasen blokkeren. Als in een fase een willekeurige partitie langzamer wordt uitgevoerd dan andere taken, moeten alle taken in het cluster wachten tot de tragere taak is voltooid voordat de fase is voltooid. Taken zijn vervolgens een manier om gegevens scheeftrekken en mogelijke knelpunten te bewaken. In de bovenstaande grafiek ziet u dat alle taken gelijkmatig zijn verdeeld.
Controleer nu de verwerkingstijd. Omdat u een streamingscenario hebt, bekijkt u de streamingdoorvoer.
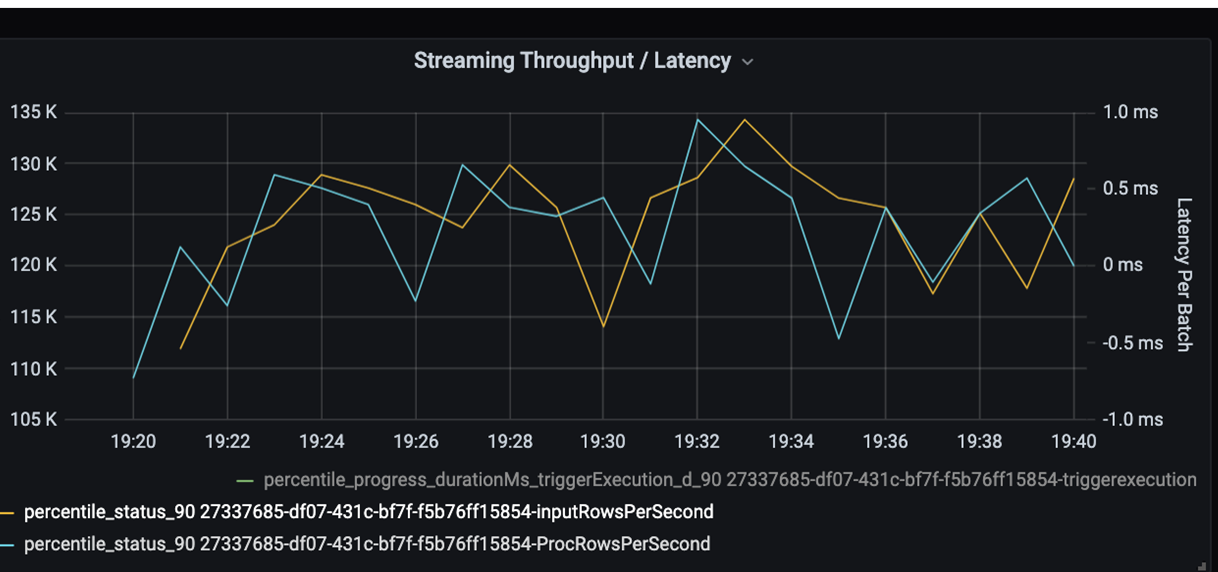
In het bovenstaande diagram voor streamingdoorvoer/batchlatentie vertegenwoordigt de oranje lijn de invoersnelheid (invoerrijen per seconde). De blauwe lijn vertegenwoordigt de verwerkingssnelheid (verwerkte rijen per seconde). Op sommige punten wordt de invoersnelheid niet door de verwerkingssnelheid afgevangen. Het mogelijke probleem is dat invoerbestanden zich in de wachtrij opstapelen.
Omdat de verwerkingssnelheid niet overeenkomt met de invoersnelheid in de grafiek, moet u de processnelheid verbeteren om de invoersnelheid volledig te dekken. Een mogelijke reden is de onevenwichtigheid van klantgegevens in elke partitiesleutel die leidt tot een knelpunt. Voor een volgende stap en mogelijke oplossing kunt u profiteren van de schaalbaarheid van Azure Databricks.
Partitioneringsonderzoek
Identificeer eerst het juiste aantal schaaluitvoerders dat u nodig hebt met Azure Databricks. Pas de vuistregel toe van het toewijzen van elke partitie met een toegewezen CPU in actieve uitvoerders. Als u bijvoorbeeld 200 partitiesleutels hebt, moet het aantal CPU's vermenigvuldigd met het aantal uitvoerders gelijk zijn aan 200. (Acht CPU's in combinatie met 25 uitvoerders zijn bijvoorbeeld een goede overeenkomst.) Met 200 partitiesleutels kan elke uitvoerder slechts op één taak werken, waardoor de kans op een knelpunt wordt verminderd.
Omdat sommige trage partities zich in dit scenario bevinden, onderzoekt u de hoge variantie in de duur van taken. Controleer op pieken in de duur van de taak. Eén taak verwerkt één partitie. Als een taak meer tijd nodig heeft, kan de partitie te groot zijn en een knelpunt veroorzaken.
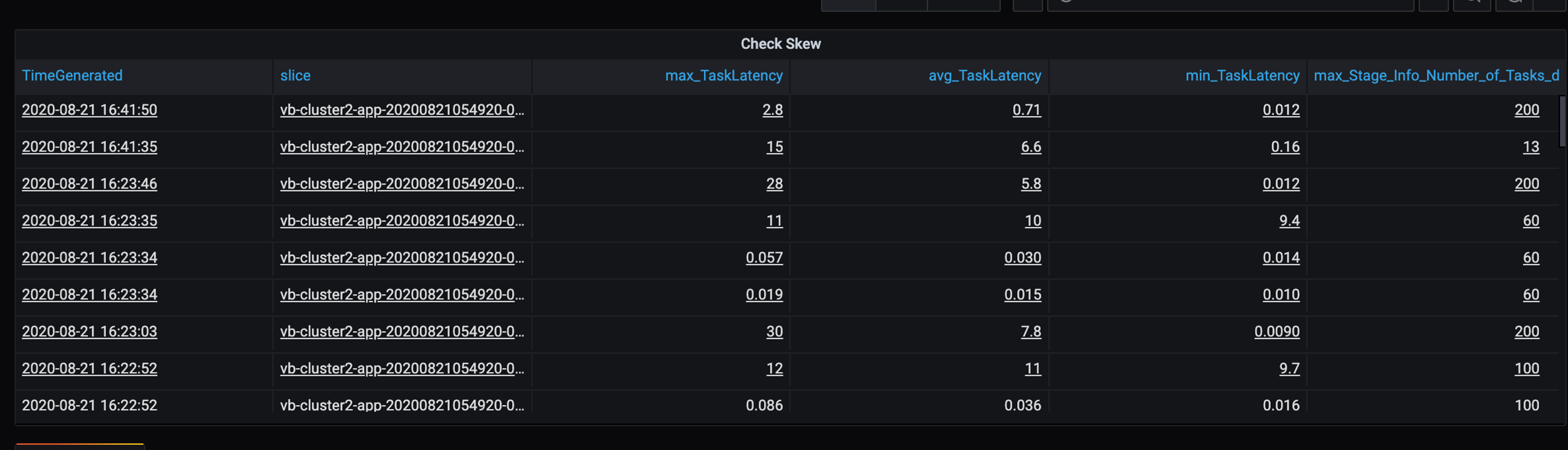
Fouttracering
Voeg een dashboard toe voor fouttracering, zodat u klantspecifieke gegevensfouten kunt opsporen. Bij voorverwerking van gegevens zijn er momenten waarop bestanden beschadigd zijn en records in een bestand niet overeenkomen met het gegevensschema. Het volgende dashboard onderschept veel ongeldige bestanden en slechte records.
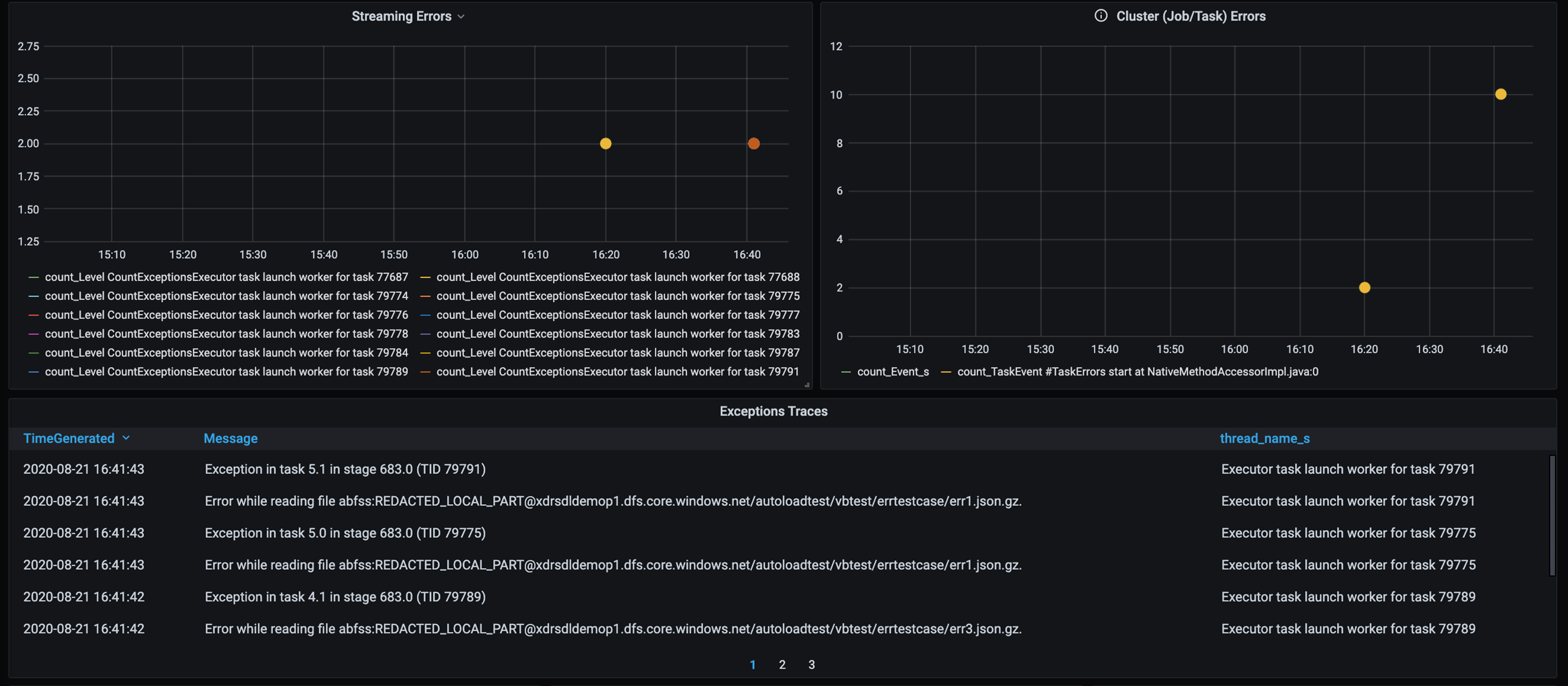
In dit dashboard worden het aantal fouten, het foutbericht en de taak-id weergegeven voor foutopsporing. In het bericht kunt u de fout eenvoudig terugzetten naar het foutenbestand. Er zijn verschillende bestanden in fout tijdens het lezen. U bekijkt de bovenste tijdlijn en onderzoekt op de specifieke punten in onze grafiek (16:20 en 16:40).
Andere knelpunten
Zie Prestatieknelpunten in Azure Databricks oplossen voor meer voorbeelden en richtlijnen.
Samenvatting van evaluatie van prestaties afstemmen
Voor dit scenario hebben deze metrische gegevens de volgende waarnemingen geïdentificeerd:
- In het faselatentiediagram nemen schrijffasen het grootste deel van de verwerkingstijd in beslag.
- In het grafiek met taaklatentie is de taaklatentie stabiel.
- In het diagram met streamingdoorvoer is de uitvoersnelheid op sommige punten lager dan de invoersnelheid.
- In de duurtabel van de taak is er een afwijking van de taak vanwege onevenwichtigheid van klantgegevens.
- Voor optimale prestaties in de partitioneringsfase moet het aantal uitvoerders voor schaalaanpassing overeenkomen met het aantal partities.
- Er zijn traceringsfouten, zoals slechte bestanden en slechte records.
U hebt de volgende metrische gegevens gebruikt om deze problemen vast te stellen:
- Taaklatentie
- Latentie fase
- Taaklatentie
- Streamingdoorvoer
- Taakduur (max, gemiddelde, min) per fase
- Fouttracering (aantal, bericht, taak-id)
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- David McGhee | Principal Program Manager
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Lees de Log Analytics-zelfstudie.
- Azure Databricks bewaken in een Azure Log Analytics-werkruimte
- Implementatie van Azure Log Analytics met metrische Spark-gegevens
- Waarneembaarheidspatronen