Prestatieknelpunten in Azure Databricks oplossen
Notitie
Dit artikel is afhankelijk van een opensource-bibliotheek die wordt gehost op GitHub op: https://github.com/mspnp/spark-monitoring.
De oorspronkelijke bibliotheek ondersteunt Azure Databricks Runtimes 10.x (Spark 3.2.x) en eerder.
Databricks heeft een bijgewerkte versie bijgedragen ter ondersteuning van Azure Databricks Runtimes 11.0 (Spark 3.3.x) en hoger op de l4jv2 vertakking op: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Houd er rekening mee dat de release 11.0 niet achterwaarts compatibel is vanwege de verschillende logboekregistratiesystemen die worden gebruikt in de Databricks Runtimes. Zorg ervoor dat u de juiste build gebruikt voor uw Databricks Runtime. De bibliotheek en GitHub-opslagplaats bevinden zich in de onderhoudsmodus. Er zijn geen plannen voor verdere releases en ondersteuning voor problemen is alleen best-effort. Neem contact op azure-spark-monitoring-help@databricks.commet eventuele aanvullende vragen over de bibliotheek of de roadmap voor het bewaken en vastleggen van uw Azure Databricks-omgevingen.
In dit artikel wordt beschreven hoe u bewakingsdashboards gebruikt om prestatieknelpunten in Spark-taken in Azure Databricks te vinden.
Azure Databricks is een op Apache Spark gebaseerde analyseservice waarmee u snel big data-analyses kunt ontwikkelen en implementeren. Het bewaken en oplossen van prestatieproblemen is essentieel bij het uitvoeren van Azure Databricks-workloads in productie. Voor het identificeren van veelvoorkomende prestatieproblemen is het handig om bewakingsvisualisaties te gebruiken op basis van telemetriegegevens.
Vereisten
De Grafana-dashboards instellen die in dit artikel worden weergegeven:
Configureer uw Databricks-cluster om telemetrie te verzenden naar een Log Analytics-werkruimte met behulp van de Azure Databricks Monitoring Library. Zie het Leesmij-leesmij-bestand voor GitHub voor meer informatie.
Grafana implementeren in een virtuele machine. Zie Dashboards gebruiken om metrische gegevens van Azure Databricks te visualiseren voor meer informatie.
Het Grafana-dashboard dat wordt geïmplementeerd, bevat een reeks visualisaties van tijdreeksen. Elke grafiek is een tijdreeksdiagram met metrische gegevens die betrekking hebben op een Apache Spark-taak, de fasen van de taak en taken waaruit elke fase bestaat.
Overzicht van azure Databricks-prestaties
Azure Databricks is gebaseerd op Apache Spark, een gedistribueerd computingsysteem voor algemeen gebruik. Toepassingscode, ook wel een taak genoemd, wordt uitgevoerd op een Apache Spark-cluster, gecoördineerd door de clusterbeheerder. Over het algemeen is een taak de eenheid op het hoogste niveau van de berekening. Een taak vertegenwoordigt de volledige bewerking die wordt uitgevoerd door de Spark-toepassing. Een typische bewerking omvat het lezen van gegevens uit een bron, het toepassen van gegevenstransformaties en het schrijven van de resultaten naar opslag of een andere bestemming.
Taken worden onderverdeeld in fasen. De taak gaat sequentieel door de fasen, wat betekent dat latere fasen moeten wachten tot eerdere fasen zijn voltooid. Fasen bevatten groepen identieke taken die parallel kunnen worden uitgevoerd op meerdere knooppunten van het Spark-cluster. Taken zijn de meest gedetailleerde uitvoeringseenheid die plaatsvindt op een subset van de gegevens.
In de volgende secties worden enkele dashboardvisualisaties beschreven die handig zijn voor het oplossen van prestatieproblemen.
Taak- en faselatentie
Taaklatentie is de duur van een taakuitvoering vanaf het moment dat deze wordt gestart totdat deze is voltooid. Het wordt weergegeven als percentielen van een taakuitvoering per cluster en toepassings-id, om de visualisatie van uitbijters toe te staan. In de volgende grafiek ziet u een taakgeschiedenis waarbij het 90e percentiel 50 seconden bereikt, ook al was het 50e percentiel consistent ongeveer 10 seconden.
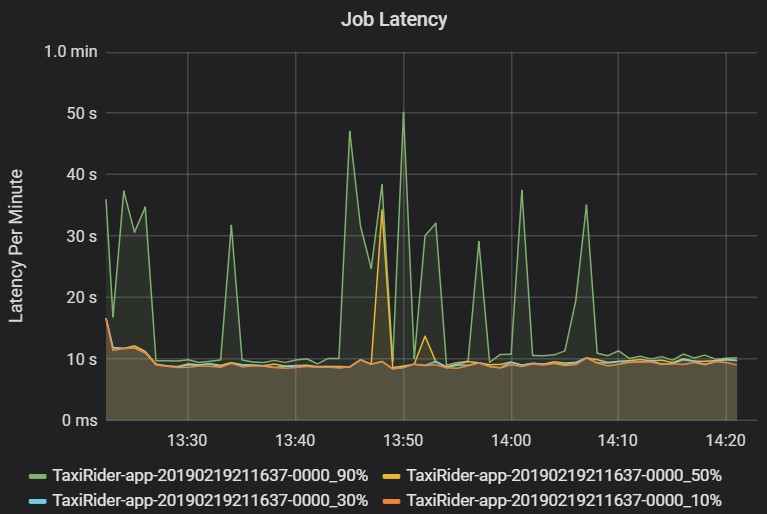
Onderzoek de taakuitvoering per cluster en toepassing, op zoek naar pieken in latentie. Zodra clusters en toepassingen met hoge latentie zijn geïdentificeerd, gaat u verder met het onderzoeken van faselatentie.
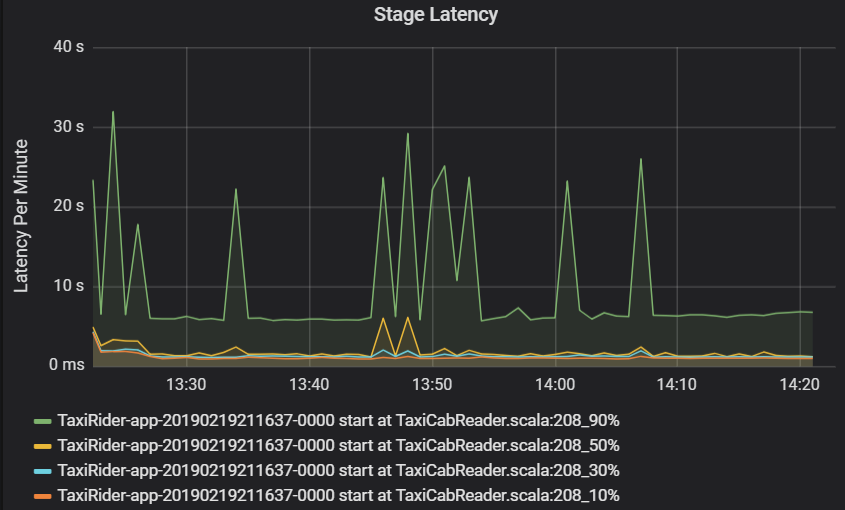
Faselatentie wordt ook weergegeven als percentielen om de visualisatie van uitbijters mogelijk te maken. De faselatentie wordt uitgesplitst op basis van de naam van het cluster, de toepassing en de fase. Identificeer pieken in taaklatentie in de grafiek om te bepalen welke taken de voltooiing van de fase tegenhouden.
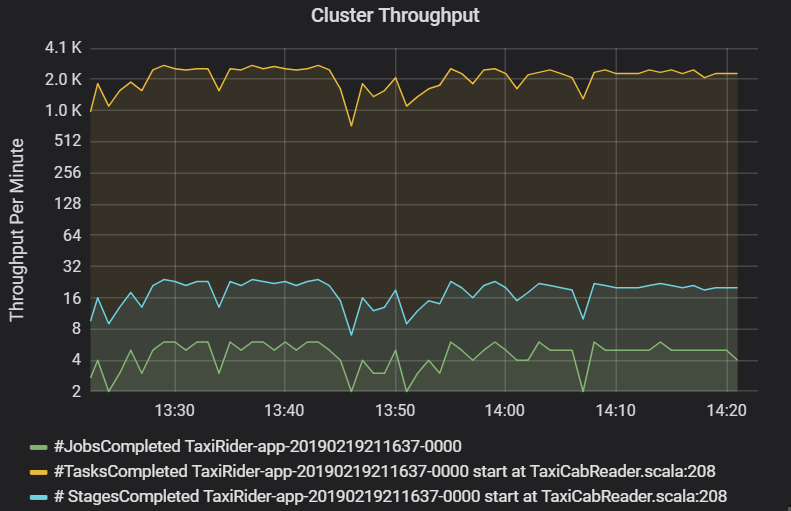
In de grafiek voor clusterdoorvoer ziet u het aantal taken, fasen en taken dat per minuut is voltooid. Dit helpt u inzicht te hebben in de workload in termen van het relatieve aantal fasen en taken per taak. Hier ziet u dat het aantal taken per minuut varieert tussen 2 en 6, terwijl het aantal fasen ongeveer 12 tot 24 per minuut is.
Som van latentie van taakuitvoering
Deze visualisatie toont de som van de latentie van taakuitvoering per host die wordt uitgevoerd op een cluster. Gebruik deze grafiek om taken te detecteren die langzaam worden uitgevoerd als gevolg van het vertragen van de host op een cluster of een onjuiste toewijzing van taken per uitvoerder. In de volgende grafiek hebben de meeste hosts een som van ongeveer 30 seconden. Twee van de hosts hebben echter sommen die ongeveer 10 minuten aanwijzen. De hosts worden traag uitgevoerd of het aantal taken per uitvoerder is onjuist toegewezen.
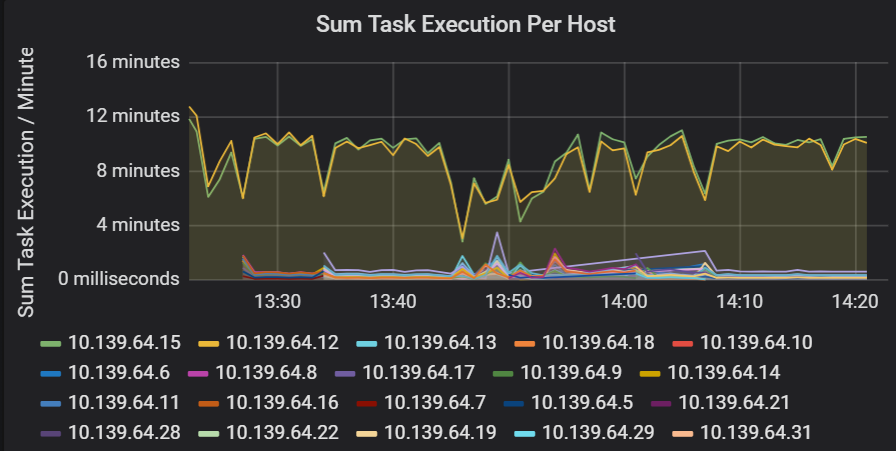
Het aantal taken per uitvoerder geeft aan dat twee uitvoerders een onevenredig aantal taken krijgen, wat een knelpunt veroorzaakt.
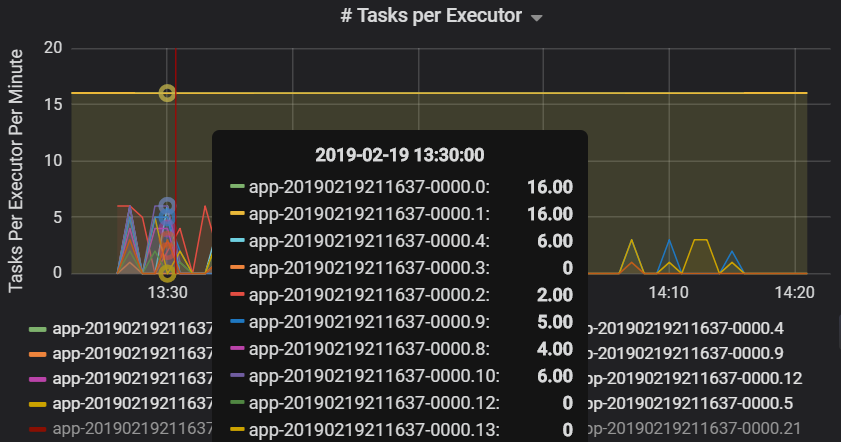
Metrische taakgegevens per fase
De visualisatie met metrische gegevens van de taak geeft de kosten uitsplitsing voor een taakuitvoering. U kunt deze gebruiken om de relatieve tijd te zien die is besteed aan taken zoals serialisatie en deserialisatie. Deze gegevens kunnen mogelijkheden tonen om te optimaliseren, bijvoorbeeld door broadcastvariabelen te gebruiken om verzendingsgegevens te voorkomen. In de metrische taakgegevens wordt ook de gegevensgrootte voor een taak in willekeurige volgorde weergegeven, evenals de lees- en schrijftijden in willekeurige volgorde. Als deze waarden hoog zijn, betekent dit dat veel gegevens via het netwerk worden verplaatst.
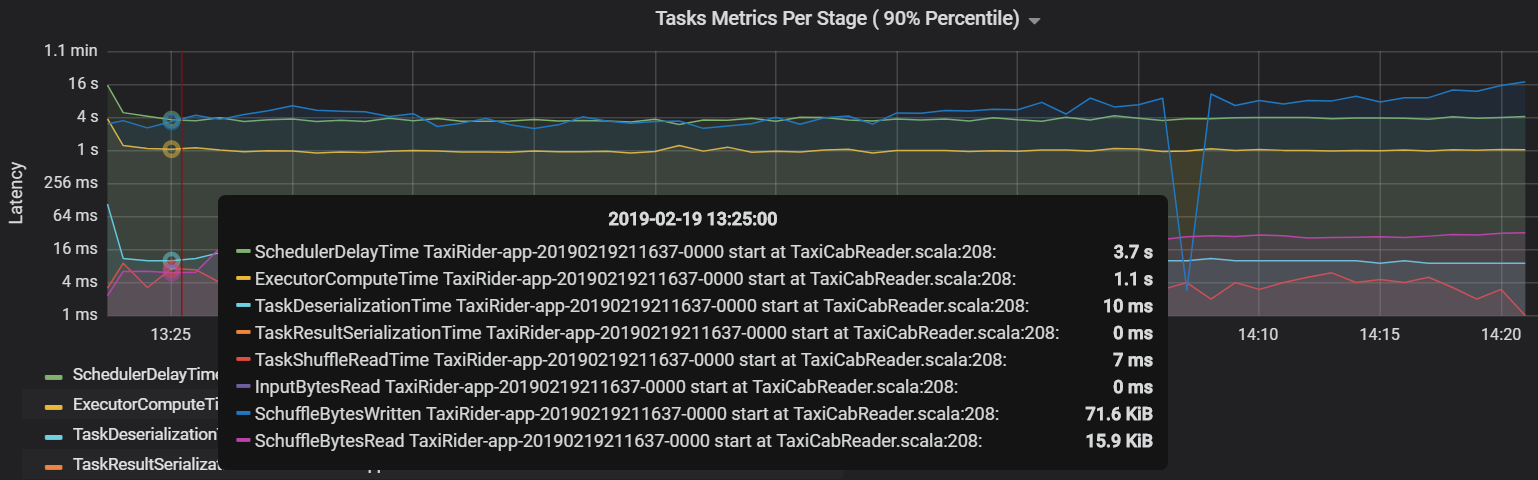
Een andere metrische taakwaarde is de vertraging van de planner, die meet hoe lang het duurt om een taak te plannen. In het ideale geval moet deze waarde laag zijn vergeleken met de rekentijd van de uitvoerder, namelijk de tijd die daadwerkelijk is besteed aan het uitvoeren van de taak.
In de volgende grafiek ziet u een vertragingstijd van de scheduler (3,7 s) die de rekentijd van de uitvoerder overschrijdt (1,1 s). Dat betekent dat er meer tijd wordt besteed aan het wachten op geplande taken dan het uitvoeren van het werkelijke werk.
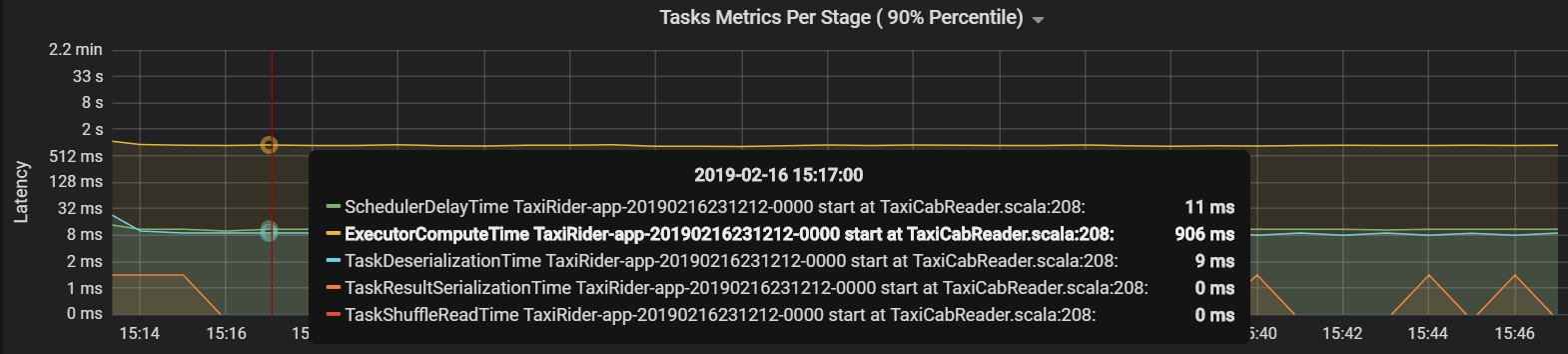
In dit geval is het probleem veroorzaakt door te veel partities, wat veel overhead veroorzaakte. Door het aantal partities te verminderen, is de vertragingstijd van de planner verlaagd. In de volgende grafiek ziet u dat de meeste tijd wordt besteed aan het uitvoeren van de taak.
Streamingdoorvoer en latentie
Streamingdoorvoer is rechtstreeks gerelateerd aan gestructureerd streamen. Er zijn twee belangrijke metrische gegevens gekoppeld aan streamingdoorvoer: invoerrijen per seconde en verwerkte rijen per seconde. Als invoerrijen per seconde de verwerkte rijen per seconde overschrijdt, betekent dit dat het stroomverwerkingssysteem achterloopt. Als de invoergegevens afkomstig zijn van Event Hubs of Kafka, moeten invoerrijen per seconde de opnamesnelheid van de gegevens aan de front-end bijhouden.
Twee taken kunnen vergelijkbare clusterdoorvoer hebben, maar zeer verschillende metrische streaminggegevens. In de volgende schermopname ziet u twee verschillende workloads. Ze zijn vergelijkbaar in termen van clusterdoorvoer (taken, fasen en taken per minuut). Maar de tweede uitvoering verwerkt 12.000 rijen per seconde versus 4000 rijen per seconde.
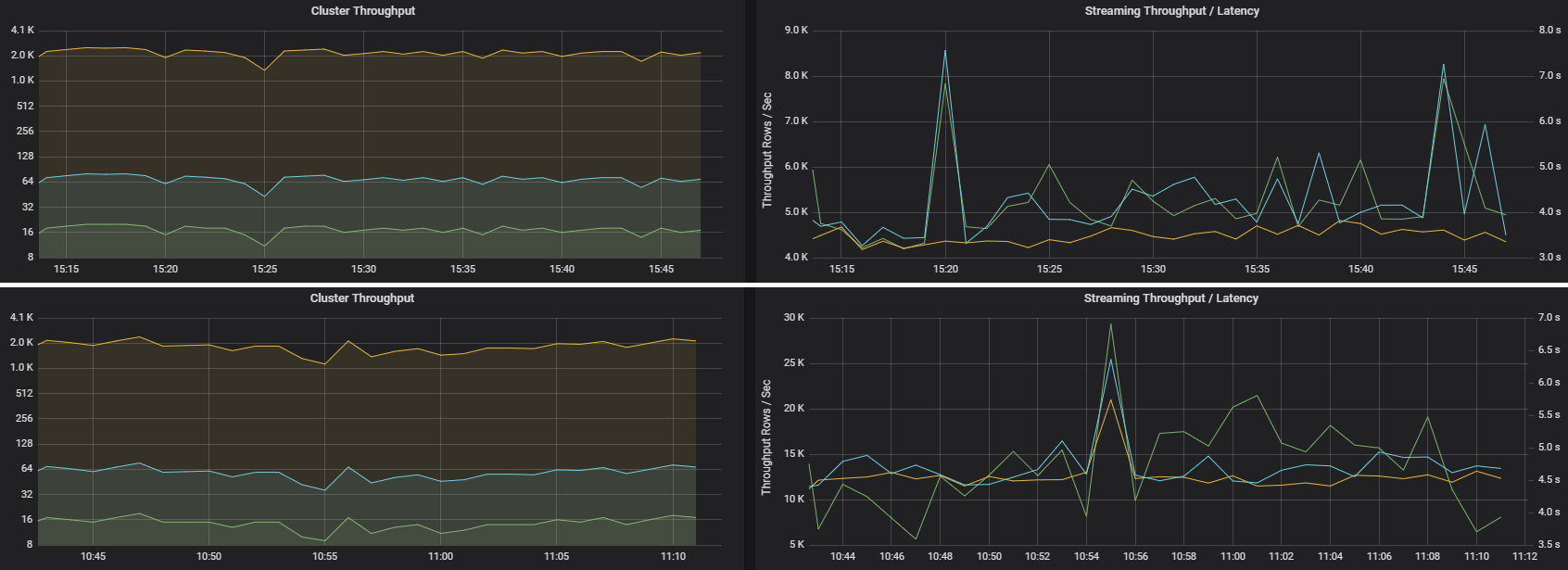
Streamingdoorvoer is vaak een betere zakelijke metriek dan clusterdoorvoer, omdat hiermee het aantal gegevensrecords wordt meet dat wordt verwerkt.
Resourceverbruik per uitvoerder
Deze metrische gegevens helpen inzicht te verkrijgen in het werk dat elke uitvoerder uitvoert.
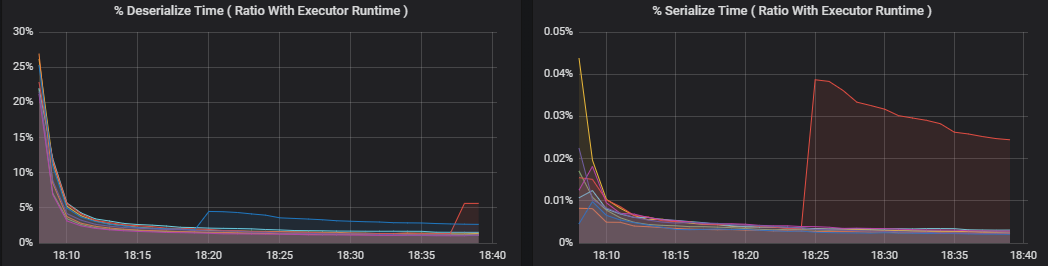
Percentage metrische gegevens meten hoeveel tijd een uitvoerder besteedt aan verschillende dingen, uitgedrukt als een verhouding van de tijd die is besteed ten opzichte van de totale rekentijd van de uitvoerder. Deze metrische gegevens zijn:
- % serialiseertijd
- % tijd deserialiseren
- % CPU-uitvoertijd
- % JVM-tijd
Deze visualisaties laten zien hoeveel elk van deze metrische gegevens bijdraagt aan de algehele verwerking van uitvoerders.
Metrische gegevens in willekeurige volgorde zijn metrische gegevens die betrekking hebben op gegevens die over de uitvoerders worden verdeeld.
- I/O in willekeurige volgorde
- Geheugen in willekeurige volgorde
- Bestandssysteemgebruik
- Schijfgebruik
Veelvoorkomende prestatieknelpunten
Twee veelvoorkomende prestatieknelpunten in Spark zijn taakontwijkers en een niet-optimaal aantal willekeurige partities.
Taakstragglers
De fasen in een taak worden opeenvolgend uitgevoerd, waarbij eerdere fasen latere fasen blokkeren. Als een bepaalde taak een willekeurige partitie langzamer uitvoert dan andere taken, moeten alle taken in het cluster wachten tot de trage taak is ingehaald voordat de fase kan worden beëindigd. Dit kan om de volgende redenen gebeuren:
Een host of groep hosts is traag. Symptomen: Hoge taak-, fase- of taaklatentie en lage clusterdoorvoer. De optelsom van takenlatenties per host wordt niet gelijkmatig verdeeld. Resourceverbruik wordt echter gelijkmatig verdeeld over uitvoerders.
Taken hebben een dure aggregatie die moet worden uitgevoerd (gegevens worden weergegeven). Symptomen: hoge taaklatentie, hoge faselatentie, hoge taaklatentie of lage clusterdoorvoer, maar de som van latenties per host wordt gelijkmatig verdeeld. Resourceverbruik wordt gelijkmatig verdeeld over uitvoerders.
Als partities van ongelijke grootte zijn, kan een grotere partitie leiden tot onevenwichtige taakuitvoering (partities). Symptomen: het verbruik van uitvoerresources is hoog in vergelijking met andere uitvoerders die op het cluster worden uitgevoerd. Alle taken die op die uitvoerder worden uitgevoerd, worden traag uitgevoerd en bevatten de uitvoering van de fase in de pijplijn. Deze fasen worden als fasebarrières beschouwd.
Niet-optimaal aantal willekeurige partities
Tijdens een gestructureerde streamingquery is de toewijzing van een taak aan een uitvoerder een resource-intensieve bewerking voor het cluster. Als de gegevens in willekeurige volgorde niet de optimale grootte hebben, heeft de hoeveelheid vertraging voor een taak een negatieve invloed op de doorvoer en latentie. Als er te weinig partities zijn, worden de kernen in het cluster onderbenut, wat kan leiden tot inefficiëntie. Als er te veel partities zijn, is er echter veel beheeroverhead voor een klein aantal taken.
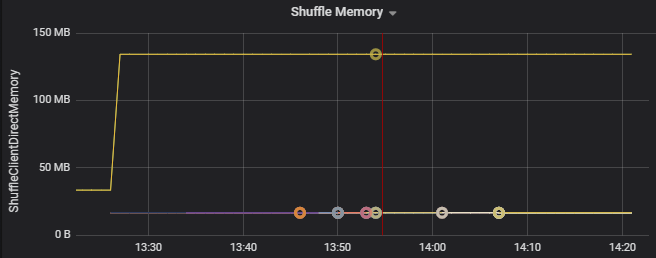
Gebruik de metrische gegevens over resourceverbruik om problemen op te lossen met partitionering en onjuiste toewijzing van uitvoerders in het cluster. Als een partitie scheef is, worden uitvoerdersbronnen verhoogd in vergelijking met andere uitvoerders die op het cluster worden uitgevoerd.
In de volgende grafiek ziet u bijvoorbeeld dat het geheugen dat wordt gebruikt door het shuffling op de eerste twee uitvoerders 90X groter is dan de andere uitvoerders:
Volgende stappen
- Azure Databricks bewaken in een Azure Log Analytics-werkruimte
- Leertraject: Machine Learning-oplossingen bouwen en gebruiken met Azure Databricks
- Documentatie voor Azure Databricks
- Overzicht van Azure Monitor
Verwante resources
- Azure Databricks bewaken
- Azure Databricks-toepassingslogboeken verzenden naar Azure Monitor
- Dashboards gebruiken om metrische gegevens van Azure Databricks te visualiseren
- Moderne analysearchitectuur met Azure Databricks
- Opname, ETL (pijplijnen extraheren, transformeren, laden) en stroomverwerkingspijplijnen met Azure Databricks