Dashboards gebruiken om metrische gegevens van Azure Databricks te visualiseren
Notitie
Dit artikel is afhankelijk van een opensource-bibliotheek die wordt gehost op GitHub op: https://github.com/mspnp/spark-monitoring.
De oorspronkelijke bibliotheek ondersteunt Azure Databricks Runtimes 10.x (Spark 3.2.x) en eerder.
Databricks heeft een bijgewerkte versie bijgedragen ter ondersteuning van Azure Databricks Runtimes 11.0 (Spark 3.3.x) en hoger op de l4jv2 vertakking op: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Houd er rekening mee dat de release 11.0 niet achterwaarts compatibel is vanwege de verschillende logboekregistratiesystemen die worden gebruikt in de Databricks Runtimes. Zorg ervoor dat u de juiste build gebruikt voor uw Databricks Runtime. De bibliotheek en GitHub-opslagplaats bevinden zich in de onderhoudsmodus. Er zijn geen plannen voor verdere releases en ondersteuning voor problemen is alleen best-effort. Neem contact op azure-spark-monitoring-help@databricks.commet eventuele aanvullende vragen over de bibliotheek of de roadmap voor het bewaken en vastleggen van uw Azure Databricks-omgevingen.
In dit artikel wordt beschreven hoe u een Grafana-dashboard instelt voor het bewaken van Azure Databricks-taken voor prestatieproblemen.
Azure Databricks is een snelle, krachtige en gezamenlijke op Apache Spark gebaseerde analyseservice waarmee u snel big data-analyses en ai-oplossingen (ai) kunt ontwikkelen en implementeren. Bewaking is een essentieel onderdeel van het uitvoeren van Azure Databricks-workloads in productie. De eerste stap is het verzamelen van metrische gegevens in een werkruimte voor analyse. In Azure is Azure Monitor de beste oplossing voor het beheren van logboekgegevens. Azure Databricks biedt geen systeemeigen ondersteuning voor het verzenden van logboekgegevens naar Azure Monitor, maar er is een bibliotheek voor deze functionaliteit beschikbaar in GitHub.
Deze bibliotheek maakt logboekregistratie van metrische gegevens van de Azure Databricks-service mogelijk, evenals metrische gegevens over streamingquery's van apache Spark-structuren. Zodra u deze bibliotheek hebt geïmplementeerd in een Azure Databricks-cluster, kunt u verder een set Grafana-dashboards implementeren die u kunt implementeren als onderdeel van uw productieomgeving.
Vereisten
Configureer uw Azure Databricks-cluster voor het gebruik van de bewakingsbibliotheek, zoals beschreven in het Leesmij-leesmij-bestand van GitHub.
De Azure Log Analytics-werkruimte implementeren
Voer de volgende stappen uit om de Azure Log Analytics-werkruimte te implementeren:
Navigeer naar de
/perftools/deployment/loganalyticsmap.Implementeer de logAnalyticsDeploy.json Azure Resource Manager-sjabloon. Zie Resources implementeren met Resource Manager-sjablonen en de Azure CLI voor meer informatie over het implementeren van Resource Manager-sjablonen. De sjabloon heeft de volgende parameters:
- locatie: de regio waar de Log Analytics-werkruimte en -dashboards worden geïmplementeerd.
- serviceTier: de prijscategorie voor werkruimten. Zie hier voor een lijst met geldige waarden.
- dataRetention (optioneel): het aantal dagen dat de logboekgegevens worden bewaard in de Log Analytics-werkruimte. De standaardwaarde is 30 dagen. Als de prijscategorie is
Free, moet de gegevensretentie zeven dagen duren. - workspaceName (optioneel): een naam voor de werkruimte. Als dit niet is opgegeven, genereert de sjabloon een naam.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Met deze sjabloon maakt u de werkruimte en maakt u ook een set vooraf gedefinieerde query's die worden gebruikt door het dashboard.
Grafana implementeren in een virtuele machine
Grafana is een opensource-project dat u kunt implementeren om de metrische tijdreeksgegevens te visualiseren die zijn opgeslagen in uw Azure Log Analytics-werkruimte met behulp van de Grafana-invoegtoepassing voor Azure Monitor. Grafana wordt uitgevoerd op een virtuele machine (VM) en vereist een opslagaccount, een virtueel netwerk en andere resources. Als u een virtuele machine wilt implementeren met de Door Bitnami gecertificeerde Grafana-installatiekopieën en bijbehorende resources, voert u de volgende stappen uit:
Gebruik de Azure CLI om de azure Marketplace-installatiekopieën voor Grafana te accepteren.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultNavigeer naar de
/spark-monitoring/perftools/deployment/grafanamap in uw lokale kopie van de GitHub-opslagplaats.Implementeer de grafanaDeploy.json Resource Manager-sjabloon als volgt:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Zodra de implementatie is voltooid, wordt de Bitnami-installatiekopieën van Grafana geïnstalleerd op de virtuele machine.
Het Grafana-wachtwoord bijwerken
Als onderdeel van het installatieproces voert het Grafana-installatiescript een tijdelijk wachtwoord uit voor de gebruiker met beheerdersrechten . U hebt dit tijdelijke wachtwoord nodig om u aan te melden. Voer de volgende stappen uit om het tijdelijke wachtwoord te verkrijgen:
- Meld u aan bij het Azure-portaal.
- Selecteer de resourcegroep waarin de resources zijn geïmplementeerd.
- Selecteer de VM waarop Grafana is geïnstalleerd. Als u de standaardparameternaam in de implementatiesjabloon hebt gebruikt, wordt de naam van de VIRTUELE machine voorafgegaan door sparkmonitoring-vm-grafana.
- Klik in de sectie Ondersteuning en probleemoplossing op Diagnostische gegevens over opstarten om de pagina met diagnostische gegevens over opstarten te openen.
- Klik op het seriële logboek op de pagina diagnostische gegevens over opstarten.
- Zoek naar de volgende tekenreeks: 'Bitnami-toepassingswachtwoord instellen op'.
- Kopieer het wachtwoord naar een veilige locatie.
Wijzig vervolgens het beheerderswachtwoord van Grafana door de volgende stappen uit te voeren:
- Selecteer de VIRTUELE machine in Azure Portal en klik op Overzicht.
- Kopieer het openbare IP-adres.
- Open een webbrowser en navigeer naar de volgende URL:
http://<IP address>:3000. - Voer in het aanmeldingsscherm van Grafana de beheerder in voor de gebruikersnaam en gebruik het Grafana-wachtwoord uit de vorige stappen.
- Nadat u zich hebt aangemeld, selecteert u Configuratie (het tandwielpictogram).
- Selecteer Serverbeheerder.
- Selecteer op het tabblad Gebruikers de aanmeldingsnaam van de beheerder .
- Werk het wachtwoord bij.
Een Azure Monitor-gegevensbron maken
Maak een service-principal waarmee Grafana de toegang tot uw Log Analytics-werkruimte kan beheren. Zie Een Azure-service-principal maken met Azure CLI voor meer informatie
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDNoteer de waarden voor appId, wachtwoord en tenant in de uitvoer van deze opdracht:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Meld u aan bij Grafana, zoals eerder beschreven. Selecteer Configuratie (het tandwielpictogram) en vervolgens Gegevensbronnen.
Klik op het tabblad Gegevensbronnen op Gegevensbron toevoegen.
Selecteer Azure Monitor als het gegevensbrontype.
Voer in de sectie Instellingen een naam in voor de gegevensbron in het tekstvak Naam .
Voer in de sectie Api-details van Azure Monitor de volgende gegevens in:
- Abonnements-id: uw Azure-abonnements-id.
- Tenant-id: de tenant-id van eerder.
- Client-id: de waarde van 'appId' van eerder.
- Clientgeheim: de waarde van 'wachtwoord' van eerder.
Schakel in de sectie Details van de Azure Log Analytics-API hetzelfde selectievakje in als Azure Monitor API .
Klik op Opslaan en testen. Als de Log Analytics-gegevensbron juist is geconfigureerd, wordt er een bericht weergegeven dat het is gelukt.
Het dashboard maken
Maak de dashboards in Grafana door de volgende stappen uit te voeren:
Navigeer naar de
/perftools/dashboards/grafanamap in uw lokale kopie van de GitHub-opslagplaats.Voer het volgende script uit:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shDe uitvoer van het script is een bestand met de naam SparkMonitoringDash.json.
Ga terug naar het Grafana-dashboard en selecteer Maken (het pluspictogram).
Selecteer Importeren.
Klik op Bestand uploaden .json.
Selecteer het SparkMonitoringDash.json bestand dat u in stap 2 hebt gemaakt.
Selecteer in de sectie Opties onder ALA de Azure Monitor-gegevensbron die u eerder hebt gemaakt.
Klik op Importeren.
Visualisaties in de dashboards
Zowel de Azure Log Analytics- als Grafana-dashboards bevatten een reeks visualisaties van tijdreeksen. Elke grafiek is een tijdreeksdiagram met metrische gegevens met betrekking tot een Apache Spark-taak, fasen van de taak en taken waaruit elke fase bestaat.
De visualisaties zijn:
Taaklatentie
Deze visualisatie toont de uitvoeringslatentie voor een taak. Dit is een grof overzicht van de algehele prestaties van een taak. Geeft de uitvoeringsduur van de taak weer van begin tot voltooiing. Houd er rekening mee dat de begintijd van de taak niet hetzelfde is als de inzendingstijd van de taak. Latentie wordt weergegeven als percentielen (10%, 30%, 50%, 90%) van de taakuitvoering geïndexeerd op cluster-id en toepassings-id.
Latentie fase
De visualisatie toont de latentie van elke fase per cluster, per toepassing en per afzonderlijke fase. Deze visualisatie is handig voor het identificeren van een bepaalde fase die langzaam wordt uitgevoerd.
Taaklatentie
Deze visualisatie toont de latentie van taakuitvoering. Latentie wordt weergegeven als een percentiel van taakuitvoering per cluster, fasenaam en toepassing.
Taakuitvoering per host optellen
Deze visualisatie toont de som van de latentie van taakuitvoering per host die wordt uitgevoerd op een cluster. Door de latentie van taakuitvoering per host weer te geven, worden hosts geïdentificeerd die veel hogere totale taaklatentie hebben dan andere hosts. Dit kan betekenen dat taken efficiënt of ongelijkmatig zijn gedistribueerd naar hosts.
Metrische taakgegevens
Deze visualisatie toont een set metrische uitvoeringsgegevens voor de uitvoering van een bepaalde taak. Deze metrische gegevens omvatten de grootte en duur van een gegevenss shuffle, de duur van serialisatie- en deserialisatiebewerkingen en andere. Bekijk de Log Analytics-query voor het deelvenster voor de volledige set metrische gegevens. Deze visualisatie is handig om inzicht te krijgen in de bewerkingen waaruit een taak bestaat en het resourceverbruik van elke bewerking te identificeren. Pieken in de grafiek vertegenwoordigen kostbare bewerkingen die moeten worden onderzocht.
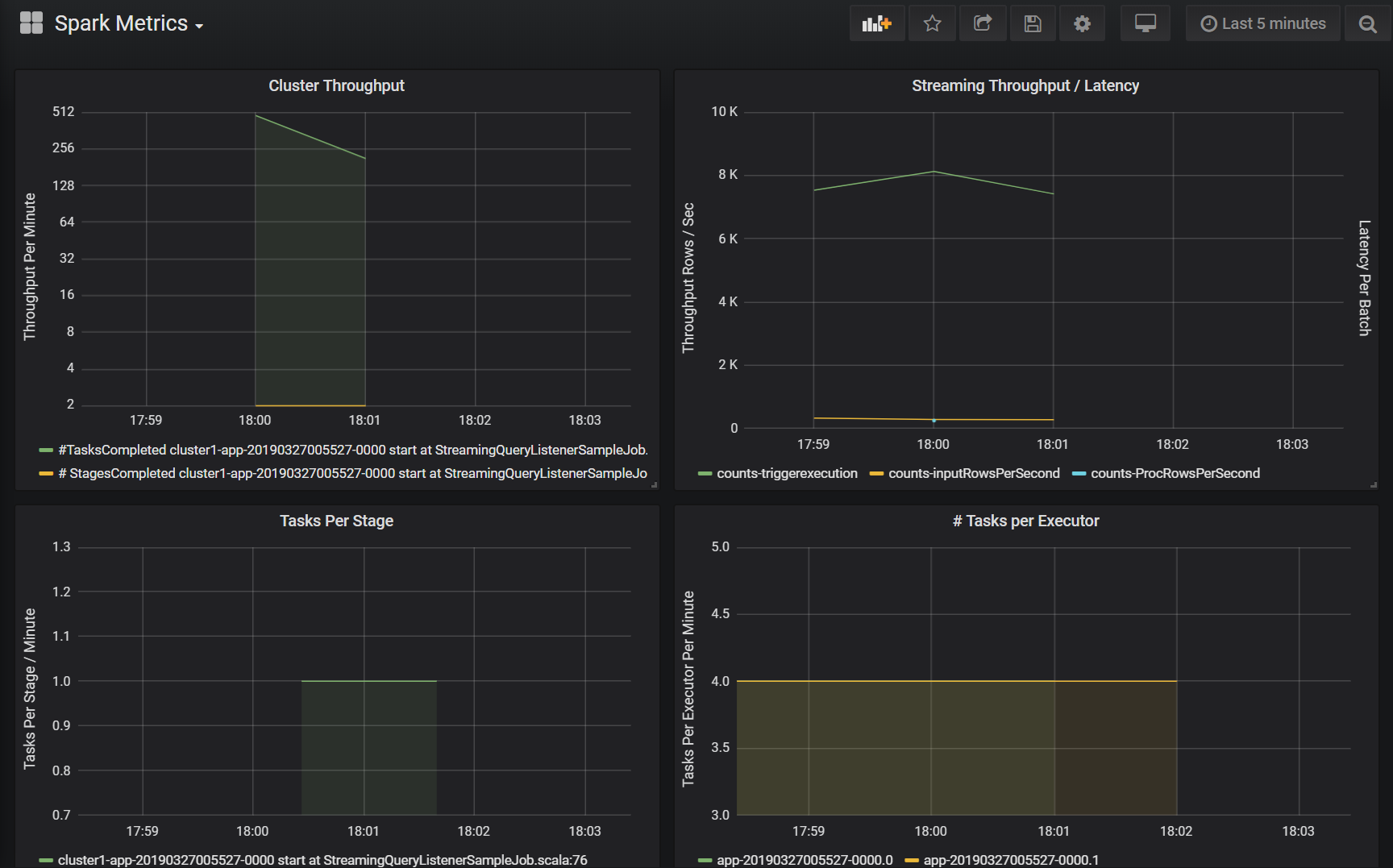
Clusterdoorvoer
Deze visualisatie is een weergave op hoog niveau van werkitems die zijn geïndexeerd door cluster en toepassing om de hoeveelheid werk weer te geven die per cluster en toepassing wordt uitgevoerd. Het toont het aantal taken, taken en fasen dat is voltooid per cluster, toepassing en fase in stappen van één minuut.
Streamingdoorvoer/latentie
Deze visualisatie is gerelateerd aan de metrische gegevens die zijn gekoppeld aan een gestructureerde streamingquery. In de grafiek ziet u het aantal invoerrijen per seconde en het aantal rijen dat per seconde is verwerkt. De metrische streaminggegevens worden ook per toepassing weergegeven. Deze metrische gegevens worden verzonden wanneer de gebeurtenis OnQueryProgress wordt gegenereerd als de gestructureerde streamingquery wordt verwerkt en de visualisatie de streaminglatentie vertegenwoordigt als de hoeveelheid tijd, in milliseconden, die nodig is om een querybatch uit te voeren.
Resourceverbruik per uitvoerder
Vervolgens ziet u een set visualisaties voor het dashboard met het specifieke type resource en hoe deze per uitvoerprogramma voor elk cluster wordt gebruikt. Deze visualisaties helpen bij het identificeren van uitbijters in resourceverbruik per uitvoerder. Als de werktoewijzing voor een bepaalde uitvoerder bijvoorbeeld scheef is, wordt het resourceverbruik verhoogd ten opzichte van andere uitvoerders die op het cluster worden uitgevoerd. Dit kan worden geïdentificeerd door pieken in het resourceverbruik voor een uitvoerder.
Metrische rekentijd van uitvoerders
Hierna volgt een set visualisaties voor het dashboard met de verhouding tussen de uitvoeringstijd, deserialiseren van tijd, CPU-tijd en de tijd van de virtuele Java-machine tot de totale rekentijd van de uitvoerder. Dit laat visueel zien hoeveel elk van deze vier metrische gegevens bijdraagt aan de algehele verwerking van uitvoerders.
Metrische gegevens in willekeurige volgorde
In de laatste set visualisaties ziet u de metrische gegevens in willekeurige volgorde die zijn gekoppeld aan een gestructureerde streamingquery voor alle uitvoerders. Dit omvat het lezen van bytes in willekeurige volgorde, het schrijven van bytes, het willekeurige geheugen en het schijfgebruik in query's waarin het bestandssysteem wordt gebruikt.