Modelleringsfase van de levenscyclus van het team Datawetenschap proces
In dit artikel worden de doelen, taken en producten beschreven die zijn gekoppeld aan de modelleringsfase van het TDSP (Team Datawetenschap Process). Dit proces biedt een aanbevolen levenscyclus die uw team kan gebruiken om uw data science-projecten te structuren. De levenscyclus bevat een overzicht van de belangrijkste fasen die uw team uitvoert, vaak iteratief:
- Bedrijfskennis
- Gegevens ophalen en begrijpen
- Modelleren
- Implementatie
- Klantacceptatie
Hier volgt een visuele weergave van de TDSP-levenscyclus:
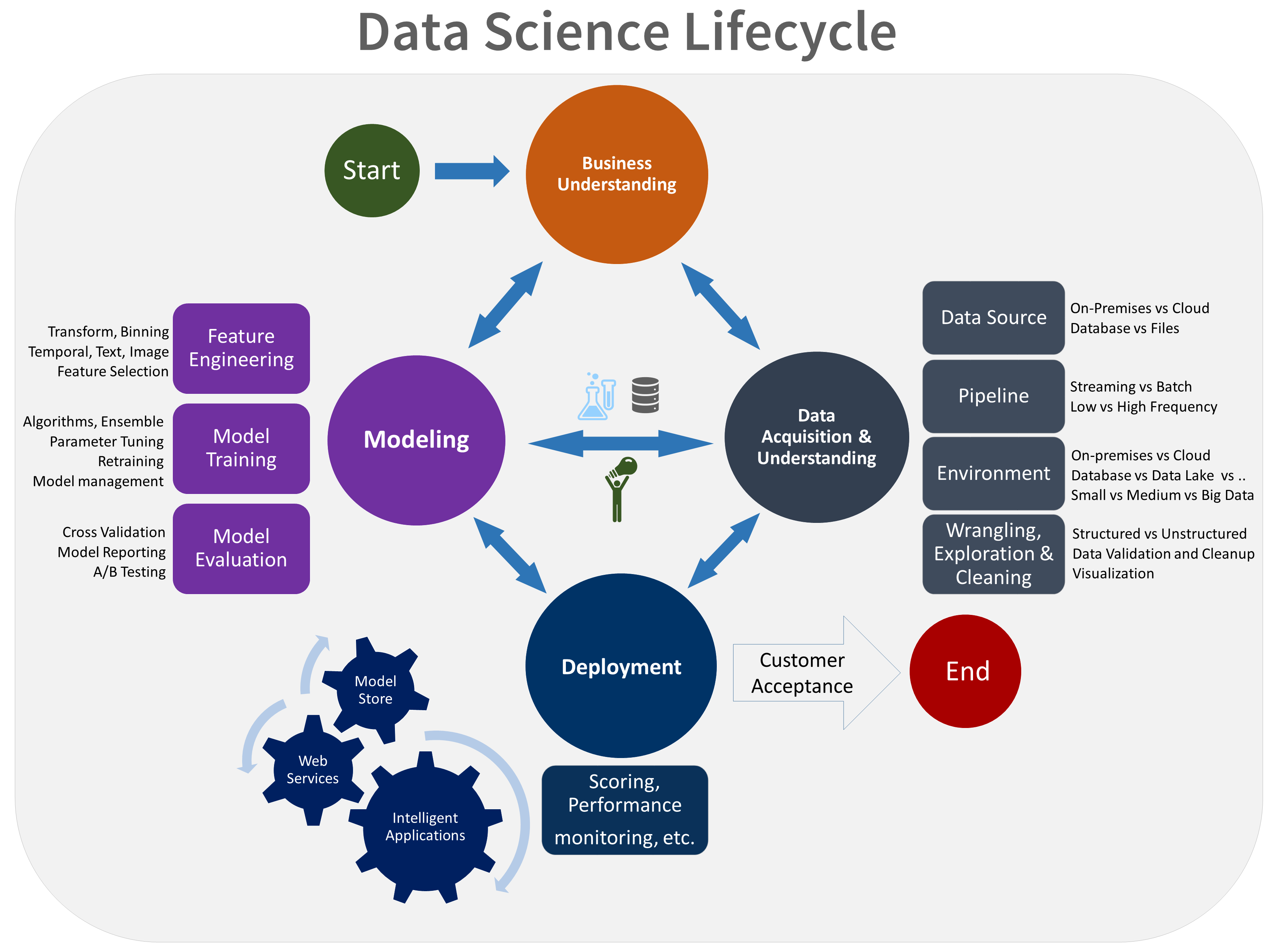
Doelstellingen
De doelstellingen van de modelleringsfase zijn:
Bepaal de optimale gegevensfuncties voor het machine learning-model.
Maak een informatief machine learning-model dat het doel het meest nauwkeurig voorspelt.
Maak een machine learning-model dat geschikt is voor productie.
De taken voltooien
De modelleringsfase heeft drie hoofdtaken:
Functie-engineering: Gegevensfuncties maken op basis van de onbewerkte gegevens om modeltraining te vergemakkelijken.
Modeltraining: Zoek het model dat de vraag het nauwkeurigst beantwoordt door de metrische succesgegevens van modellen te vergelijken.
Modelevaluatie: Bepaal of uw model geschikt is voor productie.
Functie-engineering
Functie-engineering omvat de opname, aggregatie en transformatie van onbewerkte variabelen om de functies te maken die in de analyse worden gebruikt. Als u inzicht wilt in hoe een model wordt gebouwd, moet u de onderliggende functies van het model bestuderen.
Deze stap vereist een creatieve combinatie van domeinexpertise en de inzichten die zijn verkregen uit de stap voor gegevensverkenning. Functie-engineering is een balans tussen het vinden en opnemen van informatieve variabelen, maar tegelijkertijd proberen te veel niet-gerelateerde variabelen te voorkomen. Informatieve variabelen verbeteren uw resultaat. Niet-gerelateerde variabelen introduceren onnodige ruis in het model. U moet deze functies ook genereren voor nieuwe gegevens die zijn verkregen tijdens het scoren. Als gevolg hiervan kan de generatie van deze functies alleen afhankelijk zijn van gegevens die beschikbaar zijn op het moment van scoren.
Modeltraining
Er zijn veel modelleringsalgoritmen die u kunt gebruiken, afhankelijk van het type vraag dat u wilt beantwoorden. Zie het cheatsheet voor Machine Learning-algoritmen voor Azure Machine Learning Designer voor hulp bij het kiezen van een vooraf samengesteld algoritme. Andere algoritmen zijn beschikbaar via opensource-pakketten in R of Python. Hoewel dit artikel gericht is op Azure Machine Learning, zijn de richtlijnen die het biedt nuttig voor veel machine learning-projecten.
Het proces voor modeltraining omvat de volgende stappen:
Splits de invoergegevens willekeurig voor modellering in een trainingsgegevensset en een testgegevensset.
Bouw de modellen met behulp van de trainingsgegevensset.
Evalueer de training en de testgegevensset. Gebruik een reeks concurrerende machine learning-algoritmen. Gebruik verschillende gekoppelde afstemmingsparameters (ook wel parameter-sweeps genoemd) die zijn afgestemd op het beantwoorden van de vraag van belang met de huidige gegevens.
Bepaal de beste oplossing om de vraag te beantwoorden door de metrische succesgegevens tussen alternatieve methoden te vergelijken.
Zie Modellen trainen met Machine Learning voor meer informatie.
Notitie
Lekken voorkomen: u kunt gegevenslekken veroorzaken als u gegevens van buiten de trainingsgegevensset opneemt waarmee een model of machine learning-algoritme onrealistisch goede voorspellingen kan doen. Lekkage is een veelvoorkomende reden waarom gegevenswetenschappers nerveus worden wanneer ze voorspellende resultaten krijgen die te goed lijken om waar te zijn. Deze afhankelijkheden zijn mogelijk moeilijk te detecteren. Het vermijden van lekkage vereist vaak herhalen tussen het bouwen van een analysegegevensset, het maken van een model en het evalueren van de nauwkeurigheid van de resultaten.
Modelevaluatie
Nadat u het model hebt getraind, is een data scientist in uw team gericht op modelevaluatie.
Bepaal of het model voldoende presteert voor productie. Enkele belangrijke vragen die u moet stellen zijn:
Beantwoordt het model de vraag met voldoende vertrouwen op basis van de testgegevens?
Moet u een andere benadering proberen?
Moet u meer gegevens verzamelen, meer functie-engineering uitvoeren of experimenteren met andere algoritmen?
Interpreteer het model: Gebruik de Python SDK voor Machine Learning om de volgende taken uit te voeren:
Leg het volledige modelgedrag of afzonderlijke voorspellingen lokaal uit op uw persoonlijke computer.
Schakel interpreteerbaarheidstechnieken in voor ontworpen functies.
Leg het gedrag uit voor het hele model en afzonderlijke voorspellingen in Azure.
Upload uitleg naar de uitvoeringsgeschiedenis van Machine Learning.
Gebruik een visualisatiedashboard om te communiceren met uw modeluitleg, zowel in een Jupyter-notebook als in de Machine Learning-werkruimte.
Implementeer een scoring-uitleg naast uw model om uitleg te bekijken tijdens deductie.
Beoordeel redelijkheid: gebruik het opensource Python-pakket fairlearn met Machine Learning om de volgende taken uit te voeren:
Beoordeel de redelijkheid van uw modelvoorspellingen. Dit proces helpt uw team meer te weten te komen over billijkheid in machine learning.
Upload, vermeld en download inzichten voor beoordeling van redelijkheid van en naar Machine Learning Studio.
Bekijk het dashboard voor fairness assessment in Machine Learning Studio om te communiceren met de inzichten in redelijkheid van uw modellen.
Integreren met MLflow
Machine Learning kan worden geïntegreerd met MLflow ter ondersteuning van de levenscyclus van modellen. Het maakt gebruik van het bijhouden van MLflow voor experimenten, projectimplementatie, modelbeheer en een modelregister. Deze integratie zorgt voor een naadloze en efficiënte machine learning-werkstroom. De volgende functies in Machine Learning bieden ondersteuning voor dit element voor de levenscyclus van modellen:
Experimenten bijhouden: de kernfunctionaliteit van MLflow wordt uitgebreid gebruikt in de modelleringsfase om verschillende experimenten, parameters, metrische gegevens en artefacten bij te houden.
Projecten implementeren: Verpakkingscode met MLflow Projects zorgt voor consistente uitvoeringen en eenvoudig delen tussen teamleden, wat essentieel is tijdens het ontwikkelen van iteratieve modellen.
Modellen beheren: Modellen beheren en versiebeheer is essentieel in deze fase, omdat verschillende modellen worden gebouwd, geëvalueerd en verfijnd.
Modellen registreren: het modelregister wordt gebruikt voor het versiebeheer en het beheren van modellen gedurende hun levenscyclus.
Literatuur die door peers is beoordeeld
Onderzoekers publiceren studies over de TDSP in peer-review literatuur. De bronvermeldingen bieden een mogelijkheid om andere toepassingen of vergelijkbare ideeën te onderzoeken met de TDSP, inclusief de fase van de modelleringslevenscyclus.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Mark Tabladillo | Senior Cloud Solution Architect
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Verwante resources
In deze artikelen worden de andere fasen van de TDSP-levenscyclus beschreven: