Azure Machine Learning gebruiken met het opensource-pakket Fairlearn om de billijkheid van ML-modellen te beoordelen (preview)
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In deze instructiegids leert u hoe u het OpenSource Python-pakket Fairlearn gebruikt met Azure Machine Learning om de volgende taken uit te voeren:
- Beoordeel de redelijkheid van uw modelvoorspellingen. Zie het artikel over fairness in machine learning voor meer informatie over billijkheid in machine learning.
- Upload, vermeld en download inzichten voor beoordeling van redelijkheid naar/van Azure Machine Learning-studio.
- Bekijk een beoordelingsdashboard in Azure Machine Learning-studio om te communiceren met de inzichten in redelijkheid van uw model(en).
Notitie
Billijkheidsbeoordeling is geen puur technische oefening. Met dit pakket kunt u de billijkheid van een machine learning-model beoordelen, maar alleen u kunt beslissingen nemen over hoe het model presteert. Hoewel dit pakket helpt bij het identificeren van kwantitatieve metrische gegevens om redelijkheid te beoordelen, moeten ontwikkelaars van machine learning-modellen ook een kwalitatieve analyse uitvoeren om de billijkheid van hun eigen modellen te evalueren.
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Azure Machine Learning Fairness SDK
De Azure Machine Learning Fairness SDK, azureml-contrib-fairnessintegreert het opensource Python-pakket, Fairlearn, in Azure Machine Learning. Bekijk deze voorbeeldnotebookers voor meer informatie over de integratie van Fairlearn in Azure Machine Learning. Zie de voorbeeldhandleiding en voorbeeldnotitieblokken voor meer informatie over Fairlearn.
Gebruik de volgende opdrachten om de azureml-contrib-fairness pakketten te fairlearn installeren:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
Latere versies van Fairlearn moeten ook werken in de volgende voorbeeldcode.
Inzichten in redelijkheid uploaden voor één model
In het volgende voorbeeld ziet u hoe u het fairness-pakket gebruikt. We uploaden inzicht in de redelijkheid van modellen naar Azure Machine Learning en zien het beoordelingsdashboard van fairness in Azure Machine Learning-studio.
Een voorbeeldmodel trainen in Jupyter Notebook.
Voor de gegevensset gebruiken we de bekende gegevensset voor volwassen volkstelling, die we ophalen uit OpenML. We doen alsof we een probleem met een leningsbeslissing hebben met het label waarmee wordt aangegeven of een persoon een vorige lening heeft terugbetaald. We trainen een model om te voorspellen of eerder ongelezen individuen een lening terugbetalen. Een dergelijk model kan worden gebruikt bij het nemen van beslissingen over leningen.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Meld u aan bij Azure Machine Learning en registreer uw model.
Het fairness-dashboard kan worden geïntegreerd met geregistreerde of niet-geregistreerde modellen. Registreer uw model in Azure Machine Learning met de volgende stappen:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Metrische gegevens voor redelijkheid vooraf compileren.
Maak een dashboardwoordenlijst met het pakket van
metricsFairlearn. De_create_group_metric_setmethode heeft argumenten die vergelijkbaar zijn met de dashboardconstructor, behalve dat de gevoelige functies worden doorgegeven als een woordenlijst (om ervoor te zorgen dat namen beschikbaar zijn). We moeten ook het type voorspelling (binaire classificatie in dit geval) opgeven bij het aanroepen van deze methode.# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Upload de vooraf samengestelde metrische gegevens over redelijkheid.
Importeer
azureml.contrib.fairnessnu het pakket om het uploaden uit te voeren:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idMaak een experiment, vervolgens een run en upload het dashboard naar het:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Controleer het fairness-dashboard van Azure Machine Learning-studio
Als u de vorige stappen hebt voltooid (gegenereerde fairness-inzichten uploaden naar Azure Machine Learning), kunt u het fairness-dashboard bekijken in Azure Machine Learning-studio. Dit dashboard is hetzelfde visualisatiedashboard dat wordt aangeboden in Fairlearn, zodat u de verschillen tussen de subgroepen van uw gevoelige functie (bijvoorbeeld mannelijk versus vrouwelijk) kunt analyseren. Volg een van deze paden voor toegang tot het visualisatiedashboard in Azure Machine Learning-studio:
- Deelvenster Taken (preview)
- Selecteer Taken in het linkerdeelvenster om een lijst weer te geven met experimenten die u hebt uitgevoerd op Azure Machine Learning.
- Selecteer een bepaald experiment om alle uitvoeringen in dat experiment weer te geven.
- Selecteer een uitvoering en klik vervolgens op het tabblad Redelijkheid op het dashboard voor uitlegvisualisatie.
- Zodra u op het tabblad Fairness bent aangekomen, klikt u op een fairness-id in het menu aan de rechterkant.
- Configureer uw dashboard door uw gevoelige kenmerk, prestatiemetrieken en metrischheidsmetrische gegevens te selecteren die interessant zijn om te landen op de pagina fairness-evaluatie.
- Schakel van grafiektype over van het ene naar het andere om zowel de toewijzingsschade als de kwaliteit van serviceschade te observeren.
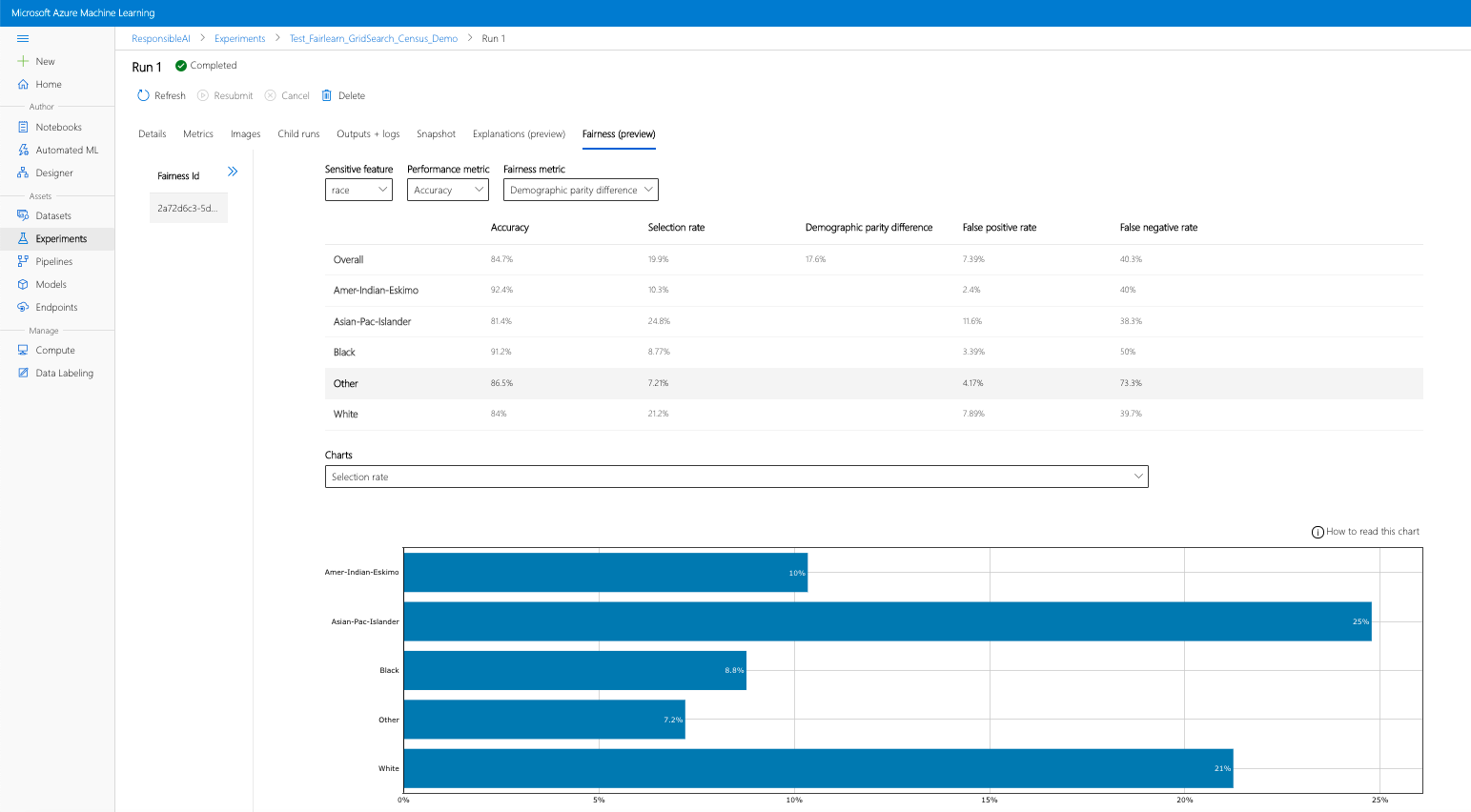
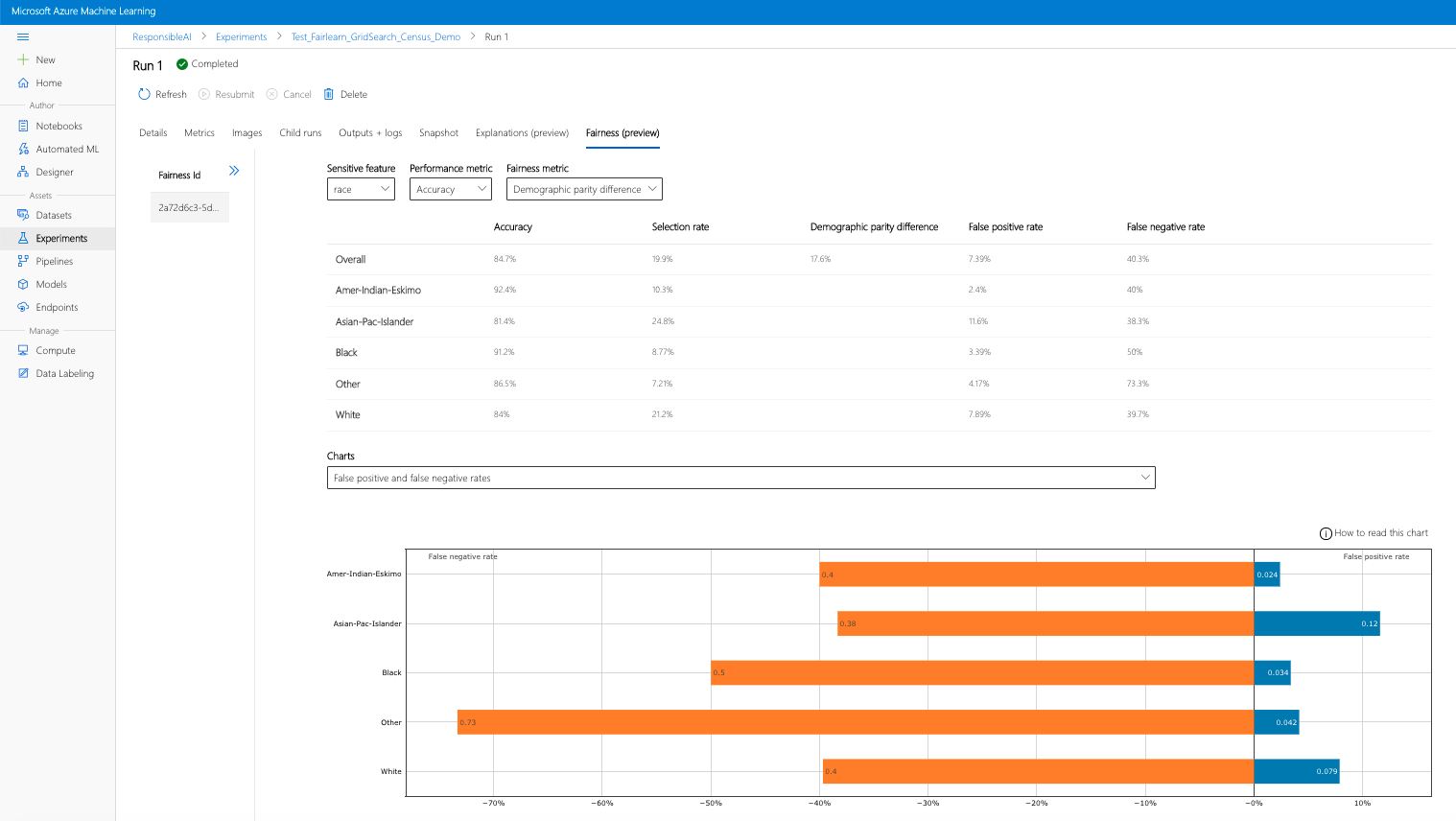
- Deelvenster Modellen
- Als u het oorspronkelijke model hebt geregistreerd door de vorige stappen te volgen, kunt u Modellen selecteren in het linkerdeelvenster om het te bekijken.
- Selecteer een model en vervolgens het tabblad Billijkheid om het dashboard voor uitlegvisualisatie weer te geven.
Raadpleeg de gebruikershandleiding van Fairlearn voor meer informatie over het visualisatiedashboard en de inhoud ervan.


Fairness Insights uploaden voor meerdere modellen
Als u meerdere modellen wilt vergelijken en wilt zien hoe hun fairness-evaluaties verschillen, kunt u meer dan één model doorgeven aan het visualisatiedashboard en hun compromissen voor de prestaties vergelijken.
Uw modellen trainen:
We maken nu een tweede classificatie op basis van een Support Vector Machine-estimator en uploaden een fairness-dashboardwoordenlijst met behulp van het pakket van
metricsFairlearn. We gaan ervan uit dat het eerder getrainde model nog steeds beschikbaar is.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Uw modellen registreren
Registreer vervolgens beide modellen in Azure Machine Learning. Sla voor het gemak de resultaten op in een woordenlijst, die het
idgeregistreerde model (een tekenreeks inname:versionindeling) toewijst aan de voorspellingsfunctie zelf:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorHet Fairness-dashboard lokaal laden
Voordat u de redelijkheidsinzichten uploadt naar Azure Machine Learning, kunt u deze voorspellingen onderzoeken in een lokaal aangeroepen Fairness-dashboard.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Metrische gegevens voor redelijkheid vooraf compileren.
Maak een dashboardwoordenlijst met het pakket van
metricsFairlearn.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Upload de vooraf samengestelde metrische gegevens over redelijkheid.
Importeer
azureml.contrib.fairnessnu het pakket om het uploaden uit te voeren:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idMaak een experiment, vervolgens een run en upload het dashboard naar het:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Net als in de vorige sectie kunt u een van de hierboven beschreven paden volgen (via experimenten of modellen) in Azure Machine Learning-studio om toegang te krijgen tot het visualisatiedashboard en de twee modellen te vergelijken in termen van billijkheid en prestaties.
Niet-gemitigeerde en verzachte inzichten in redelijkheid uploaden
U kunt de risicobeperkingsalgoritmen van Fairlearn gebruiken, hun gegenereerde verzachte model(en) vergelijken met het oorspronkelijke niet-gemitigeerde model en door de afwegingen tussen de prestaties/fairness van vergeleken modellen navigeren.
Bekijk dit voorbeeldnotitieblok voor een voorbeeld van het gebruik van het algoritme voor het beperken van Grid Search (waarmee een verzameling van verzachte modellen met verschillende redelijkheid en prestatieproblemen wordt gemaakt).
Het uploaden van inzichten in de billijkheid van meerdere modellen in één run maakt het mogelijk om modellen te vergelijken met betrekking tot redelijkheid en prestaties. U kunt klikken op een van de modellen die worden weergegeven in de modelvergelijkingsgrafiek om de gedetailleerde redelijkheidsinzichten van het specifieke model te bekijken.
