Het Python-interpreteerbaarheidspakket gebruiken om ML-modellen en -voorspellingen uit te leggen (preview)
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In deze instructiegids leert u hoe u het interpreteerbaarheidspakket van de Azure Machine Learning Python SDK gebruikt om de volgende taken uit te voeren:
Leg het volledige modelgedrag of afzonderlijke voorspellingen lokaal uit op uw persoonlijke computer.
Schakel interpreteerbaarheidstechnieken in voor ontworpen functies.
Leg het gedrag uit voor het hele model en afzonderlijke voorspellingen in Azure.
Upload uitleg naar De uitvoeringsgeschiedenis van Azure Machine Learning.
Gebruik een visualisatiedashboard om te communiceren met uw modeluitleg, zowel in een Jupyter Notebook als in de Azure Machine Learning-studio.
Implementeer een scoring-uitleg naast uw model om uitleg te bekijken tijdens deductie.
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Zie Modelinterpretabiliteit in Azure Machine Learning en voorbeeldnotebookers voor meer informatie over de ondersteunde interpreteerbaarheidstechnieken en machine learning-modellen.
Zie Interpreteerbaarheid: modeluitlegen voor geautomatiseerde machine learning-modellen (preview) voor hulp bij het inschakelen van interpreteerbaarheid voor modellen die zijn getraind met geautomatiseerde machine learning.
Waarde voor functiebelang genereren op uw persoonlijke computer
In het volgende voorbeeld ziet u hoe u het interpreteerbaarheidspakket op uw persoonlijke computer gebruikt zonder contact op te maken met Azure-services.
Installeer het
azureml-interpret-pakket.pip install azureml-interpretEen voorbeeldmodel trainen in een lokaal Jupyter Notebook.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Roep de uitlegfunctie lokaal aan.
- Als u een uitlegobject wilt initialiseren, geeft u uw model en enkele trainingsgegevens door aan de constructor van de uitleger.
- Als u uw uitleg en visualisaties informatiever wilt maken, kunt u ervoor kiezen om functienamen en uitvoerklassenamen door te geven als u classificatie uitvoert.
In de volgende codeblokken ziet u hoe u een uitlegobject kunt instantiëren met
TabularExplainer,MimicExplainerenPFIExplainerlokaal.TabularExplainerroept een van de drie SHAP-uitlegders eronder aan (TreeExplainer,DeepExplainerofKernelExplainer).TabularExplainerselecteert automatisch de meest geschikte voor uw use-case, maar u kunt elk van de drie onderliggende uitlegders rechtstreeks aanroepen.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Het gedrag van het hele model uitleggen (globale uitleg)
Raadpleeg het volgende voorbeeld om u te helpen bij het ophalen van de waarden voor het belang van statistische functies (globaal).
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Een afzonderlijke voorspelling uitleggen (lokale uitleg)
Haal de waarden voor het belang van afzonderlijke functies van verschillende gegevenspunten op door uitleg aan te roepen voor een afzonderlijk exemplaar of een groep exemplaren.
Notitie
PFIExplainer biedt geen ondersteuning voor lokale uitleg.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Onbewerkte functietransformaties
U kunt ervoor kiezen om uitleg te krijgen in termen van onbewerkte, niet-vertaalde functies in plaats van ontworpen functies. Voor deze optie geeft u uw pijplijn voor functietransformatie door aan de uitleg in train_explain.py. Anders biedt de uitleg uitleg over de functies die zijn ontworpen.
De indeling van ondersteunde transformaties is hetzelfde als beschreven in sklearn-pandas. In het algemeen worden transformaties ondersteund zolang ze op één kolom werken, zodat ze duidelijk zijn dat ze een-op-veel zijn.
Krijg een uitleg over onbewerkte functies met behulp van een sklearn.compose.ColumnTransformer of met een lijst met ingerichte transformator tuples. In het volgende voorbeeld wordt gebruikgemaakt van sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Gebruik de volgende code als u het voorbeeld wilt uitvoeren met de lijst met aangepaste transformator tuples:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Waardewaarden voor functiebelang genereren via externe uitvoeringen
In het volgende voorbeeld ziet u hoe u de ExplanationClient klasse kunt gebruiken om modelinterpreteerbaarheid in te schakelen voor externe uitvoeringen. Het is conceptueel vergelijkbaar met het lokale proces, met uitzondering van u:
- Gebruik de
ExplanationClientexterne uitvoering om de interpreteerbaarheidscontext te uploaden. - Download de context later in een lokale omgeving.
Installeer het
azureml-interpret-pakket.pip install azureml-interpretMaak een trainingsscript in een lokaal Jupyter Notebook. Bijvoorbeeld:
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Stel een Azure Machine Learning Compute in als uw rekendoel en dien de trainingsuitvoering in. Zie Azure Machine Learning-rekenclusters maken en beheren voor instructies. Mogelijk vindt u ook de voorbeeldnotitieblokken nuttig.
Download de uitleg in uw lokale Jupyter Notebook.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Visualisaties
Nadat u de uitleg in uw lokale Jupyter Notebook hebt gedownload, kunt u de visualisaties in het dashboard uitleg gebruiken om uw model te begrijpen en te interpreteren. Gebruik de volgende code om de dashboardwidget uitleg in uw Jupyter Notebook te laden:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
De visualisaties ondersteunen uitleg over zowel ontworpen als onbewerkte functies. Onbewerkte uitleg is gebaseerd op de functies van de oorspronkelijke gegevensset en kundige uitleg zijn gebaseerd op de functies uit de gegevensset waarop functie-engineering is toegepast.
Wanneer u probeert een model te interpreteren met betrekking tot de oorspronkelijke gegevensset, is het raadzaam onbewerkte uitleg te gebruiken, omdat elk functiebelang overeenkomt met een kolom uit de oorspronkelijke gegevensset. Een scenario waarin ontworpen uitleg nuttig kan zijn, is bij het onderzoeken van de impact van afzonderlijke categorieën op basis van een categorische functie. Als een one-hot codering wordt toegepast op een categorische functie, bevatten de resulterende ontworpen uitleg een andere urgentiewaarde per categorie, één per hot-engineered functie. Deze codering kan nuttig zijn bij het beperken van welk deel van de gegevensset het meest informatief is voor het model.
Notitie
Ontworpen en onbewerkte uitleg worden sequentieel berekend. Eerst wordt een ontworpen uitleg gemaakt op basis van het model en de featurization-pijplijn. Vervolgens wordt de onbewerkte uitleg gemaakt op basis van die ontworpen uitleg door het belang te aggregeren van ontworpen functies die afkomstig zijn van dezelfde onbewerkte functie.
Cohorten voor gegevenssets maken, bewerken en weergeven
Op het bovenste lint ziet u de algemene statistieken voor uw model en gegevens. U kunt uw gegevens segmenteren en dobbelen in cohorten van gegevenssets, of subgroepen, om de prestaties en uitleg van uw model in deze gedefinieerde subgroepen te onderzoeken of te vergelijken. Door de statistieken en uitleg van uw gegevenssets in deze subgroepen te vergelijken, krijgt u een idee waarom mogelijke fouten zich in de ene groep of in een andere groep voordoen.

Volledig modelgedrag begrijpen (globale uitleg)
De eerste drie tabbladen van het uitlegdashboard bieden een algemene analyse van het getrainde model, samen met de voorspellingen en uitleg.
Modelprestaties
Evalueer de prestaties van uw model door de distributie van uw voorspellingswaarden en de waarden van uw modelprestatiegegevens te verkennen. U kunt uw model verder onderzoeken door te kijken naar een vergelijkende analyse van de prestaties in verschillende cohorten of subgroepen van uw gegevensset. Selecteer filters langs y-waarde en x-waarde om over verschillende dimensies te snijden. Bekijk metrische gegevens, zoals nauwkeurigheid, precisie, relevante overeenkomsten, fout-positieve frequentie (FPR) en fout-negatieve rente (FNR).

Gegevenssetverkenner
Verken uw gegevenssetstatistieken door verschillende filters langs de X-, Y- en kleurassen te selecteren om uw gegevens over verschillende dimensies te segmenteren. Maak gegevensset cohorten hierboven om gegevenssetstatistieken te analyseren met filters zoals voorspeld resultaat, gegevenssetfuncties en foutgroepen. Gebruik het tandwielpictogram in de rechterbovenhoek van de grafiek om grafiektypen te wijzigen.

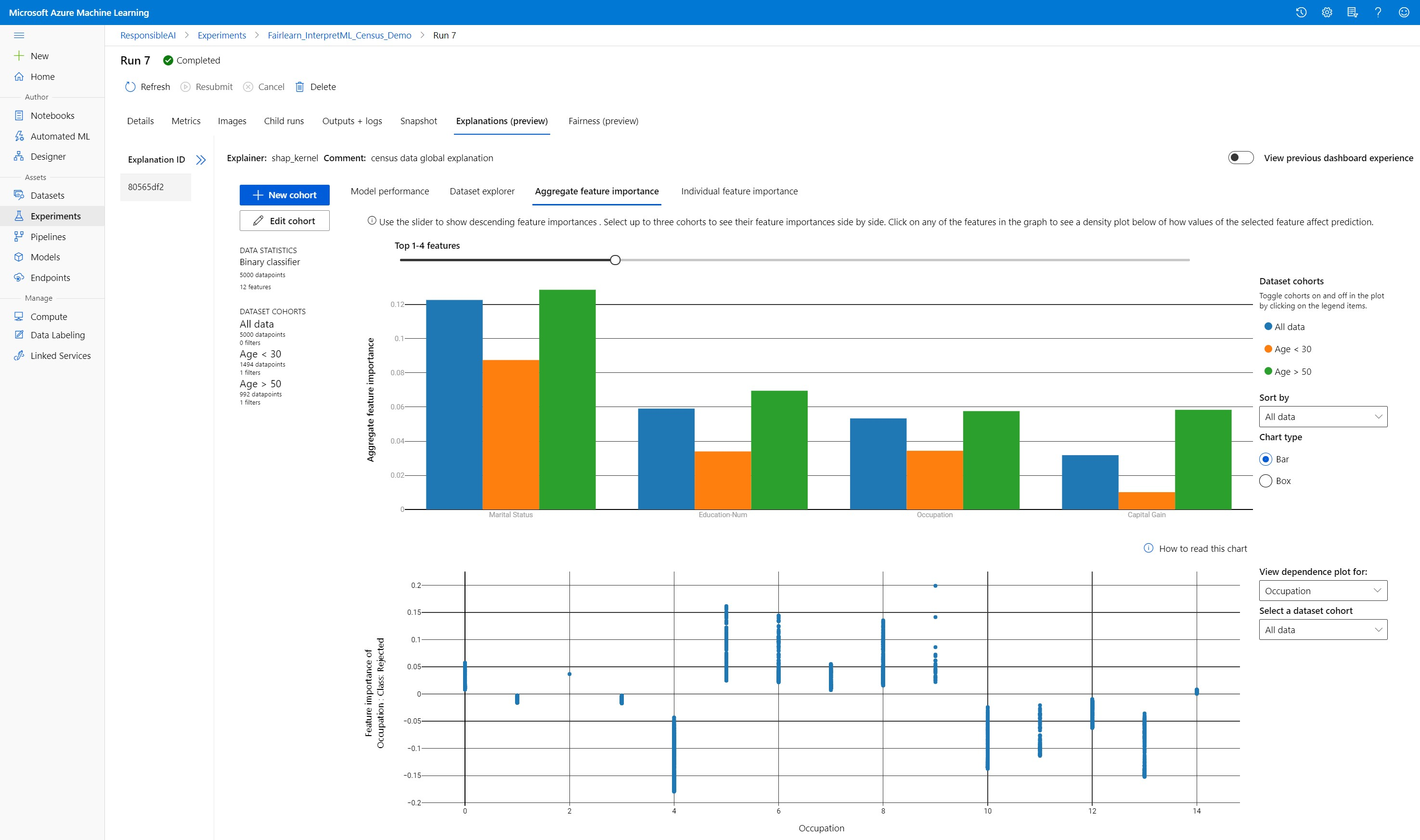
Urgentie van statistische functies
Verken de belangrijkste functies die van invloed zijn op uw algemene modelvoorspellingen (ook wel globale uitleg genoemd). Gebruik de schuifregelaar om aflopende waardewaarden voor functiebelang weer te geven. Selecteer maximaal drie cohorten om de urgentiewaarden van hun functie naast elkaar weer te geven. Selecteer een van de functiebalken in de grafiek om te zien hoe waarden van de voorspelling van het geselecteerde functiemodel beïnvloeden in het onderstaande afhankelijkheidsdiagram.

Inzicht in afzonderlijke voorspellingen (lokale uitleg)
Op het vierde tabblad van het tabblad Uitleg kunt u inzoomen op een afzonderlijk gegevenspunt en de urgentie van de afzonderlijke functies. U kunt de afzonderlijke functiebelangplot voor elk gegevenspunt laden door te klikken op een van de afzonderlijke gegevenspunten in het hoofdspreidingsdiagram of door een specifiek gegevenspunt te selecteren in de wizard aan de rechterkant van het deelvenster.
| Plotten | Beschrijving |
|---|---|
| Urgentie van afzonderlijke functies | Toont de belangrijkste functies van top k voor een afzonderlijke voorspelling. Helpt het lokale gedrag van het onderliggende model op een specifiek gegevenspunt te illustreren. |
| Wat-als-analyse | Hiermee kunt u wijzigingen aanbrengen in functiewaarden van het geselecteerde werkelijke gegevenspunt en de resulterende wijzigingen in de voorspellingswaarde observeren door een hypothetisch gegevenspunt te genereren met de nieuwe functiewaarden. |
| Individuele voorwaardelijke verwachting (ICE) | Hiermee kunt u functiewaardewijzigingen van een minimumwaarde tot een maximumwaarde toestaan. Helpt u te illustreren hoe de voorspelling van het gegevenspunt verandert wanneer een functie wordt gewijzigd. |

Notitie
Dit zijn verklaringen op basis van veel benaderingen en zijn niet de 'oorzaak' van voorspellingen. Zonder strikte wiskundige robuustheid van causale deductie raden we gebruikers niet aan om echte beslissingen te nemen op basis van de functie-verstoringen van het What-If-hulpprogramma. Dit hulpprogramma is voornamelijk bedoeld om inzicht te krijgen in uw model en foutopsporing.
Visualisatie in Azure Machine Learning-studio
Als u de stappen voor externe interpreteerbaarheid (het uploaden van gegenereerde uitleg naar De uitvoeringsgeschiedenis van Azure Machine Learning) voltooit, kunt u de visualisaties bekijken op het dashboard uitleg in Azure Machine Learning-studio. Dit dashboard is een eenvoudigere versie van de dashboardwidget die wordt gegenereerd in uw Jupyter Notebook. What-If-gegevenspunten genereren en ICE-plots zijn uitgeschakeld omdat er geen actieve berekeningen zijn in Azure Machine Learning-studio die hun realtime berekeningen kunnen uitvoeren.
Als de gegevensset, globale en lokale uitleg beschikbaar zijn, worden alle tabbladen ingevuld. Als er echter alleen een algemene uitleg beschikbaar is, wordt het tabblad Afzonderlijke functiebelang uitgeschakeld.
Volg een van deze paden voor toegang tot het dashboard uitleg in Azure Machine Learning-studio:
Deelvenster Experimenten (preview)
- Selecteer Experimenten in het linkerdeelvenster om een lijst weer te geven met experimenten die u hebt uitgevoerd op Azure Machine Learning.
- Selecteer een bepaald experiment om alle uitvoeringen in dat experiment weer te geven.
- Selecteer een uitvoering en vervolgens het tabblad Uitleg naar het dashboard voor uitlegvisualisatie.
Deelvenster Modellen
- Als u uw oorspronkelijke model hebt geregistreerd door de stappen in Modellen implementeren met Azure Machine Learning te volgen, kunt u modellen selecteren in het linkerdeelvenster om het te bekijken.
- Selecteer een model en vervolgens het tabblad Uitleg om het dashboard uitleg weer te geven.

Interpreteerbaarheid bij deductietijd
U kunt de uitleg samen met het oorspronkelijke model implementeren en gebruiken op deductietijd om de waarden voor het belang van afzonderlijke functies (lokale uitleg) voor elk nieuw gegevenspunt op te geven. We bieden ook uitleg over lichter gewicht scoren om de interpreteerbaarheidsprestaties tijdens deductietijd te verbeteren. Deze wordt momenteel alleen ondersteund in de Azure Machine Learning SDK. Het proces voor het implementeren van een lichtere score-uitleg is vergelijkbaar met het implementeren van een model en bevat de volgende stappen:
Maak een uitlegobject. U kunt bijvoorbeeld het volgende gebruiken
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Maak een score-uitleg met het uitlegobject.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Configureer en registreer een installatiekopieën die gebruikmaken van het score-uitlegmodel.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Als optionele stap kunt u de score-uitleg ophalen uit de cloud en de uitleg testen.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Implementeer de installatiekopieën op een rekendoel door de volgende stappen uit te voeren:
Registreer indien nodig uw oorspronkelijke voorspellingsmodel door de stappen in Modellen implementeren met Azure Machine Learning te volgen.
Maak een scorebestand.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}De implementatieconfiguratie configureren.
Deze configuratie is afhankelijk van de vereisten van uw model. In het volgende voorbeeld wordt een configuratie gedefinieerd die gebruikmaakt van één CPU-kern en één GB geheugen.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Maak een bestand met omgevingsafhankelijkheden.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Maak een aangepast dockerfile waarop g++ is geïnstalleerd.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Implementeer de gemaakte installatiekopieën.
Dit proces duurt ongeveer vijf minuten.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Test de implementatie.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Opschonen.
Als u een geïmplementeerde webservice wilt verwijderen, gebruikt u
service.delete().
Probleemoplossing
Sparse-gegevens worden niet ondersteund: het dashboard voor modeluitleg wordt aanzienlijk onderbreekt/vertraagt aanzienlijk met een groot aantal functies, daarom bieden we momenteel geen ondersteuning voor de sparse-gegevensindeling. Daarnaast ontstaan er algemene geheugenproblemen met grote gegevenssets en een groot aantal functies.
Ondersteunde uitlegfunctiesmatrix
| Tabblad Ondersteunde uitleg | Onbewerkte functies (dicht) | Onbewerkte functies (sparse) | Ontworpen functies (dicht) | Ontworpen functies (sparse) |
|---|---|---|---|---|
| Modelprestaties | Ondersteund (geen prognose) | Ondersteund (geen prognose) | Ondersteund | Ondersteund |
| Gegevenssetverkenner | Ondersteund (geen prognose) | Wordt niet ondersteund. Omdat sparse-gegevens niet worden geüpload en de gebruikersinterface problemen heeft met het weergeven van sparsegegevens. | Ondersteund | Wordt niet ondersteund. Omdat sparse-gegevens niet worden geüpload en de gebruikersinterface problemen heeft met het weergeven van sparsegegevens. |
| Urgentie van statistische functies | Ondersteund | Ondersteund | Ondersteund | Ondersteund |
| Urgentie van afzonderlijke functies | Ondersteund (geen prognose) | Wordt niet ondersteund. Omdat sparse-gegevens niet worden geüpload en de gebruikersinterface problemen heeft met het weergeven van sparsegegevens. | Ondersteund | Wordt niet ondersteund. Omdat sparse-gegevens niet worden geüpload en de gebruikersinterface problemen heeft met het weergeven van sparsegegevens. |
Prognosemodellen worden niet ondersteund met modeluitleg: Interpreteerbaarheid, beste modeluitleg, is niet beschikbaar voor AutoML-voorspellingsexperimenten die de volgende algoritmen aanbevelen als het beste model: TCNForecaster, AutoArima, Prophet, ExponentialSmoothing, Average, Naive, Seasonal Average en Seasonal Naive. AutoML-regressiemodellen ondersteunen uitleg. In het uitlegdashboard wordt het tabblad Afzonderlijke functiebelang echter niet ondersteund voor prognose vanwege complexiteit in hun gegevenspijplijnen.
Lokale uitleg voor gegevensindex: het uitlegdashboard biedt geen ondersteuning voor het koppelen van lokale urgentiewaarden aan een rij-id van de oorspronkelijke validatiegegevensset als die gegevensset groter is dan 5000 gegevenspunten, omdat het dashboard de gegevens willekeurig ondersampt. In het dashboard worden echter onbewerkte gegevenssetfunctiewaarden weergegeven voor elk gegevenspunt dat wordt doorgegeven aan het dashboard op het tabblad Prioriteit van afzonderlijke functies. Gebruikers kunnen lokale urgenties weer toewijzen aan de oorspronkelijke gegevensset door de waarden van de onbewerkte gegevenssetfunctie te vinden. Als de grootte van de validatiegegevensset kleiner is dan 5000 voorbeelden, komt de
indexfunctie in Azure Machine Learning-studio overeen met de index in de validatiegegevensset.What-if/ICE-plots worden niet ondersteund in studio: What-If- en Individual Conditional Expectation (ICE)-plots worden niet ondersteund in Azure Machine Learning-studio op het tabblad Uitleg, omdat de geüploade uitleg een actief rekenproces nodig heeft om voorspellingen en waarschijnlijkheden van gestoorde functies opnieuw te berekenen. Het wordt momenteel ondersteund in Jupyter-notebooks wanneer deze worden uitgevoerd als widget met behulp van de SDK.
Volgende stappen
Technieken voor modelinterpretabiliteit in Azure Machine Learning
Azure Machine Learning-voorbeeldnotebooks voor interpreteerbaarheid bekijken