Inhoudsfilters configureren met Azure AI Foundry
Het inhoudsfiltersysteem dat is geïntegreerd in Azure AI Foundry wordt uitgevoerd naast de kernmodellen, waaronder DALL-E-modellen voor het genereren van installatiekopieën. Het maakt gebruik van een ensemble van classificatiemodellen met meerdere klassen om vier categorieën schadelijke inhoud (geweld, haat, seksueel en zelfbeschadiging) te detecteren op respectievelijk vier ernstniveaus (veilig, laag, gemiddeld en hoog) en optionele binaire classificaties voor het detecteren van jailbreakrisico's, bestaande tekst en code in openbare opslagplaatsen.
De standaardconfiguratie voor inhoudsfiltering is ingesteld om te filteren op de drempelwaarde voor gemiddelde ernst voor alle vier de inhoudscategorieën voor zowel prompts als voltooiingen. Dit betekent dat inhoud die wordt gedetecteerd op ernstniveau gemiddeld of hoog, wordt gefilterd, terwijl inhoud op ernstniveau laag of veilig niet wordt gefilterd door de inhoudsfilters. Meer informatie over inhoudscategorieën, ernstniveaus en het gedrag van het inhoudsfiltersysteem vindt u hier.
Jailbreak-risicodetectie en beveiligde tekst- en codemodellen zijn optioneel en standaard ingeschakeld. Voor jailbreak- en beveiligde tekst- en codemodellen kunnen alle klanten de modellen in- en uitschakelen met de functie configureerbaarheid. De modellen zijn standaard ingeschakeld en kunnen worden uitgeschakeld volgens uw scenario. Sommige modellen moeten zijn ingeschakeld voor bepaalde scenario's om dekking te behouden onder de toezegging voor het auteursrecht van de klant.
Notitie
Alle klanten hebben de mogelijkheid om de inhoudsfilters te wijzigen en de ernstdrempels (laag, gemiddeld, hoog) te configureren. Goedkeuring is vereist voor het gedeeltelijk of volledig uitschakelen van de inhoudsfilters. Beheerde klanten kunnen alleen van toepassing zijn op volledig beheer van inhoudsfilters via Beperkte toegangsbeoordeling van Azure OpenAI: Gewijzigde inhoudsfilters. Op dit moment is het niet mogelijk om een beheerde klant te worden.
Inhoudsfilters kunnen worden geconfigureerd op resourceniveau. Zodra een nieuwe configuratie is gemaakt, kan deze worden gekoppeld aan een of meer implementaties. Zie de gids implementatiemodellen voor meer informatie over de implementatiemodellen.
Vereisten
- U moet een Azure OpenAI-resource en een LLM-implementatie (Large Language Model) hebben om inhoudsfilters te configureren. Volg een snelstart om aan de slag te gaan.
Inzicht in de configureerbaarheid van inhoudsfilters
Azure OpenAI Service bevat standaardbeveiligingsinstellingen die zijn toegepast op alle modellen, met uitzondering van Azure OpenAI Whisper. Deze configuraties bieden u standaard een verantwoorde ervaring, waaronder modellen voor inhoudsfilters, bloklijsten, prompttransformatie, inhoudsreferenties en andere. Lees hier meer over.
Alle klanten kunnen ook inhoudsfilters configureren en aangepast veiligheidsbeleid maken dat is afgestemd op hun use-casevereisten. Met de configureerbaarheidsfunctie kunnen klanten de instellingen, afzonderlijk voor prompts en voltooiingen, aanpassen om inhoud voor elke inhoudscategorie op verschillende ernstniveaus te filteren, zoals beschreven in de onderstaande tabel. Inhoud die is gedetecteerd op het ernstniveau 'veilig', wordt gelabeld in aantekeningen, maar is niet onderhevig aan filteren en kan niet worden geconfigureerd.
| Ernst gefilterd | Configureerbaar voor prompts | Configureerbaar voor voltooiingen | Omschrijvingen |
|---|---|---|---|
| Laag, gemiddeld, hoog | Ja | Ja | Striktste filterconfiguratie. Inhoud die is gedetecteerd op ernstniveaus laag, gemiddeld en hoog, wordt gefilterd. |
| Gemiddeld, hoog | Ja | Ja | Inhoud die is gedetecteerd op ernstniveau laag, wordt niet gefilterd, inhoud op gemiddeld en hoog wordt gefilterd. |
| Hoog | Ja | Ja | Inhoud die is gedetecteerd op ernstniveaus laag en gemiddeld, wordt niet gefilterd. Alleen inhoud op ernstniveau hoog wordt gefilterd. |
| Geen filters | Indien goedgekeurd1 | Indien goedgekeurd1 | Er wordt geen inhoud gefilterd, ongeacht het ernstniveau dat is gedetecteerd. Vereist goedkeuring1. |
| Alleen aantekeningen maken | Indien goedgekeurd1 | Indien goedgekeurd1 | Hiermee wordt de filterfunctionaliteit uitgeschakeld, zodat inhoud niet wordt geblokkeerd, maar aantekeningen worden geretourneerd via API-antwoord. Vereist goedkeuring1. |
1 Voor Azure OpenAI-modellen hebben alleen klanten die zijn goedgekeurd voor aangepaste inhoudsfilters volledige controle over inhoudsfilters en kunnen inhoudsfilters uitschakelen. Aanvragen voor gewijzigde inhoudsfilters via dit formulier: Beperkte toegangsbeoordeling van Azure OpenAI: Gewijzigde inhoudsfilters. Voor Klanten van Azure Government kunt u via dit formulier aangepaste inhoudsfilters aanvragen: Azure Government - Aangepaste inhoudsfilters aanvragen voor De Azure OpenAI-service.
Configureerbare inhoudsfilters voor invoer (prompts) en uitvoer (voltooiingen) zijn beschikbaar voor alle Azure OpenAI-modellen.
Configuraties voor inhoudsfilters worden gemaakt in een resource in de Azure AI Foundry-portal en kunnen worden gekoppeld aan implementaties. Meer informatie over configureerbaarheid vindt u hier.
Klanten zijn verantwoordelijk voor het garanderen dat toepassingen die Azure OpenAI integreren, voldoen aan de gedragscode.
Meer informatie over andere filters
U kunt de volgende filtercategorieën configureren naast de standaardfilters voor schadelijke categorieën.
| Filtercategorie | Status | Standaardinstelling | Toegepast op prompt of voltooiing? | Beschrijving |
|---|---|---|---|---|
| Prompt Shields voor directe aanvallen (jailbreak) | GA | Uit | Gebruikersprompt | Filters/aantekeningen maken van gebruikersprompts die mogelijk een jailbreakrisico vormen. Ga naar Azure AI Foundry-inhoudsfiltering voor meer informatie over aantekeningen. |
| Vraag afschermingen voor indirecte aanvallen | GA | Uit | Gebruikersprompt | Filter/aantekeningen maken van indirecte aanvallen, ook wel indirecte promptaanvallen of aanvallen tussen domeinprompts genoemd, een potentieel beveiligingsprobleem waarbij derden schadelijke instructies plaatsen in documenten waartoe het generatieve AI-systeem toegang heeft en verwerkt. Vereist: document insluiten en opmaken. |
| Beschermd materiaal - code | GA | Uit | Voltooiing | Filtert beveiligde code of haalt de voorbeeldvermelding en licentiegegevens op in aantekeningen voor codefragmenten die overeenkomen met openbare codebronnen, mogelijk gemaakt door GitHub Copilot. Zie de handleiding met concepten voor inhoudsfilters voor meer informatie over het gebruik van aantekeningen |
| Beveiligd materiaal - tekst | GA | Uit | Voltooiing | Identificeert en blokkeert bekende tekstinhoud die wordt weergegeven in de modeluitvoer (bijvoorbeeld liedteksten, recepten en geselecteerde webinhoud). |
| Geaardheid* | Preview uitvoeren | Uit | Voltooiing | Hiermee wordt gedetecteerd of de tekstreacties van grote taalmodellen (LLM's) worden geaard in de bronmaterialen van de gebruikers. Niet-geaardheid verwijst naar instanties waarbij de LLM's informatie produceren die niet feitelijk of onnauwkeurig is van wat aanwezig was in de bronmaterialen. Vereist: document insluiten en opmaken. |
Een inhoudsfilter maken in Azure AI Foundry
Voor elke modelimplementatie in Azure AI Foundry kunt u het standaardinhoudsfilter rechtstreeks gebruiken, maar misschien wilt u meer controle hebben. U kunt bijvoorbeeld een filter strenger of flexibeler maken of geavanceerdere mogelijkheden inschakelen, zoals promptschilden en beveiligde materiaaldetectie.
Tip
Voor hulp bij inhoudsfilters in uw Azure AI Foundry-project kunt u meer lezen op Azure AI Foundry-inhoudsfilters.
Volg deze stappen om een inhoudsfilter te maken:
Ga naar Azure AI Foundry en navigeer naar uw project. Selecteer vervolgens de pagina Veiligheid en beveiliging in het linkermenu en selecteer het tabblad Inhoudsfilters .
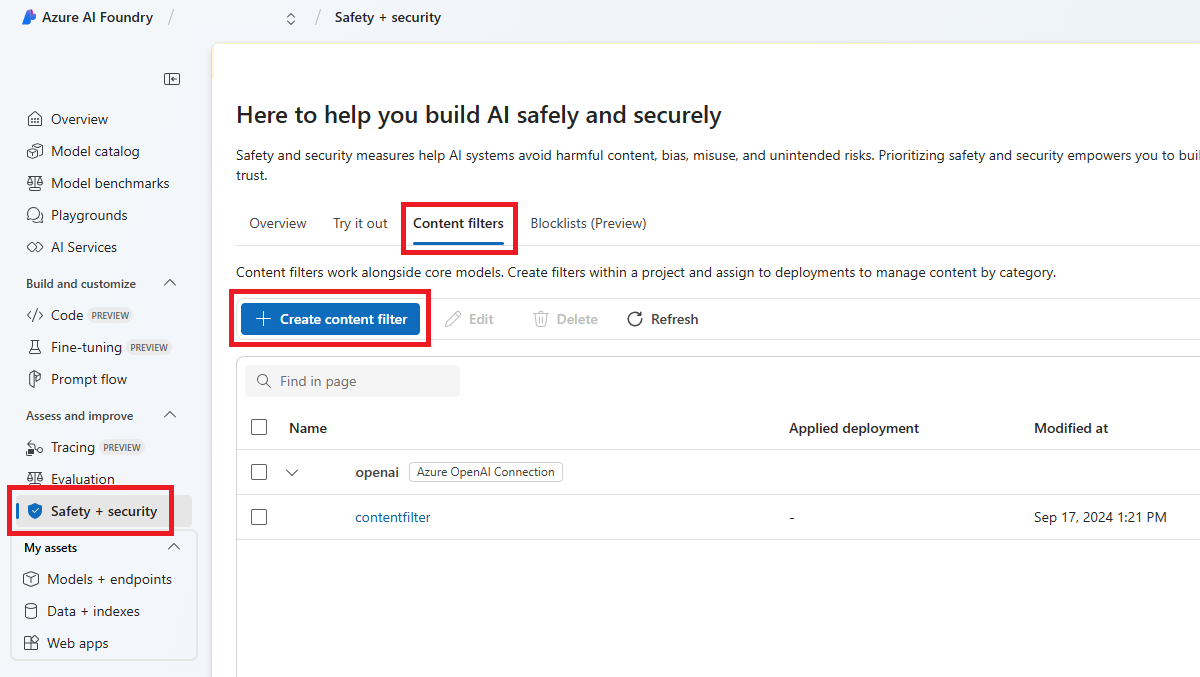
Selecteer + Inhoudsfilter maken.
Voer op de pagina Basisgegevens een naam in voor de configuratie van het filteren van inhoud. Selecteer een verbinding om aan het inhoudsfilter te koppelen. Selecteer Volgende.
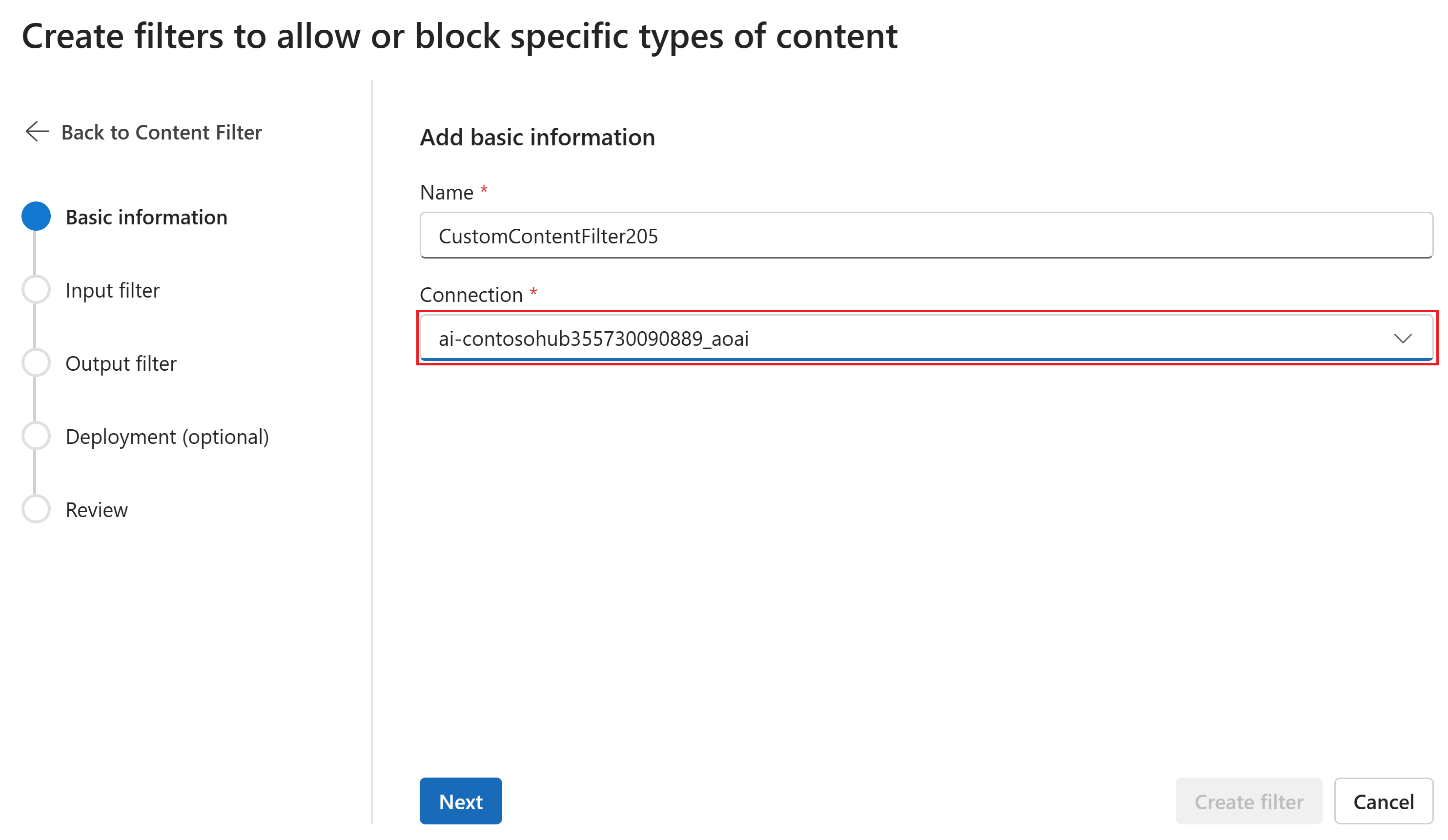
U kunt nu de invoerfilters (voor gebruikersprompts) en uitvoerfilters (voor voltooiing van het model) configureren.
Op de pagina Invoerfilters kunt u het filter voor de invoerprompt instellen. Voor de eerste vier inhoudscategorieën zijn er drie ernstniveaus die kunnen worden geconfigureerd: Laag, Gemiddeld en Hoog. U kunt de schuifregelaars gebruiken om de ernstdrempel in te stellen als u bepaalt dat voor uw toepassing of gebruiksscenario andere filters zijn vereist dan de standaardwaarden. Met sommige filters, zoals promptschilden en beveiligde materiaaldetectie, kunt u bepalen of het model aantekeningen moet maken en/of inhoud moet blokkeren. Als u Aantekeningen selecteren, wordt alleen het respectieve model uitgevoerd en worden aantekeningen geretourneerd via api-antwoord, maar wordt inhoud niet gefilterd. Naast aantekeningen kunt u er ook voor kiezen om inhoud te blokkeren.
Als uw use-case is goedgekeurd voor gewijzigde inhoudsfilters, ontvangt u volledige controle over configuraties voor inhoudsfilters en kunt u ervoor kiezen om filteren gedeeltelijk of volledig uit te schakelen of aantekeningen alleen in te schakelen voor de categorieën inhoudsschade (geweld, haat, seksueel en zelfbeschadiging).
Inhoud wordt geannoteerd op categorie en geblokkeerd volgens de drempelwaarde die u hebt ingesteld. Voor de categorieën geweld, haat, seksueel en zelfschadigen, past u de schuifregelaar aan om inhoud van hoog, gemiddeld of laag ernst te blokkeren.
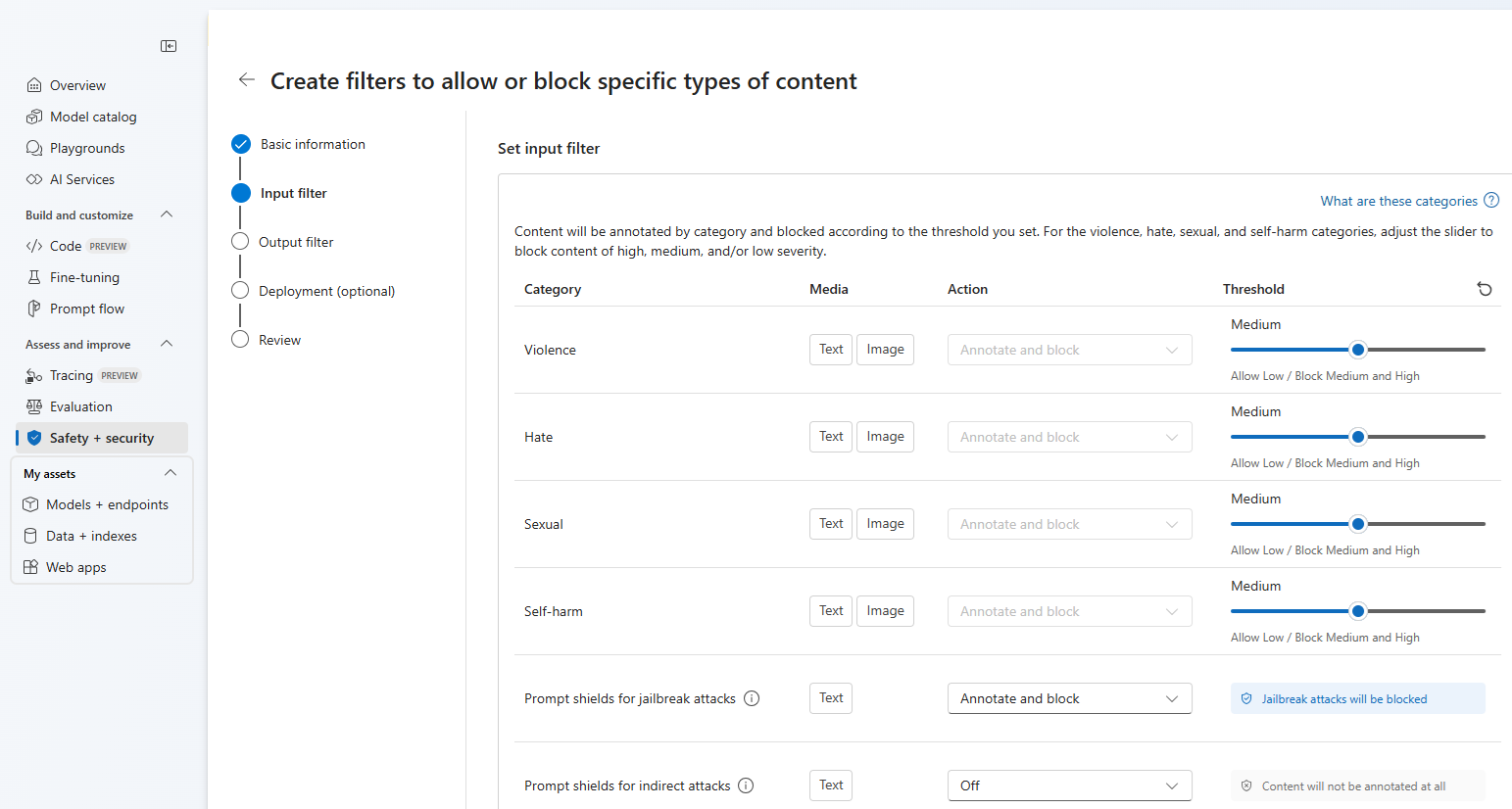
Op de pagina Uitvoerfilters kunt u het uitvoerfilter configureren dat wordt toegepast op alle uitvoerinhoud die door uw model wordt gegenereerd. Configureer de afzonderlijke filters zoals voorheen. Deze pagina biedt ook de optie Streamingmodus, waarmee u inhoud in bijna realtime kunt filteren terwijl deze wordt gegenereerd door het model, waardoor de latentie wordt verminderd. Wanneer u klaar bent, selecteert u Volgende.
Inhoud wordt geannoteerd door elke categorie en geblokkeerd volgens de drempelwaarde. Voor gewelddadige inhoud, haat inhoud, seksuele inhoud en inhoudscategorie die zelf schade toebrengt, past u de drempelwaarde aan om schadelijke inhoud met gelijke of hogere ernstniveaus te blokkeren.
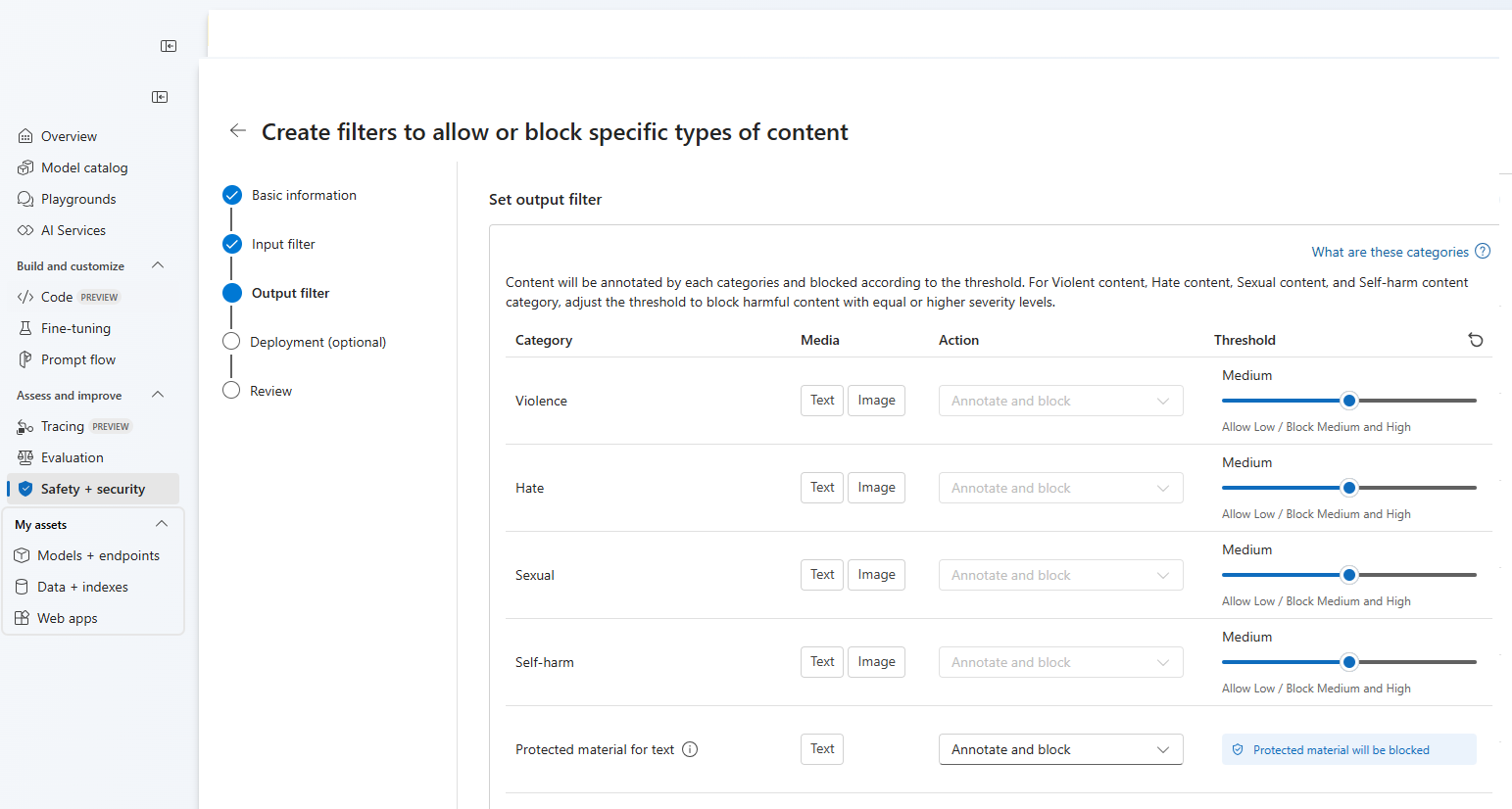
U kunt eventueel op de pagina Implementatie het inhoudsfilter koppelen aan een implementatie. Als voor een geselecteerde implementatie al een filter is gekoppeld, moet u bevestigen dat u deze wilt vervangen. U kunt het inhoudsfilter ook later koppelen aan een implementatie. Selecteer Maken.
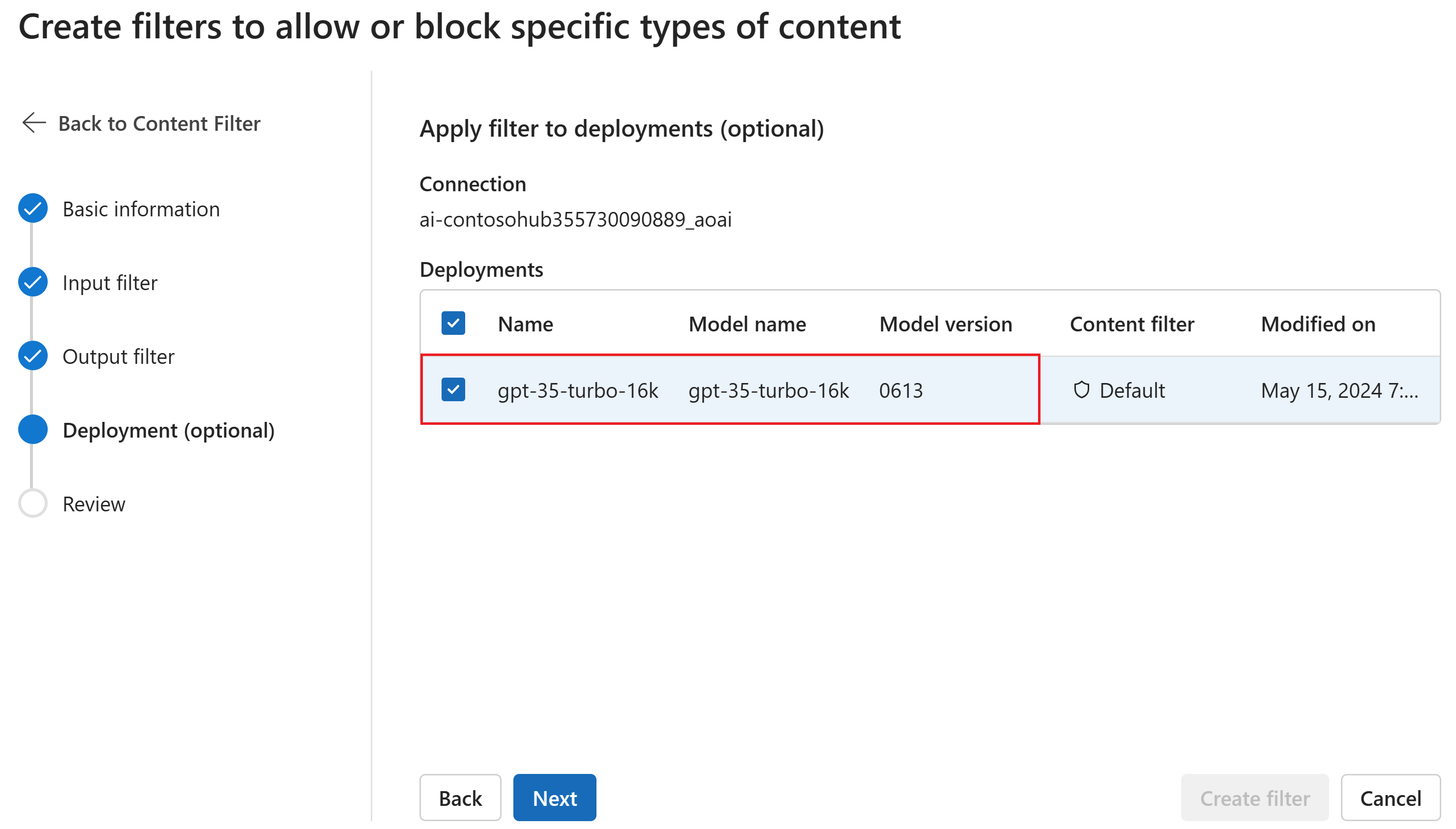
Configuraties voor inhoudsfilters worden gemaakt op hubniveau in de Azure AI Foundry-portal. Meer informatie over de configuratiemogelijkheden vindt u in de documentatie van de Azure OpenAI-service.
Controleer de instellingen op de pagina Controleren en selecteer vervolgens Filter maken.



Een blokkering als filter gebruiken
U kunt een bloklijst toepassen als een invoer- of uitvoerfilter, of beide. Schakel de optie Bloklijst in op de pagina Invoerfilter en/of Uitvoerfilter . Selecteer een of meer bloklijsten in de vervolgkeuzelijst of gebruik de ingebouwde bloklijst voor grof taalgebruik. U kunt meerdere bloklijsten combineren in hetzelfde filter.
Een inhoudsfilter toepassen
Het proces voor het maken van filters biedt u de mogelijkheid om het filter toe te passen op de gewenste implementaties. U kunt inhoudsfilters ook op elk gewenst moment wijzigen of verwijderen uit uw implementaties.
Volg deze stappen om een inhoudsfilter toe te passen op een implementatie:
Ga naar Azure AI Foundry en selecteer een project.
Selecteer Modellen en eindpunten in het linkerdeelvenster en kies een van uw implementaties en selecteer vervolgens Bewerken.
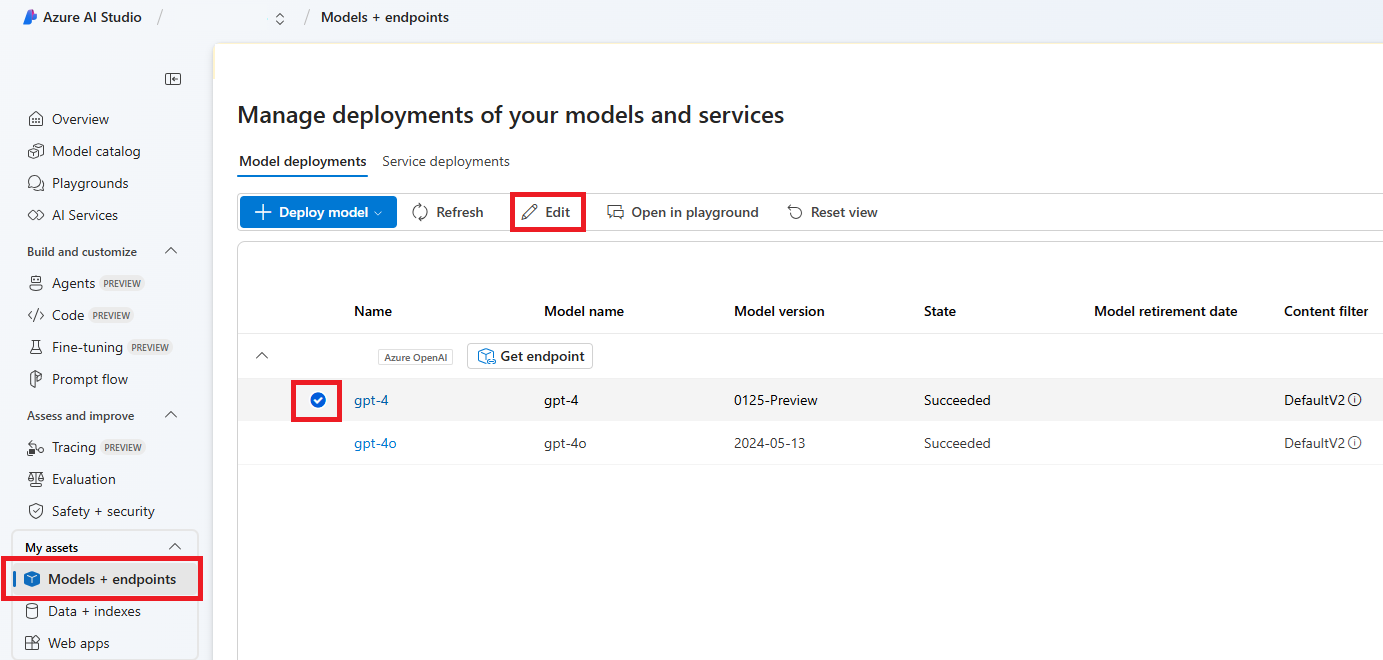
Selecteer in het venster Update-implementatie het inhoudsfilter dat u wilt toepassen op de implementatie. Selecteer Vervolgens Opslaan en sluiten.
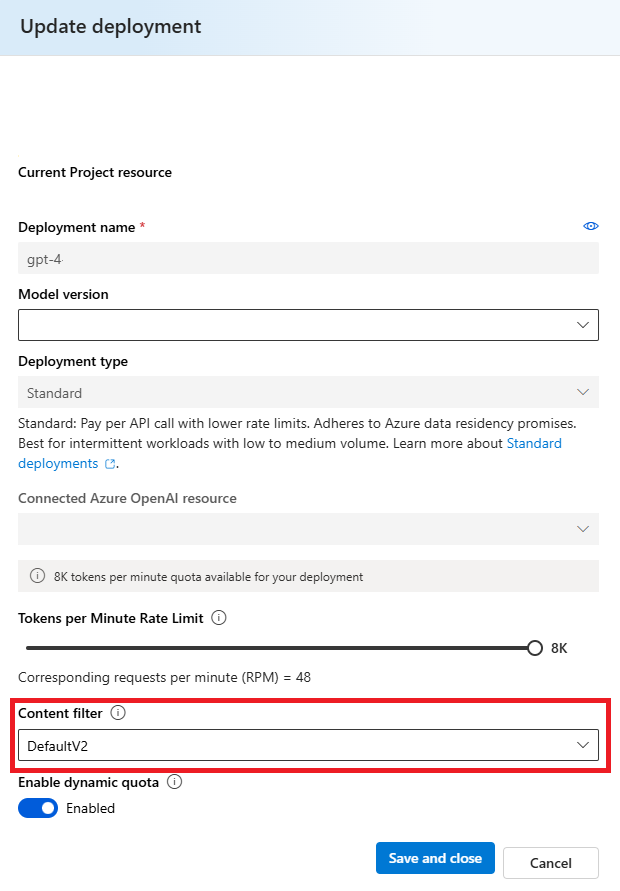
U kunt indien nodig ook een configuratie van een inhoudsfilter bewerken en verwijderen. Voordat u een configuratie voor inhoudsfiltering verwijdert, moet u de toewijzing ongedaan maken en vervangen door een implementatie op het tabblad Implementaties .


U kunt nu naar de speeltuin gaan om te testen of het inhoudsfilter werkt zoals verwacht.
Feedback over het filteren van rapportinhoud
Als u een probleem ondervindt met het filteren van inhoud, selecteert u de knop Feedback filteren bovenaan de speeltuin. Dit is ingeschakeld in de speeltuin Afbeeldingen, Chatten en Voltooiingen zodra u een prompt indient .
Wanneer het dialoogvenster wordt weergegeven, selecteert u het juiste probleem met het filteren van inhoud. Neem zoveel mogelijk details op met betrekking tot uw probleem met inhoudsfiltering, zoals de specifieke prompt en de fout bij het filteren van inhoud die u hebt aangetroffen. Neem geen persoonlijke of gevoelige informatie op.
Voor ondersteuning dient u een ondersteuningsticket in.
Best practices volgen
Het is raadzaam om uw beslissingen over de configuratie van inhoudsfilters te informeren via een iteratieve identificatie (bijvoorbeeld het testen van rode teams, stresstests en analyse) en het meetproces om de mogelijke schade aan te pakken die relevant zijn voor een specifiek model, toepassing en implementatiescenario. Nadat u oplossingen zoals inhoudsfiltering hebt geïmplementeerd, herhaalt u de meting om de effectiviteit te testen. Aanbevelingen en best practices voor verantwoordelijke AI voor Azure OpenAI, op basis van microsoft Responsible AI Standard , vindt u in het Overzicht van Verantwoorde AI voor Azure OpenAI.
Gerelateerde inhoud
- Meer informatie over verantwoorde AI-procedures voor Azure OpenAI: overzicht van verantwoorde AI-procedures voor Azure OpenAI-modellen.
- Lees meer over inhoudsfiltercategorieën en ernstniveaus met Azure AI Foundry.
- Meer informatie over rode koppeling vindt u in ons artikel Inleiding tot red teaming large language models (LLMs).