Quickstart: Aan de slag met het genereren van audio van Azure OpenAI
De gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen introduceren de modaliteit van audio in de bestaande /chat/completions API. Het audiomodel breidt het potentieel uit voor AI-toepassingen in tekst- en spraakgebaseerde interacties en audioanalyse. Modaliteiten die worden ondersteund in gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen zijn onder andere: tekst, audio en tekst + audio.
Hier volgt een tabel met de ondersteunde modaliteiten met voorbeeldgebruiksvoorbeelden:
| Modaliteitsinvoer | Modaliteitsuitvoer | Voorbeeld van een toepassing |
|---|---|---|
| Sms verzenden | Tekst en audio | Tekst naar spraak, audioboekgeneratie |
| Audio | Tekst en audio | Audiotranscriptie, audioboekgeneratie |
| Audio | Sms verzenden | Audiotranscriptie |
| Tekst en audio | Tekst en audio | Audioboekgeneratie |
| Tekst en audio | Sms verzenden | Audiotranscriptie |
Met behulp van mogelijkheden voor het genereren van audio kunt u dynamischere en interactieve AI-toepassingen bereiken. Met modellen die audio-invoer en -uitvoer ondersteunen, kunt u gesproken audioantwoorden genereren om vragen te stellen en audio-invoer te gebruiken om het model te vragen.
Ondersteunde modellen
Momenteel alleen gpt-4o-audio-preview en gpt-4o-mini-audio-preview versie: 2024-12-17 ondersteunt het genereren van audio.
Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
Momenteel worden de volgende stemmen ondersteund voor audio: Legering, Echo en Shimmer.
De maximale bestandsgrootte is 20 MB.
Notitie
De Realtime-API maakt gebruik van hetzelfde onderliggende GPT-4o-audiomodel als de voltooiings-API, maar is geoptimaliseerd voor realtime audio-interacties met lage latentie.
API-ondersteuning
Ondersteuning voor audiovoltooiingen is voor het eerst toegevoegd in api-versie 2025-01-01-preview.
Een model implementeren voor audiogeneratie
Het model implementeren gpt-4o-mini-audio-preview in de Azure AI Foundry-portal:
- Ga naar de azure OpenAI-servicepagina in de Azure AI Foundry-portal. Zorg ervoor dat u bent aangemeld met het Azure-abonnement met uw Azure OpenAI Service-resource en het geïmplementeerde
gpt-4o-mini-audio-previewmodel. - Selecteer de chatspeeltuin onder Speeltuinen in het linkerdeelvenster.
- Selecteer + Nieuwe implementatie>maken van basismodellen om het implementatievenster te openen.
- Zoek en selecteer het
gpt-4o-mini-audio-previewmodel en selecteer vervolgens Implementeren naar geselecteerde resource. - Selecteer in de implementatiewizard de
2024-12-17modelversie. - Volg de wizard om het model te implementeren.
Nu u een implementatie van het gpt-4o-mini-audio-preview model hebt, kunt u ermee werken in de chatspeeltuin van azure AI Foundry Portal of de API voor het voltooien van chats.
GPT-4o-audiogeneratie gebruiken
Voer de volgende stappen uit om te chatten met uw geïmplementeerde gpt-4o-mini-audio-preview model in de Chat-speeltuin van Azure AI Foundry Portal:
Ga naar de azure OpenAI-servicepagina in de Azure AI Foundry-portal. Zorg ervoor dat u bent aangemeld met het Azure-abonnement met uw Azure OpenAI Service-resource en het geïmplementeerde
gpt-4o-mini-audio-previewmodel.Selecteer de chatspeeltuin in het linkerdeelvenster onder Resource-speeltuin .
Selecteer het geïmplementeerde
gpt-4o-mini-audio-previewmodel in de vervolgkeuzelijst Implementatie .Begin met chatten met het model en luister naar de audioantwoorden.
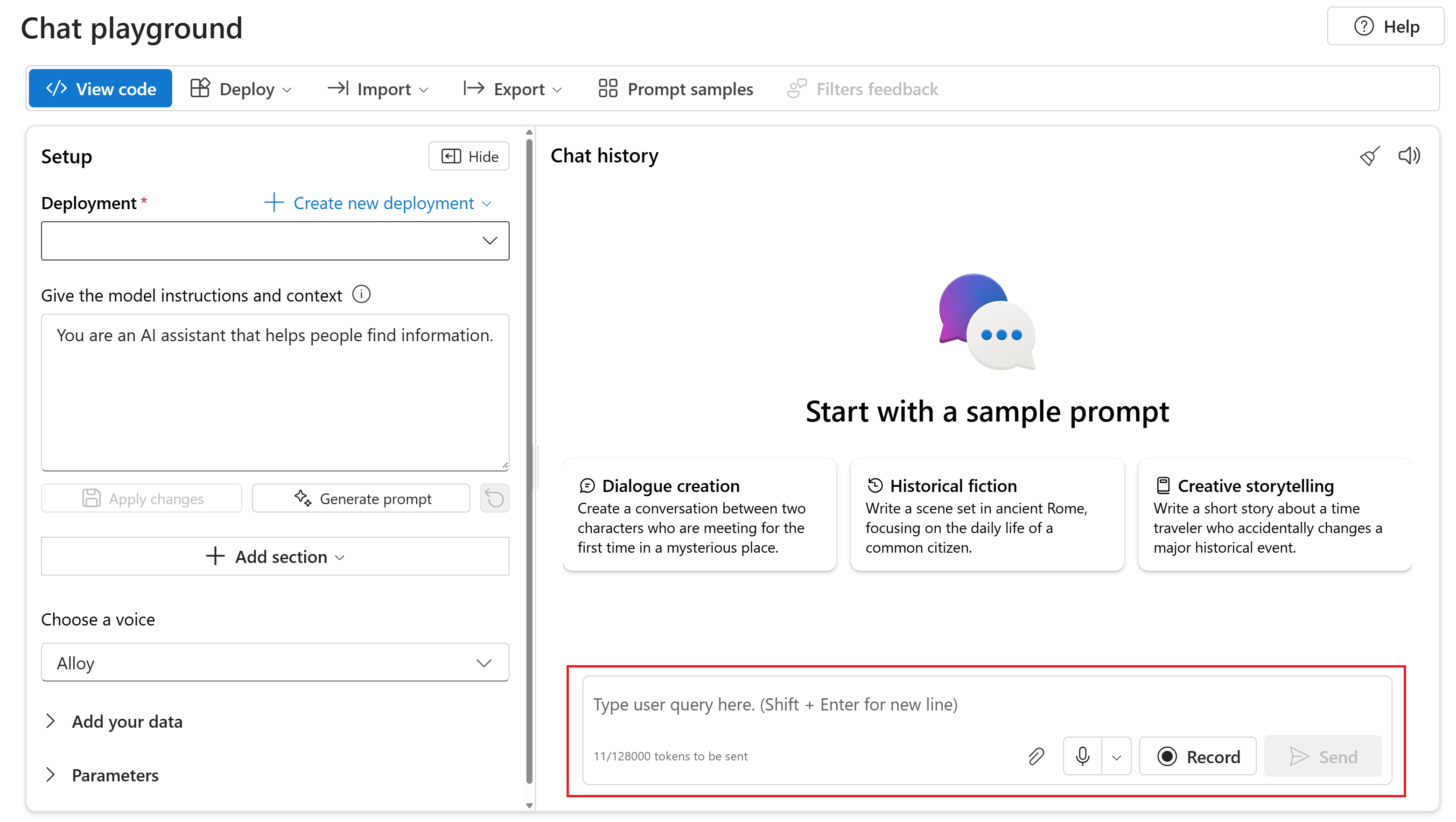
U kunt:
- Neem audioprompts op.
- Voeg audiobestanden toe aan de chat.
- Voer tekstprompts in.

Referentiedocumentatie | Bibliotheekbroncode | Pakket (npm) | Voorbeelden
De gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen introduceren de modaliteit van audio in de bestaande /chat/completions API. Het audiomodel breidt het potentieel uit voor AI-toepassingen in tekst- en spraakgebaseerde interacties en audioanalyse. Modaliteiten die worden ondersteund in gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen zijn onder andere: tekst, audio en tekst + audio.
Hier volgt een tabel met de ondersteunde modaliteiten met voorbeeldgebruiksvoorbeelden:
| Modaliteitsinvoer | Modaliteitsuitvoer | Voorbeeld van een toepassing |
|---|---|---|
| Sms verzenden | Tekst en audio | Tekst naar spraak, audioboekgeneratie |
| Audio | Tekst en audio | Audiotranscriptie, audioboekgeneratie |
| Audio | Sms verzenden | Audiotranscriptie |
| Tekst en audio | Tekst en audio | Audioboekgeneratie |
| Tekst en audio | Sms verzenden | Audiotranscriptie |
Met behulp van mogelijkheden voor het genereren van audio kunt u dynamischere en interactieve AI-toepassingen bereiken. Met modellen die audio-invoer en -uitvoer ondersteunen, kunt u gesproken audioantwoorden genereren om vragen te stellen en audio-invoer te gebruiken om het model te vragen.
Ondersteunde modellen
Momenteel alleen gpt-4o-audio-preview en gpt-4o-mini-audio-preview versie: 2024-12-17 ondersteunt het genereren van audio.
Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
Momenteel worden de volgende stemmen ondersteund voor audio: Legering, Echo en Shimmer.
De maximale bestandsgrootte is 20 MB.
Notitie
De Realtime-API maakt gebruik van hetzelfde onderliggende GPT-4o-audiomodel als de voltooiings-API, maar is geoptimaliseerd voor realtime audio-interacties met lage latentie.
API-ondersteuning
Ondersteuning voor audiovoltooiingen is voor het eerst toegevoegd in api-versie 2025-01-01-preview.
Vereisten
- Een Azure-abonnement - Een gratis abonnement maken
- Node.js LTS- of ESM-ondersteuning.
- Een Azure OpenAI-resource die is gemaakt in een van de ondersteunde regio's. Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
- Vervolgens moet u een
gpt-4o-mini-audio-previewmodel implementeren met uw Azure OpenAI-resource. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
Vereisten voor Microsoft Entra-id
Voor de aanbevolen sleutelloze verificatie met Microsoft Entra-id moet u het volgende doen:
- Installeer de Azure CLI die wordt gebruikt voor sleutelloze verificatie met Microsoft Entra-id.
- Wijs de
Cognitive Services Userrol toe aan uw gebruikersaccount. U kunt rollen toewijzen in Azure Portal onder Toegangsbeheer (IAM)>Roltoewijzing toevoegen.
Instellingen
Maak een nieuwe map
audio-completions-quickstartdie de toepassing bevat en open Visual Studio Code in die map met de volgende opdracht:mkdir audio-completions-quickstart && code audio-completions-quickstartMaak de
package.jsonopdracht met de volgende opdracht:npm init -yWerk de
package.jsonapp bij naar ECMAScript met de volgende opdracht:npm pkg set type=moduleInstalleer de OpenAI-clientbibliotheek voor JavaScript met:
npm install openaiVoor de aanbevolen sleutelloze verificatie met Microsoft Entra ID installeert u het
@azure/identitypakket met:npm install @azure/identity
Resourcegegevens ophalen
U moet de volgende informatie ophalen om uw toepassing te verifiëren met uw Azure OpenAI-resource:
| Naam van de variabele | Weergegeven als |
|---|---|
AZURE_OPENAI_ENDPOINT |
Deze waarde vindt u in de sectie Sleutels en eindpunt bij het controleren van uw resource vanuit Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Deze waarde komt overeen met de aangepaste naam die u hebt gekozen voor uw implementatie toen u een model hebt geïmplementeerd. Deze waarde vindt u onder Resource Management>Model Deployments in Azure Portal. |
OPENAI_API_VERSION |
Meer informatie over API-versies. |
Meer informatie over sleutelloze verificatie en het instellen van omgevingsvariabelen.
Let op
Als u de aanbevolen sleutelloze verificatie met de SDK wilt gebruiken, moet u ervoor zorgen dat de AZURE_OPENAI_API_KEY omgevingsvariabele niet is ingesteld.
Audio genereren op basis van tekstinvoer
Maak het
to-audio.jsbestand met de volgende code:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Meld u aan bij Azure met de volgende opdracht:
az loginVoer het JavaScript-bestand uit.
node to-audio.js
Wacht even om het antwoord te krijgen.
Uitvoer voor het genereren van audio vanuit tekstinvoer
Het script genereert een audiobestand met de naam dog.wav in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt: 'Is een gouden retriever een goede gezinshond?'
Audio en tekst genereren op basis van audio-invoer
Maak het
from-audio.jsbestand met de volgende code:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Meld u aan bij Azure met de volgende opdracht:
az loginVoer het JavaScript-bestand uit.
node from-audio.js
Wacht even om het antwoord te krijgen.
Uitvoer voor audio- en tekstgeneratie van audio-invoer
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Er wordt ook een audiobestand met de naam analysis.wav gegenereerd in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt.
Audio genereren en multi-turn chat-voltooiingen gebruiken
Maak het
multi-turn.jsbestand met de volgende code:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Meld u aan bij Azure met de volgende opdracht:
az loginVoer het JavaScript-bestand uit.
node multi-turn.js
Wacht even om het antwoord te krijgen.
Uitvoer voor voltooiingen van chats met meerdere draaiingen
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Vervolgens is er een multi-turn chatvoltooiing om kort de gesproken audio-invoer samen te vatten.
Broncode van de bibliotheek | Pakket | Voorbeelden
De gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen introduceren de modaliteit van audio in de bestaande /chat/completions API. Het audiomodel breidt het potentieel uit voor AI-toepassingen in tekst- en spraakgebaseerde interacties en audioanalyse. Modaliteiten die worden ondersteund in gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen zijn onder andere: tekst, audio en tekst + audio.
Hier volgt een tabel met de ondersteunde modaliteiten met voorbeeldgebruiksvoorbeelden:
| Modaliteitsinvoer | Modaliteitsuitvoer | Voorbeeld van een toepassing |
|---|---|---|
| Sms verzenden | Tekst en audio | Tekst naar spraak, audioboekgeneratie |
| Audio | Tekst en audio | Audiotranscriptie, audioboekgeneratie |
| Audio | Sms verzenden | Audiotranscriptie |
| Tekst en audio | Tekst en audio | Audioboekgeneratie |
| Tekst en audio | Sms verzenden | Audiotranscriptie |
Met behulp van mogelijkheden voor het genereren van audio kunt u dynamischere en interactieve AI-toepassingen bereiken. Met modellen die audio-invoer en -uitvoer ondersteunen, kunt u gesproken audioantwoorden genereren om vragen te stellen en audio-invoer te gebruiken om het model te vragen.
Ondersteunde modellen
Momenteel alleen gpt-4o-audio-preview en gpt-4o-mini-audio-preview versie: 2024-12-17 ondersteunt het genereren van audio.
Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
Momenteel worden de volgende stemmen ondersteund voor audio: Legering, Echo en Shimmer.
De maximale bestandsgrootte is 20 MB.
Notitie
De Realtime-API maakt gebruik van hetzelfde onderliggende GPT-4o-audiomodel als de voltooiings-API, maar is geoptimaliseerd voor realtime audio-interacties met lage latentie.
API-ondersteuning
Ondersteuning voor audiovoltooiingen is voor het eerst toegevoegd in api-versie 2025-01-01-preview.
Gebruik deze handleiding om aan de slag te gaan met het genereren van audio met de Azure OpenAI SDK voor Python.
Vereisten
- Een Azure-abonnement. Maak gratis een account.
- Python 3.8 of nieuwere versie. U wordt aangeraden Python 3.10 of hoger te gebruiken, maar python 3.8 is vereist. Als u geen geschikte versie van Python hebt geïnstalleerd, kunt u de instructies in de VS Code Python-zelfstudie volgen voor de eenvoudigste manier om Python op uw besturingssysteem te installeren.
- Een Azure OpenAI-resource die is gemaakt in een van de ondersteunde regio's. Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
- Vervolgens moet u een
gpt-4o-mini-audio-previewmodel implementeren met uw Azure OpenAI-resource. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
Vereisten voor Microsoft Entra-id
Voor de aanbevolen sleutelloze verificatie met Microsoft Entra-id moet u het volgende doen:
- Installeer de Azure CLI die wordt gebruikt voor sleutelloze verificatie met Microsoft Entra-id.
- Wijs de
Cognitive Services Userrol toe aan uw gebruikersaccount. U kunt rollen toewijzen in Azure Portal onder Toegangsbeheer (IAM)>Roltoewijzing toevoegen.
Instellingen
Maak een nieuwe map
audio-completions-quickstartdie de toepassing bevat en open Visual Studio Code in die map met de volgende opdracht:mkdir audio-completions-quickstart && code audio-completions-quickstartMaak een virtuele omgeving. Als Python 3.10 of hoger al is geïnstalleerd, kunt u een virtuele omgeving maken met behulp van de volgende opdrachten:
Als u de Python-omgeving activeert, betekent dit dat wanneer u de opdrachtregel uitvoert
pythonofpipvanaf de opdrachtregel de Python-interpreter gebruikt die zich in de.venvmap van uw toepassing bevindt. U kunt dedeactivateopdracht gebruiken om de virtuele Python-omgeving af te sluiten en deze later opnieuw te activeren wanneer dat nodig is.Tip
U wordt aangeraden een nieuwe Python-omgeving te maken en te activeren om de pakketten te installeren die u nodig hebt voor deze zelfstudie. Installeer geen pakketten in uw globale Python-installatie. U moet altijd een virtuele of conda-omgeving gebruiken bij het installeren van Python-pakketten, anders kunt u uw globale installatie van Python verbreken.
Installeer de OpenAI-clientbibliotheek voor Python met:
pip install openaiVoor de aanbevolen sleutelloze verificatie met Microsoft Entra ID installeert u het
azure-identitypakket met:pip install azure-identity
Resourcegegevens ophalen
U moet de volgende informatie ophalen om uw toepassing te verifiëren met uw Azure OpenAI-resource:
| Naam van de variabele | Weergegeven als |
|---|---|
AZURE_OPENAI_ENDPOINT |
Deze waarde vindt u in de sectie Sleutels en eindpunt bij het controleren van uw resource vanuit Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Deze waarde komt overeen met de aangepaste naam die u hebt gekozen voor uw implementatie toen u een model hebt geïmplementeerd. Deze waarde vindt u onder Resource Management>Model Deployments in Azure Portal. |
OPENAI_API_VERSION |
Meer informatie over API-versies. |
Meer informatie over sleutelloze verificatie en het instellen van omgevingsvariabelen.
Audio genereren op basis van tekstinvoer
Maak het
to-audio.pybestand met de volgende code:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Voer het Python-bestand uit.
python to-audio.py
Wacht even om het antwoord te krijgen.
Uitvoer voor het genereren van audio vanuit tekstinvoer
Het script genereert een audiobestand met de naam dog.wav in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt: 'Is een gouden retriever een goede gezinshond?'
Audio en tekst genereren op basis van audio-invoer
Maak het
from-audio.pybestand met de volgende code:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Voer het Python-bestand uit.
python from-audio.py
Wacht even om het antwoord te krijgen.
Uitvoer voor audio- en tekstgeneratie van audio-invoer
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Er wordt ook een audiobestand met de naam analysis.wav gegenereerd in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt.
Audio genereren en multi-turn chat-voltooiingen gebruiken
Maak het
multi-turn.pybestand met de volgende code:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Voer het Python-bestand uit.
python multi-turn.py
Wacht even om het antwoord te krijgen.
Uitvoer voor voltooiingen van chats met meerdere draaiingen
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Vervolgens is er een multi-turn chatvoltooiing om kort de gesproken audio-invoer samen te vatten.
De gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen introduceren de modaliteit van audio in de bestaande /chat/completions API. Het audiomodel breidt het potentieel uit voor AI-toepassingen in tekst- en spraakgebaseerde interacties en audioanalyse. Modaliteiten die worden ondersteund in gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen zijn onder andere: tekst, audio en tekst + audio.
Hier volgt een tabel met de ondersteunde modaliteiten met voorbeeldgebruiksvoorbeelden:
| Modaliteitsinvoer | Modaliteitsuitvoer | Voorbeeld van een toepassing |
|---|---|---|
| Sms verzenden | Tekst en audio | Tekst naar spraak, audioboekgeneratie |
| Audio | Tekst en audio | Audiotranscriptie, audioboekgeneratie |
| Audio | Sms verzenden | Audiotranscriptie |
| Tekst en audio | Tekst en audio | Audioboekgeneratie |
| Tekst en audio | Sms verzenden | Audiotranscriptie |
Met behulp van mogelijkheden voor het genereren van audio kunt u dynamischere en interactieve AI-toepassingen bereiken. Met modellen die audio-invoer en -uitvoer ondersteunen, kunt u gesproken audioantwoorden genereren om vragen te stellen en audio-invoer te gebruiken om het model te vragen.
Ondersteunde modellen
Momenteel alleen gpt-4o-audio-preview en gpt-4o-mini-audio-preview versie: 2024-12-17 ondersteunt het genereren van audio.
Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
Momenteel worden de volgende stemmen ondersteund voor audio: Legering, Echo en Shimmer.
De maximale bestandsgrootte is 20 MB.
Notitie
De Realtime-API maakt gebruik van hetzelfde onderliggende GPT-4o-audiomodel als de voltooiings-API, maar is geoptimaliseerd voor realtime audio-interacties met lage latentie.
API-ondersteuning
Ondersteuning voor audiovoltooiingen is voor het eerst toegevoegd in api-versie 2025-01-01-preview.
Vereisten
- Een Azure-abonnement. Maak gratis een account.
- Python 3.8 of nieuwere versie. U wordt aangeraden Python 3.10 of hoger te gebruiken, maar python 3.8 is vereist. Als u geen geschikte versie van Python hebt geïnstalleerd, kunt u de instructies in de VS Code Python-zelfstudie volgen voor de eenvoudigste manier om Python op uw besturingssysteem te installeren.
- Een Azure OpenAI-resource die is gemaakt in een van de ondersteunde regio's. Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
- Vervolgens moet u een
gpt-4o-mini-audio-previewmodel implementeren met uw Azure OpenAI-resource. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
Vereisten voor Microsoft Entra-id
Voor de aanbevolen sleutelloze verificatie met Microsoft Entra-id moet u het volgende doen:
- Installeer de Azure CLI die wordt gebruikt voor sleutelloze verificatie met Microsoft Entra-id.
- Wijs de
Cognitive Services Userrol toe aan uw gebruikersaccount. U kunt rollen toewijzen in Azure Portal onder Toegangsbeheer (IAM)>Roltoewijzing toevoegen.
Instellingen
Maak een nieuwe map
audio-completions-quickstartdie de toepassing bevat en open Visual Studio Code in die map met de volgende opdracht:mkdir audio-completions-quickstart && code audio-completions-quickstartMaak een virtuele omgeving. Als Python 3.10 of hoger al is geïnstalleerd, kunt u een virtuele omgeving maken met behulp van de volgende opdrachten:
Als u de Python-omgeving activeert, betekent dit dat wanneer u de opdrachtregel uitvoert
pythonofpipvanaf de opdrachtregel de Python-interpreter gebruikt die zich in de.venvmap van uw toepassing bevindt. U kunt dedeactivateopdracht gebruiken om de virtuele Python-omgeving af te sluiten en deze later opnieuw te activeren wanneer dat nodig is.Tip
U wordt aangeraden een nieuwe Python-omgeving te maken en te activeren om de pakketten te installeren die u nodig hebt voor deze zelfstudie. Installeer geen pakketten in uw globale Python-installatie. U moet altijd een virtuele of conda-omgeving gebruiken bij het installeren van Python-pakketten, anders kunt u uw globale installatie van Python verbreken.
Installeer de OpenAI-clientbibliotheek voor Python met:
pip install openaiVoor de aanbevolen sleutelloze verificatie met Microsoft Entra ID installeert u het
azure-identitypakket met:pip install azure-identity
Resourcegegevens ophalen
U moet de volgende informatie ophalen om uw toepassing te verifiëren met uw Azure OpenAI-resource:
| Naam van de variabele | Weergegeven als |
|---|---|
AZURE_OPENAI_ENDPOINT |
Deze waarde vindt u in de sectie Sleutels en eindpunt bij het controleren van uw resource vanuit Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Deze waarde komt overeen met de aangepaste naam die u hebt gekozen voor uw implementatie toen u een model hebt geïmplementeerd. Deze waarde vindt u onder Resource Management>Model Deployments in Azure Portal. |
OPENAI_API_VERSION |
Meer informatie over API-versies. |
Meer informatie over sleutelloze verificatie en het instellen van omgevingsvariabelen.
Audio genereren op basis van tekstinvoer
Maak het
to-audio.pybestand met de volgende code:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Voer het Python-bestand uit.
python to-audio.py
Wacht even om het antwoord te krijgen.
Uitvoer voor het genereren van audio vanuit tekstinvoer
Het script genereert een audiobestand met de naam dog.wav in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt: 'Is een gouden retriever een goede gezinshond?'
Audio en tekst genereren op basis van audio-invoer
Maak het
from-audio.pybestand met de volgende code:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Voer het Python-bestand uit.
python from-audio.py
Wacht even om het antwoord te krijgen.
Uitvoer voor audio- en tekstgeneratie van audio-invoer
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Er wordt ook een audiobestand met de naam analysis.wav gegenereerd in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt.
Audio genereren en multi-turn chat-voltooiingen gebruiken
Maak het
multi-turn.pybestand met de volgende code:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-mini-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Voer het Python-bestand uit.
python multi-turn.py
Wacht even om het antwoord te krijgen.
Uitvoer voor voltooiingen van chats met meerdere draaiingen
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Vervolgens is er een multi-turn chatvoltooiing om kort de gesproken audio-invoer samen te vatten.
Referentiedocumentatie | Bibliotheekbroncode | Pakket (npm) | Voorbeelden
De gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen introduceren de modaliteit van audio in de bestaande /chat/completions API. Het audiomodel breidt het potentieel uit voor AI-toepassingen in tekst- en spraakgebaseerde interacties en audioanalyse. Modaliteiten die worden ondersteund in gpt-4o-audio-preview en gpt-4o-mini-audio-preview modellen zijn onder andere: tekst, audio en tekst + audio.
Hier volgt een tabel met de ondersteunde modaliteiten met voorbeeldgebruiksvoorbeelden:
| Modaliteitsinvoer | Modaliteitsuitvoer | Voorbeeld van een toepassing |
|---|---|---|
| Sms verzenden | Tekst en audio | Tekst naar spraak, audioboekgeneratie |
| Audio | Tekst en audio | Audiotranscriptie, audioboekgeneratie |
| Audio | Sms verzenden | Audiotranscriptie |
| Tekst en audio | Tekst en audio | Audioboekgeneratie |
| Tekst en audio | Sms verzenden | Audiotranscriptie |
Met behulp van mogelijkheden voor het genereren van audio kunt u dynamischere en interactieve AI-toepassingen bereiken. Met modellen die audio-invoer en -uitvoer ondersteunen, kunt u gesproken audioantwoorden genereren om vragen te stellen en audio-invoer te gebruiken om het model te vragen.
Ondersteunde modellen
Momenteel alleen gpt-4o-audio-preview en gpt-4o-mini-audio-preview versie: 2024-12-17 ondersteunt het genereren van audio.
Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
Momenteel worden de volgende stemmen ondersteund voor audio: Legering, Echo en Shimmer.
De maximale bestandsgrootte is 20 MB.
Notitie
De Realtime-API maakt gebruik van hetzelfde onderliggende GPT-4o-audiomodel als de voltooiings-API, maar is geoptimaliseerd voor realtime audio-interacties met lage latentie.
API-ondersteuning
Ondersteuning voor audiovoltooiingen is voor het eerst toegevoegd in api-versie 2025-01-01-preview.
Vereisten
- Een Azure-abonnement - Een gratis abonnement maken
- Node.js LTS- of ESM-ondersteuning.
- TypeScript is wereldwijd geïnstalleerd.
- Een Azure OpenAI-resource die is gemaakt in een van de ondersteunde regio's. Zie de documentatie over modellen en versies voor meer informatie over beschikbaarheid van regio's.
- Vervolgens moet u een
gpt-4o-mini-audio-previewmodel implementeren met uw Azure OpenAI-resource. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
Vereisten voor Microsoft Entra-id
Voor de aanbevolen sleutelloze verificatie met Microsoft Entra-id moet u het volgende doen:
- Installeer de Azure CLI die wordt gebruikt voor sleutelloze verificatie met Microsoft Entra-id.
- Wijs de
Cognitive Services Userrol toe aan uw gebruikersaccount. U kunt rollen toewijzen in Azure Portal onder Toegangsbeheer (IAM)>Roltoewijzing toevoegen.
Instellingen
Maak een nieuwe map
audio-completions-quickstartdie de toepassing bevat en open Visual Studio Code in die map met de volgende opdracht:mkdir audio-completions-quickstart && code audio-completions-quickstartMaak de
package.jsonopdracht met de volgende opdracht:npm init -yWerk de
package.jsonapp bij naar ECMAScript met de volgende opdracht:npm pkg set type=moduleInstalleer de OpenAI-clientbibliotheek voor JavaScript met:
npm install openaiVoor de aanbevolen sleutelloze verificatie met Microsoft Entra ID installeert u het
@azure/identitypakket met:npm install @azure/identity
Resourcegegevens ophalen
U moet de volgende informatie ophalen om uw toepassing te verifiëren met uw Azure OpenAI-resource:
| Naam van de variabele | Weergegeven als |
|---|---|
AZURE_OPENAI_ENDPOINT |
Deze waarde vindt u in de sectie Sleutels en eindpunt bij het controleren van uw resource vanuit Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Deze waarde komt overeen met de aangepaste naam die u hebt gekozen voor uw implementatie toen u een model hebt geïmplementeerd. Deze waarde vindt u onder Resource Management>Model Deployments in Azure Portal. |
OPENAI_API_VERSION |
Meer informatie over API-versies. |
Meer informatie over sleutelloze verificatie en het instellen van omgevingsvariabelen.
Let op
Als u de aanbevolen sleutelloze verificatie met de SDK wilt gebruiken, moet u ervoor zorgen dat de AZURE_OPENAI_API_KEY omgevingsvariabele niet is ingesteld.
Audio genereren op basis van tekstinvoer
Maak het
to-audio.tsbestand met de volgende code:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Maak het
tsconfig.jsonbestand om de TypeScript-code te transpileren en kopieer de volgende code voor ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile van TypeScript naar JavaScript.
tscMeld u aan bij Azure met de volgende opdracht:
az loginVoer de code uit met de volgende opdracht:
node to-audio.js
Wacht even om het antwoord te krijgen.
Uitvoer voor het genereren van audio vanuit tekstinvoer
Het script genereert een audiobestand met de naam dog.wav in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt: 'Is een gouden retriever een goede gezinshond?'
Audio en tekst genereren op basis van audio-invoer
Maak het
from-audio.tsbestand met de volgende code:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Maak het
tsconfig.jsonbestand om de TypeScript-code te transpileren en kopieer de volgende code voor ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile van TypeScript naar JavaScript.
tscMeld u aan bij Azure met de volgende opdracht:
az loginVoer de code uit met de volgende opdracht:
node from-audio.js
Wacht even om het antwoord te krijgen.
Uitvoer voor audio- en tekstgeneratie van audio-invoer
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Er wordt ook een audiobestand met de naam analysis.wav gegenereerd in dezelfde map als het script. Het audiobestand bevat het gesproken antwoord op de prompt.
Audio genereren en multi-turn chat-voltooiingen gebruiken
Maak het
multi-turn.tsbestand met de volgende code:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Maak het
tsconfig.jsonbestand om de TypeScript-code te transpileren en kopieer de volgende code voor ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile van TypeScript naar JavaScript.
tscMeld u aan bij Azure met de volgende opdracht:
az loginVoer de code uit met de volgende opdracht:
node multi-turn.js
Wacht even om het antwoord te krijgen.
Uitvoer voor voltooiingen van chats met meerdere draaiingen
Het script genereert een transcriptie van de samenvatting van de gesproken audio-invoer. Vervolgens is er een multi-turn chatvoltooiing om kort de gesproken audio-invoer samen te vatten.
Resources opschonen
Als u een Azure OpenAI-resource wilt opschonen en verwijderen, kunt u de resource verwijderen. Voordat u de resource verwijdert, moet u eerst geïmplementeerde modellen verwijderen.
Gerelateerde inhoud
- Meer informatie over Azure OpenAI-implementatietypen.
- Meer informatie over Azure OpenAI-quota en -limieten.