Gegevens kopiëren van Google BigQuery met behulp van Azure Data Factory of Synapse Analytics (verouderd)
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt in Azure Data Factory- en Synapse Analytics-pijplijnen om gegevens uit Google BigQuery te kopiëren. Het is gebaseerd op het artikel Overzicht van kopieeractiviteit met een algemeen overzicht van de kopieeractiviteit.
Belangrijk
De Google BigQuery V2-connector biedt verbeterde systeemeigen Ondersteuning voor Google BigQuery. Als u de Google BigQuery V1-connector in uw oplossing gebruikt, moet u uw Google BigQuery-connector upgraden omdat V1 zich in de fase Einde van de ondersteuning bevindt. Raadpleeg deze sectie voor meer informatie over het verschil tussen V2 en V1.
Ondersteunde mogelijkheden
Deze Google BigQuery-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/-) | (1) (2) |
| Activiteit Lookup | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Zie de tabel Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen of sinks door de kopieeractiviteit.
De service biedt een ingebouwd stuurprogramma om connectiviteit mogelijk te maken. Daarom hoeft u geen stuurprogramma handmatig te installeren om deze connector te gebruiken.
De connector ondersteunt de Windows-versies in dit artikel.
Notitie
Deze Google BigQuery-connector is gebouwd op basis van de BigQuery-API's. Houd er rekening mee dat BigQuery de maximale snelheid van binnenkomende aanvragen beperkt en de juiste quota afdwingt op basis van een project, raadpleegt u Quota & Limieten - API-aanvragen. Zorg ervoor dat u niet te veel gelijktijdige aanvragen activeert voor het account.
Vereisten
Als u deze connector wilt gebruiken, hebt u de volgende minimale machtigingen van Google BigQuery nodig:
- bigquery.connections.*
- bigquery.datasets.*
- bigquery.jobs.*
- bigquery.readsessions.*
- bigquery.routines.*
- bigquery.tables.*
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde service maken voor Google BigQuery met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken voor Google BigQuery in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Google en selecteer de Google BigQuery-connector.
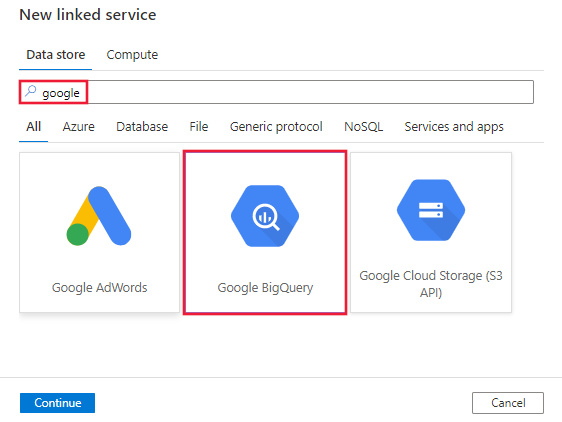
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
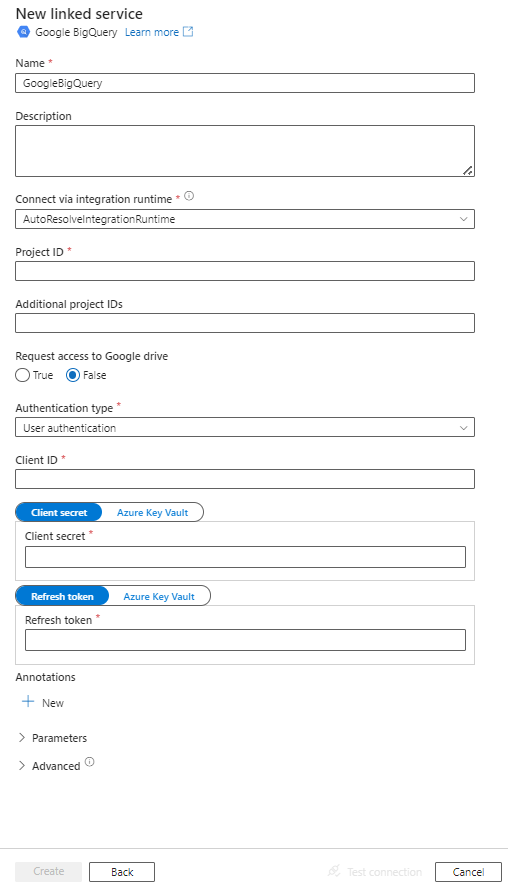
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt om entiteiten te definiëren die specifiek zijn voor de Google BigQuery-connector.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor de gekoppelde Google BigQuery-service.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op GoogleBigQuery. | Ja |
| project | De project-id van het standaard BigQuery-project om een query op uit te voeren. | Ja |
| additionalProjects | Een door komma's gescheiden lijst met project-id's van openbare BigQuery-projecten voor toegang. | Nee |
| requestGoogleDriveScope | Of u toegang tot Google Drive wilt aanvragen. Het toestaan van Google Drive-toegang maakt ondersteuning mogelijk voor federatieve tabellen die BigQuery-gegevens combineren met gegevens uit Google Drive. De standaardwaarde is onwaar. | Nee |
| authenticationType | Het OAuth 2.0-verificatiemechanisme dat wordt gebruikt voor verificatie. ServiceAuthentication kan alleen worden gebruikt voor zelf-hostende Integration Runtime. Toegestane waarden zijn UserAuthentication en ServiceAuthentication. Raadpleeg secties onder deze tabel voor meer eigenschappen en JSON-voorbeelden voor respectievelijk deze verificatietypen. |
Ja |
Gebruikersverificatie gebruiken
Stel de eigenschap authenticationType in op UserAuthentication en geef de volgende eigenschappen op, samen met algemene eigenschappen die in de vorige sectie worden beschreven:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| clientId | Id van de toepassing die wordt gebruikt om het vernieuwingstoken te genereren. | Ja |
| clientSecret | Geheim van de toepassing die wordt gebruikt om het vernieuwingstoken te genereren. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| refreshToken | Het vernieuwingstoken dat is verkregen van Google, heeft gebruikt om toegang tot BigQuery te autoriseren. Meer informatie over het verkrijgen van OAuth 2.0-toegangstokens en deze communityblog. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
Het minimale bereik dat is vereist voor het verkrijgen van een OAuth 2.0-vernieuwingstoken is https://www.googleapis.com/auth/bigquery.readonly. Als u van plan bent om een query uit te voeren die grote resultaten kan retourneren, is mogelijk een ander bereik vereist. Raadpleeg dit artikel voor meer informatie.
Voorbeeld:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQuery",
"typeProperties": {
"project" : "<project ID>",
"additionalProjects" : "<additional project IDs>",
"requestGoogleDriveScope" : true,
"authenticationType" : "UserAuthentication",
"clientId": "<id of the application used to generate the refresh token>",
"clientSecret": {
"type": "SecureString",
"value":"<secret of the application used to generate the refresh token>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Serviceverificatie gebruiken
Stel de eigenschap authenticationType in op ServiceAuthentication en geef de volgende eigenschappen op, samen met algemene eigenschappen die in de vorige sectie worden beschreven. Dit verificatietype kan alleen worden gebruikt voor zelf-hostende Integration Runtime.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| e-mailadres | De e-mailadres-id van het serviceaccount dat wordt gebruikt voor ServiceAuthentication. Deze kan alleen worden gebruikt voor zelf-hostende Integration Runtime. | Nee |
| keyFilePath | Het volledige pad naar het .json sleutelbestand dat wordt gebruikt om het e-mailadres van het serviceaccount te verifiëren. |
Ja |
| trustedCertPath | Het volledige pad van het PEM-bestand dat vertrouwde CA-certificaten bevat die worden gebruikt om de server te verifiëren wanneer u verbinding maakt via TLS. Deze eigenschap kan alleen worden ingesteld wanneer u TLS gebruikt voor zelf-hostende Integration Runtime. De standaardwaarde is het cacerts.pem-bestand dat is geïnstalleerd met de Integration Runtime. | Nee |
| useSystemTrustStore | Hiermee geeft u op of u een CA-certificaat uit het systeemvertrouwensarchief of een opgegeven PEM-bestand wilt gebruiken. De standaardwaarde is onwaar. | Nr. |
Notitie
De connector ondersteunt geen P12-sleutelbestanden meer. Als u gebruikmaakt van serviceaccounts, wordt u aangeraden in plaats daarvan JSON-sleutelbestanden te gebruiken. De P12CustomPwd-eigenschap die wordt gebruikt voor het ondersteunen van het P12-sleutelbestand, is ook afgeschaft. Zie dit artikel voor meer informatie.
Voorbeeld:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQuery",
"typeProperties": {
"project" : "<project id>",
"requestGoogleDriveScope" : true,
"authenticationType" : "ServiceAuthentication",
"email": "<email>",
"keyFilePath": "<.json key path on the IR machine>"
},
"connectVia": {
"referenceName": "<name of Self-hosted Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets . Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Google BigQuery-gegevensset.
Als u gegevens van Google BigQuery wilt kopiëren, stelt u de typeeigenschap van de gegevensset in op GoogleBigQueryObject. De volgende eigenschappen worden ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet zijn ingesteld op: GoogleBigQueryObject | Ja |
| gegevensset | Naam van de Google BigQuery-gegevensset. | Nee (als 'query' in de activiteitsbron is opgegeven) |
| table | Naam van de tabel. | Nee (als 'query' in de activiteitsbron is opgegeven) |
| tableName | Naam van de tabel. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Voor nieuwe workload gebruikt dataset u en table. |
Nee (als 'query' in de activiteitsbron is opgegeven) |
Voorbeeld
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<GoogleBigQuery linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door het brontype Google BigQuery.
GoogleBigQuerySource als brontype
Als u gegevens van Google BigQuery wilt kopiëren, stelt u het brontype in de kopieeractiviteit in op GoogleBigQuerySource. De volgende eigenschappen worden ondersteund in de sectie bron van de kopieeractiviteit.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op GoogleBigQuerySource. | Ja |
| query | Gebruik de aangepaste SQL-query om gegevens te lezen. Een voorbeeld is "SELECT * FROM MyTable". |
Nee (als 'tableName' in de gegevensset is opgegeven) |
Voorbeeld:
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<GoogleBigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQuerySource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.