Forklaringstyper i Microsoft Syntex
Gjelder for: ✓ Ustrukturert dokumentbehandling
Forklaringer brukes til å definere informasjonen du vil merke og trekke ut i ustrukturerte dokumentbehandlingsmodeller i Microsoft Syntex. Når du oppretter en forklaring, må du velge en forklaringstype. Denne artikkelen hjelper deg med å forstå de ulike forklaringstypene og hvordan de brukes.
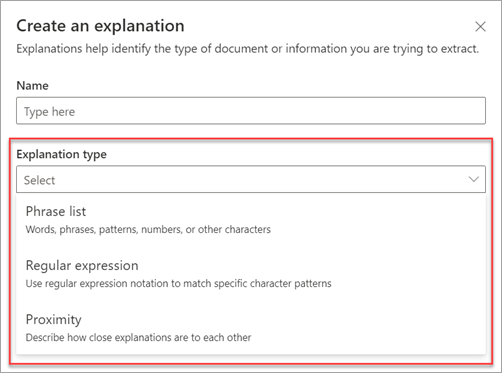
Disse forklaringstypene er tilgjengelige:
Uttrykksliste: Liste over ord, uttrykk, tall eller andre tegn du kan bruke i dokumentet eller informasjonen du trekker ut. Tekststrengen som henviser til lege , er for eksempel i alle dokumenter for medisinsk henvisning som du identifiserer. Eller telefonnummeret til den henvisende legen fra alle dokumenter for medisinsk henvisning som du identifiserer.
Vanlig uttrykk: Bruker en mønstersamsvars-notasjon til å finne bestemte tegnmønstre. Du kan for eksempel bruke et vanlig uttrykk til å finne alle forekomster av et mønster for e-postadresser i et sett med dokumenter.
Nærhet: Beskriver hvor nære forklaringer er for hverandre. En liste over gatenummeruttrykk går for eksempel rett foran listen over gatenavnuttrykk , uten tokener i mellom (du lærer om tokener senere i denne artikkelen). Hvis du bruker nærhetstypen, må du ha minst to forklaringer i modellen, ellers deaktiveres alternativet.
Uttrykksliste
En forklaringstype for uttrykksliste brukes vanligvis til å identifisere og klassifisere et dokument gjennom modellen. Som beskrevet i eksempelet på den refererende legeetiketten , er det en streng med ord, uttrykk, tall eller tegn som konsekvent er i dokumentene du identifiserer.
Selv om det ikke er et krav, kan du oppnå bedre suksess med forklaringen hvis uttrykket du registrerer, er plassert på en konsekvent plassering i dokumentet. Den refererende legeetiketten kan for eksempel være konsekvent plassert i det første avsnittet i dokumentet. Du kan også bruke innstillingen Konfigurer hvor uttrykk forekommer i den avanserte innstillingen for dokumentet til å velge bestemte områder der uttrykket er plassert, spesielt hvis det er en sjanse for at uttrykket kan oppstå på flere steder i dokumentet.
Hvis skille mellom store og små bokstaver er et krav for å identifisere etiketten, kan du bruke uttrykkslistetypen til å angi den i forklaringen ved å merke av for Bare nøyaktig stor forbokstav .

En uttrykkstype er spesielt nyttig når du oppretter en forklaring som identifiserer og trekker ut informasjon i ulike formater, for eksempel datoer, telefonnumre og kredittkortnumre. En dato kan for eksempel vises i mange forskjellige formater (01.01.2020, 1-1-2020, 01.01.20, 01.01.2020 eller 1. januar 2020). Når du definerer en uttrykksliste, blir forklaringen mer effektiv ved å registrere eventuelle variasjoner i dataene du prøver å identifisere og trekke ut.
I telefonnummereksemplet trekker du ut telefonnummeret for hver henvisende lege fra alle dokumenter for medisinsk henvisning som modellen identifiserer. Når du oppretter forklaringen, skriver du inn de ulike formatene et telefonnummer kan vise i dokumentet, slik at du kan registrere mulige variasjoner.
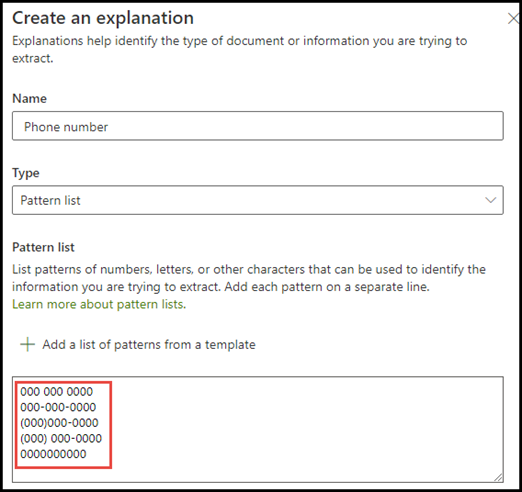
I dette eksemplet velger du et siffer fra 0 til 9 i Avanserte innstillinger for å gjenkjenne hver «0»-verdi som brukes i uttrykkslisten til å være et hvilket som helst siffer fra 0 til 9.

På samme måte, hvis du oppretter en uttrykksliste som inneholder teksttegn, merker du av for Alle bokstaver fra a-z for å gjenkjenne hvert «a»-tegn som brukes i uttrykkslisten til å være et hvilket som helst tegn fra «a» til «z».
Hvis du for eksempel oppretter en datouttrykksliste og du vil forsikre deg om at et datoformat, for eksempel 1. januar 2020, gjenkjennes, må du:
- Legg til aaa 0, 0000 og aaa 00 0000 i uttrykkslisten.
- Kontroller at alle bokstavene fra a-z også er valgt.

Hvis du har krav til stor forbokstav i uttrykkslisten, kan du merke av for Bare nøyaktig stor forbokstav . Hvis du for eksempel krever at den første bokstaven i måneden skal ha stor forbokstav, må du:
- Legg til Aaa 0, 0000 og Aaa 00 0000 i uttrykkslisten.
- Kontroller at bare nøyaktig stor forbokstav også er valgt.

Obs!
I stedet for å opprette en forklaring av en setningsliste manuelt, kan du bruke forklaringsbiblioteket til å bruke uttrykkslistemaler for en felles uttrykksliste, for eksempel dato, telefonnummer eller kredittkortnummer.
Vanlig uttrykk
Med en vanlig uttrykksforklaringstype kan du opprette mønstre som bidrar til å finne og identifisere bestemte tekststrenger i dokumenter. Du kan bruke vanlige uttrykk til raskt å analysere store mengder tekst til:
- Finn bestemte tegnmønstre.
- Valider tekst for å sikre at den samsvarer med et forhåndsdefinert mønster (for eksempel en e-postadresse).
- Trekk ut, rediger, erstatt eller slett tekstunderstrenger.
En vanlig uttrykkstype er spesielt nyttig når du oppretter en forklaring som identifiserer og trekker ut informasjon i lignende formater, for eksempel e-postadresser, bankkontonumre eller nettadresser. En e-postadresse, for eksempel megan@contoso.com, vises i et bestemt mønster ("megan" er den første delen, og "com" er den siste delen).
Det vanlige uttrykket for en e-postadresse er: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[ A-Za-z]{2,6}.
Dette uttrykket består av fem deler, i denne rekkefølgen:
En hvilken som helst mengde av følgende tegn:
a. Bokstaver fra a til å
b. Tall fra 0 til 9
c. Punktum, understrekingstegn, prosent eller tankestreking
@-symbolet
Alle mengder av de samme tegnene som den første delen av e-postadressen
Et punktum
To til seks bokstaver
Slik legger du til en vanlig uttrykksforklaringstype:
Velg Vanlig uttrykk under Forklaringstype i panelet Opprett en forklaring.
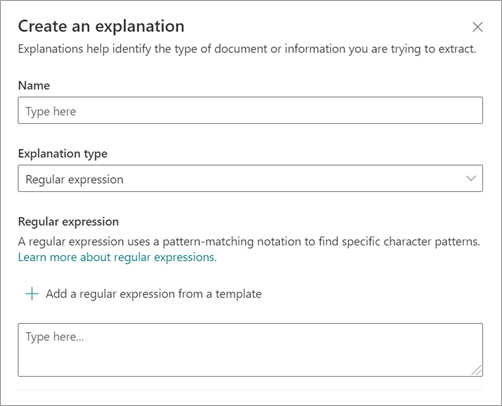
Du kan enten skrive inn et uttrykk i tekstboksen Vanlig uttrykk eller velge Legg til et vanlig uttrykk fra en mal.
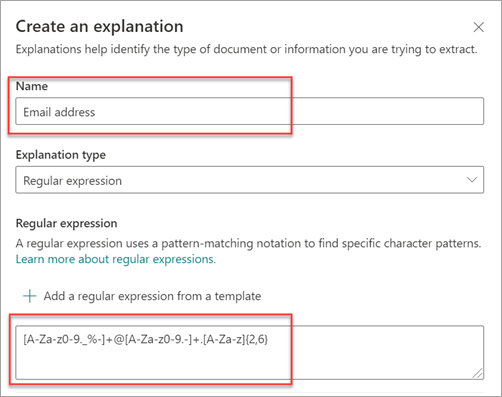
Når du legger til et vanlig uttrykk ved hjelp av en mal, legges det automatisk til navnet og det vanlige uttrykket i tekstboksen. Hvis du for eksempel velger malen E-postadresse , fylles panelet Opprett en forklaring ut.
Begrensninger
Tabellen nedenfor viser innebygde tegnalternativer som for øyeblikket ikke er tilgjengelige for bruk i vanlige uttrykksmønstre.
| Alternativ | Tilstand | Gjeldende funksjonalitet |
|---|---|---|
| Skille mellom store og små bokstaver | Støttes for øyeblikket ikke. | Alle treff som utføres, skilles ikke mellom små og store bokstaver. |
| Linjeankere | Støttes for øyeblikket ikke. | Kan ikke angi en bestemt plassering i en streng der et treff må forekomme. |
Nærhet
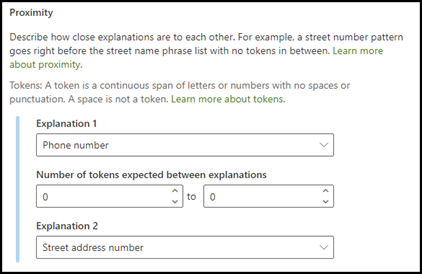
Nærhetsforklaringstypen hjelper modellen med å identifisere data ved å definere hvor nær en annen datadel er for den. I modellen sier du for eksempel at du har definert to forklaringer som merker både kundens gateadressenummer og telefonnummer.
Legg merke til at kundetelefonnumre alltid vises før gateadressenummeret.
Alex Wilburn
555-555-5555
Én Microsoft Way
Redmond, WA 98034
Bruk nærhetsforklaringen til å definere hvor langt unna telefonnummerforklaringen er for bedre å identifisere gateadressenummeret i dokumentene dine.
Obs!
Vanlige uttrykk kan for øyeblikket ikke brukes med nærhetsklaringstypen.
Hva er tokener?
Hvis du vil bruke nærhetsforklaringstypen, må du forstå hva et token er. Antall tokener er hvordan nærhetsforklaringen måler avstand fra én forklaring til en annen. Et token er et kontinuerlig spenn (ikke inkludert mellomrom eller tegnsetting) med bokstaver og tall.
Tabellen nedenfor viser eksempler på hvordan du fastslår antall tokener i et uttrykk.
| Frase | Antall tokener | Forklaring |
|---|---|---|
Dog |
1 | Et enkelt ord uten tegnsetting eller mellomrom. |
RMT33W |
1 | Et postlokatornummer. Det kan inneholde tall og bokstaver, men har ikke tegnsetting. |
425-555-5555 |
5 | Et telefonnummer. Hvert skilletegn er ett enkelt token, så 425-555-5555 det er 5 tokener:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Konfigurer nærhetsklaringstypen
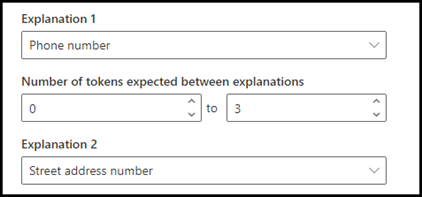
Du kan for eksempel konfigurere nærhetsinnstillingen til å definere området for antall tokener i telefonnummerforklaringen fra forklaringen av gateadressenummeret . Legg merke til at minimumsområdet er «0», fordi det ikke er noen tokener mellom telefonnummeret og gateadressenummeret.
Men noen telefonnumre i eksempeldokumentene legges til (mobil).
Nestor Wilke
111-111-1111 (mobil)
Én Microsoft Way
Redmond, WA 98034
Det finnes tre tokener i (mobil):
| Frase | Tokenantall |
|---|---|
| ( | 1 |
| mobil | 2 |
| ) | 3 |
Konfigurer nærhetsinnstillingen til å ha et område på 0 til 3.
Konfigurere hvor uttrykk forekommer i dokumentet
Når du oppretter en forklaring, søkes hele dokumentet som standard etter uttrykket du prøver å trekke ut. Du kan imidlertid bruke innstillingen Hvor disse uttrykkene forekommer avansert for å isolere en bestemt plassering i dokumentet der et uttrykk oppstår. Denne innstillingen er nyttig i situasjoner der lignende forekomster av et uttrykk kan vises et annet sted i dokumentet, og du vil kontrollere at den riktige er valgt.
Med henvisning til vårt eksempel på medisinsk henvisningsdokument, er den henvisende legen alltid nevnt i det første avsnittet i dokumentet. Med innstillingen Hvor disse uttrykkene forekommer , kan du i dette eksemplet konfigurere forklaringen til å søke etter denne etiketten bare i begynnelsen av dokumentet, eller en annen plassering der den kan forekomme.
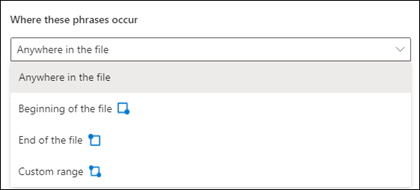
Du kan velge følgende alternativer for denne innstillingen:
Hvor som helst i filen: Hele dokumentet søkes etter uttrykket.
Begynnelsen av filen: Dokumentet søkes fra begynnelsen til fraseplasseringen.
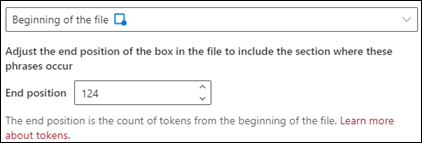
I visningsprogrammet kan du justere merkeboksen manuelt for å inkludere plasseringen der fasen inntreffer. Verdien for sluttposisjon oppdateres for å vise antall tokener det valgte området inkluderer. Du kan også oppdatere verdien for sluttplassering for å justere det valgte området.
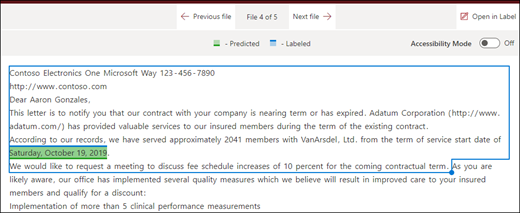
Slutten av filen: Dokumentet søkes fra slutten til setningsplasseringen.
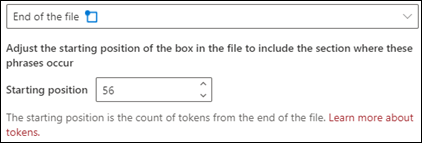
I visningsprogrammet kan du justere merkeboksen manuelt for å inkludere plasseringen der fasen inntreffer. Verdien for startposisjon oppdateres for å vise antall tokener det valgte området inkluderer. Du kan også oppdatere verdien for startposisjon for å justere det valgte området.

Egendefinert område: Dokumentet søkes i et angitt område etter setningsplasseringen.
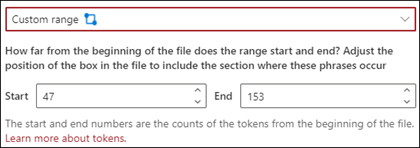
I visningsprogrammet kan du justere merkeboksen manuelt for å inkludere plasseringen der fasen inntreffer. For denne innstillingen må du velge start- og sluttposisjon . Disse verdiene representerer antall tokener fra begynnelsen av dokumentet. Selv om du kan skrive inn disse verdiene manuelt, er det enklere å justere merkeboksen i visningsprogrammet manuelt.
Viktige faktorer når du konfigurerer forklaringer
Når du trener en klassifier, er det et par ting å huske på som vil gi mer forutsigbare resultater:
Jo flere dokumenter du kalibrerer med, jo mer nøyaktig blir klassifieren. Når det er mulig, kan du bruke mer enn fem gode dokumenter og bruke mer enn ett ugyldig dokument. Hvis bibliotekene du arbeider med, har flere forskjellige dokumenttyper, fører flere av hver type til mer forutsigbare resultater.
Merking av dokumentet spiller en viktig rolle i opplæringsprosessen. De brukes sammen med forklaringer for å lære opp modellen. Det kan hende du ser noen avvik når du trener en klassifier med dokumenter som ikke har mye innhold i seg. Forklaringen samsvarer kanskje ikke med noe i dokumentet, men siden det ble merket som et «godt» dokument, kan det hende du ser at det samsvarer under opplæringen.
Når du oppretter forklaringer, bruker den ELLER-logikk i kombinasjon med etiketten for å avgjøre om det er et treff. Vanlig uttrykk som bruker AND-logikk, kan være mer forutsigbart. Her er et eksempel på et vanlig uttrykk du kan bruke på ekte dokumenter som opplæring. Legg merke til at teksten som er uthevet i rødt, er uttrykket eller uttrykkene du vil se etter.
(?=.*network provider)(?=.*participating providers).*
Etiketter og forklaringer fungerer sammen og brukes til å lære opp modellen. Det er ikke en serie med regler som kan kobles fra hverandre og nøyaktige vektinger eller prognoser som brukes på hver variabel som er konfigurert. Jo større variasjon av dokumenter som brukes i opplæringen, gir mer nøyaktighet i modellen.