Bruk Tidyverse
Tidyverse er en samling av R-pakker som dataforskere vanligvis bruker i daglige dataanalyser. Den inneholder pakker for dataimport (readr), datavisualisering (ggplot2), datamanipulering (dplyr, tidyr), funksjonell programmering (purrr) og modellbygging (tidymodels) osv. Pakkene i tidyverse er utformet for å fungere sammen sømløst og følge et konsekvent sett med utformingsprinsipper.
Microsoft Fabric distribuerer den nyeste stabile versjonen av tidyverse med hver kjøretidsutgivelse. Importer og begynn å bruke de velkjente R-pakkene.
Forutsetning
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

Åpne eller opprett en notatblokk. Hvis du vil finne ut hvordan du bruker Microsoft Fabric-notatblokker.
Angi språkalternativet til SparkR (R) for å endre primærspråket.
Legg notatblokken til et lakehouse. På venstre side velger du Legg til for å legge til et eksisterende innsjøhus eller opprette et innsjøhus.
Belastning tidyverse
# load tidyverse
library(tidyverse)
Dataimport
readr er en R-pakke som inneholder verktøy for å lese rektangulære datafiler, for eksempel CSV-, TSV- og fastbreddefiler.
readrgir en rask og brukervennlig måte å lese rektangulære datafiler på, for eksempel å tilby funksjoner og read_csv() for å lese henholdsvis read_tsv() CSV- og TSV-filer.
La oss først opprette en R data.frame, skrive den til lakehouse ved hjelp av readr::write_csv() og lese den tilbake med readr::read_csv().
Merk
Hvis du vil ha tilgang til Lakehouse-filer ved hjelp av readr, må du bruke Fil-API-banen. Høyreklikk på filen eller mappen du vil ha tilgang til, i Lakehouse-utforskeren, og kopier fil-API-banen fra hurtigmenyen.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
La oss deretter skrive dataene til lakehouse ved hjelp av Fil-API-banen.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Les dataene fra lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Datarydding
tidyr er en R-pakke som gir verktøy for å arbeide med rotete data. Hovedfunksjonene i tidyr er utformet for å hjelpe deg med å omforme data til et ryddig format. Ryddige data har en bestemt struktur der hver variabel er en kolonne, og hver observasjon er en rad, noe som gjør det enklere å arbeide med data i R og andre verktøy.
Funksjonen i gather() kan for eksempel tidyr brukes til å konvertere brede data til lange data. Her er et eksempel:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funksjonell programmering
purrr er en R-pakke som forbedrer Rs funksjonelle programmeringsverktøysett ved å tilby et komplett og konsekvent sett med verktøy for å arbeide med funksjoner og vektorer. Det beste stedet å begynne med purrr er familien av map() funksjoner som lar deg erstatte mange for løkker med kode som er både mer kortfattet og enklere å lese. Her er et eksempel på hvordan du bruker map() en funksjon på hvert element i en liste:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Datamanipulering
dplyr er en R-pakke som gir et konsekvent sett med verb som hjelper deg med å løse de vanligste problemene med datamanipulering, for eksempel å velge variabler basert på navnene, plukke saker basert på verdiene, redusere flere verdier ned til ett enkelt sammendrag og endre rekkefølgen på radene osv. Her er noen eksempler:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Datavisualisering
ggplot2 er en R-pakke for deklarativt oppretting av grafikk, basert på Grammatikk i grafikk. Du oppgir dataene, forteller ggplot2 hvordan du tilordner variabler til estetikk, hvilke grafiske primitiver som skal brukes, og det tar seg av detaljene. Her er noen eksempler:
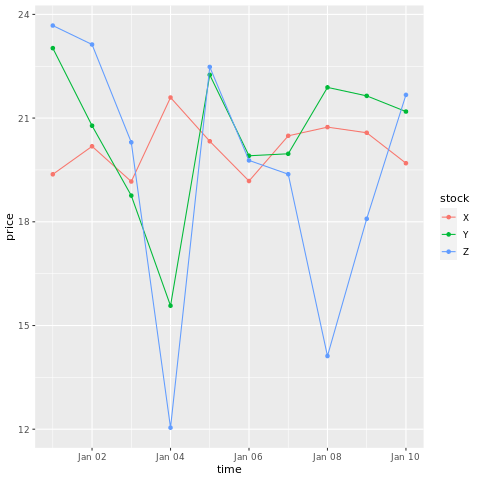
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
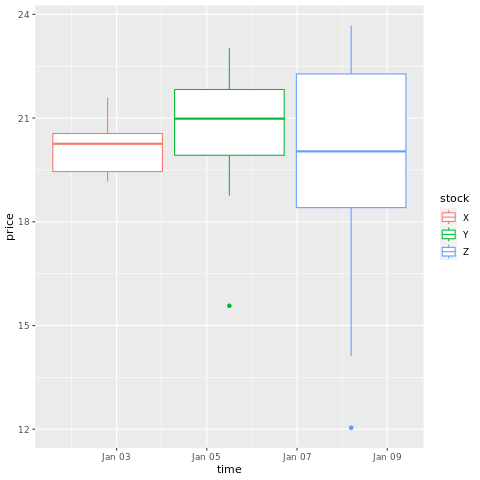
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Modellbygning
Rammeverket tidymodels er en samling pakker for modellering og maskinlæring ved hjelp av tidyverse prinsipper. Den dekker en liste over kjernepakker for en rekke modellbyggeoppgaver, for eksempel rsample for opplærings-/testdatasetteksempelsplitting, parsnip for modellspesifikasjon, recipes for dataforbehandling, workflows for modelleringsarbeidsflyter, tune for hyperparameterejustering, yardstick for modellevaluering, broom for å rydde modellutdata og dials for administrasjon av justeringsparametere. Du kan lære mer om pakkene ved å gå til tidymodels-nettstedet. Her er et eksempel på å bygge en lineær regresjonsmodell for å forutsi miles per gallon (mpg) av en bil basert på vekten (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
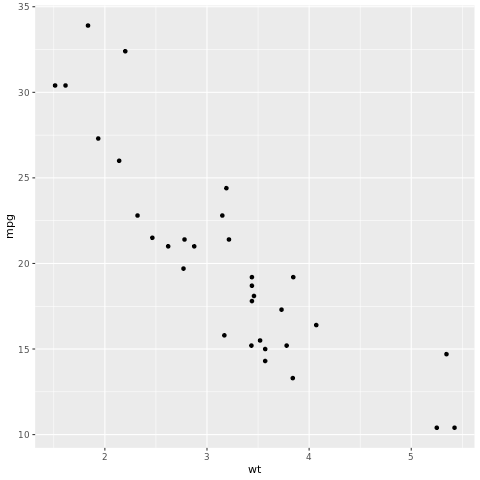
Fra punktplottet ser relasjonen omtrent lineær ut, og variansen ser konstant ut. La oss prøve å modellere dette ved hjelp av lineær regresjon.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Bruk den lineære regresjonsmodellen for å forutsi på testdatasett.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
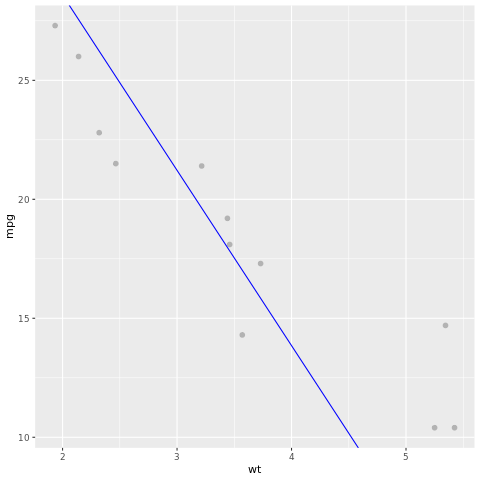
La oss ta en titt på modellresultatet. Vi kan tegne modellen som et linjediagram og testbakkens sannhetsdata som punkter i samme diagram. Modellen ser bra ut.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")