Opplæring: Bruk R til å forutsi flyforsinkelse
Denne opplæringen presenterer et ende-til-ende-eksempel på en Synapse Data Science-arbeidsflyt i Microsoft Fabric. Den bruker nycflights13 data, og R, til å forutsi om et fly kommer mer enn 30 minutter for sent. Den bruker deretter prognoseresultatene til å bygge et interaktivt Power BI-instrumentbord.
I denne opplæringen lærer du hvordan du:
- Bruk tidymodels pakker (oppskrifter, analyse, rsample, arbeidsflyter) for å behandle data og lære opp en maskinlæringsmodell
- Skriv utdata til et lakehouse som deltatabell
- Bygg en visualiseringsrapport for Power BI for å få direkte tilgang til data i lakehouse
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

Åpne eller opprett en notatblokk. Hvis du vil lære hvordan du gjør det, kan du se Slik bruker du Microsoft Fabric-notatblokker.
Angi språkalternativet til SparkR (R)- for å endre primærspråket.
Legg notatblokken til et lakehouse. På venstre side velger du Legg til for å legge til et eksisterende innsjøhus eller opprette et innsjøhus.
Installer pakker
Installer nycflights13-pakken for å bruke koden i denne opplæringen.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Utforsk dataene
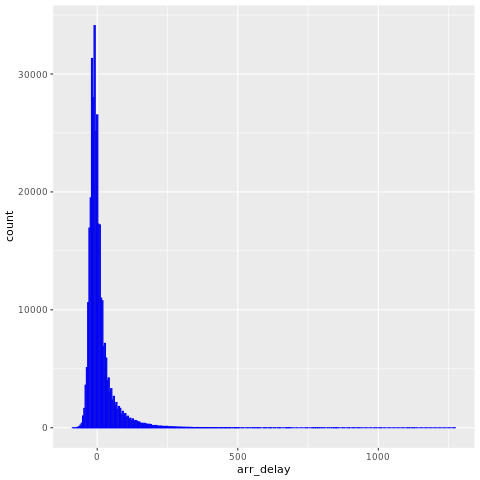
De nycflights13 dataene har informasjon om 325 819 flyvninger som ankom nær New York City i 2013. Først kan du se distribusjonen av flyforsinkelser. Denne grafen viser at fordelingen av ankomstforsinkelser er riktig skjev. Den har en lang hale i de høye verdiene.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Last inn dataene, og gjør noen endringer i variablene:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Før vi bygger modellen, bør du vurdere noen spesifikke variabler som er viktige for både forhåndsbehandling og modellering.
Variabel arr_delay er en faktorvariabel. For opplæring av logistisk regresjonsmodell er det viktig at resultatvariabelen er en faktorvariabel.
glimpse(flight_data)
Omtrent 16% av flyene i dette datasettet kom mer enn 30 minutter for sent.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Funksjonen dest har 104 flydestinasjoner.
unique(flight_data$dest)
Det finnes 16 forskjellige operatører.
unique(flight_data$carrier)
Dele dataene
Del det enkle datasettet i to sett: en opplæring sett og en testing sett. Behold de fleste radene i det opprinnelige datasettet (som et tilfeldig valgt delsett) i opplæringsdatasettet. Bruk opplæringsdatasettet til å tilpasse modellen, og bruk testdatasettet til å måle modellytelsen.
Bruk rsample-pakken til å opprette et objekt som inneholder informasjon om hvordan du deler dataene. Bruk deretter ytterligere to rsample funksjoner til å opprette DataFrames for opplærings- og testsettene:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Opprette en oppskrift og roller
Lag en oppskrift på en enkel logistisk regresjonsmodell. Før du trener modellen, kan du bruke en oppskrift til å opprette nye prediktorer og gjennomføre forhåndsbearbeidingen som modellen krever.
Bruk update_role()-funksjonen slik at oppskriftene vet at flight og time_hour er variabler, med en egendefinert rolle kalt ID. En rolle kan ha en hvilken som helst tegnverdi. Formelen inneholder alle variabler i opplæringssettet, bortsett fra arr_delay, som prediktorer. Oppskriften beholder disse to ID-variablene, men bruker dem ikke som resultater eller prediktorer.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Hvis du vil vise gjeldende sett med variabler og roller, bruker du summary()-funksjonen:
summary(flights_rec)
Opprett funksjoner
Gjør noen funksjonsteknikker for å forbedre modellen. Flydatoen kan ha en rimelig effekt på sannsynligheten for en sen ankomst.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Det kan bidra til å legge til modelltermer avledet fra datoen som potensielt har viktighet for modellen. Utled følgende meningsfulle funksjoner fra enkeltdatovariabelen:
- Dag i uken
- Måned
- Hvorvidt datoen tilsvarer en ferie eller ikke
Legg til de tre trinnene i oppskriften:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Tilpass en modell med en oppskrift
Bruk logistisk regresjon til å modellere flydataene. Først bygger du en modellspesifikasjon med parsnip-pakken:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Bruk workflows pakken til å samle parsnip modellen (lr_mod) med oppskriften din (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Kalibrer modellen
Denne funksjonen kan klargjøre oppskriften og lære opp modellen fra de resulterende prediktorene:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Bruk hjelpefunksjonene xtract_fit_parsnip() og extract_recipe() til å trekke ut modell- eller oppskriftsobjektene fra arbeidsflyten. I dette eksemplet kan du dra det monterte modellobjektet, og deretter bruke broom::tidy()-funksjonen til å få en ryddig tibble av modellskoeffisienter:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Forutsi resultater
Et enkelt kall til predict() bruker den opplærte arbeidsflyten (flights_fit) til å lage prognoser med de usynlige testdataene. Den predict() metoden bruker oppskriften på de nye dataene, og sender deretter resultatene til den monterte modellen.
predict(flights_fit, test_data)
Få utdataene fra predict() for å returnere den forventede klassen: late versus on_time. Men for de forventede klassesannsynlighetene for hver flyvning bruker du augment() med modellen, kombinert med testdata, til å lagre dem sammen:
flights_aug <-
augment(flights_fit, test_data)
Se gjennom dataene:
glimpse(flights_aug)
Evaluer modellen
Vi har nå en tibble med de forventede klassesannsynlighetene. I de første radene, modellen riktig spådd fem on-time flyreiser (verdier av .pred_on_time er p > 0.50). Vi har imidlertid totalt 81 455 rader å forutsi.
Vi trenger en metrikkverdi som forteller hvor godt modellen forutså sene ankomster, sammenlignet med den sanne statusen til resultatvariabelen, arr_delay.
Bruk området under driftsegenskaper for kurvemottaker (AUC-ROC) som metrikkverdi. Beregne den med roc_curve() og roc_auc(), fra yardstick-pakken:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Bygg en Power BI-rapport
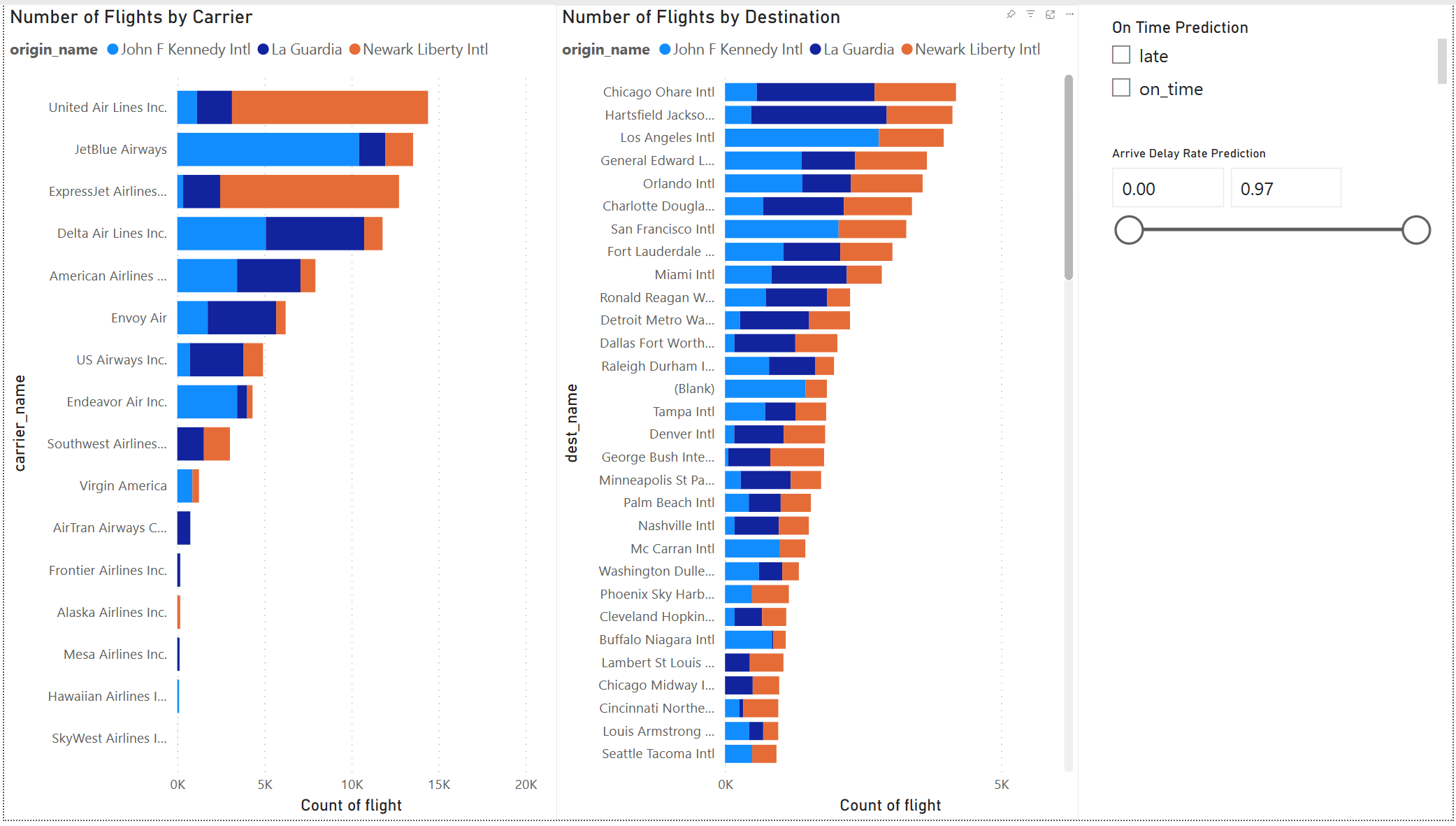
Modellresultatet ser bra ut. Bruk prognoseresultatene for flyforsinkelse til å bygge et interaktivt Power BI-instrumentbord. Instrumentbordet viser antall flyvninger etter transportør, og antall flyvninger etter mål. Instrumentbordet kan filtrere etter forsinkelsesprognoseresultatene.
Inkluder navnet på operatøren og flyplassnavnet i prognoseresultatdatasettet:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Se gjennom dataene:
glimpse(flights_clean)
Konvertere dataene til en Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Skriv inn dataene i en deltatabell i lakehouse:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Bruk deltatabellen til å opprette en semantisk modell.
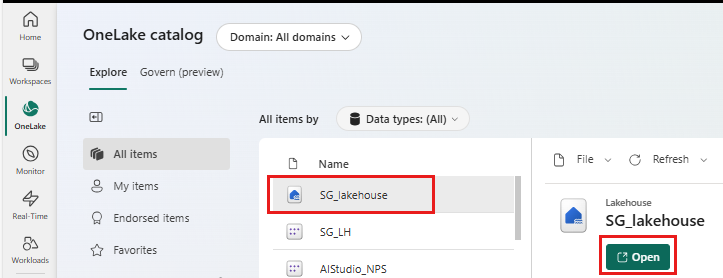
Velg OneLake til venstre
Velg lakehouse som du har knyttet til notatblokken
Velg Åpne
Velg ny semantisk modell
Velg nycflight13 for den nye semantiske modellen, og velg deretter Bekreft
Den semantiske modellen er opprettet. Velg Ny rapport
Merke eller dra felt fra Data- og visualiseringer ruter til rapportlerretet for å bygge rapporten
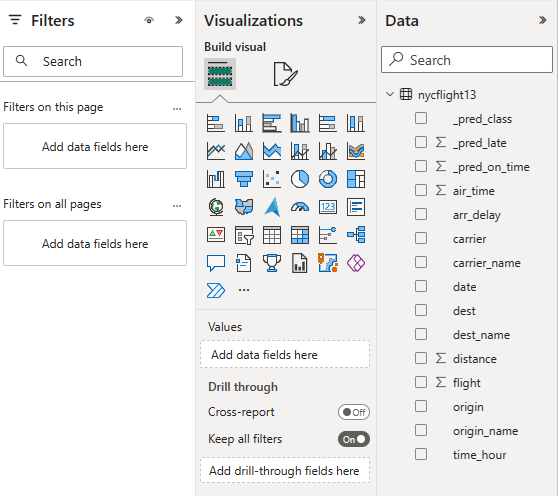
Hvis du vil opprette rapporten som vises i begynnelsen av denne delen, bruker du disse visualiseringene og dataene:
-
 stablet stolpediagram med:
stablet stolpediagram med: - Y-akse: carrier_name
- X-akse: . Velg Antall for aggregasjonen
- Forklaring: origin_name
-
stablet stolpediagram med:
- Y-akse: dest_name
- X-akse: . Velg Antall for aggregasjonen
- Forklaring: origin_name
-
 slicer med:
slicer med: - Felt: _pred_class
-
slicer med:
- Felt: _pred_late