Administrasjon av R-bibliotek
Biblioteker gir gjenbrukbar kode som du kanskje vil inkludere i programmene eller prosjektene for Microsoft Fabric Spark.
Microsoft Fabric støtter en R-kjøretid med mange populære R-pakker med åpen kildekode, inkludert TidyVerse, forhåndsinstallert. Når en Spark-forekomst starter, inkluderes disse bibliotekene automatisk og kan brukes umiddelbart i notatblokker eller Spark-jobbdefinisjoner.
Du må kanskje oppdatere R-bibliotekene av ulike årsaker. En av kjerneavhengighetene ga for eksempel ut en ny versjon, eller teamet ditt har laget en egendefinert pakke som du trenger tilgjengelig i Spark-klyngene.
Det finnes to typer biblioteker du kanskje vil inkludere basert på scenarioet:
Feedbiblioteker referere til de som er bosatt i offentlige kilder eller repositorier, for eksempel CRAN eller GitHub.
egendefinerte biblioteker er koden som er bygget av deg eller organisasjonen, kan .tar.gz administreres gjennom bibliotekbehandlingsportaler.
Det er to nivåer med pakker installert på Microsoft Fabric:
Miljø: Administrere biblioteker gjennom et miljø for å bruke samme sett med biblioteker på nytt på tvers av flere notatblokker eller jobber.
økt: En installasjon på øktnivå oppretter et miljø for en bestemt notatblokkøkt. Endringen av øktnivåbiblioteker beholdes ikke mellom økter.
Oppsummerer gjeldende tilgjengelige virkemåter for behandling av R-bibliotek:
| Bibliotektype | Miljøinstallasjon | Installasjon på øktnivå |
|---|---|---|
| R-feed (CRAN) | Støttes ikke | Støttes |
| R-egendefinert | Støttes | Støttes |
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

R-biblioteker på øktnivå
Når du utfører interaktiv dataanalyse eller maskinlæring, kan du prøve nyere pakker, eller du trenger kanskje pakker som for øyeblikket ikke er tilgjengelige i arbeidsområdet. I stedet for å oppdatere innstillingene for arbeidsområdet, kan du bruke øktomfangpakker til å legge til, administrere og oppdatere øktavhengigheter.
- Når du installerer biblioteker med øktomfang, har bare gjeldende notatblokk tilgang til de angitte bibliotekene.
- Disse bibliotekene påvirker ikke andre økter eller jobber ved hjelp av samme Spark-utvalg.
- Disse bibliotekene er installert på toppen av bibliotekene for basiskjøring og utvalgsnivå.
- Notatblokkbiblioteker har høyest prioritet.
- Øktomfangede R-biblioteker vedvarer ikke på tvers av økter. Disse bibliotekene installeres i begynnelsen av hver økt når de relaterte installasjonskommandoene kjøres.
- R-biblioteker med øktomfang installeres automatisk på tvers av både driver- og arbeidernoder.
Notat
Kommandoene for administrasjon av R-biblioteker deaktiveres når du kjører datasamlebåndjobber. Hvis du vil installere en pakke i et datasamlebånd, må du bruke bibliotekbehandlingsfunksjonene på arbeidsområdenivå.
Installer R-pakker fra CRAN
Du kan enkelt installere et R-bibliotek fra CRAN.
# install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Du kan også bruke CRAN-øyeblikksbilder som repositorium for å sikre at du laster ned samme pakkeversjon hver gang.
# install a package from CRAN snapsho
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Installer R-pakker ved hjelp av devtools
Biblioteket devtools forenkler pakkeutviklingen for å fremskynde vanlige oppgaver. Dette biblioteket er installert i standard Kjøretid for Microsoft Fabric.
Du kan bruke devtools til å angi en bestemt versjon av et bibliotek som skal installeres. Disse bibliotekene installeres på tvers av alle noder i klyngen.
# Install a specific version.
install_version("caesar", version = "1.0.0")
På samme måte kan du installere et bibliotek direkte fra GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
For øyeblikket støttes følgende devtools funksjoner i Microsoft Fabric:
| Kommando | Beskrivelse |
|---|---|
| install_github() | Installerer en R-pakke fra GitHub |
| install_gitlab() | Installerer en R-pakke fra GitLab |
| install_bitbucket() | Installerer en R-pakke fra BitBucket |
| install_url() | Installerer en R-pakke fra en vilkårlig URL-adresse |
| install_git() | Installerer fra et tilfeldig git-repositorium |
| install_local() | Installerer fra en lokal fil på disken |
| install_version() | Installerer fra en bestemt versjon på CRAN |
Installer egendefinerte R-biblioteker
Hvis du vil bruke et egendefinert bibliotek på øktnivå, må du først laste det opp til et vedlagt Lakehouse.
Åpne notatblokken du vil bruke det egendefinerte biblioteket i.
På venstre side velger du Legg til for å legge til et eksisterende innsjøhus eller opprette et innsjøhus.
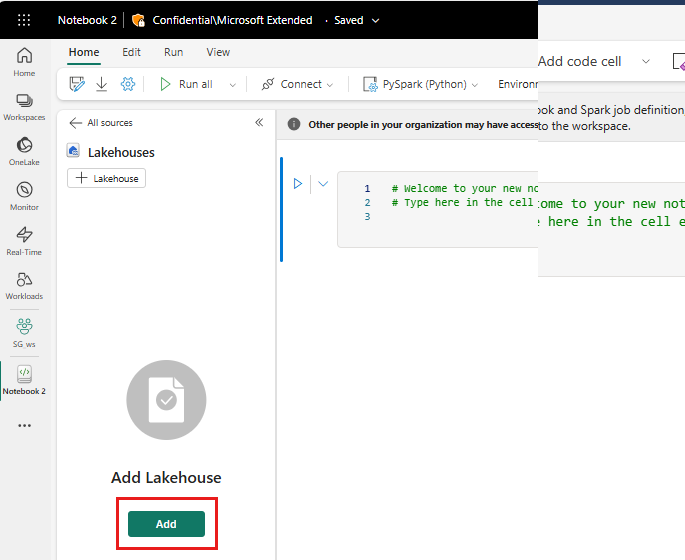
Høyreklikk eller velg "..." ved siden av Filer for å laste opp .tar.gz filen.
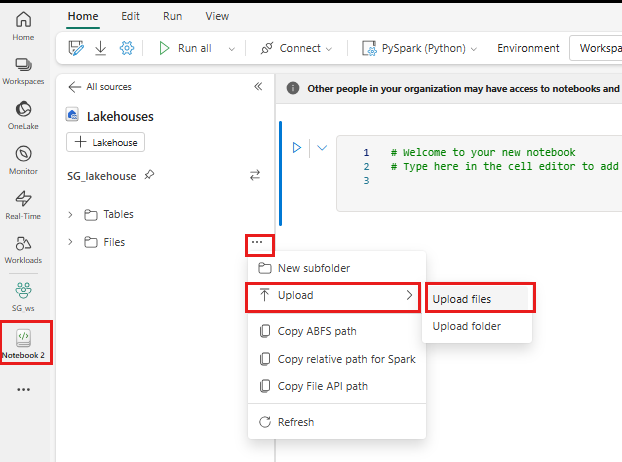
Når du har lastet opp, går du tilbake til notatblokken. Bruk følgende kommando til å installere det egendefinerte biblioteket i økten:
install.packages("filepath/filename.tar.gz", repos = NULL, type = "source")
Vis installerte biblioteker
Spør alle bibliotekene som er installert i økten, ved hjelp av kommandoen library.
# query all the libraries installed in current session
library()
Bruk packageVersion-funksjonen til å kontrollere versjonen av biblioteket:
# check the package version
packageVersion("caesar")
Fjerne en R-pakke fra en økt
Du kan bruke detach-funksjonen til å fjerne et bibliotek fra navneområdet. Disse bibliotekene forblir på disken til de lastes inn på nytt.
# detach a library
detach("package: caesar")
Hvis du vil fjerne en pakke med øktomfang fra en notatblokk, bruker du kommandoen remove.packages(). Denne bibliotekendringen har ingen innvirkning på andre økter på samme klynge. Brukere kan ikke avinstallere eller fjerne innebygde biblioteker for standard Kjøretid for Microsoft Fabric.
Notat
Du kan ikke fjerne kjernepakker som SparkR, SparklyR eller R.
remove.packages("caesar")
Øktomfangede R-biblioteker og SparkR
Biblioteker med notatblokkomfang er tilgjengelige for SparkR-arbeidere.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Øktomfangede R-biblioteker og sparklyr
Med spark_apply() i sparklyr, kan du bruke alle R-pakker i Spark. Som standard settes pakkeargumentet til USANN i sparklyr::spark_apply(). Dette kopierer biblioteker i gjeldende libPaths til arbeiderne, slik at du kan importere og bruke dem på arbeidere. Du kan for eksempel kjøre følgende for å generere en cæsarkryptert melding med sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- sparkR.version()
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Relatert innhold
Finn ut mer om R-funksjonaliteten: