Overfør Spark-bassenger fra Azure Synapse Analytics til Fabric
Mens Azure Synapse tilbyr Spark-bassenger, tilbyr Fabric Starter-bassenger og egendefinerte bassenger. Startutvalget kan være et godt valg hvis du har ett enkelt utvalg uten egendefinerte konfigurasjoner eller biblioteker i Azure Synapse, og hvis middels nodestørrelse oppfyller kravene dine. Hvis du imidlertid søker mer fleksibilitet med Konfigurasjonene for Spark-utvalget, anbefaler vi imidlertid å bruke egendefinerte utvalg. Det finnes to alternativer her:
- Alternativ 1: Flytt Spark-utvalget til standardutvalget for et arbeidsområde.
- Alternativ 2: Flytt Spark-bassenget til et egendefinert miljø i Fabric.
Hvis du har mer enn ett Spark-basseng og planlegger å flytte dem til samme Fabric-arbeidsområde, anbefaler vi at du bruker alternativ 2, og oppretter flere egendefinerte miljøer og bassenger.
Se forskjeller mellom Azure Synapse Spark og Fabric for hensyn til Spark-utvalget.
Forutsetning
Hvis du ikke allerede har en, oppretter du et Fabric-arbeidsområde i leieren.
Alternativ 1: Fra Spark-utvalget til arbeidsområdets standardutvalg
Du kan opprette et egendefinert Spark-utvalg fra Fabric-arbeidsområdet og bruke det som standardutvalg i arbeidsområdet. Standardutvalget brukes av alle notatblokker og Spark-jobbdefinisjoner i samme arbeidsområde.
Slik flytter du fra et eksisterende Spark-utvalg fra Azure Synapse til et standardutvalg for arbeidsområdet:
- Access Azure Synapse-arbeidsområde: Logg på Azure. Gå til Azure Synapse-arbeidsområdet, gå til Analyseutvalg og velg Apache Spark-bassenger.
- Finn Spark-bassenget: Finn Spark-bassenget du vil flytte til Fabric, fra Apache Spark-bassenger, og kontroller utvalgets egenskaper.
- Hent egenskaper: Få egenskaper for Spark-utvalget, for eksempel Apache Spark-versjon, nodestørrelse, nodestørrelse eller autoskala. Se hensyn til Spark-utvalget for å se eventuelle forskjeller.
-
Opprett et egendefinert Spark-basseng i Fabric:
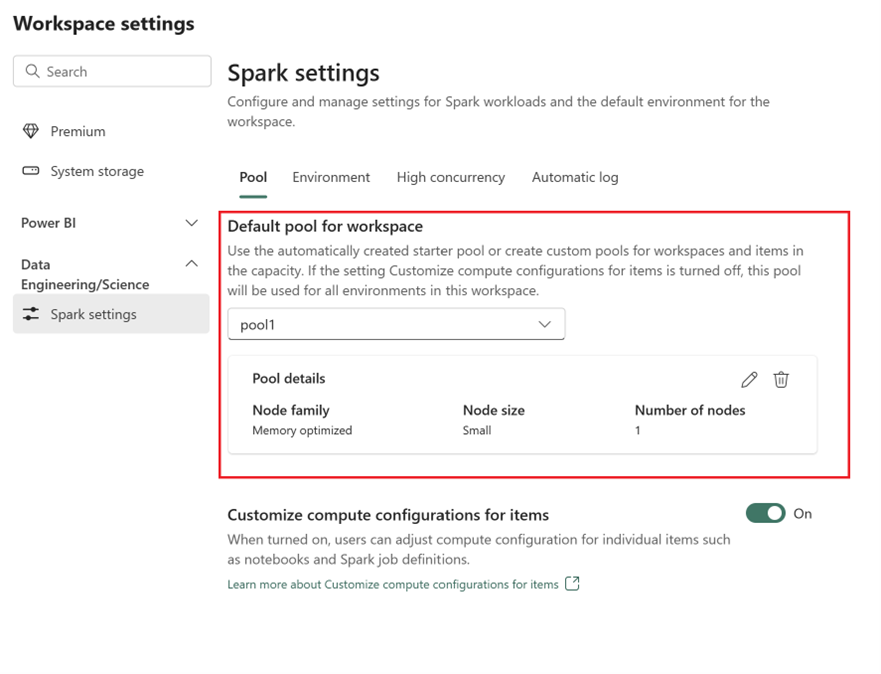
- Gå til fabric-arbeidsområdet, og velg innstillinger for arbeidsområde.
- Gå til Dataingeniør ing/Vitenskap, og velg Spark-innstillinger.
- Utvid rullegardinmenyen på Fanen Utvalg og Standardutvalg for arbeidsområde, og velg Opprett nytt utvalg.
- Opprett det egendefinerte utvalget med tilsvarende målverdier. Fyll ut alternativene for navn, nodefamilie, nodestørrelse, autoskalering og dynamisk fordeling av eksekutor.
-
Velg en kjøretidsversjon:
- Gå til Miljø-fanen , og velg den nødvendige Runtime-versjonen. Se tilgjengelige kjøretider her.
- Deaktiver alternativet Angi standardmiljø.
Merk
I dette alternativet støttes ikke biblioteker eller konfigurasjoner på utvalgsnivå. Du kan imidlertid justere beregningskonfigurasjonen for individuelle elementer, for eksempel notatblokker og Spark-jobbdefinisjoner, og legge til innebygde biblioteker. Hvis du trenger å legge til egendefinerte biblioteker og konfigurasjoner i et miljø, bør du vurdere et egendefinert miljø.
Alternativ 2: Fra Spark-utvalg til egendefinert miljø
Med egendefinerte miljøer kan du konfigurere egendefinerte Spark-egenskaper og -biblioteker. Slik oppretter du et egendefinert miljø:
- Access Azure Synapse-arbeidsområde: Logg på Azure. Gå til Azure Synapse-arbeidsområdet, gå til Analyseutvalg og velg Apache Spark-bassenger.
- Finn Spark-bassenget: Finn Spark-bassenget du vil flytte til Fabric, fra Apache Spark-bassenger, og kontroller utvalgets egenskaper.
- Hent egenskaper: Få egenskaper for Spark-utvalget, for eksempel Apache Spark-versjon, nodestørrelse, nodestørrelse eller autoskala. Se hensyn til Spark-utvalget for å se eventuelle forskjeller.
-
Opprette et egendefinert Spark-utvalg:
- Gå til fabric-arbeidsområdet, og velg innstillinger for arbeidsområde.
- Gå til Dataingeniør ing/Vitenskap, og velg Spark-innstillinger.
- Utvid rullegardinmenyen på Fanen Utvalg og Standardutvalg for arbeidsområde, og velg Opprett nytt utvalg.
- Opprett det egendefinerte utvalget med tilsvarende målverdier. Fyll ut alternativene for navn, nodefamilie, nodestørrelse, autoskalering og dynamisk fordeling av eksekutor.
- Opprett et miljøelement hvis du ikke har et.
-
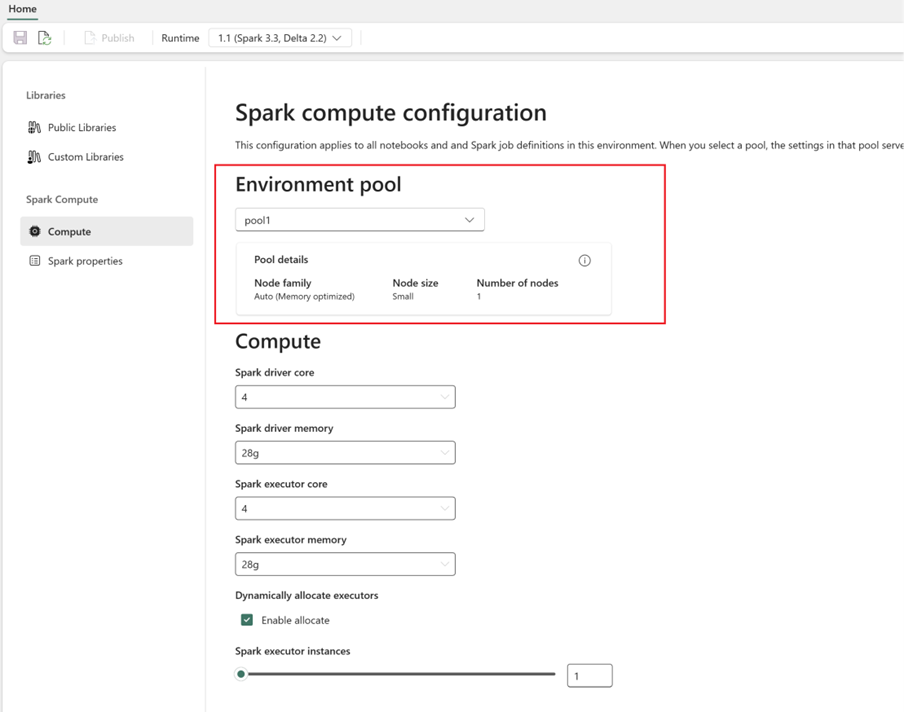
Konfigurer Spark-databehandling:
- Gå til Spark Compute Compute i >
- Velg det nyopprettede utvalget for det nye miljøet.
- Du kan konfigurere kjerner og minne for driver- og eksekutorer.
- Velg en kjøretidsversjon for miljøet. Se tilgjengelige kjøretider her.
- Klikk på Lagre og publiser endringer.
Mer informasjon på å opprette og bruke en Miljø.