Overføre Spark-konfigurasjoner fra Azure Synapse Analytics til Fabric
Apache Spark har en rekke konfigurasjoner som kan tilpasses for å forbedre opplevelsen i ulike scenarioer. I Azure Synapse Spark og Fabric Dataingeniør har du fleksibilitet til å innlemme disse konfigurasjonene eller egenskapene for å skreddersy opplevelsen din. I Fabric kan du legge til Spark-konfigurasjoner i et miljø og bruke innebygde Spark-egenskaper direkte i Spark-jobbene dine. Hvis du vil flytte Azure Synapse Spark pool-konfigurasjoner til Fabric, kan du bruke et miljø.
Se forskjeller mellom Azure Synapse Spark og Fabric for spark-konfigurasjonshensyn.
Forutsetning
- Hvis du ikke allerede har en, oppretter du et Fabric-arbeidsområde i leieren.
- Hvis du ikke allerede har en, oppretter du et miljø i arbeidsområdet.
Alternativ 1: Legge til Spark-konfigurasjoner i egendefinert miljø
I et miljø kan du angi Spark-egenskaper, og disse konfigurasjonene brukes på det valgte miljøutvalget.
- Åpne Synapse Studio: Logg på Azure. Gå til Azure Synapse-arbeidsområdet og åpne Synapse Studio.
-
Finn Spark-konfigurasjoner:
- Gå til Administrer-området , og velg Apache Spark-bassenger.
- Finn Apache Spark-utvalget, velg Apache Spark-konfigurasjon og finn Spark-konfigurasjonsnavnet for utvalget.
- Få Spark-konfigurasjoner: Du kan enten hente disse egenskapene ved å velge Vis konfigurasjoner eller eksportere konfigurasjon (.txt/.conf/.json-format) fra Konfigurasjoner + biblioteker>Apache Spark-konfigurasjoner.
- Når du har Spark-konfigurasjoner, kan du legge til egendefinerte Spark-egenskaper i miljøet i Fabric:
- Gå til Spark Compute>Spark-egenskaper i miljøet.
- Legg til Spark-konfigurasjoner. Du kan enten legge til hver manuelt eller importere fra .yml.
- Klikk på Lagre og publiser endringer.
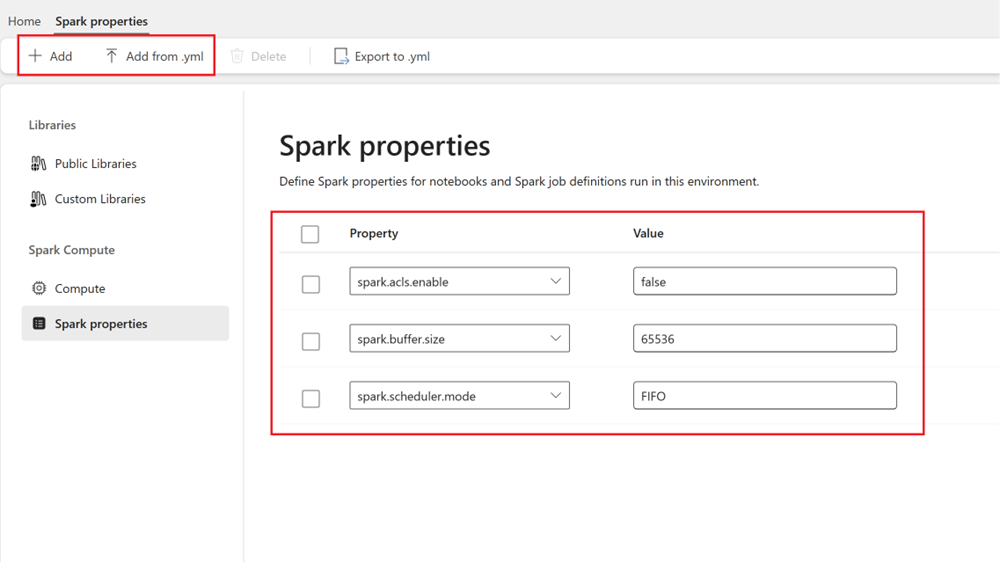
Mer informasjon på å legge til Spark-konfigurasjoner i en Miljø.