Konfigurasjonsinnstillinger for spark-databehandling i stoffmiljøer
Microsoft Fabric Dataingeniør- og Data Science-opplevelser opererer på en fullstendig administrert Spark-databehandlingsplattform. Denne plattformen er utformet for å levere enestående hastighet og effektivitet. Det inkluderer startutvalg og egendefinerte bassenger.
Et stoffmiljø inneholder en samling konfigurasjoner, inkludert Spark-databehandlingsegenskaper som gjør det mulig for brukere å konfigurere Spark-økten etter at de er knyttet til notatblokker og Spark-jobber. Med et miljø har du en fleksibel måte å tilpasse databehandlingskonfigurasjoner for å kjøre Spark-jobber på. I et miljø lar databehandlingsdelen deg konfigurere egenskapene for Spark-øktnivå til å tilpasse minnet og kjernene til eksekutorer basert på arbeidsbelastningskrav.
Arbeidsområdeadministratorer kan aktivere eller deaktivere beregningstilpasninger med tilpassing av databehandlingskonfigurasjoner for elementer-bryteren i utvalgsfanen i Dataingeniør/Vitenskap-delen i skjermbildet Innstillinger for arbeidsområde.
Arbeidsområdeadministratorer kan delegere medlemmer og bidragsytere til å endre standard konfigurasjoner for øktnivådatabehandling i Fabric-miljøet ved å aktivere denne innstillingen.
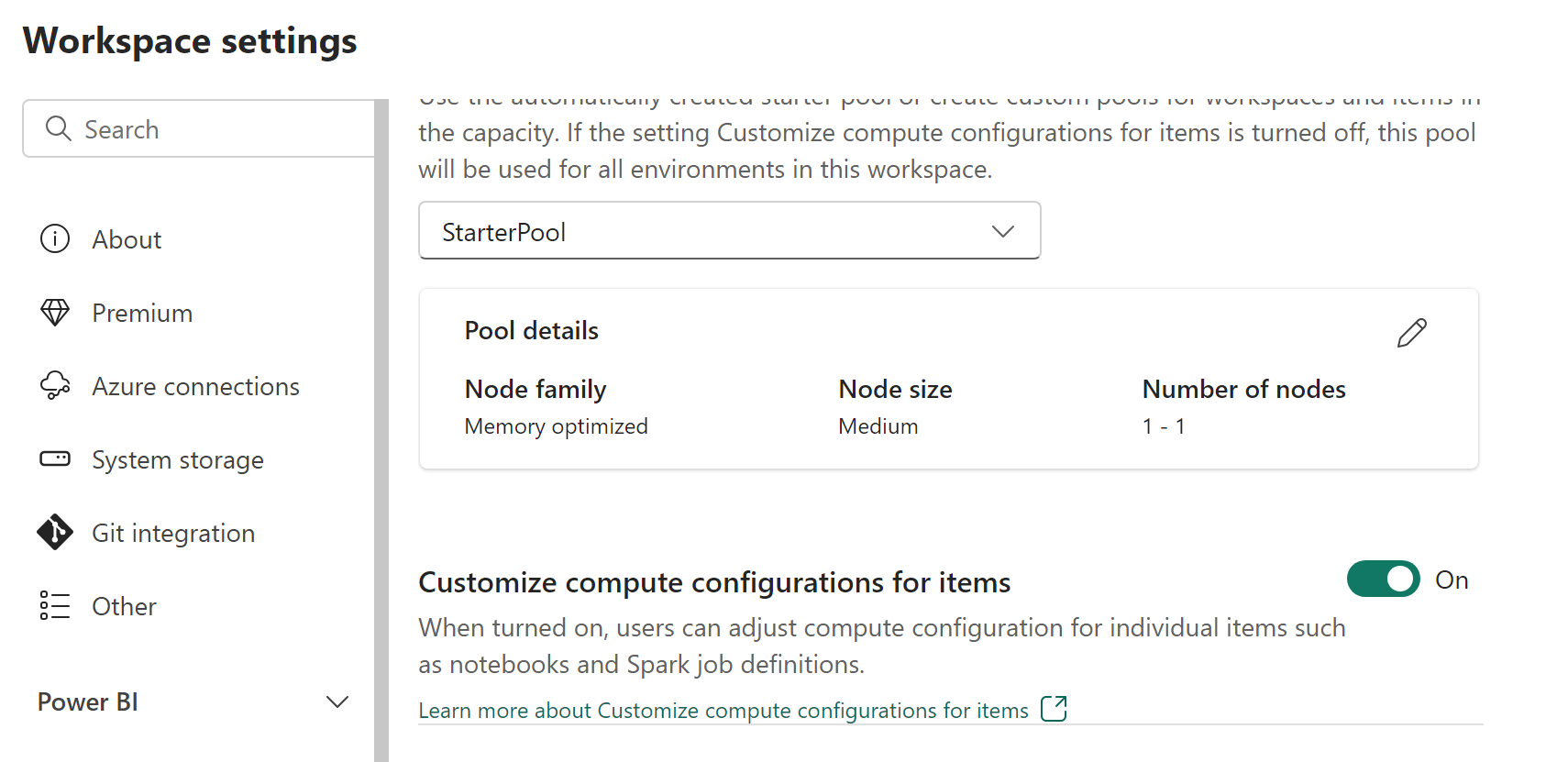
Hvis administratoren for arbeidsområdet deaktiverer dette alternativet i innstillingene for arbeidsområdet, deaktiveres databehandlingsdelen av miljøet, og standard konfigurasjoner for utvalgsdatabehandling for arbeidsområdet brukes til å kjøre Spark-jobber.
Tilpasse egenskaper for databehandling på øktnivå i et miljø
Som bruker kan du velge et utvalg for miljøet fra listen over bassenger som er tilgjengelige i Fabric-arbeidsområdet. Administratoren for Fabric-arbeidsområdet oppretter standard startutvalg og egendefinerte utvalg.
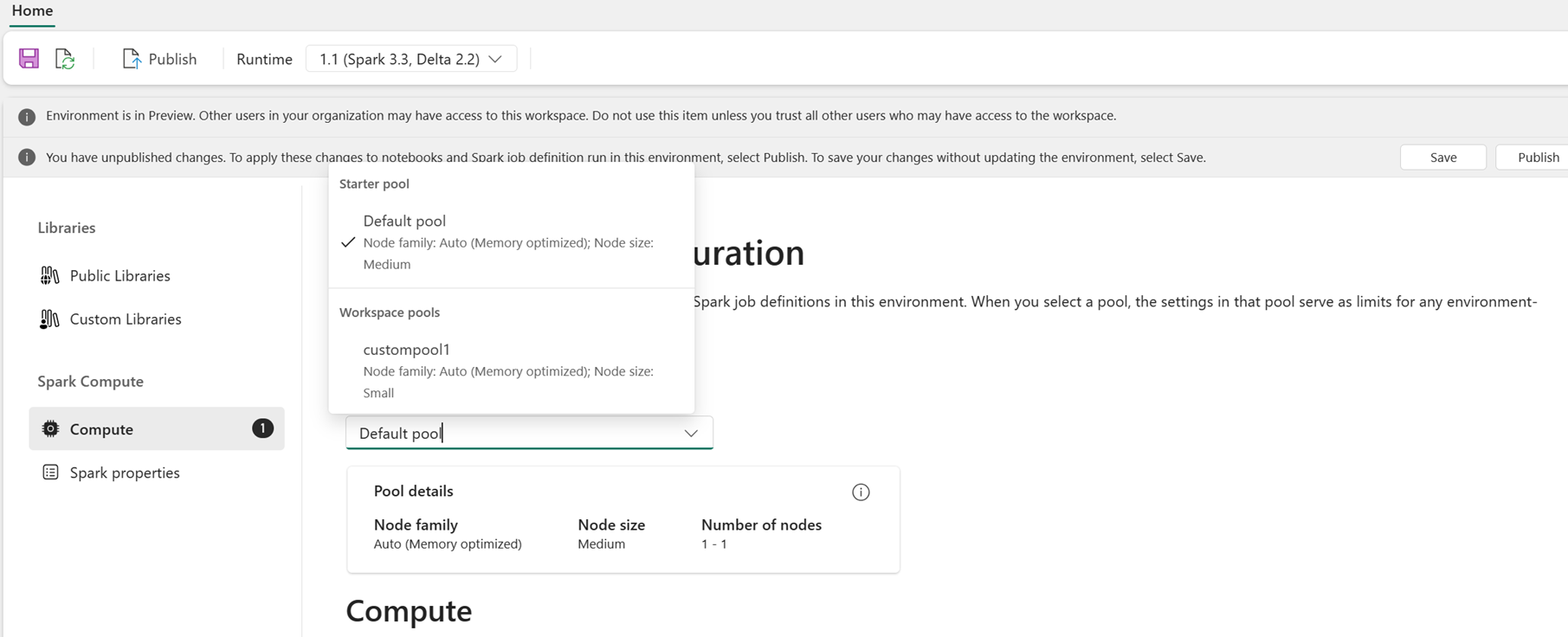
Når du har valgt et utvalg i Databehandling-delen, kan du justere kjerner og minne for eksekutorene innenfor grensene til nodestørrelsene og grensene for det valgte utvalget.
For eksempel: Du velger et egendefinert utvalg med nodestørrelse på store, som er 16 Spark vCores, som miljøutvalg. Deretter kan du velge driver-/eksekutorkjernen som enten er 4, 8 eller 16, basert på jobbnivåkravet. For minnet som er tildelt driveren og eksekutorene, kan du velge 28 g, 56 g eller 112 g, som alle er innenfor grensene til en stor nodeminnegrense.
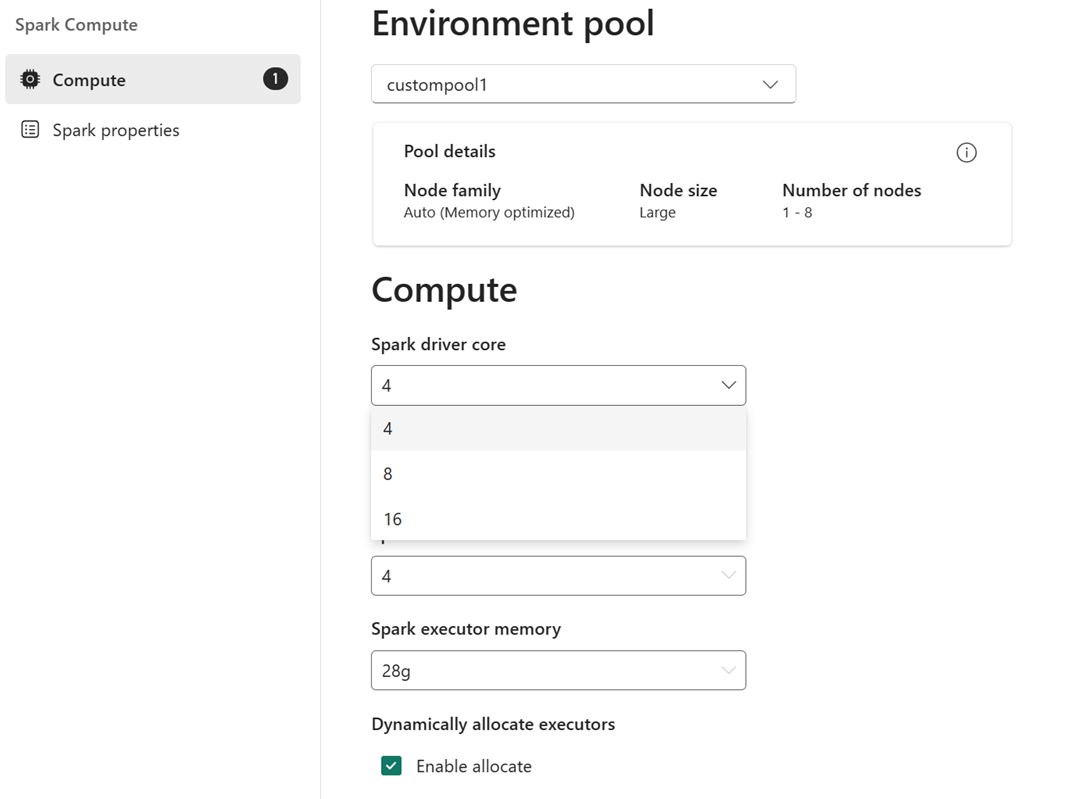
Hvis du vil ha mer informasjon om spark-databehandlingsstørrelser og kjerner eller minnealternativer, kan du se Hva er Spark-databehandling i Microsoft Fabric?.