Microsoft Fabric에서 작업 영역 관리 설정 데이터 엔지니어
적용 대상:✅ Microsoft Fabric의 데이터 엔지니어링 및 데이터 과학
Microsoft Fabric에서 작업 영역을 만들면 해당 작업 영역과 연결된 시작 풀이 자동으로 만들어집니다. Microsoft Fabric에서 간소화된 설정을 사용하면 이러한 옵션이 백그라운드에서 처리되므로 노드 또는 머신 크기를 선택할 필요가 없습니다. 이 구성은 사용자가 컴퓨팅 설정에 대해 걱정할 필요 없이 많은 일반적인 시나리오에서 Apache Spark 작업을 시작하고 실행할 수 있도록 더 빠른(5~10초) Apache Spark 세션 시작 환경을 제공합니다. 특정 컴퓨팅 요구 사항이 있는 고급 시나리오의 경우 사용자는 사용자 지정 Apache Spark 풀을 만들고 성능 요구 사항에 따라 노드 크기를 조정할 수 있습니다.
작업 영역에서 Apache Spark 설정을 변경하려면 해당 작업 영역에 대한 관리자 역할이 있어야 합니다. 자세한 내용은 작업 영역의 역할을 참조 하세요.
작업 영역과 연결된 풀에 대한 Spark 설정을 관리하려면 다음을 수행합니다.
작업 영역의 작업 영역 설정으로 이동하고 데이터 엔지니어링/과학 옵션을 선택하여 메뉴를 확장합니다.
왼쪽 메뉴에 Spark 컴퓨팅 옵션이 표시됩니다.
참고 항목
기본 풀을 시작 풀에서 사용자 지정 Spark 풀로 변경하면 세션 시작 시간이 길어질 수 있습니다(~3분).

풀
작업 영역의 기본 풀
자동으로 생성된 시작 풀을 사용하거나 작업 영역에 대한 사용자 지정 풀을 만들 수 있습니다.
시작 풀: 빠른 환경을 위해 미리 하이드레이션된 라이브 풀이 자동으로 생성됩니다. 이러한 클러스터는 중간 크기입니다. 시작 풀은 구매한 패브릭 용량 SKU에 따라 기본 구성으로 설정됩니다. 관리자는 Spark 워크로드 크기 조정 요구 사항에 따라 최대 노드 및 실행기를 사용자 지정할 수 있습니다. 자세한 내용은 시작 풀 구성을 참조하세요.
사용자 지정 Spark 풀: Spark 작업 요구 사항에 따라 노드 크기를 조정하고, 자동 크기 조정하고, 실행기를 동적으로 할당할 수 있습니다. 사용자 지정 Spark 풀을 만들려면 용량 관리자가 용량 관리자 설정의 Spark 컴퓨팅 섹션에서 사용자 지정된 작업 영역 풀 옵션을 사용하도록 설정해야 합니다.
참고 항목
사용자 지정된 작업 영역 풀에 대한 용량 수준 제어는 기본적으로 사용하도록 설정됩니다. 자세한 내용은 패브릭 용량에 대한 데이터 엔지니어링 및 데이터 과학 설정 구성 및 관리를 참조하세요.
관리자는 새 풀 옵션을 선택하여 컴퓨팅 요구 사항에 따라 사용자 지정 Spark 풀을 만들 수 있습니다.

Microsoft Fabric용 Apache Spark는 단일 노드 클러스터를 지원하므로 사용자가 최소 노드 구성을 1로 선택할 수 있습니다. 이 경우 드라이버와 실행기가 단일 노드에서 실행됩니다. 이러한 단일 노드 클러스터는 노드 실패 시 복원 가능한 고가용성을 제공하고 컴퓨팅 요구 사항이 더 작은 워크로드에 대해 더 나은 작업 안정성을 제공합니다. 사용자 지정 Spark 풀에 대해 자동 크기 조정 옵션을 사용하거나 사용하지 않도록 설정할 수도 있습니다. 자동 크기 조정을 사용하도록 설정하면 풀은 사용자가 지정한 최대 노드 제한 내에서 새 노드를 획득하고 성능 향상을 위해 작업 실행 후 사용 중지합니다.
성능 향상을 위해 데이터 볼륨에 따라 지정된 최대 한도 내에서 자동으로 최적의 실행기 수를 풀링하기 위해 실행기를 동적으로 할당하는 옵션을 선택할 수도 있습니다.

패브릭용 Apache Spark 컴퓨팅에 대해 자세히 알아보세요.
- 항목에 대한 컴퓨팅 구성 사용자 지정: 작업 영역 관리자는 사용자가 환경을 사용하여 Notebook, Spark 작업 정의와 같은 개별 항목에 대해 컴퓨팅 구성(드라이버/실행기 코어, 드라이버/실행기 메모리를 포함하는 세션 수준 속성)을 조정하도록 허용할 수 있습니다.
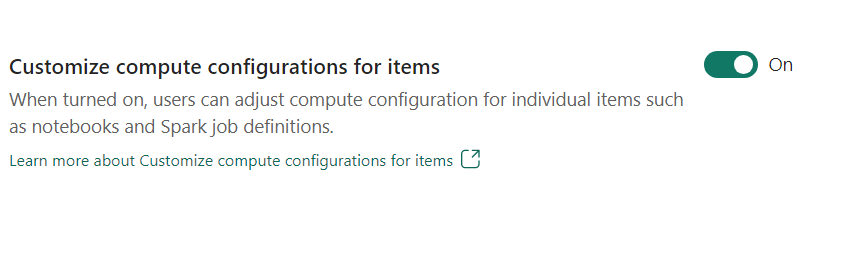
작업 영역 관리자가 설정을 해제하면 기본 풀과 해당 컴퓨팅 구성이 작업 영역의 모든 환경에 사용됩니다.
Environment
환경은 Spark 작업(Notebook, Spark 작업 정의)을 실행하기 위한 유연한 구성을 제공합니다. 환경에서 컴퓨팅 속성을 구성하고, 워크로드 요구 사항에 따라 다양한 런타임을 선택하고, 라이브러리 패키지 종속성을 설정할 수 있습니다.
환경 탭에는 기본 환경을 설정하는 옵션이 있습니다. 작업 영역에 사용할 Spark 버전을 선택할 수 있습니다.
패브릭 작업 영역 관리자는 환경을 작업 영역 기본 환경으로 선택할 수 있습니다.
환경 드롭다운을 통해 새 항목을 만들 수도 있습니다.

기본 환경을 사용하는 옵션을 사용하지 않도록 설정하면 드롭다운 선택 영역에 나열된 사용 가능한 런타임 버전에서 패브릭 런타임 버전을 선택할 수 있습니다.

Apache Spark 런타임에 대해 자세히 알아봅니다.
작업
작업 설정을 사용하면 관리자가 작업 영역의 모든 Spark 작업에 대한 작업 허용 논리를 제어할 수 있습니다.

기본적으로 모든 작업 영역은 낙관적 작업 허용으로 사용하도록 설정됩니다. Microsoft Fabric의 Spark에 대한 작업 허용에 대해 자세히 알아봅니다.
활성 Spark 작업에 대해 최대 예약 코어를 사용하도록 설정하여 낙관적 작업 허용 기반 접근 방식을 전환하고 Spark 작업에 대한 최대 코어를 예약할 수 있습니다.
Spark 세션 시간 제한을 설정하여 모든 Notebook 대화형 세션에 대한 세션 만료를 사용자 지정할 수도 있습니다.
참고 항목
기본 세션 만료는 대화형 Spark 세션에 대해 20분으로 설정됩니다.
높은 동시성
높은 동시성 모드를 사용하면 사용자가 Apache Spark for Fabric 데이터 엔지니어링 및 데이터 과학 워크로드에서 동일한 Spark 세션을 공유할 수 있습니다. Notebook과 같은 항목은 실행에 Spark 세션을 사용하며, 이를 사용하도록 설정하면 사용자가 여러 Notebook에서 단일 Spark 세션을 공유할 수 있습니다.

Apache Spark for Fabric의 높은 동시성에 대해 자세히 알아보세요.
기계 학습 모델 및 실험에 대한 자동 로깅
이제 관리자는 기계 학습 모델 및 실험에 자동 로깅을 사용하도록 설정할 수 있습니다. 이 옵션은 학습 중인 기계 학습 모델의 입력 매개 변수, 출력 메트릭 및 출력 항목의 값을 자동으로 캡처합니다. 자동 로깅에 대해 자세히 알아보세요.

관련 콘텐츠
- Fabric의 Apache Spark 런타임 - 개요, 버전 관리, 다중 런타임 지원 및 Delta Lake 프로토콜 업그레이드에 대해 알아보세요.
- Apache Spark 공개 문서에서 자세히 알아보세요.
- 자주 묻는 질문에 대한 답변은 Apache Spark 작업 영역 관리 설정 FAQ에서 찾아보세요.