Fabric의 Apache Spark 런타임
Microsoft Fabric 런타임은 데이터 엔지니어링 및 데이터 과학 환경을 실행하고 관리할 수 있도록 하는 Apache Spark를 기반으로 하는 Azure 통합 플랫폼입니다. 내부 및 오픈 소스 소스의 주요 구성 요소를 결합하여 고객에게 포괄적인 솔루션을 제공합니다. 간단히 하기 위해 Apache Spark에서 제공하는 Microsoft Fabric 런타임을 Fabric 런타임이라고 합니다.
Fabric 런타임의 주요 구성 요소:
Apache Spark - 대규모 데이터 처리 및 분석 작업을 가능하게 하는 강력한 오픈 소스 분산 컴퓨팅 라이브러리입니다. Apache Spark는 데이터 엔지니어링 및 데이터 과학 환경을 위한 다재다능하고 고성능 플랫폼을 제공합니다.
Delta Lake - Apache Spark에 ACID 트랜잭션 및 기타 데이터 안정성 기능을 제공하는 오픈 소스 스토리지 계층입니다. Fabric 런타임 내에 통합된 Delta Lake는 데이터 처리 기능을 향상시키고 여러 동시 작업에서 데이터 일관성을 보장합니다.
네이티브 실행 엔진 은 Apache Spark 워크로드의 향상된 기능으로, Lakehouse 인프라에서 Spark 쿼리를 직접 실행하여 상당한 성능 향상을 제공합니다. 원활하게 통합되므로 코드를 변경하지 않아도 되며 공급업체 잠금을 방지하여 런타임 1.3(Spark 3.5)의 Apache Spark API에서 Parquet 및 Delta 형식을 모두 지원합니다. 이 엔진은 TPC-DS 1TB 벤치마크에 표시된 것처럼 기존 OSS Spark보다 최대 4배 빠른 쿼리 속도를 향상시켜 운영 비용을 절감하고 데이터 수집, ETL, 분석 및 대화형 쿼리를 비롯한 다양한 데이터 작업에서 효율성을 향상시킵니다. Meta의 Velox 및 Intel의 Apache Gluten을 기반으로 하여 다양한 데이터 처리 시나리오를 처리하면서 리소스 사용을 최적화합니다.
Java/Scala, Python 및 R에 대한 기본 수준 패키지 - 다양한 프로그래밍 언어 및 환경을 지원하는 패키지입니다. 이러한 패키지는 자동으로 설치 및 구성되므로 개발자는 데이터 처리 작업에 기본 프로그래밍 언어를 적용할 수 있습니다.
Microsoft Fabric 런타임은 강력한 오픈 소스 운영 체제를 기반으로 구축되어 다양한 하드웨어 구성 및 시스템 요구 사항과의 호환성을 보장합니다.
아래에서는 Microsoft Fabric 플랫폼 내에서 Apache Spark 기반 런타임에 대해 Apache Spark 버전, 지원되는 운영 체제, Java, Scala, Python, Delta Lake 및 R을 비롯한 주요 구성 요소를 포괄적으로 비교합니다.
팁
현재 런타임 1.3인 프로덕션 워크로드에 대해 항상 가장 최근의 GA 런타임 버전을 사용합니다.
| 런타임 1.1 | 런타임 1.2 | 런타임 1.3 | |
|---|---|---|---|
| 릴리스 단계 | EOSA | 조지아 | 조지아 주 |
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| 운영 체제 | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
런타임 1.1, 런타임 1.2 또는 런타임 1.3을 방문하여 특정 런타임 버전에 대한 세부 정보, 새로운 기능, 개선 사항 및 마이그레이션 시나리오를 살펴봅니다.
Fabric 최적화
Microsoft Fabric에서 Spark 엔진과 Delta Lake 구현 모두 플랫폼별 최적화 및 기능을 통합합니다. 이러한 기능은 플랫폼 내에서 네이티브 통합을 사용하도록 설계되었습니다. 표준 Spark 및 Delta Lake 기능을 구현하려면 이러한 모든 기능을 사용하지 않도록 설정할 수 있습니다. Apache Spark용 Fabric 런타임은 다음을 포함합니다.
- Apache Spark의 전체 오픈 소스 버전입니다.
- 거의 100개의 기본 제공 고유 쿼리 성능 향상의 컬렉션입니다. 이러한 향상된 기능에는 파티션 캐싱(FileSystem 파티션 캐시를 사용하여 메타스토어 호출을 줄일 수 있도록 설정) 및 스칼라 하위 쿼리의 프로젝션에 대한 교차 조인과 같은 기능이 포함됩니다.
- 기본 제공 지능형 캐시입니다.
Apache Spark 및 Delta Lake용 Fabric 런타임 내에는 다음 두 가지 주요 목적을 제공하는 네이티브 작성기 기능이 있습니다.
- 쓰기 작업을 위한 차별화된 성능을 제공하여 쓰기 프로세스를 최적화합니다.
- 기본값은 Delta Parquet 파일의 V 순서 최적화입니다. Delta Lake V-Order 최적화는 모든 Fabric 엔진에서 뛰어난 읽기 성능을 제공하는 데 매우 중요합니다. 작동 방식과 관리 방법을 자세히 이해하려면 Delta Lake 테이블 최적화 및 V-Order에 대한 전용 문서를 참조하세요.
다중 런타임 지원
Fabric은 다중 런타임을 지원하여 사용자에게 원활하게 전환할 수 있는 유연성을 제공하여 비호환성 또는 중단의 위험을 최소화합니다.
기본적으로 모든 새 작업 영역은 현재 런타임 1.3인 최신 런타임 버전을 사용합니다.
작업 영역 수준에서 런타임 버전을 변경하려면 데이터 엔지니어링/과학
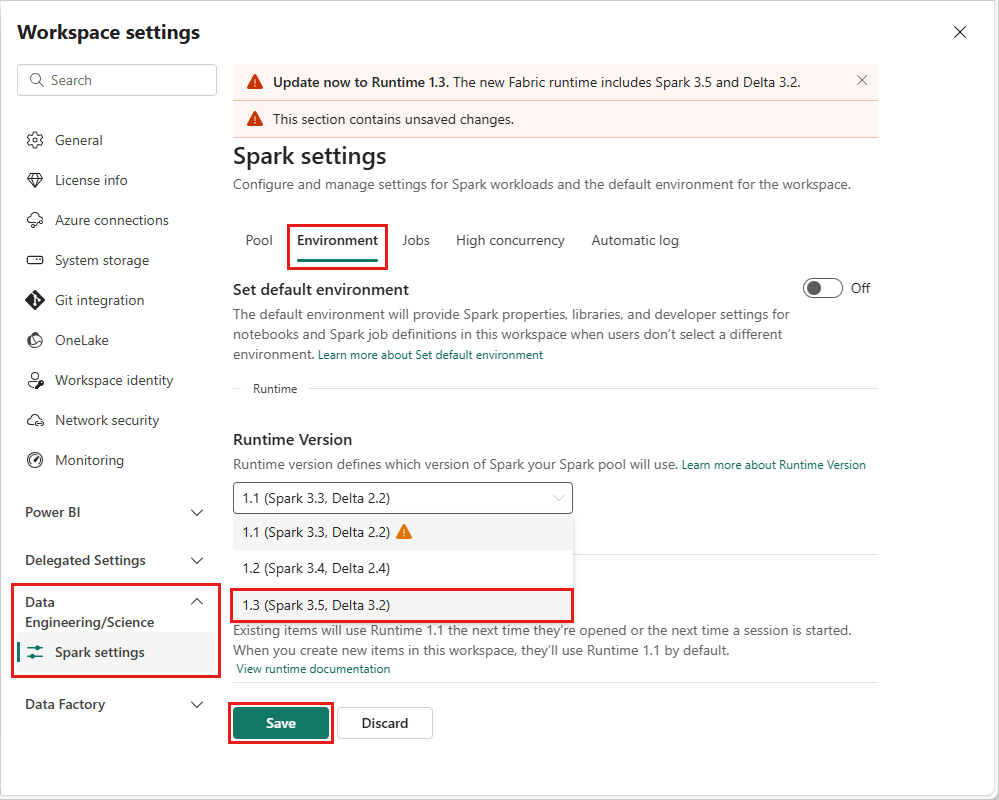
이 변경을 수행하면 Lakehouses, SJD 및 Notebook을 비롯한 작업 영역 내의 모든 시스템 생성 항목은 다음 Spark 세션부터 새로 선택한 작업 영역 수준 런타임 버전을 사용하여 작동합니다. 현재 작업 또는 Lakehouse 관련 작업에 대한 기존 세션이 있는 Notebook을 사용하는 경우 해당 Spark 세션은 그대로 계속됩니다. 그러나 다음 세션 또는 작업부터 선택한 런타임 버전이 적용됩니다.
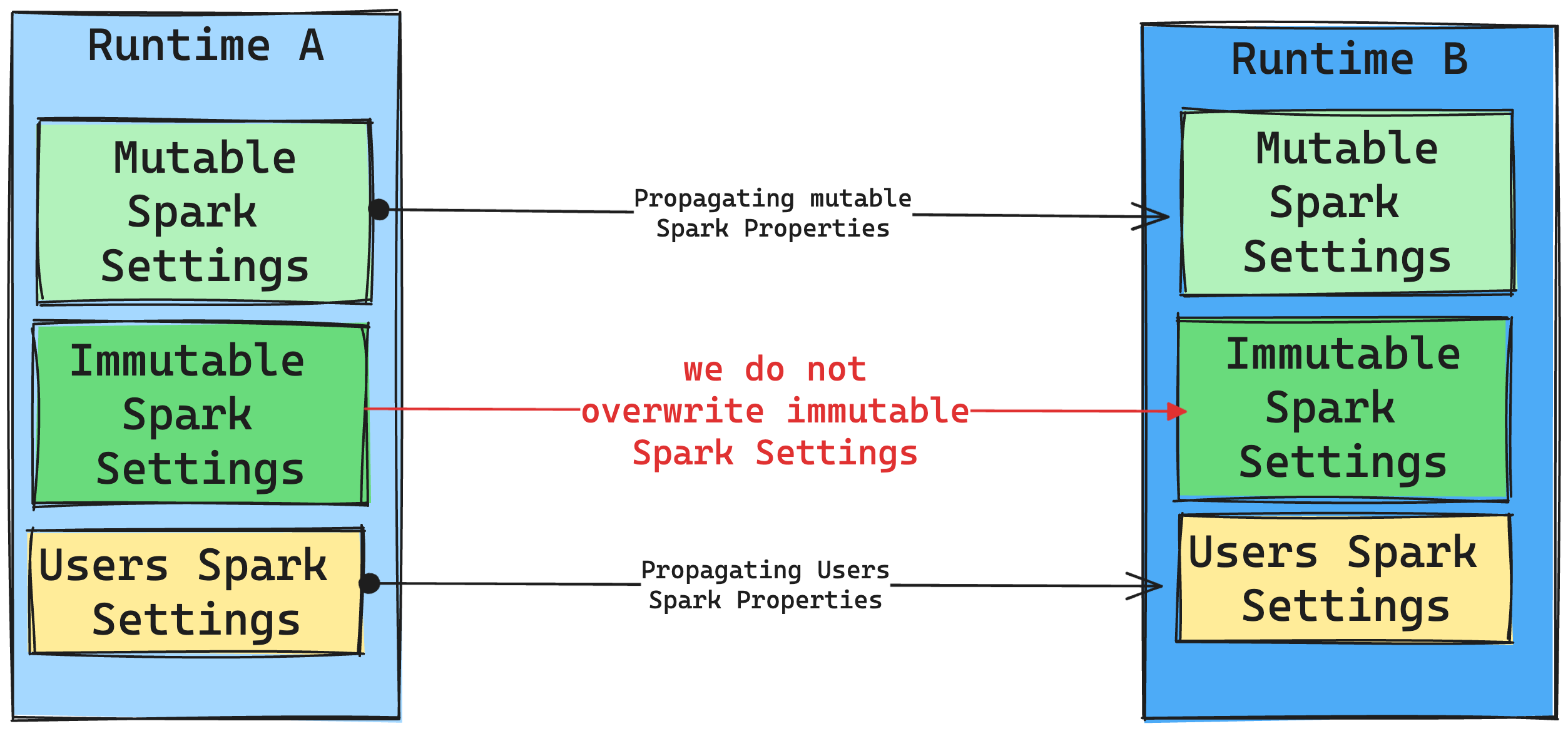
Spark 설정에서 런타임 변경의 결과
일반적으로 모든 Spark 설정을 마이그레이션하는 것을 목표로 합니다. 그러나 Spark 설정이 런타임 B와 호환되지 않는 것으로 확인되면 경고 메시지를 실행하고 설정 구현을 자제합니다.
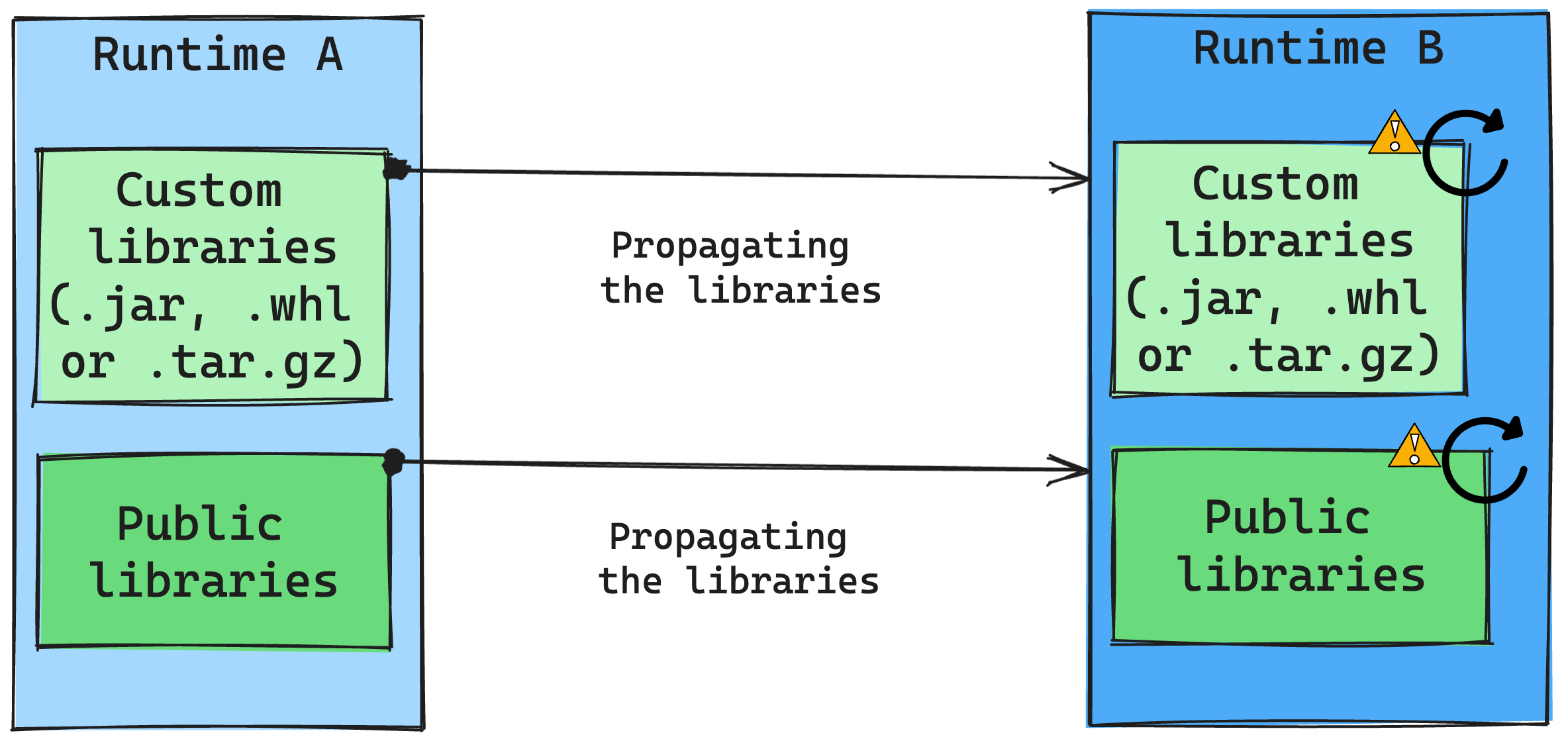
라이브러리 관리에 대한 런타임 변경의 결과
일반적으로 공용 및 사용자 지정 런타임을 포함하여 모든 라이브러리를 런타임 A에서 런타임 B로 마이그레이션하는 것이 좋습니다. Python 및 R 버전이 변경되지 않은 상태로 유지되면 라이브러리가 제대로 작동해야 합니다. 그러나 Jars의 경우 종속성 변경 및 Scala, Java, Spark 및 운영 체제의 변경과 같은 기타 요인으로 인해 작동하지 않을 가능성이 큽니다.
사용자는 런타임 B에서 작동하지 않는 라이브러리를 업데이트하거나 교체할 책임이 있습니다. 충돌이 발생하면 런타임 B에 원래 런타임 A에 정의된 라이브러리가 포함되어 있는 경우 라이브러리 관리 시스템은 사용자의 설정에 따라 런타임 B에 필요한 종속성을 만들려고 합니다. 그러나 충돌이 발생하면 빌드 프로세스가 실패합니다. 오류 로그에서 사용자는 충돌을 일으키는 라이브러리를 확인하고 해당 버전 또는 사양을 조정할 수 있습니다.
Delta Lake 프로토콜 업그레이드
Delta Lake 기능은 항상 이전 버전과 호환되므로 더 낮은 Delta Lake 버전에서 만든 테이블이 상위 버전과 원활하게 상호 작용할 수 있습니다. 그러나 특정 기능을 사용하도록 설정하면(예: delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) 메서드를 사용하여 더 낮은 Delta Lake 버전과의 정방향 호환성이 손상될 수 있음) 이러한 경우 호환성을 유지하는 Delta Lake 버전에 맞게 업그레이드된 테이블을 참조하는 워크로드를 수정해야 합니다.
각 Delta 테이블은 프로토콜 사양과 연결되어 지원되는 기능을 정의합니다. 읽기 또는 쓰기를 위해 테이블과 상호 작용하는 애플리케이션은 이 프로토콜 사양을 사용하여 테이블의 기능 집합과 호환되는지 확인합니다. 애플리케이션이 테이블의 프로토콜에서 지원되는 대로 나열된 기능을 처리할 수 없는 경우 해당 테이블에서 읽거나 쓸 수 없습니다.
프로토콜 사양은 읽기 프로토콜과 쓰기 프로토콜이라는 두 가지 고유한 구성 요소로 나뉩니다. "Delta Lake에서 기능 호환성을 어떻게 관리하나요?" 페이지

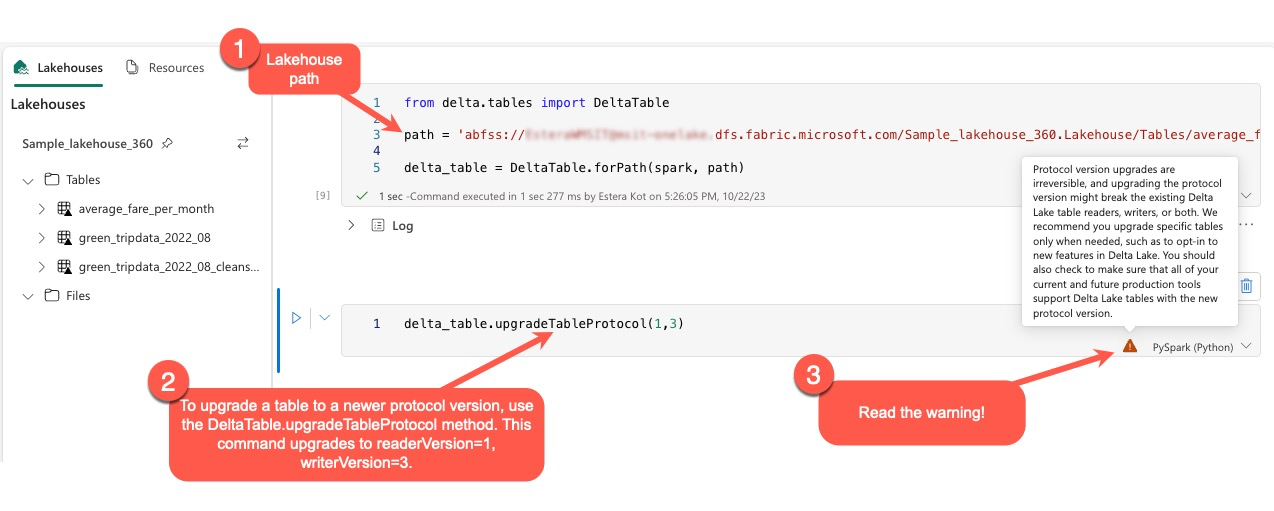
사용자는 PySpark 환경 및 Spark SQL 및 Scala에서 delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) 명령을 실행할 수 있습니다. 이 명령을 사용하면 Delta 테이블에 대한 업데이트를 시작할 수 있습니다.
이 업그레이드를 수행할 때 사용자는 Delta 프로토콜 버전 업그레이드가 되돌릴 수 없는 프로세스임을 나타내는 경고를 수신해야 합니다. 즉, 업데이트가 실행되면 실행 취소할 수 없습니다.
프로토콜 버전 업그레이드는 잠재적으로 기존 Delta Lake 테이블 판독기, 기록기 또는 둘 다의 호환성에 영향을 미칠 수 있습니다. 따라서 Delta Lake에서 새 기능을 채택하는 경우와 같이 필요한 경우에만 신중하게 진행하고 프로토콜 버전을 업그레이드하는 것이 좋습니다.
또한 사용자는 원활한 전환을 보장하고 잠재적인 중단을 방지하기 위해 모든 현재 및 미래의 프로덕션 워크로드 및 프로세스가 새 프로토콜 버전을 사용하여 Delta Lake 테이블과 호환되는지 확인해야 합니다.
Delta 2.2 및 Delta 2.4 변경 내용
최신 Fabric 런타임 버전 1.3 및 Fabric 런타임 버전 1.2에서는 이제 기본 테이블 형식(spark.sql.sources.default) delta이 됩니다. 이전 버전의 Fabric 런타임, 버전 1.1 및 Spark 3.3 이하를 포함하는 Apache Spark용 모든 Synapse 런타임에서 기본 테이블 형식은 parquet과 같이 정의되었습니다. Azure Synapse Analytics와 Microsoft Fabric 간의 차이점에 대한 Apache Spark 구성 세부 정보를 사용하여 테이블을 확인합니다.
테이블 형식을 생략할 때마다 Spark SQL, PySpark, Scala Spark 및 Spark R을 사용하여 만든 모든 테이블은 기본적으로 테이블 delta을 만듭니다. 스크립트가 명시적으로 테이블 형식을 설정하는 경우 해당 형식이 적용됩니다. Spark create table 명령의 USING DELTA 명령은 중복됩니다.
Parquet 테이블 형식을 예상하거나 가정하는 스크립트를 수정해야 합니다. Delta 테이블에서는 다음 명령이 지원되지 않습니다.
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE