Microsoft Fabric에서 시작 풀 구성
이 문서에서는 분석 워크로드에 대해 Microsoft Fabric에서 시작 풀을 사용자 지정하는 방법을 설명합니다. 시작 풀은 몇 초 내에 Microsoft Fabric 플랫폼에서 Spark를 빠르고 쉽게 사용할 수 있는 방법입니다. Spark가 노드를 설정할 때까지 기다리지 않고 바로 Spark 세션을 사용할 수 있으므로 데이터를 사용하여 더 많은 작업을 수행하고 인사이트를 더 빠르게 얻을 수 있습니다.
시작 풀에는 항상 켜져 있고 요청에 대해 준비된 Spark 클러스터가 있습니다. 중간 크기의 노드를 사용하며 워크로드 요구 사항에 따라 확장할 수 있습니다.
데이터 엔지니어링 또는 데이터 과학 워크로드 요구 사항에 따라 자동 크기 조정을 위한 최대 노드를 지정할 수 있습니다. 구성하는 최대 노드 수를 기준으로 작업의 컴퓨팅 요구 사항이 변경됨에 따라 시스템은 노드를 동적으로 획득하고 사용 중지하므로 효율적인 크기 조정 및 성능이 향상됩니다.
또한 시작 풀에서 실행기의 최대 제한을 설정할 수 있으며 동적 할당을 사용하도록 설정하면 시스템은 데이터 볼륨 및 작업 수준 컴퓨팅 요구 사항에 따라 실행기 수를 조정합니다. 이 프로세스를 사용하면 성능 최적화 및 리소스 관리에 대한 걱정 없이 워크로드에 집중할 수 있습니다.
참고 항목
시작 풀을 사용자 지정하려면 작업 영역에 대한 관리자 액세스 권한이 필요합니다.
시작 풀 구성
작업 영역과 연결된 시작 풀을 관리하려면 다음을 수행합니다.
Fabric 작업 영역으로 이동하여 작업 영역 설정을 선택합니다.

그런 다음 데이터 엔지니어링/과학 옵션을 선택하여 메뉴를 확장합니다.
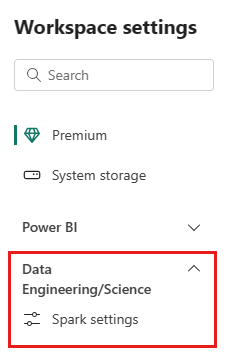
StarterPool 옵션을 선택합니다.
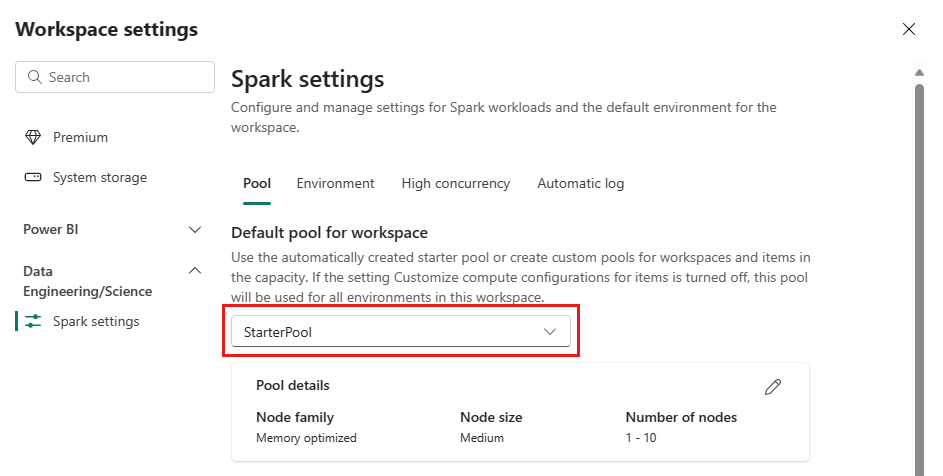
시작 풀의 최대 노드 구성을 구매한 용량에 따라 허용되는 수로 설정하거나 더 작은 워크로드를 실행할 때 기본 최대 노드 구성을 더 작은 값으로 줄일 수 있습니다.
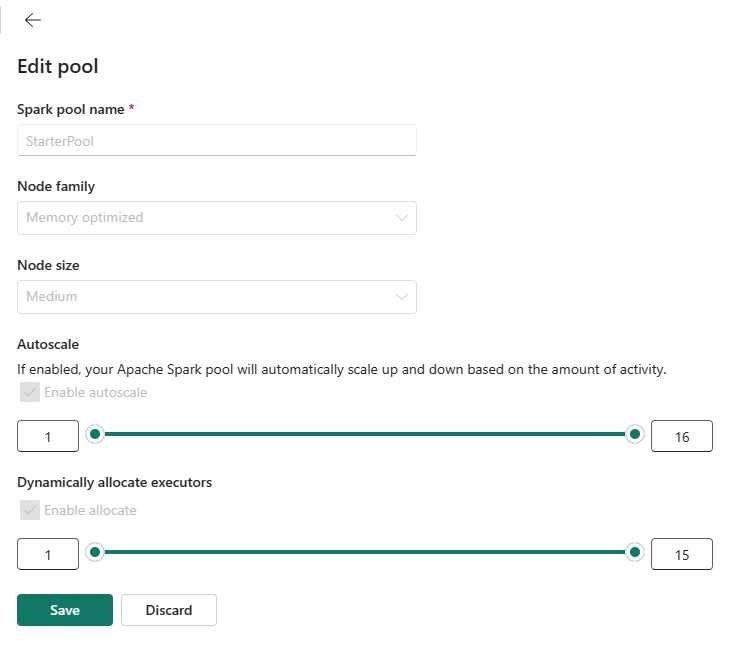

다음 섹션에서는 Microsoft Fabric 용량 SKU를 기반으로 하는 시작 풀에 대해 지원되는 다양한 기본 구성 및 최대 노드 제한을 나열합니다.
| SKU name | 용량 단위 | Spark VCore | 노드 크기 | 기본 최대 노드 수 | 최대 노드 수 |
|---|---|---|---|---|---|
| F2 | 2 | 4 | 중간 | 1 | 1 |
| F4 | 4 | 8 | 중간 | 1 | 1 |
| F8 | 8 | 16 | 중간 | 2 | 2 |
| F16 | 16 | 32 | 중간 | 3 | 4 |
| F32 | 32 | 64 | 중간 | 8 | 8 |
| F64 | 64 | 128 | 중간 | 10 | 16 |
| (평가판 용량) | 64 | 128 | 중간 | 10 | 16 |
| F128 | 128 | 256 | 중간 | 10 | 32 |
| F256 | 256 | 512 | 중간 | 10 | 64 |
| F512 | 512 | 1024 | 중간 | 10 | 128 |
| F1024 | 1024 | 2048 | 중간 | 10 | 200 |
| F2048 | 2048 | 4096 | 중간 | 10 | 200 |
참고 항목
시작 풀을 사용자 지정하려면 작업 영역에 대한 관리자 액세스 권한이 필요합니다.
관련 콘텐츠
- Apache Spark 공개 문서에서 자세히 알아보세요.
- Microsoft Fabric에서 Spark 작업 영역 관리 설정을 시작합니다.