Lakehouse 자습서: Lakehouse에서 데이터 준비 및 변환
이 자습서에서는 Spark 런타임과 함께 Notebook을 사용하여 Lakehouse에서 원시 데이터를 변환하고 준비합니다.
필수 조건
데이터를 포함하는 Lakehouse가 없는 경우 다음을 수행해야 합니다.
데이터 준비
이전 자습서 단계에서는 원본에서 Lakehouse의 Files 섹션으로 원시 데이터를 수집했습니다. 이제 해당 데이터를 변환하고 Delta 테이블을 만들기 위해 준비할 수 있습니다.
Lakehouse 자습서 소스 코드 폴더에서 Notebook을 다운로드합니다.
작업 영역에서 이 컴퓨터에서
Notebook 가져오기 선택합니다. 방문 페이지의 맨 위에 있는 새로운 섹션에서 Notebook 가져오기를 선택합니다.
화면 오른쪽에 열리는 상태 가져오기 창에서 업로드를 선택합니다.
이 섹션의 첫 번째 단계에서 다운로드한 모든 Notebook을 선택합니다.
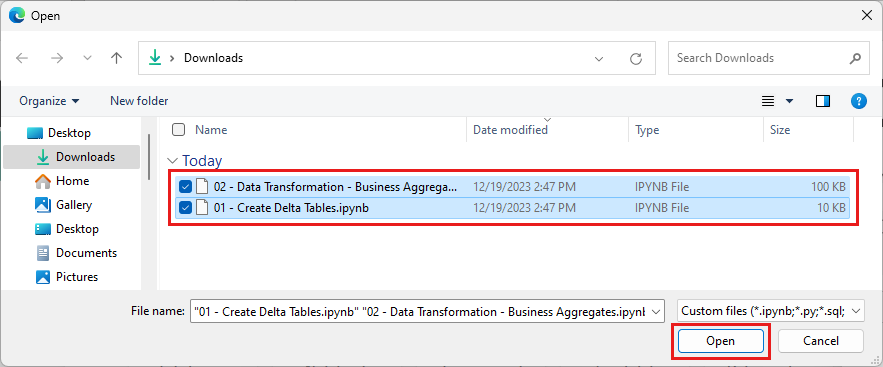
열기를 선택합니다. 가져오기 상태를 나타내는 알림이 브라우저 창의 오른쪽 위 모서리에 표시됩니다.
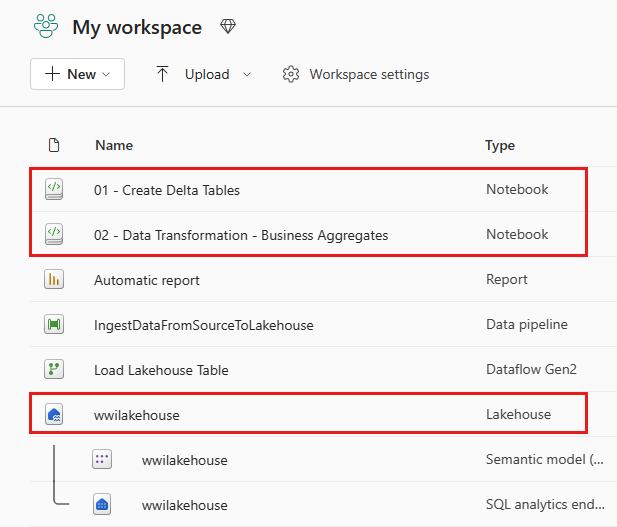
가져오기에 성공하면 작업 영역의 항목 보기로 이동하여 새로 가져온 Notebook을 확인합니다. wwilakehouse Lakehouse를 선택하여 엽니다.
wwilakehouse Lakehouse가 열리면 위쪽 탐색 메뉴에서 Notebook 기존 열기>Notebook를 선택합니다.
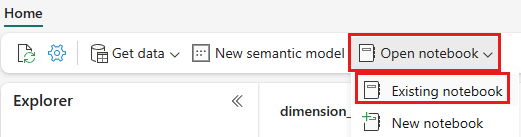
기존 Notebook 목록에서 01 - Delta 테이블 Notebook 만들기를 선택하고 열기를 선택합니다.
Lakehouse 탐색기의 열린 Notebook에서 Notebook이 열려 있는 Lakehouse에 이미 연결되어 있는 것을 볼 수 있습니다.
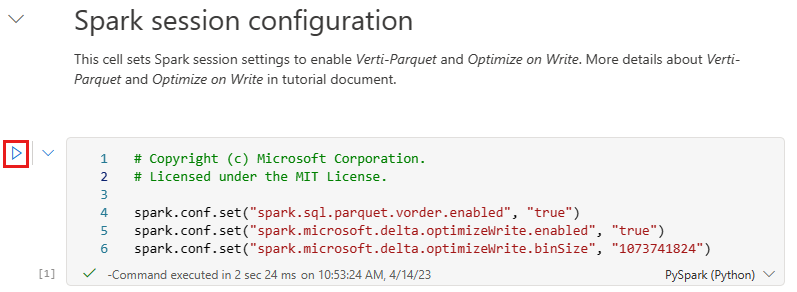
Lakehouse의 테이블 섹션에서 Delta Lake 테이블로 데이터를 작성하기 전에 최적화된 데이터 쓰기 및 향상된 읽기 성능을 위해 두 가지 Fabric 기능(V 순서 및 쓰기 최적화)을 사용합니다. 세션에서 이러한 기능을 사용하도록 설정하려면 Notebook의 첫 번째 셀에서 이러한 구성을 설정합니다.
Notebook을 시작하고 모든 셀을 순서대로 실행하려면 위쪽 리본(홈 아래)에서 모두 실행을 선택합니다. 또는 특정 셀의 코드만 실행하려면 마우스로 가리키면 셀 왼쪽에 표시되는 실행 아이콘을 선택하거나 컨트롤이 셀에 있는 동안 키보드에서 Shift + Enter를 누릅니다.
셀을 실행할 때 Fabric이 라이브 풀을 통해 제공하므로 기본 Spark 풀 또는 클러스터 세부 정보를 지정할 필요가 없었습니다. 모든 Fabric 작업 영역에는 라이브 풀이라는 기본 Spark 풀이 함께 제공됩니다. 즉, Notebook을 만들 때 Spark 구성 또는 클러스터 세부 정보를 지정하는 것에 대해 걱정할 필요가 없습니다. 첫 번째 Notebook 명령을 실행하면 라이브 풀이 몇 초 안에 실행되고 있습니다. 그리고 Spark 세션이 설정되고 코드 실행이 시작됩니다. Spark 세션이 활성 상태인 동안 이 Notebook에서 후속 코드 실행은 거의 즉각적입니다.
다음으로 Lakehouse의 파일 섹션에서 원시 데이터를 읽고 변환의 일부로 다른 날짜 부분에 대한 열을 더 추가합니다. 마지막으로 파티션 By Spark API를 사용하여 데이터를 분할한 후 새로 만든 데이터 파트 열(연도 및 분기)에 따라 Delta 테이블 형식으로 작성합니다.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)팩트 테이블이 로드되면 나머지 차원에 대한 데이터 로드로 이동할 수 있습니다. 다음 셀은 매개 변수로 전달된 각 테이블 이름에 대한 Lakehouse의 Files 섹션에서 원시 데이터를 읽는 함수를 만듭니다. 다음으로 차원 테이블 목록을 만듭니다. 마지막으로 테이블 목록을 반복하고 입력 매개 변수에서 읽은 각 테이블 이름에 대한 Delta 테이블을 만듭니다. 스크립트는 열이 사용되지 않으므로 이 예제에서 명명된
Photo열을 삭제합니다.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)만든 테이블의 유효성을 검사하려면 wwilakehouse Lakehouse에서 마우스 오른쪽 단추를 클릭하고 새로 고침을 선택합니다. 테이블이 나타납니다.
작업 영역의 항목 보기로 다시 이동하여 wwilakehouse Lakehouse를 선택하여 엽니다.
이제 두 번째 Notebook을 엽니다. Lakehouse 보기의 리본에서 Notebook 열기>Notebook 기존를 선택합니다.
기존 Notebook 목록에서 02 - 데이터 변환 - 비즈니스 Notebook을 선택하여 엽니다.
Lakehouse 탐색기의 열린 Notebook에서 Notebook이 열려 있는 Lakehouse에 이미 연결되어 있는 것을 볼 수 있습니다.
조직에는 Scala/Python과 함께 작업하는 데이터 엔지니어와 SQL(Spark SQL 또는 T-SQL)을 사용하는 다른 데이터 엔지니어가 모두 동일한 데이터 복사본에서 작업할 수 있습니다. Fabric을 사용하면 다양한 환경과 선호도를 가진 이러한 다양한 그룹이 작업하고 공동 작업할 수 있습니다. 두 가지 방법은 비즈니스 집계를 변환하고 생성합니다. 적합한 방법을 선택하거나 성능에 영향을 주지 않고 기본 설정에 따라 이러한 방법을 혼합하고 일치시킬 수 있습니다.
접근 방식 #1 - PySpark를 사용하여 비즈니스 집계를 생성하기 위한 데이터를 조인하고 집계합니다. 이 방법은 프로그래밍(Python 또는 PySpark) 배경을 가진 사람에게 더 좋습니다.
접근 방식 #2 - Spark SQL을 사용하여 비즈니스 집계를 생성하기 위한 데이터를 조인하고 집계합니다. 이 방법은 SPARK로 전환하면서 SQL 배경을 가진 사람에게 선호됩니다.
접근 방식 #1(sale_by_date_city) - PySpark를 사용하여 비즈니스 집계를 생성하기 위한 데이터를 조인하고 집계합니다. 다음 코드를 사용하여 각각 기존 Delta 테이블을 참조하는 세 가지 Spark 데이터 프레임을 만듭니다. 그런 다음 데이터 프레임을 사용하여 이러한 테이블을 조인하고, 그룹화하여 집계를 생성하고, 몇 개의 열 이름을 바꾸고, 마지막으로 Lakehouse의 테이블 섹션에서 Delta 테이블로 작성하여 데이터를 유지합니다.
이 셀에서는 각각 기존 Delta 테이블을 참조하는 세 가지 Spark 데이터 프레임을 만듭니다.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")이전에 만든 데이터 프레임을 사용하여 이러한 테이블을 조인하려면 동일한 셀에 다음 코드를 추가합니다. 그룹화하여 집계를 생성하고, 몇 개의 열 이름을 바꾸고, 마지막으로 Lakehouse의 테이블 섹션에서 Delta 테이블로 작성합니다.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")접근 방식 #2(sale_by_date_employee) - Spark SQL을 사용하여 비즈니스 집계를 생성하기 위한 데이터를 조인하고 집계합니다. 다음 코드를 사용하면 세 개의 테이블을 조인하여 임시 Spark 뷰를 만들고, 그룹화하여 집계를 생성하고, 일부 열의 이름을 바꿉니다. 마지막으로 임시 Spark 뷰에서 읽고 마지막으로 Lakehouse의 테이블 섹션에서 Delta 테이블로 작성하여 데이터를 유지합니다.
이 셀에서는 세 개의 테이블을 조인하여 임시 Spark 뷰를 만들고, 그룹화하여 집계를 생성하고, 일부 열의 이름을 바꿉니다.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC이 셀에서는 이전 셀에서 만든 임시 Spark 뷰를 읽고 마지막으로 Lakehouse의 테이블 섹션에서 Delta 테이블로 작성합니다.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")만든 테이블의 유효성을 검사하려면 wwilakehouse Lakehouse에서 마우스 오른쪽 단추를 클릭하고 새로 고침을 선택합니다. 집계 테이블이 나타납니다.
두 가지 방법은 비슷한 결과를 생성합니다. 새로운 기술을 배우거나 성능에 대한 타협을 배울 필요성을 최소화하려면 배경과 기본 설정에 가장 적합한 접근 방식을 선택합니다.
데이터를 Delta Lake 파일로 작성하는 것을 알 수 있습니다. Fabric의 자동 테이블 검색 및 등록 기능은 이를 선택하고 메타스토어에 등록합니다. SQL과 함께 사용할 테이블을 만들기 위해 명시적으로 CREATE TABLE 문을 호출 할 필요가 없습니다.