Azure HDInsight Spark 클러스터에서 Microsoft Cognitive 도구 키트 심층 학습 모델 사용
이 문서에서는 다음 단계를 수행합니다.
사용자 지정 스크립트를 실행하여 Azure HDInsight Spark 클러스터에 Microsoft Cognitive Toolkit를 설치합니다.
Apache Spark 클러스터에 Jupyter Notebook을 업로드하여 Spark Python API(PySpark)를 통해 Azure Blob Storage 계정의 파일에 학습된 Microsoft Cognitive Toolkit 딥러닝 모델을 적용하는 방법을 확인합니다.
필수 조건
HDInsight의 Apache Spark. Apache Spark 클러스터 만들기를 참조하세요.
HDInsight의 Spark에서 Jupyter Notebook을 사용하는 방법 이해. 자세한 내용은 HDInsight의 Apache Spark로 데이터 로드 및 쿼리 실행을 참조하세요.
이 솔루션을 전달하는 방법
이 솔루션은 이 문서와 이 문서의 일부로 업로드하는 Jupyter Notebook으로 분할되어 있습니다. 이 문서에서는 다음 단계를 완료합니다.
- HDInsight Spark 클러스터에서 스크립트 동작을 실행하여 Microsoft Cognitive 도구 키트 및 Python 패키지를 설치합니다.
- 솔루션을 실행하는 Jupyter Notebook을 HDInsight Spark 클러스터에 업로드합니다.
다음의 나머지 단계에서는 Jupyter Notebook에서 설명합니다.
- Spark RDD(Resilient Distributed Dataset)에 샘플 이미지 로드
- 모듈 로드 및 사전 설정 정의
- Spark 클러스터에서 로컬로 데이터 세트 다운로드
- 데이터 세트를 RDD로 변환
- 학습된 Cognitive 도구 키트 모델을 사용하여 이미지 점수 매기기
- Spark 클러스터에 학습된 Cognitive 도구 키트 모델 다운로드
- 작업자 노드에서 사용할 함수 정의
- 작업자 노드에서 이미지 점수 매기기
- 모델 정확도 평가
Microsoft Cognitive 도구 키트 설치
스크립트 동작을 사용하여 Spark 클러스터에 Microsoft Cognitive 도구 키트를 설치할 수 있습니다. 스크립트 작업은 사용자 지정 스크립트를 사용하여 기본적으로 사용할 수 없는 클러스터에 구성 요소를 설치합니다. HDInsight .NET SDK 또는 Azure PowerShell을 사용하여 Azure Portal에서 사용자 지정 스크립트를 사용할 수 있습니다. 또한 스크립트를 사용하여 클러스터 만들기의 일부로 또는 클러스터가 작동하여 실행된 후에 도구 키트를 설치할 수 있습니다.
이 문서에서는 클러스터를 만든 후에 포털을 사용하여 도구 키트를 설치합니다. 사용자 지정 스크립트를 실행하는 다른 방법은 스크립트 동작을 사용하여 HDInsight 클러스터 사용자 지정을 참조하세요.
Azure 포털 사용하기
Azure Portal을 사용하여 스크립트 동작을 실행하는 방법에 대한 지침은 스크립트 동작을 사용하여 HDInsight 클러스터 사용자 지정을 참조하세요. Microsoft Cognitive 도구 키트를 설치하려면 다음 입력을 제공해야 합니다. 스크립트 동작에는 다음 값을 사용합니다.
| 속성 | 값 |
|---|---|
| 스크립트 유형 | - 사용자 지정 |
| 이름 | MCT 설치 |
| Bash 스크립트 URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| 노드 유형: | 헤드, 작업자 |
| 매개 변수 | 없음 |
Azure HDInsight Spark 클러스터에 Jupyter Notebook 업로드
Azure HDInsight Spark 클러스터에서 Microsoft Cognitive 도구 키트를 사용하려면 Azure HDInsight Spark 클러스터에 CNTK_model_scoring_on_Spark_walkthrough.ipynb Jupyter Notebook을 로드해야 합니다. 이 노트북은 GitHub의 https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration에서 제공합니다.
https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration을 다운로드하고 압축 해제합니다.
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/jupyter로 이동합니다. 여기서CLUSTERNAME은 클러스터의 이름입니다.Jupyter Notebook의 오른쪽 위 모서리에서 업로드를 선택하고 다운로드로 이동하여
CNTK_model_scoring_on_Spark_walkthrough.ipynb파일을 선택합니다.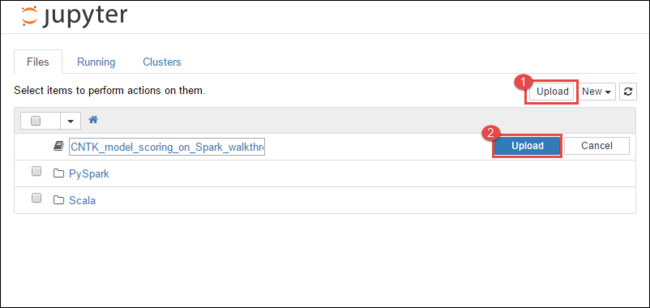
업로드를 다시 선택합니다.
노트북을 업로드한 후 노트북의 이름을 클릭한 다음, 데이터 세트를 로드하고 문서를 수행하는 방법에 대한 노트북 자체의 지침을 따릅니다.
참고 항목
시나리오
- BI와 Apache Spark: BI 도구와 함께 HDInsight의 Spark를 사용하여 대화형 데이터 분석 수행
- Machine Learning과 Apache Spark: HVAC 데이터를 사용하여 건물 온도를 분석하는 데 HDInsight의 Spark 사용
- Machine Learning과 Apache Spark: HDInsight의 Spark를 사용하여 식품 검사 결과 예측
- HDInsight의 Apache Spark를 사용한 웹 사이트 로그 분석
- HDInsight의 Apache Spark를 사용한 Application Insight 원격 분석 데이터 분석
애플리케이션 만들기 및 실행
도구 및 확장
- IntelliJ IDEA용 HDInsight 도구 플러그 인을 사용하여 Spark Scala 애플리케이션 만들기 및 제출
- IntelliJ IDEA용 HDInsight 도구 플러그 인을 사용하여 Apache Spark 애플리케이션을 원격으로 디버그
- HDInsight에서 Apache Spark 클러스터와 함께 Apache Zeppelin Notebook 사용
- HDInsight의 Apache Spark 클러스터에서 Jupyter Notebook에 사용할 수 있는 커널
- Jupyter Notebook에서 외부 패키지 사용
- 컴퓨터에 Jupyter를 설치하고 HDInsight Spark 클러스터에 연결