Apache Spark MLlib을 사용하여 Machine Learning 애플리케이션 빌드 및 데이터 세트 분석
Apache Spark MLlib을 사용하여 Machine Learning 애플리케이션을 만드는 방법에 대해 알아봅니다. 애플리케이션은 공개 데이터 세트에 대한 예측 분석을 수행합니다. Spark의 기본 제공 Machine Learning 라이브러리에서 이 예제는 로지스틱 회귀를 통해 분류를 사용합니다.
MLlib은 다음과 같이 Machine Learning 작업에 유용한 여러 유틸리티를 제공하는 코어 Spark 라이브러리입니다.
- 분류
- 회귀
- Clustering
- 모델링
- SVD(특이값 분해) 및 PCA(주성분 분석)
- 가설 테스트 및 샘플 통계 계산
분류 및 로지스틱 회귀의 이해
널리 사용되는 Machine Learning 작업인 분류는 입력 데이터를 범주로 정렬하는 프로세스입니다. “레이블”을 사용자가 제공하는 입력 데이터에 할당하는 방법을 파악하는 분류 알고리즘 작업입니다. 예를 들어, 주식 정보를 입력으로 받아들이는 Machine Learning 알고리즘을 생각할 수 있습니다. 그런 다음, 주식을 팔아야 할 주식과 보유해야 할 주식 두 가지로 나눕니다.
로지스틱 회귀는 분류에 사용되는 알고리즘입니다. Spark의 로지스틱 회귀 API는 이진 분류또는 입력 데이터를 두 그룹 중 하나로 분류하는 데 유용합니다. 로지스틱 회귀에 대한 자세한 내용은 Wikipedia를 참조하세요.
요약하면 로지스틱 회귀 프로세스는 로지스틱 함수를 생성합니다. 함수를 사용하여 입력 벡터가 한 그룹 또는 다른 그룹에 속할 가능성을 예측합니다.
식품 검사 데이터의 예측 분석 예
이 예제에서는 Spark를 사용하여 식품 검사 데이터(Food_Inspections1.csv)에 대한 몇 가지 예측 분석을 수행합니다. City of Chicago 데이터 포털를 통해 얻은 데이터입니다. 이 데이터 세트는 시카고에서 수행된 식품 시설 검사에 대한 정보를 포함합니다. 각 시설에 대한 정보, 발견된 위반 사항(있는 경우) 및 검사 결과를 포함합니다. CSV 데이터 파일은 /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv에 있는 클러스터와 연결된 스토리지 계정에서 이미 사용할 수 있습니다.
다음 단계에서는 식품 검사를 통과하거나 실패하는 데 필요한 사항을 확인하는 모델을 개발합니다.
Apache Spark MLlib 기계 학습 앱 만들기
PySpark 커널을 사용하여 Jupyter Notebook을 만듭니다. 지침은 Jupyter Notebook 파일 만들기를 참조하세요.
이 애플리케이션에 필요한 형식을 가져옵니다. 다음 코드를 복사하여 빈 셀에 붙여넣은 다음, SHIFT + ENTER를 누릅니다.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *PySpark 커널로 인해 컨텍스트를 명시적으로 만들 필요가 없습니다. 첫 번째 코드 셀을 실행하면 Spark 및 Hive 컨텍스트가 자동으로 만들어집니다.
입력 데이터 프레임 구축
Spark 컨텍스트를 사용하여 원시 CSV 데이터를 메모리에 구조화되지 않은 텍스트로 끌어옵니다. 그런 다음 Python의 CSV 라이브러리를 사용하여 데이터의 각 줄을 구문 분석합니다.
다음 줄을 실행하여 입력 데이터를 가져오고 구문 분석하여 RDD(복원 분산 데이터 세트)를 만듭니다.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)다음 코드를 실행하여 RDD에서 한 행을 검색하면 데이터 스키마의 모양을 살펴볼 수 있습니다.
inspections.take(1)출력은 다음과 같습니다.
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]출력을 보면 입력 파일의 스키마를 알 수 있습니다. 여기에는 모든 시설의 이름 및 시설의 유형이 포함되어 있습니다. 또한, 주소, 검사 데이터 및 위치 등 여러 가지가 있습니다.
다음 코드를 실행하여 예측 분석에 유용한 몇 개 열이 포함된 데이터 프레임(df) 및 임시 테이블(CountResults)을 만듭니다.
sqlContext는 구조화된 데이터에서 변환을 수행하는 데 사용할 수 있습니다.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')데이터 프레임에서 관심이 있는 네 개의 열은 ID, name, results 및 violations입니다.
다음 코드를 실행하여 데이터의 작은 예제를 가져옵니다.
df.show(5)출력은 다음과 같습니다.
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
데이터 이해
데이터 세트에 무엇이 들어 있는지 알아보겠습니다.
다음 코드를 실행하여 results 열에 고유 값을 표시합니다.
df.select('results').distinct().show()출력은 다음과 같습니다.
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+다음 코드를 실행하여 이러한 결과의 분포를 시각화합니다.
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY results-o countResultsdf앞의%%sql매직은 쿼리 출력이 Jupyter 서버(일반적으로 클러스터의 헤드 노드)에서 로컬로 유지되도록 합니다. 출력은 countResultsdf 라는 이름이 지정된 Pandas데이터 프레임으로 유지됩니다.%%sql매직 및 PySpark 커널에서 사용 가능한 기타 매직에 대한 자세한 내용은 Apache Spark HDInsight 클러스터와 함께 Jupyter Notebook에서 사용 가능한 커널을 참조하세요.출력은 다음과 같습니다.
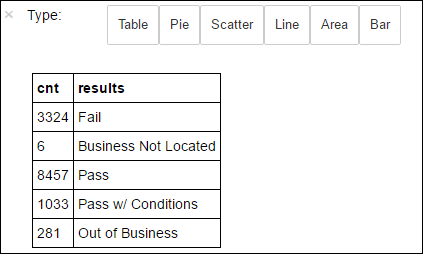
또한 데이터 시각화를 구성하는 데 사용되는 라이브러리인 Matplotlib를 사용하여 플롯을 만들 수 있습니다. 로컬로 유지되는 countResultsdf 데이터 프레임에서 플롯을 만들어야 하므로 코드 조각은
%%local매직으로 시작해야 합니다. 이렇게 하면 코드가 Jupyter 서버에서 로컬로 실행됩니다.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')음식 검사 결과를 예측하려면 위반을 기반으로 모델을 개발해야 합니다. 로지스틱 회귀는 이진 분류 방법이므로 결과 데이터를 두 가지 범주, 즉 불합격 및 합격으로 그룹화할 수 있습니다.
합격
- 합격
- 조건부 합격
실패
- 실패
취소
- 회사를 찾을 수 없음
- 폐업
결과가 다른 데이터(“회사를 찾을 수 없음” 또는 “폐업”)는 유용하지 않으며, 어찌됐건 결과의 작은 비율을 구성합니다.
다음 코드를 실행하여 기존 데이터 프레임(
df)을 각 검사가 레이블-위반 쌍으로 표시되는 새 데이터 프레임으로 변환합니다. 이 예에서0.0의 레이블은 불합격,1.0의 레이블은 합격,-1.0의 레이블은 앞의 두 결과를 제외한 기타 결과를 나타냅니다.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')다음 코드를 실행하여 레이블이 지정된 데이터의 한 행을 표시합니다.
labeledData.take(1)출력은 다음과 같습니다.
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
입력 데이터 프레임으로 로지스틱 회귀 모델 만들기
마지막 작업은 레이블이 지정된 데이터를 변환하는 것입니다. 데이터를 로지스틱 회귀로 분석된 형식으로 변환합니다. 로지스틱 회귀 알고리즘에 대한 입력에는 레이블 기능 벡터 쌍 세트가 필요합니다. 여기서 “기능 벡터"는 입력 지점을 나타내는 숫자의 벡터입니다. 따라서 반구조화되고 자유 텍스트의 많은 주석을 포함하는 "위반" 열을 변환해야 합니다. 컴퓨터가 쉽게 이해할 수 있는 실제 숫자 배열로 열을 변환합니다.
자연어를 처리하는 한 가지 표준 기계 학습 방법은 각각의 고유한 단어를 인덱스에 할당하는 것입니다. 그런 다음, Machine Learning 알고리즘에 벡터를 전달합니다. 각 인덱스 값이 텍스트 문자열에서 해당 단어의 상대 빈도를 포함하도록 합니다.
MLlib은 이 작업을 간단하게 수행할 수 있는 방법을 제공합니다. 첫째, 각 문자열에서 개별 단어를 가져오기 위해 각 위반 문자열을 "토큰화"합니다. 그런 다음 HashingTF을 사용하여 모델을 생성하는 로지스틱 회귀 알고리즘에 전달될 수 있는 기능 벡터로 각 토큰 집합을 변환합니다. 파이프라인를 사용하여 이 모든 단계를 차례로 수행합니다.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
다른 데이터 세트를 사용하여 모델 평가
앞서 만든 모델을 사용하여 새 검사의 결과를 예측할 수 있습니다. 예측은 관찰된 위반을 기반으로 합니다. Food_Inspections1.csv 데이터 세트에서 이 모델을 학습했습니다. 두 번째 데이터 세트인 Food_Inspections2.csv를 사용하여 새 데이터에서 이 모델의 강도를 평가할 수 있습니다. 이 두 번째 데이터 세트(Food_Inspections2.csv)은 클러스터와 연결된 기본 스토리지 컨테이너에 있습니다.
다음 코드를 실행하여 모델에서 생성한 예측을 포함하는 새 데이터 프레임 predictionsDf를 만듭니다. 이 조각은 데이터 프레임을 기반으로 Predictions라는 임시 테이블도 만듭니다.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columns다음 텍스트와 같은 출력이 표시됩니다.
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']예측 중 하나를 살펴보겠습니다. 이 코드 조각을 실행합니다.
predictionsDf.take(1)테스트 데이터 세트에 첫 번째 항목에 대한 예측이 있습니다.
model.transform()메서드는 스키마가 같은 모든 새 데이터에 동일한 변환 방법을 적용하여 데이터 분류 방법에 대한 예측에 도달합니다. 몇 가지 통계를 수행하여 예측이 어떠한지 알아볼 수 있습니다.numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")출력은 다음 텍스트와 비슷합니다.
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateSpark에서 로지스틱 회귀를 사용하면 위반 설명 간의 관계에 대한 모델이 영어로 제공됩니다. 지정된 비즈니스에서 식품 검사를 통과하거나 실패하는지 여부를 지정합니다.
예측의 시각적 표현 만들기
이제 이 테스트 결과의 이유를 파악하는 데 도움이 되는 최종 시각화를 만들 수 있습니다.
먼저 이전에 만든 Predictions 임시 테이블에서 여러 예측 및 결과를 추출합니다. 다음 쿼리는 출력을 true_positive, false_positive, true_negative 및 false_negative로 구분합니다. 아래 쿼리에서는
-q를 사용하여 시각화를 해제하고%%local매직에서 사용할 수 있는 데이터 프레임으로 출력을 저장(-o를 사용하여)합니다.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')마지막으로, 다음 조각을 사용하여 Matplotlib를 통해 플롯을 생성합니다.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')다음과 같은 출력이 표시됩니다.
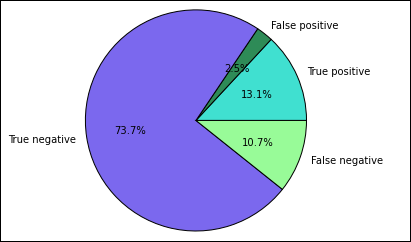
이 차트에서 "긍정" 결과는 불합격한 음식 검사를 참조하는 반면, 부정 결과는 합격한 검사를 참조합니다.
Notebook 종료
애플리케이션을 실행한 후 리소스를 해제하려면 Notebook을 종료해야 합니다. 이렇게 하기 위해 Notebook의 파일 메뉴에서 닫기 및 중지를 선택합니다. 그러면 Notebook이 종료된 후 닫힙니다.