Azure HDInsight에서 Apache Spark 클러스터용 리소스 관리
Apache Ambari UI, Apache Hadoop YARN UI 및 Apache Spark 클러스터와 관련된 Spark 기록 서버와 같은 인터페이스에 액세스하는 방법과 최적의 성능을 위해 클러스터 구성을 튜닝하는 방법을 알아봅니다.
Spark 기록 서버 열기
Spark 기록 서버는 완료되고 실행되는 Spark 애플리케이션의 웹 UI입니다. Spark 웹 UI의 확장입니다. 전체 정보는 Spark 기록 서버를 참조하세요.
Yarn UI 열기
YARN UI를 사용하여 현재 Spark 클러스터에서 실행 중인 애플리케이션을 모니터링할 수 있습니다.
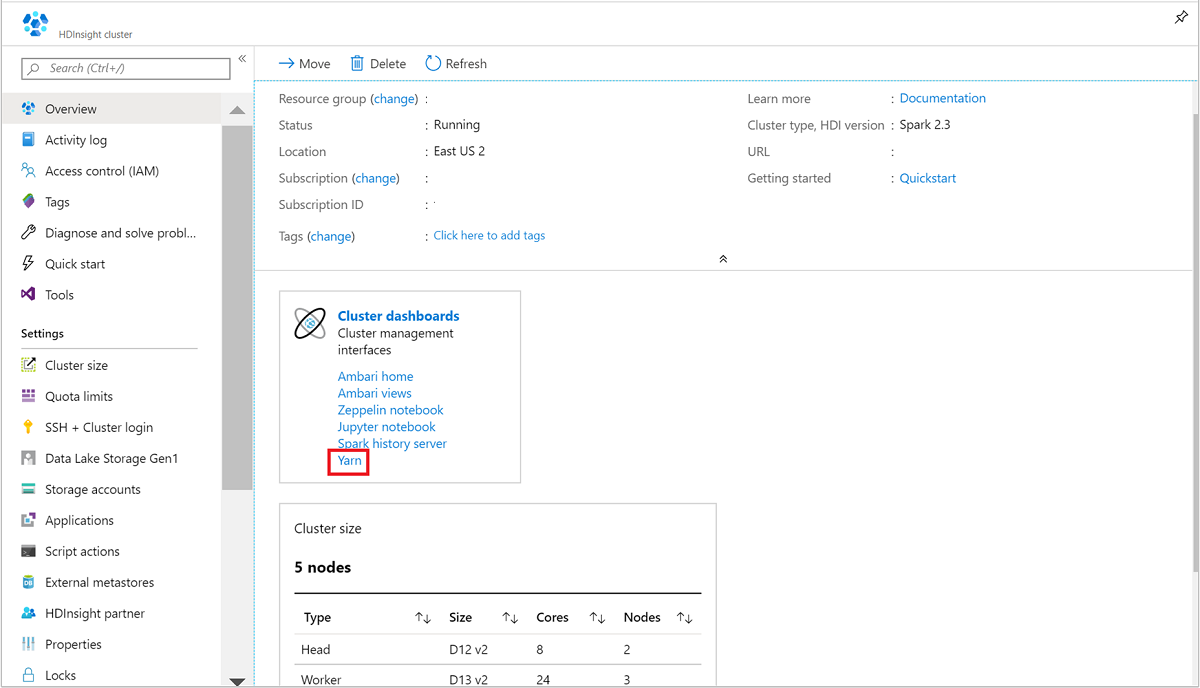
Azure Portal에서 Spark 클러스터를 엽니다. 자세한 내용은 클러스터 나열 및 표시를 참조하세요.
클러스터 대시보드에서 Yarn을 선택합니다. 메시지가 표시되면 Spark 클러스터에 대한 관리자 자격 증명을 입력합니다.
팁
또는 Ambari UI에서 YARN UI를 시작할 수도 있습니다. Ambari UI에서 YARN>빠른 링크>활성>Resource Manager UI로 이동합니다.
Spark 애플리케이션에 대해 클러스터 최적화
애플리케이션 요구 사항에 따라 Spark 구성에 사용할 수 있는 세 가지 주요 매개 변수는 spark.executor.instances, spark.executor.cores 및 spark.executor.memory입니다. 실행자는 Spark 애플리케이션을 위해 시작된 프로세스입니다. 작업자 노드에서 실행되며 애플리케이션에 대한 작업을 수행해야 합니다. 각 클러스터에 대한 실행자 및 실행자 크기의 기본 수는 작업자 노드 및 작업자 노드 크기의 수에 기반하여 계산됩니다. 이 정보는 클러스터 헤드 노드의 spark-defaults.conf에 저장됩니다.
세 가지 구성 매개 변수는 (클러스터에서 실행된는 모든 애플리케이션의 경우) 클러스터 수준에서 구성될 수 있거나 각 개별 애플리케이션에 대해 지정될 수 있습니다.
Ambari UI를 사용하여 매개 변수 변경
Ambari UI에서 Spark 2>Configs>Custom spark2-defaults로 이동합니다.
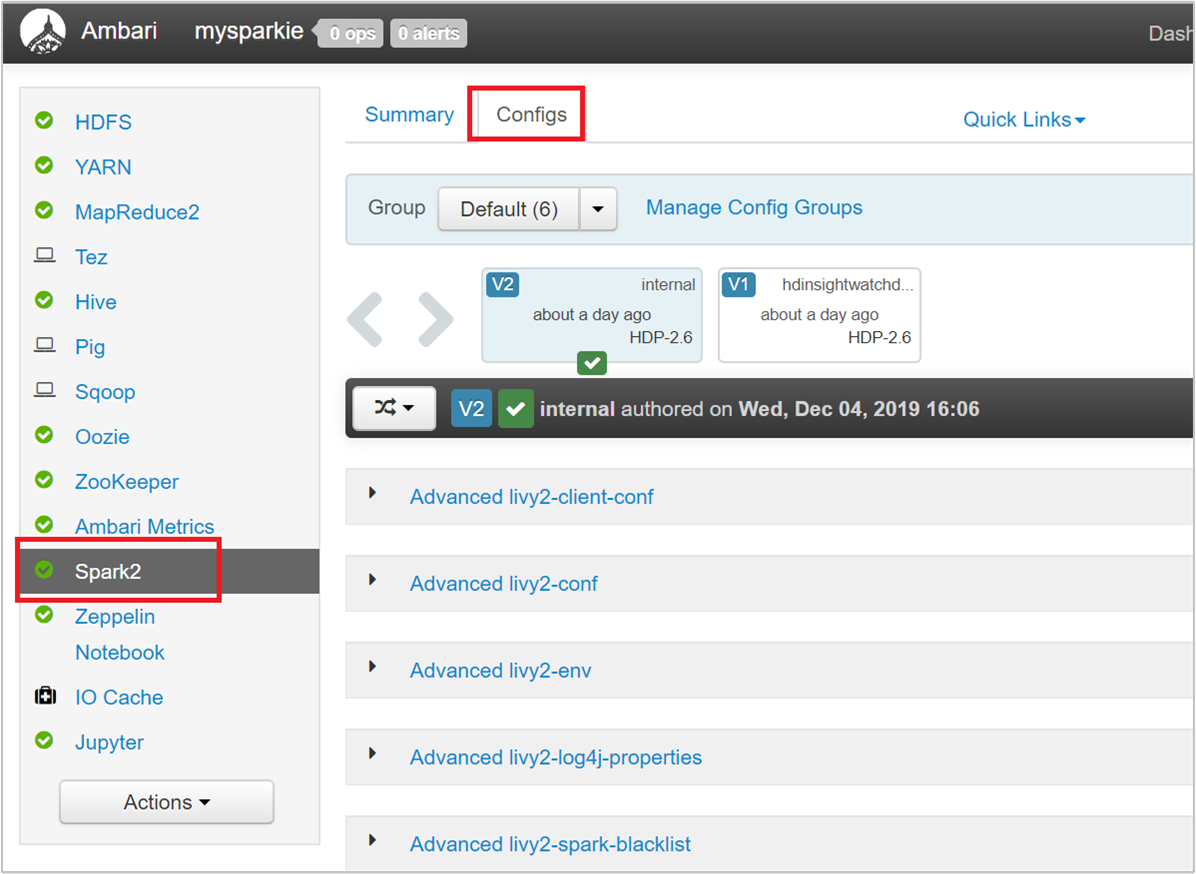
기본값으로 Spark 클러스터에서 4개의 애플리케이션을 동시에 실행할 수 있습니다. 다음 스크린샷에 표시된 대로 사용자 인터페이스에서 이러한 값을 변경할 수 있습니다.
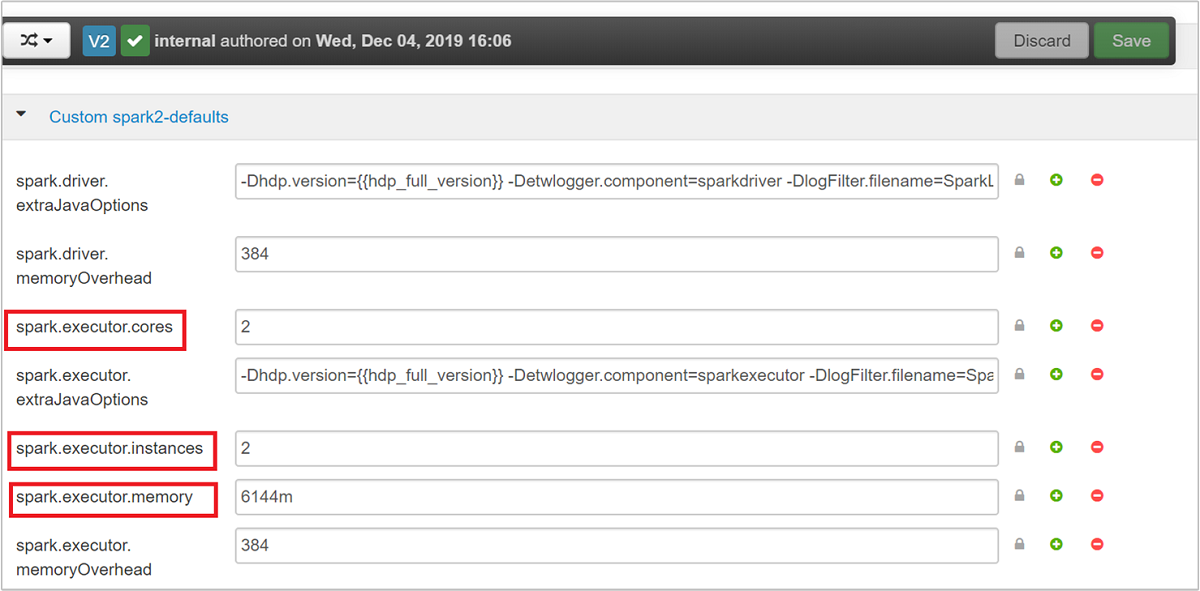
저장을 선택하여 구성 변경을 저장합니다. 페이지 맨 위에 모든 영향을 받는 서비스를 다시 시작하라는 메시지가 표시됩니다. 다시 시작을 선택합니다.
Jupyter Notebook에서 실행 중인 애플리케이션에 대한 매개 변수 변경
Jupyter Notebook에서 실행 중인 애플리케이션의 경우 %%configure 매직을 사용하여 구성을 변경할 수 있습니다. 이상적으로 첫 번째 코드 셀을 실행하기 전에 애플리케이션의 시작 부분에 이를 변경해야 합니다. 이렇게 하면 구성이 생성된 경우 Livy 세션에 적용됩니다. 애플리케이션의 이후 단계에서 구성을 변경하려는 경우 -f 매개 변수를 사용해야 합니다. 그러나 이렇게 하면 애플리케이션의 모든 진행률이 손실됩니다.
다음 코드 조각에서는 Jupyter에서 실행 중인 애플리케이션에 대한 구성을 변경하는 방법을 보여줍니다.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
구성 매개 변수는 JSON 문자열로 전달되어야 하며, 아래 예제 열과 같이 매직 뒤의 다음 줄에 있어야 합니다.
spark-submit를 사용하여 제출된 애플리케이션에 대한 매개 변수 변경
다음 명령은 spark-submit을 사용하여 제출된 배치 애플리케이션에 대한 구성 매개 변수를 변경하는 방법의 예제입니다.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
cURL을 사용하여 제출된 애플리케이션에 대한 매개 변수 변경
다음 명령은 cURL을 사용하여 제출된 배치 애플리케이션에 대한 구성 매개 변수를 변경하는 방법의 예제입니다.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
참고 항목
JAR 파일을 클러스터 스토리지 계정에 복사합니다. JAR 파일을 헤드 노드에 직접 복사하지 마십시오.
Spark Thrift 서버에서 이러한 매개 변수 변경
Spark Thrift 서버에서는 Spark 클러스터에 대한 JDBC/ODBC 액세스를 제공하고 Spark SQL 쿼리를 제공하는 데 사용됩니다. Power BI, Tableau 등의 도구는 ODBC 프로토콜을 사용하여 Spark SQL 쿼리를 Spark 애플리케이션으로 실행하기 위해 Spark Thrift 서버와 통신합니다. Spark 클러스터를 만들 경우 Spark Thrift 서버에서 각 헤드 노드에 하나씩 두 개의 인스턴스를 시작합니다. 각 Spark Thrift 서버는 YARN UI에서 Spark 애플리케이션으로 표시됩니다.
Spark Thrift 서버는 Spark 동적 실행자 할당을 사용하며 따라서 spark.executor.instances를 사용하지 않습니다. 대신 Spark Thrift 서버는 spark.dynamicAllocation.maxExecutors 및 spark.dynamicAllocation.minExecutors을 사용하여 실행자 수를 지정합니다. 구성 매개 변수 spark.executor.cores 및 spark.executor.memory를 사용하여 실행자 크기를 수정합니다. 다음 단계와 같이 이러한 매개 변수를 변경할 수 있습니다.
고급 spark2-thrift-sparkconf 범주를 확장하여
spark.dynamicAllocation.maxExecutors및spark.dynamicAllocation.minExecutors매개 변수를 업데이트합니다.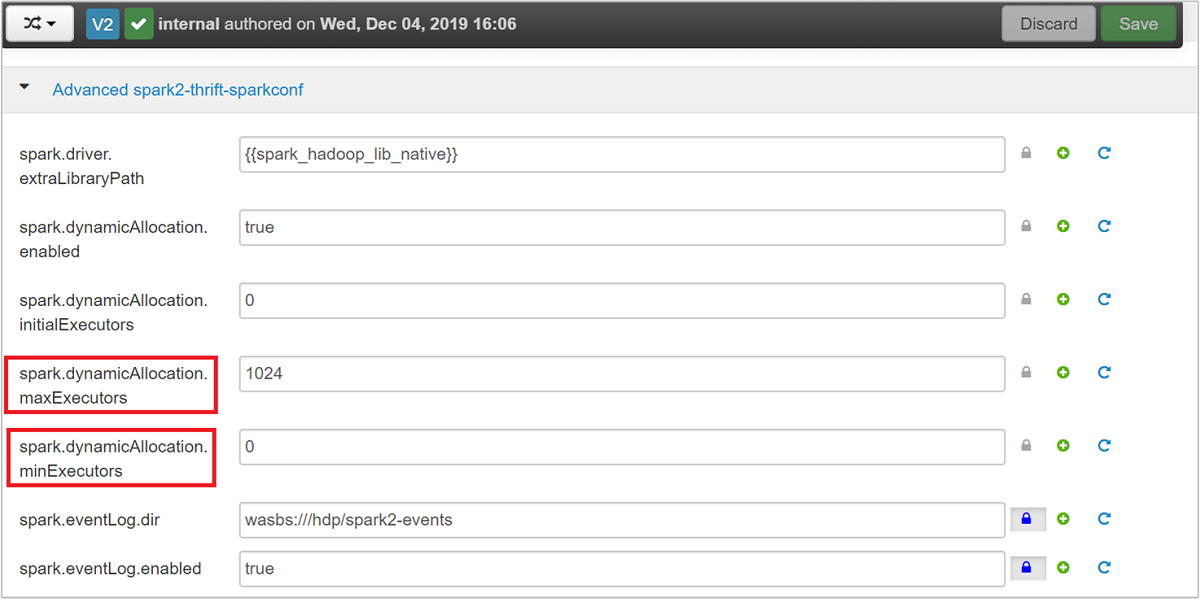
사용자 지정 spark2-thrift-sparkconf 범주를 확장하여
spark.executor.cores및spark.executor.memory매개 변수를 업데이트합니다.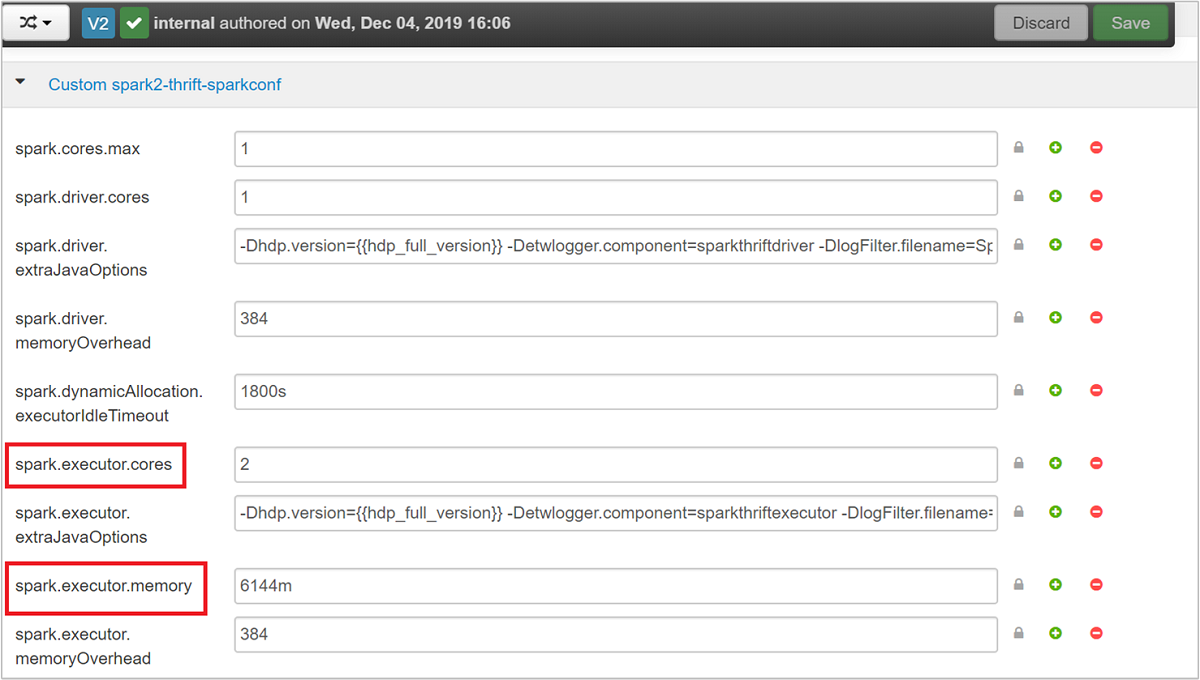
Spark Thrift 서버의 드라이버 메모리 변경
Spark Thrift 서버 드라이버 메모리는 헤드 노드 RAM 크기의 25%로 구성되어 제공된 헤드 노드의 총 RAM 크기는 14GB보다 큽니다. 다음 스크린샷에 표시된 대로 Ambari UI를 사용하여 드라이버 메모리 구성을 변경할 수 있습니다.
Ambari UI에서 Spark2>Configs>Advanced spark2-env로 이동합니다. 그런 다음 spark_thrift_cmd_opts에 대한 값을 제공합니다.
Spark 클러스터 리소스 확보
Spark 동적 할당 때문에 Thrift 서버에서 사용되는 리소스만이 두 애플리케이션 마스터에 대한 리소스입니다. 이러한 리소스를 회수하려면 클러스터에서 실행되는 Thrift 서버 서비스를 중지해야 합니다.
Ambari UI의 왼쪽 창에서 Spark2를 선택합니다.
다음 페이지에서 Spark 2 Thrift Servers를 선택합니다.
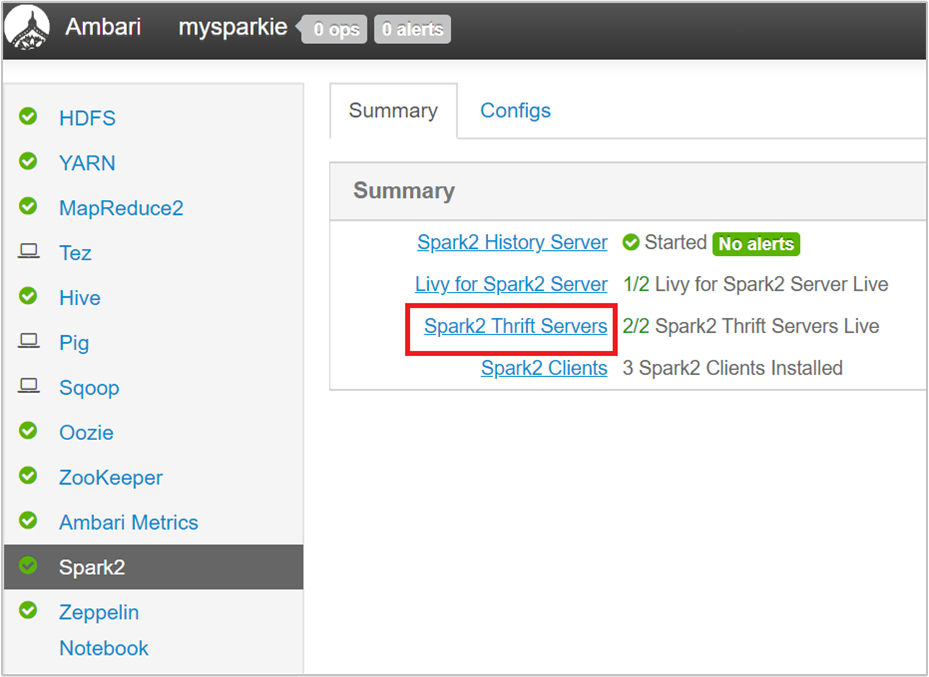
Spark 2 Thrift 서버가 실행되고 있는 두 개의 헤드 노드가 표시됩니다. 헤드 노드 중 하나를 선택합니다.
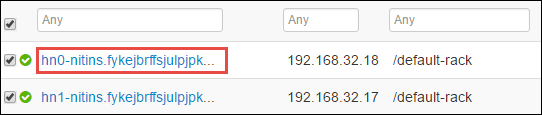
다음 페이지는 헤드 노드에서 실행 중인 모든 서비스를 나열합니다. 목록에서 Spark 2 Thrift 서버 옆에 있는 드롭다운 단추를 선택한 다음 중지를 선택합니다.
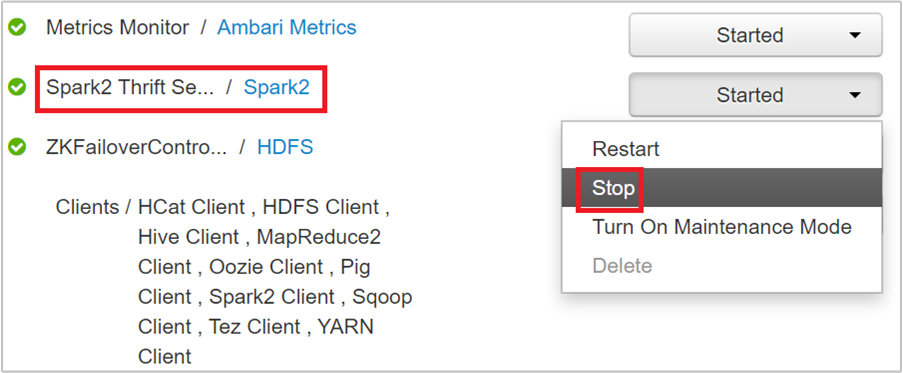
다른 헤드 노드에서도 이 단계를 반복합니다.
Jupyter 서비스 다시 시작
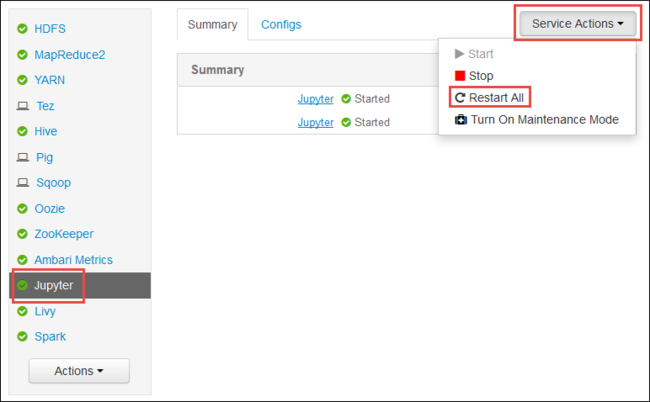
문서의 처음에 표시된 대로 Ambari 웹 UI가 시작됩니다. 왼쪽의 탐색 창에서 Jupyter, 서비스 작업, 모두 다시 시작을 차례로 선택합니다. 그러면 모든 헤드 노드에서 Jupyter 서비스가 시작됩니다.
리소스 모니터링
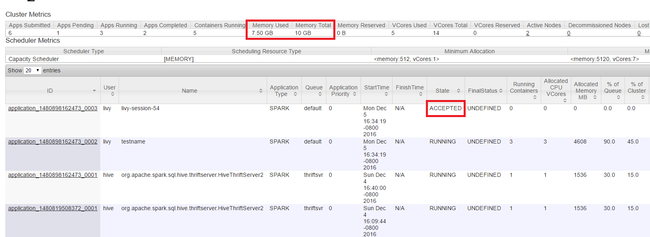
문서의 처음에 표시된 대로 Yarn UI가 시작됩니다. 화면 위쪽의 클러스터 메트릭 테이블에서 사용된 메모리 및 총 메모리 열 값을 확인합니다. 두 값이 비슷하면 리소스가 충분하지 않아 다음 애플리케이션을 시작하지 못할 수 있습니다. 동일한 현상이 사용된 VCore 및 총 VCore 열에도 적용됩니다. 또한 기본 보기에서 수락 상태이고 실행 중 또는 실패 상태로 전환되지 않은 애플리케이션이 있는 경우에도 리소스가 충분하지 않아 시작하지 못함을 나타낼 수 있습니다.
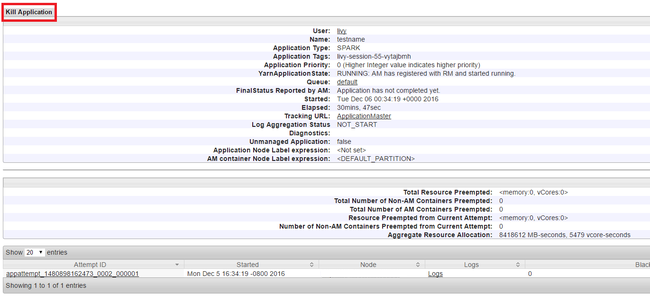
애플리케이션 실행 종료
Yarn UI의 왼쪽 패널에서 실행 중을 선택합니다. 실행 중인 애플리케이션 목록에서 종료할 애플리케이션을 결정하고 ID를 선택합니다.
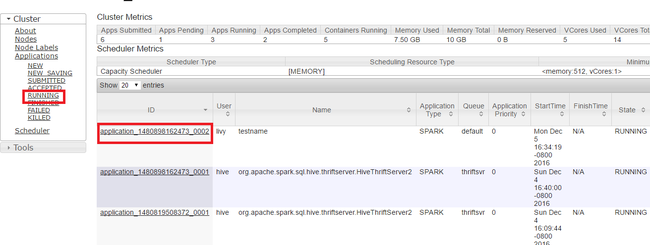
오른쪽 위 구석에서 애플리케이션 종료를 선택하고 확인을 선택합니다.
참고 항목
데이터 분석가
- Machine Learning과 Apache Spark: HVAC 데이터를 사용하여 건물 온도를 분석하는 데 HDInsight의 Spark 사용
- Machine Learning과 Apache Spark: HDInsight의 Spark를 사용하여 식품 검사 결과 예측
- HDInsight의 Apache Spark를 사용한 웹 사이트 로그 분석
- HDInsight의 Apache Spark를 사용한 Application Insight 원격 분석 데이터 분석
Apache Spark 개발자의 경우
- Scala를 사용하여 독립 실행형 애플리케이션 만들기
- Apache Livy를 사용하여 Apache Spark 클러스터에서 원격으로 작업 실행
- IntelliJ IDEA용 HDInsight 도구 플러그 인을 사용하여 Spark Scala 애플리케이션 만들기 및 제출
- IntelliJ IDEA용 HDInsight 도구 플러그 인을 사용하여 Apache Spark 애플리케이션을 원격으로 디버그
- HDInsight에서 Apache Spark 클러스터와 함께 Apache Zeppelin Notebook 사용
- HDInsight의 Apache Spark 클러스터에서 Jupyter Notebook에 사용할 수 있는 커널
- Jupyter Notebook에서 외부 패키지 사용
- 컴퓨터에 Jupyter를 설치하고 HDInsight Spark 클러스터에 연결