Databricks Notebook에서 코드 개발
이 페이지에서는 Python 및 SQL의 자동 완성, 자동 서식 지정, Notebook에서 Python 및 SQL 결합, Notebook 버전 기록 추적 등 Databricks Notebook에서 코드를 개발하는 방법을 설명합니다.
자세한 내용은 자동 완성, 변수 선택, 다중 커서 지원 및 병렬 비교 등 편집기에서 사용할 수 있는 고급 기능에 대해 Databricks 노트북 및 파일 편집기탐색을 참조하세요.
Notebook 또는 파일 편집기를 사용하는 경우 Databricks Assistant를 사용하여 코드를 생성, 설명 및 디버그할 수 있습니다. 자세한 내용은 Databricks 도우미 사용을 참조하세요.
Databricks Notebook에는 Python Notebook용 기본 제공 대화형 디버거도 포함되어 있습니다. Notebook 디버깅을 참조하세요.
코드 모듈화
Important
이 기능은 공개 미리 보기 상태입니다.
Databricks Runtime 11.3 LTS 이상을 사용하면 Azure Databricks 작업 영역에서 소스 코드 파일을 만들고 관리한 다음 필요에 따라 이러한 파일을 Notebook으로 가져올 수 있습니다.
소스 코드 파일 작업에 대한 자세한 내용은 Databricks Notebook 간에 코드 공유 및 Python 및 R 모듈 작업을 참조하세요.
코드 셀 서식 지정
Azure Databricks는 Notebook 셀에서 Python 및 SQL 코드의 서식을 쉽고 빠르게 지정할 수 있는 도구를 제공합니다. 이러한 도구는 코드의 서식을 유지하는 데 필요한 노력을 줄여 주며 여러 Notebook에서 동일한 코딩 표준을 적용해 줍니다.
Python 검정 포맷터 라이브러리
Important
이 기능은 공개 미리 보기 상태입니다.
Azure Databricks는 Notebook 내에서 Black을 사용하여 Python 코드 서식 지정을 지원합니다. Notebook은 black 및 tokenize-rt Python 패키지가 설치된 클러스터에 연결해야 합니다.
Databricks Runtime 11.3 LTS 이상에서 Azure Databricks는 black 및 tokenize-rt를 사전 설치합니다. 이러한 라이브러리를 설치하지 않고도 포맷터를 직접 사용할 수 있습니다.
Databricks Runtime 10.4 LTS 이하에서 Python 포맷터를 사용하려면 Notebook 또는 클러스터에 PyPI의 black==22.3.0 및 tokenize-rt==4.2.1을 설치해야 합니다. Notebook에서 다음 명령을 실행할 수 있습니다.
%pip install black==22.3.0 tokenize-rt==4.2.1
또는 클러스터에 라이브러리를 설치할 수 있습니다.
라이브러리 설치에 대한 자세한 내용은 Python 환경 관리를 참조하세요.
Databricks Git 폴더의 파일 및 Notebook의 경우 pyproject.toml 파일에 따라 Python 포맷터를 구성할 수 있습니다. 이 기능을 사용하려면 Git 폴더 루트 디렉터리에 pyproject.toml 파일을 만들고 Black 구성 형식에 따라 구성합니다. 파일에서 [tool.black] 섹션을 편집합니다. 이 구성은 해당 Git 폴더의 파일 및 Notebook 서식을 지정할 때 적용됩니다.
Python 및 SQL 셀의 서식을 지정하는 방법
코드 서식을 지정하려면 Notebook에 대해 편집 가능 권한이 있어야 합니다.
Azure Databricks는 Gethue/sql-formatter 라이브러리를 사용하여 SQL과 PYTHON용 black 코드 포맷터를 포맷합니다.
서식 지정 도구는 다음과 같은 방법으로 트리거할 수 있습니다.
단일 셀 서식 지정
- 바로 가기 키: Cmd+Shift+F를 누릅니다.
- 명령 바로 가기 메뉴:
- Notebook 편집 메뉴: Python 또는 SQL 셀을 선택한 후, >편집 을(를) 선택합니다.
여러 셀 서식 지정
여러 셀을 선택한 다음 편집 > 셀 서식선택합니다. 둘 이상의 언어로 된 셀을 선택하면 SQL 및 Python 셀만 서식이 지정됩니다. 여기에는
%sql및%python을 사용하는 셀도 포함됩니다.Notebook에서 모든 Python 및 SQL 셀의 서식 지정
> 편집을 선택합니다. Notebook에 둘 이상의 언어가 포함된 경우 SQL 및 Python 셀의 서식만 지정됩니다. 여기에는
%sql및%python을 사용하는 셀도 포함됩니다.
코드 서식 지정의 제한 사항
- Black은 4칸 들여쓰기를 위해 PEP 8 표준을 적용합니다. 들여쓰기를 구성할 수는 없습니다.
- SQL UDF 내에 포함된 Python 문자열의 서식 지정은 지원되지 않습니다. 마찬가지로, Python UDF 내에서 SQL 문자열의 서식 지정은 지원되지 않습니다.
Notebook의 코드 언어
기본 언어 설정
Notebook의 기본 언어는 Notebook 이름 옆에 표시됩니다.

기본 언어를 변경하려면 언어 단추를 클릭하고 드롭다운 메뉴에서 새 언어를 선택합니다. 기존 명령이 계속 작동하도록 하기 위해, 이전 기본 언어의 명령에 자동으로 언어 매직 명령 접두사가 추가됩니다.
언어 혼합
기본적으로 셀은 Notebook의 기본 언어를 사용합니다. 언어 단추를 클릭하고 드롭다운 메뉴에서 언어를 선택하여 셀의 기본 언어를 재정의할 수 있습니다.
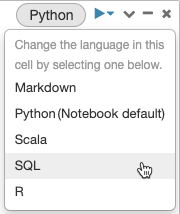
또는 셀 시작 부분에서 언어 매직 명령 %<language>를 사용할 수 있습니다. 지원되는 매직 명령은 %python, %r, %scala, %sql입니다.
참고 항목
언어 매직 명령을 호출하면 명령이 Notebook의 실행 컨텍스트에서 REPL로 전송됩니다. 하나의 언어로 정의된 변수(및 이에 따라 해당 언어의 REPL로 정의된 변수)는 다른 언어의 REPL에서 사용할 수 없습니다. REPL은 DBFS의 파일, 개체 스토리지의 개체와 같은 외부 리소스를 통해서만 상태를 공유할 수 있습니다.
Notebook은 다음과 같은 보조 매직 명령도 지원합니다.
-
%sh: Allows Notebook에서 셸 코드를 실행할 수 있습니다. 셸 명령에 0이 아닌 종료 상태가 있는 경우 셀이 실패하도록 하려면-e옵션을 추가합니다. 이 명령은 Apache Spark 드라이버에서만 실행되며, 작업자에서는 실행되지 않습니다. 모든 노드에서 셸 명령을 실행하려면 init 스크립트를 사용합니다. -
%fs:dbutils파일 시스템 명령을 사용할 수 있습니다. 예를 들어dbutils.fs.ls명령을 실행하여 파일을 나열하려면 대신%fs ls지정할 수 있습니다. 자세한 내용은 Azure Databricks에서 파일로 작업을 참조하세요. -
%md: 텍스트, 이미지, 수학 수식, 방정식을 포함하는 다양한 유형의 설명서를 포함할 수 있습니다. 다음 섹션을 확인하세요.
Python 명령에서 SQL 구문 강조 표시 및 자동 완성
구문 강조 표시 및 SQL 자동 완성은 spark.sql 명령과 같은 Python 명령 내에서 SQL을 사용할 때 사용할 수 있습니다.
SQL 셀 결과 탐색
Databricks Notebook에서 SQL 언어 셀의 결과는 변수 _sqldf에 할당된 암시적 DataFrame으로 자동으로 제공됩니다. 그런 다음, Notebook에서의 위치에 관계없이 나중에 실행하는 모든 Python 및 SQL 셀에서 이 변수를 사용할 수 있습니다.
참고 항목
이 기능에는 다음과 같은 제한 사항이 있습니다.
-
_sqldf컴퓨팅에 SQL 웨어하우스를 사용하는 Notebook에서는 변수를 사용할 수 없습니다. - 후속 Python 셀에서의 사용
_sqldf은 Databricks Runtime 13.3 이상에서 지원됩니다. - 후속 SQL 셀에서의 사용
_sqldf은 Databricks Runtime 14.3 이상에서만 지원됩니다. - 쿼리에서 키워드를
CACHE TABLE사용하거나UNCACHE TABLE변수를_sqldf사용할 수 없는 경우
아래 스크린샷은 후속 Python 및 SQL 셀에서 사용할 수 있는 방법을 _sqldf 보여줍니다.
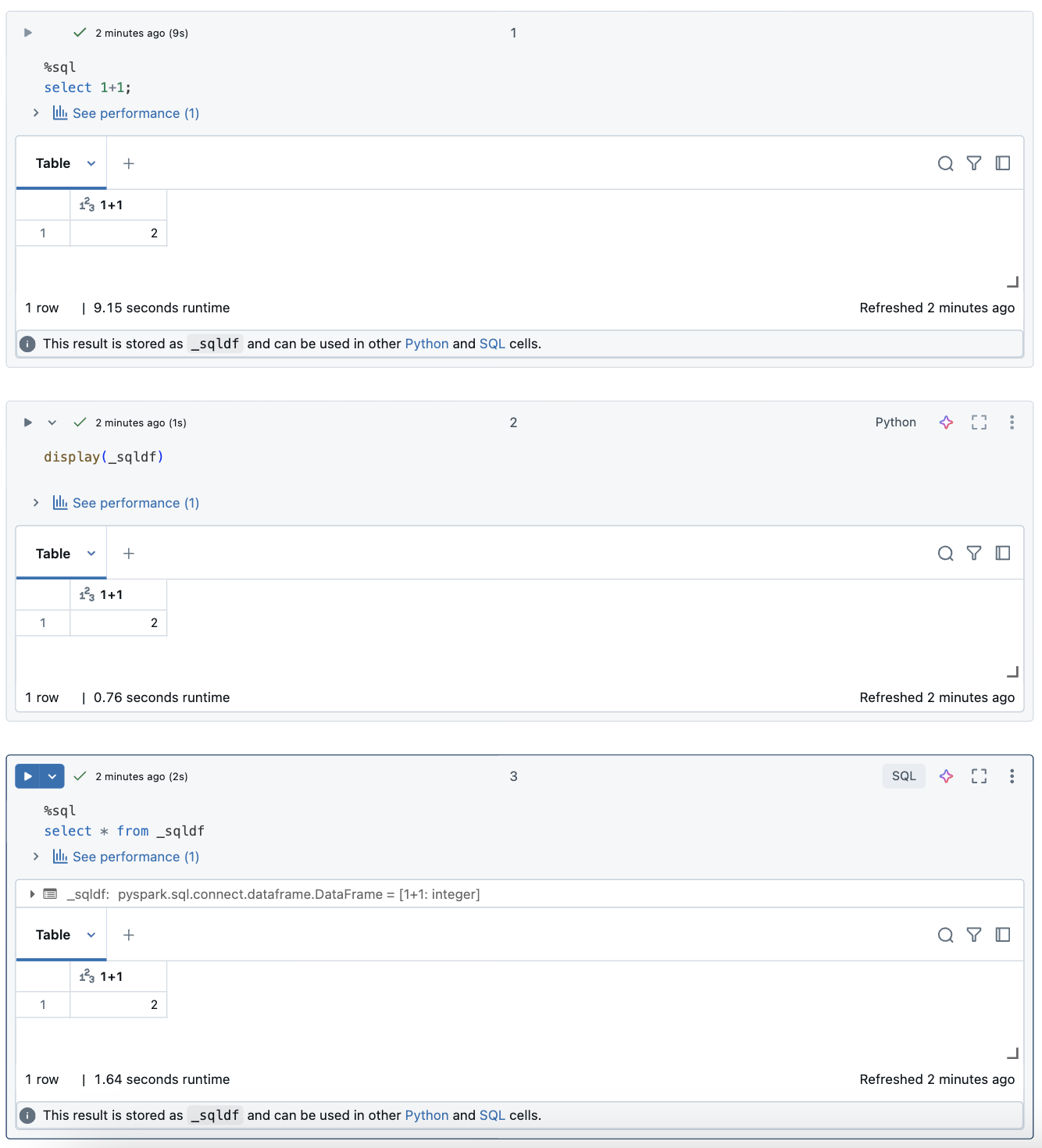
Important
변수 _sqldf 는 SQL 셀이 실행될 때마다 다시 할당됩니다. 특정 DataFrame 결과에 대한 참조가 손실되지 않도록 하려면 다음 SQL 셀을 실행하기 전에 새 변수 이름에 할당합니다.
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
병렬로 SQL 셀 실행
명령이 실행되고 Notebook이 대화형 클러스터에 연결된 동안 현재 명령과 동시에 SQL 셀을 실행할 수 있습니다. SQL 셀은 새로운 병렬 세션에서 실행됩니다.
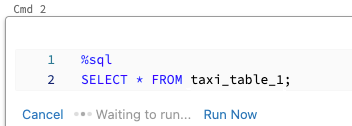
셀을 병렬로 실행하려면 다음을 수행합니다.
지금 실행을 클릭합니다. 셀이 즉시 실행됩니다.
셀이 새 세션에서 실행되므로 임시 뷰, UDF 및 암시적 Python DataFrame(_sqldf)은 병렬로 실행되는 셀에 대해 지원되지 않습니다. 또한 기본 카탈로그 및 데이터베이스 이름은 병렬 실행 중에 사용됩니다. 코드가 다른 카탈로그 또는 데이터베이스의 테이블을 참조하는 경우 3개 수준 네임스페이스(catalog.schema.table)를 사용하여 테이블 이름을 지정해야 합니다.
SQL 웨어하우스에서 SQL 셀 실행
SQL 분석에 컴퓨팅 최적화 유형의 SQL 웨어하우스에 있는 Databricks Notebook에서, 서버리스 컴퓨팅에서 SQL 명령을 실행할 수 있습니다. SQL 웨어하우스에서 Notebook 사용을 참조하세요.