データ重複除去のインストールと有効化
このトピックでは、データ重複除去のインストール、重複除去のワークロードの評価、および特定のボリュームでのデータ重複除去の有効化の方法について説明します。
注意
フェールオーバー クラスター内でデータ重複除去を実行する場合は、クラスター内のすべてのノードに、データ重複除去のサーバーの役割がインストールされている必要があります。
データ重複除去のインストール
重要
KB4025334 には、信頼性についての重要な修正データを含め、重複除去に関する修正のロールアップが含まれているため、Windows Server 2016 でデータ重複除去を使う場合はインストールすることを強くお勧めします。
サーバー マネージャーを使用してデータ重複除去をインストールする
- 役割と機能の追加ウィザードで [サーバーの役割] を選択し、[データ重複除去] をオンにします。
![サーバー マネージャーを使用したデータ重複除去のインストール: [サーバーの役割] で [データ重複除去] をオンにする](media/install-dedup-via-server-manager-1.png)
- [インストール] がアクティブになるまで [次へ] をクリックし、[インストール] をクリックします。
![サーバー マネージャーを使用したデータ重複除去のインストール: [インストール] をクリックする](media/install-dedup-via-server-manager-2.png)
PowerShell を使用してデータ重複除去をインストールする
データ重複除去をインストールするには、管理者のアカウントで次の PowerShell コマンドを実行します: Install-WindowsFeature -Name FS-Data-Deduplication
データ重複除去をインストールするには:
Windows Server 2016 以降を実行しているサーバー、またはリモート サーバー管理ツール (RSAT) がインストールされている Windows PC から、Nano Server インスタンスへの明示的な参照を使用して、データ重複除去をインストールします ('MyServer' をサーバー インスタンスの実名に置き換えてください)。
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-Deduplicationまたは
PowerShell のリモート処理を使用してサーバー インスタンスにリモートで接続し、DISM を使用してデータ重複除去をインストールします。
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
データ重複除去の有効化
データ重複除去の候補となるボリュームの決定
データ重複除去を使用すると、重複データによって消費されるディスク領域を削減して、サーバー アプリケーションのデータ消費コストを効率よく最小限に抑えることができます。 重複除去を有効にする前に、記憶域のパフォーマンスを最大限に活かすことができるようにワークロードの特性を理解する必要があります。 考慮すべきの 2 つのクラスのワークロードがあります。
- "推奨ワークロード": 重複除去によって大きなメリットが得られるデータセットと、リソース消費パターンがデータ重複除去の処理後モデルに適合しているデータセットの両方が含まれることが実証されているワークロード。 次のワークロードに対しては、常にデータ重複除去を有効にすることをお勧めします。
- チーム共有、ユーザー ホーム フォルダー、ワーク フォルダー、ソフトウェア開発共有などの、共有のための汎用ファイル サーバー (GPFS)
- 仮想デスクトップ インフラストラクチャ (VDI) サーバー
- Microsoft Data Protection Manager (DPM) などの仮想化バックアップ アプリケーション
- 重複除去によってメリットを得る可能性があるものの、常に重複除去に適しているとは限らないワークロード。 たとえば、以下のワークロードでは重複除去が有効な可能性はありますが、まず重複除去のメリットを評価する必要があります。
- 汎用 Hyper-V ホスト
- SQL Server
- 基幹業務 (LOB) サーバー
データ重複除去のワークロードの評価
重要
推奨ワークロードを実行している場合は、このセクションをスキップして、ワークロードのデータ重複除去の有効化に進むことができます。
ワークロードで重複除去によるメリットが得られるかどうかを判定するには、次の質問に回答します。 よくわからないワークロードの場合は、ワークロードのテスト データセットにデータ重複除去をパイロット展開し、そのパフォーマンスを確認することを検討してください。
重複除去の有効化のメリットを得るのに十分な重複がワークロードのデータセットに含まれていますか。 ワークロードのデータ重複除去を有効にする前に、Data Deduplication Savings Evaluation Tool (DDPEval) を使用して、ワークロードのデータセットに含まれている重複の量を調査します。 データ重複除去をインストールすると、このツールは
C:\Windows\System32\DDPEval.exeにあります。 DDPEval では、直接接続されているボリューム (ローカル ドライブやクラスターの共有ボリュームなど) と、(マップの有無にかかわらず) ネットワーク共有の最適化の可能性を評価できます。DDPEval.exe を実行すると、以下のような出力が返されます。
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0データセットに対するワークロードの I/O パターンはどのようなものですか。 ワークロードのパフォーマンスはどのようになりますか。 データ重複除去によるファイルの最適化は、ディスクへのファイルの書き込み時ではなく定期的に行われます。 このため、ワークロードで想定される重複除去対象ボリュームの読み取りパターンを調査する必要があります。 データ重複除去では、ファイル コンテンツをチャンク ストアに移動してから、チャンク ストアをできる限りファイル別に整理しようとするため、読み取り操作のパフォーマンスはファイルの順次範囲に対して適用した場合に最高となります。
データベースでは、実行される可能性があるすべてのクエリに対してデータベース レイアウトが最適ではない可能性があります。したがって、データベースのようなワークロードでは、通常、順次読み取りパターンよりもランダム読み取りパターンの方が多くなります。 チャンク ストアのセクションはボリューム全体に存在することがあるため、データベース クエリのチャンク ストア内のデータ範囲にアクセスすると、待機時間が増加する可能性があります。 高パフォーマンス ワークロードはこの待機時間の増加の影響を特に受けやすいのですが、他のデータベースのようなワークロードには影響が特に生じないものもあります。
注意
こうした懸念の主な対象は、従来の回転記憶域メディア (別名ハード ディスク ドライブ (HDD)) から成るボリュームの記憶域ワークロードです。 フラッシュ メディアの特徴の 1 つは、ディスクのどの場所へのアクセス時間も同じであることです。そのため、オールフラッシュ記憶域インフラストラクチャ (別名ソリッド ステート ドライブ (SSD)) では、ランダム IO パターンの影響が低くなります。 したがって、オールフラッシュ メディアに格納されているワークロードのデータセットの読み取りでは、重複除去によって従来の回転記憶域メディアと同じ長さの待機時間が発生することはありません。
ワークロードは、サーバーのどのようなリソースを必要としますか。 データ重複除去では処理後モデルが使用されることから、データ重複除去が最適化ジョブと他のジョブを完了するのに十分なシステム リソースが定期的に必要になります。 つまり、夜間や週末などにアイドル時間があるワークロードは重複除去に適していますが、一日中実行されるワークロードは適さない可能性があります。 アイドル時間がないワークロードでも、必要とするサーバー リソースが多くない場合は、重複除去に適している可能性があります。
データ重複除去の有効化
データ重複除去を有効にする前に、ワークロードに最もよく似た使用法の種類を選択する必要があります。 データ重複除去には 3 つの使用法の種類が含まれています。
- 既定 - 汎用ファイル サーバー用
- Hyper-V - VDI サーバー専用
- バックアップ - 仮想化バックアップ アプリケーション (Microsoft DPM など) 専用
サーバー マネージャーを使用してデータ重複除去を有効にする
- サーバー マネージャーで [ファイル サービスと記憶域サービス] を選択します。
![[ファイル サービスおよびストレージ サービス] をクリック](media/enable-dedup-via-server-manager-1.png)
- [ファイル サービスと記憶域サービス] で [ボリューム] をクリックします。
![[ボリューム] をクリックする](media/enable-dedup-via-server-manager-2.png)
- 目的のボリュームを右クリックして、[データ重複除去の構成] を選択します。
![[データ重複除去の構成] をクリック](media/enable-dedup-via-server-manager-3.png)
- ドロップダウン ボックスから目的とする使用法の種類を選択して、[OK] を選択します。
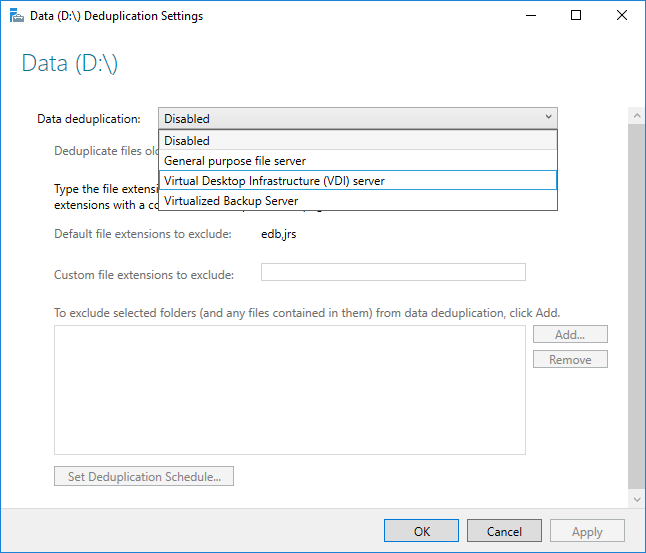
- 推奨ワークロードを実行している場合は、これで終了です。 他のワークロードの場合は、「他の考慮事項」を参照してください。
注意
ファイル拡張子やフォルダーの除外、および重複除去スケジュールの選択 (これを実行する理由など) の詳細は、データ重複除去の構成に関するページに記載されています。
PowerShell を使用してデータ重複除去を有効にする
管理者のコンテキストで、次の PowerShell コマンドを実行します。
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>推奨ワークロードを実行している場合は、これで終了です。 他のワークロードの場合は、「他の考慮事項」を参照してください。
注意
データ重複除去の PowerShell コマンドレット (Enable-DedupVolume など) は、-CimSession パラメーターで CIM セッションを指定するとリモートで実行できます。 これは、サーバー インスタンスに対してデータ重複除去の PowerShell コマンドレットをリモートで実行するのに特に役立ちます。 新しい CIM セッションを作成するには、New-CimSession を実行します。
その他の考慮事項
重要
推奨ワークロードを実行している場合、このセクションはスキップできます。
- データ重複除去の各使用方法の種類では推奨ワークロードに適した既定値が提供されますが、ほかのワークロードにとってもこれらの値は適切な出発点となります。 推奨ワークロードではないワークロードの場合は、重複除去のパフォーマンスを向上させるために、データ重複除去の詳細設定を変更することもできます。
- ワークロードに必要なサーバー リソースが多い場合は、データ重複除去ジョブがそのワークロードがアイドルであると見込まれる時間中に実行されるようにスケジュールする必要があります。 業務が予定されている時間中にデータ重複除去を実行すると仮想メモリが不足する可能性があるため、ハイパーコンバージド ホストで重複除去を実行する場合には、これは特に重要です。
- ワークロードに必要なリソースがそれほど多くない場合、またはワークロードの要求を満たすよりも最適化ジョブを完了する方が重要である場合は、データ重複除去ジョブのメモリ、CPU、および優先順位を調整できます。
よく寄せられる質問 (FAQ)
X ワークロードのデータセットに対してデータ重複除去を実行したいのですが、 これはサポートされていますか。 データ重複除去との同時使用に未対応であることが確認されているワークロードを除いて、どんなワークロードであってもデータ重複除去のデータの整合性は完全にサポートされています。 推奨ワークロードについてはパフォーマンスもサポートされます。 他のワークロードのパフォーマンスは、サーバー上での操作に大きく左右されます。 お客様のワークロードにデータ重複除去が及ぼすパフォーマンス上の影響を確認して、そのワークロードに適しているかどうかを判断してください。
重複除去されるボリュームには、どのようなボリューム サイズ設定が必要ですか。 Windows Server 2012 および Windows Server 2012 R2 では、データ重複除去がボリュームのチャーンについていけるように、ボリュームのサイズを注意して設定する必要があります。 一般的には、高チャーンのワークロードで重複除去されるボリュームの平均最大サイズは 1 ~ 2 TB であり、推奨される絶対最大サイズは 10 TB です。 Windows Server 2016 では、これらの制約がなくなりました。 詳細については、「データ重複除去の新機能」を参照してください。
推奨ワークロードの場合、スケジュールなどのデータ重複除去設定を変更する必要はありますか。 いいえ。推奨ワークロードに適した既定値を設定するための使用法の種類が用意されています。
データ重複除去にはどれだけのメモリが必要ですか。
最小でも、データ重複除去では 300 MB に加えて、1 TB の論理データにつき 50 MB が必要です。 たとえば、10 TB のボリュームを最適化する場合は、最小で 800 MB のメモリが重複除去に割り当てられている必要があります (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB)。 データ重複除去では、この少量のメモリでボリュームを最適化できますが、そのようなリソース制約があると、データ重複除去ジョブの速度が低下します。
データ重複除去を最適に行うには、1 TB の論理データにつき 1 GB のメモリが必要です。 たとえば、10 TB のボリュームを最適化する場合、好ましい状況とするには、10 GB のメモリが重複除去に割り当てられている必要があります (1 GB * 10)。 この比率であれば、データ重複除去ジョブのパフォーマンスを最大化することができます。
データ重複除去にはどれだけの記憶域が必要ですか。 Windows Server 2016 において、データ重複除去では 64 TB までのボリューム サイズをサポートできます。 詳細については、「What's New in Data Deduplication (データ重複除去の新機能)」を参照してください。