Fabric Lakehouse データ資産のデータ品質
Fabric OneLake は、organization全体の単一の統合された論理データ レイクです。 Data Lake は、さまざまなソースからの大量のデータを処理します。 Microsoft OneDrive と同様に、OneLake はすべての Microsoft Fabric テナントに自動的に付属し、すべての分析データの単一の場所として設計されています。 OneLake では、次の顧客が提供されます。
- organization全体の 1 つのデータ レイク
- 複数の分析エンジンで使用するデータの 1 つのコピー
OneLake は、データの移動や複製を行わずに、データの 1 つのコピーから可能な限り最大限の価値を提供することを目的としています。 データを別のエンジンで使用したり、サイロを分割したりするためにデータをコピーする必要がなくなり、他のソースのデータを使用してデータを分析できます。 Microsoft Purview を使用して、ファブリック データ資産をカタログ化し、データ品質を測定して、改善アクションを管理および推進できます。
ショートカットを使用して、他のファイルの場所に格納されているデータを参照できます。 これらのファイルの場所は、同じワークスペース内、または異なるワークスペース内、OneLake 内、または Azure Data Lake Storage (ADLS)、Amazon Web Services (AWS) S3、Dataverse の外部にあり、より多くのターゲットの場所が近日公開される予定です。 データ ソースの場所はそれほど重要ではありません。OneLake ショートカットを使用すると、ファイルとフォルダーがローカルに保存されたように見えます。 チームが個別のワークスペースで独立して作業する場合、ショートカットを使用すると、さまざまなビジネス グループやドメインのデータを仮想データ製品に結合して、ユーザー固有のニーズに合わせることができます。
ミラーリングを使用して、さまざまなソースのデータを Fabric に取り込むことができます。 Fabric でのミラーリングは、さまざまなシステムのデータを 1 つの分析プラットフォームにまとめるために、低コストで待機時間の短いソリューションです。 Azure SQL Database、Azure Cosmos DB、Snowflake からのデータなど、既存のデータ資産を Fabric の OneLake に直接継続的にレプリケートできます。 OneLake でクエリ可能な形式の最新のデータを使用すると、Fabric のすべての異なるサービスを使用できるようになりました。 たとえば、Spark での分析の実行、ノートブックの実行、データ エンジニアリング、Power BI レポートによる視覚化などです。 その後、Delta テーブルをあらゆる場所の Fabric で使用できるため、ユーザーは Fabric への移行を加速できます。
Fabric OneLake を登録する
Data Map スキャンを構成するには、最初にスキャンするデータ ソースを登録する必要があります。 Fabric ワークスペースをスキャンするために、データ ソースとして Fabric テナントを登録するための既存のエクスペリエンスに変更はありません。 新しいデータ ソースを登録するには、次の手順に従います。
- Microsoft Purview ポータルで、[ データ マップ] に移動します。
- [登録] を選択します。
- [ソース の登録 ] で、[ Fabric] を選択します。
同じテナントとテナント間のセットアップ手順を参照してください。
データ マップ スキャンを設定する
Lakehouse subartifacts をスキャンするために、データ マップの既存のエクスペリエンスに変更を加えてスキャンを設定する必要はありません。 サポートされているファイル形式からスキーマ情報を抽出するために、Fabric ワークスペースで少なくとも 共同作成者 ロールを持つスキャン資格情報を付与する別の手順があります。
現在、認証方法としてサポートされているのはサービス プリンシパルのみです。 MSI のサポートはバックログに残っています。
同じテナントとテナント間のセットアップ手順を参照してください。
Fabric Lakehouse スキャンの接続を設定する
Fabric Lakehouse をソースとして登録した後、Data Map で登録済みのデータ ソースの一覧から [Fabric] を選択し、[ 新しいスキャン] を選択できます。 データ ソース ID を追加し、次の手順に従います。
セキュリティ グループとサービス プリンシパルを作成する
このサービス プリンシパルと Purview マネージド ID の両方をこのセキュリティ グループに追加してから、このセキュリティ グループを指定してください。
セキュリティ グループを Fabric テナントに関連付ける
- Fabric 管理ポータルにログインします。
- [テナント設定] ページを選択します。 テナント設定ページを表示するには、Fabric 管理である必要があります。
- [管理 API 設定] > [サービス プリンシパルが読み取り専用管理者 API を使用できるようにする] を選択します。
- [特定のセキュリティ グループ] を選択します。
- [API 設定管理>詳細なメタデータを使用して管理 API 応答を強化する] と [DAX 式とマッシュアップ式を使用した管理者 API 応答の強化] を選択>スキャンの一部として Fabric データセットの詳細なメタデータMicrosoft Purview データ マップ自動的に検出できるようにするトグルを有効にします。 Fabric テナントの 管理 API 設定を更新した後、スキャンとテストの接続を登録するまで約 15 分待ちます。
このセキュリティ グループ管理 API 設定の読み取り専用 API アクセス許可を指定します。
[資格情報] フィールドに SPN を追加します。
Azure リソース名を追加します。
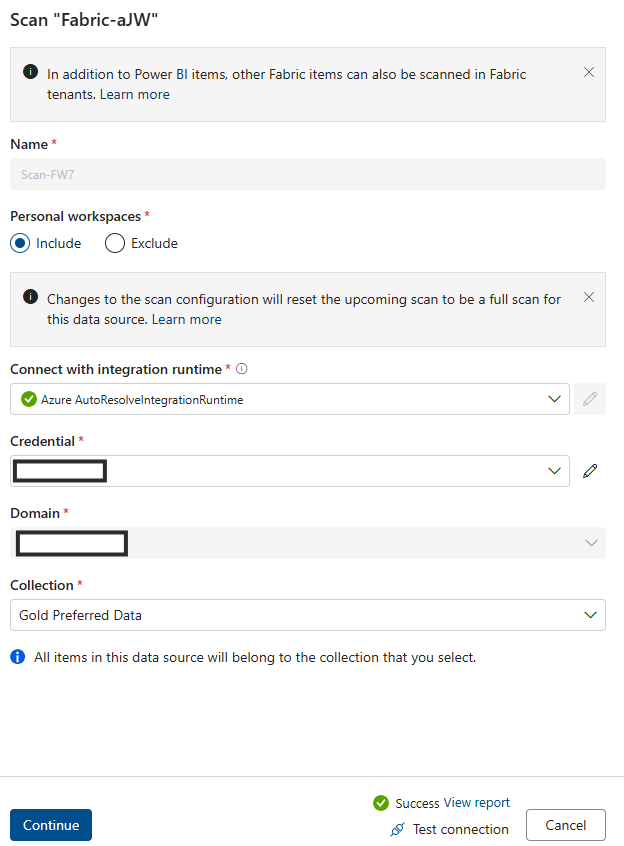
テナント ID を追加します。
サービス プリンシパル ID を追加します。
接続Key Vault追加します。
シークレット名を追加します。


Data Map スキャンが完了したら、統合カタログで Lakehouse インスタンスを見つけます。
- Microsoft Purview ポータルで、統合カタログを開きます。
- [ 検出]、[ データ資産] の順に選択します。
- [ データ資産 ] ページで、[ Microsoft Fabric] を選択します。
- [ Fabric ワークスペース] を選択し、一覧からワークスペースを選択します。
- ワークスペースのページで、[ アイテム名] の下にある Lakehouse インスタンスを見つけます。
Lakehouse テーブルを参照するには:
- ワークスペース ページで、項目名 [テーブル] を選択します。
- [ アイテム名] の下に一覧表示されている Lakehouse テーブル アセットを選択します。
- 資産の詳細ページを表示して、スキーマ、系列、プロパティなどのメタデータを見つけます。
Fabric Lakehouse データ品質スキャンの前提条件
- ショートカット、ミラー、またはデータを Delta 形式で Fabric Lakehouse に読み込みます。

重要
ミラーリングまたはショートカットを使用して新しいテーブル、ファイル、または新しいデータ セットを Fabric Lakehouse に追加した場合は、データ品質評価のためにデータ資産をデータ製品に追加する前に、データ マップ スコープ スキャンを実行して、それらの新しいデータ セットをカタログ化する必要があります。
- Purview MSI のワークスペースに共同作成者権限を付与する

- スキャンされたデータ資産を Lakehouse からガバナンス ドメインのデータ製品に追加します。 統合カタログのデータ製品のページで、[データ資産] を見つけて、[データ資産の追加] を選択します。 データ プロファイルとデータ品質スキャンは、ガバナンス ドメインのデータ製品に関連付けられているデータ資産に対してのみ実行できます。
データ プロファイルとデータ品質スキャンの場合は、データ ソースの接続とデータ品質の事実とディメンションをキャプチャするためにデータをスキャンするためにさまざまなコネクタが使用されるため、データ ソース接続を作成する必要があります。 接続を設定するには:
統合カタログで、[正常性管理] を選択し、[データ品質] を選択します。
ガバナンス ドメインを選択し、[管理] ドロップダウン リストから [Connections] を選択します。
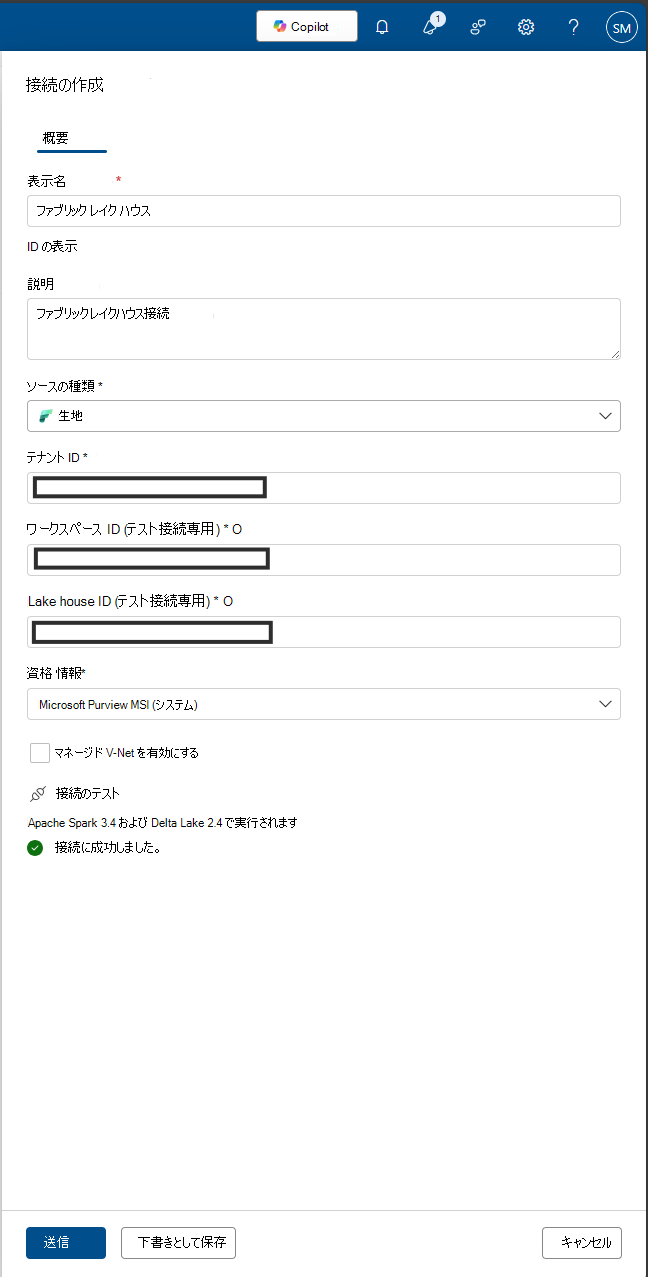
[ 新規] を選択して接続構成ページを開きます。
接続の表示名と説明を追加します。
ソースの種類 Fabric を追加します。
テナント ID を追加します。
ワークスペース ID の追加
Lakehouse ID の追加
資格情報 - Microsoft Purview MSI を追加します。

接続をテストして、構成された接続が成功したことを確認します。


重要
- データ品質スキャンの場合、Microsoft Purview MSI は、Fabric ワークスペースを接続するために Fabric ワークスペースへの共同作成者アクセス権を持っている必要があります。 共同作成者へのアクセスを許可するには、Fabric ワークスペースを開き、3 つのドット (...) を選択し、[ ワークスペース アクセス] を選択し、[ ユーザーまたはグループを追加する] を選択してから、Purview MSI を 共同作成者として追加します。
- ファブリック テーブルは、Delta 形式または Iceberg 形式である必要があります。
Fabric Lakehouse でのデータのプロファイリングとデータ品質 (DQ) スキャン
接続のセットアップが正常に完了したら、Fabric Lakehouse でデータのプロファイリング、作成、適用、データ品質 (DQ) スキャンを実行できます。 以下で説明するステップバイステップのガイドラインに従ってください。
- キュレーション、検出、サブスクリプションのデータ製品に Lakehouse テーブルを関連付けます。 データ製品を作成および管理する方法について説明します。

- Profile Fabric Lakehouse テーブル。 データ資産のデータ プロファイルを構成して実行する方法について説明します。

- Fabric Lakehouse テーブルのデータ品質を測定するために、データ品質スキャンを構成して実行します。 データ品質スキャンを構成して実行する方法について説明します。

重要
- データが Delta 形式または Iceberg 形式であることを確認します。
- データ マップ スキャンが正常に実行されたことを確認します。 実行されなかった場合は、スキャンを再実行します。
制限事項
Parquet ファイルのデータ品質は、次をサポートするように設計されています。
- Parquet パーツ ファイルを含むディレクトリ。 例: ./Sales/{Parquet Part Files}。 完全修飾名は、
https://(storage account).dfs.core.windows.net/(container)/path/path2/{SparkPartitions}に従う必要があります。 ディレクトリ/サブディレクトリ構造に {n} パターンがないことを確認します。{SparkPartitions} につながる直接の FQN である必要があります。 - 年と月でパーティション分割された売上データなど、データセット内の列でパーティション分割されたパーティション分割された Parquet ファイルを含むディレクトリ。 例: ./Sales/{Year=2018}/{Month=Dec}/{Parquet Part Files}。
一貫性のある Parquet データセット スキーマを示すこれらの重要なシナリオの両方がサポートされています。 制限事項: Parquet ファイルを含むディレクトリの N 個の任意の階層に対して設計されていないか、サポートされません。 (1) または (2) 構築された構造でデータを提示するようにお客様にアドバイスします。 そのため、サポートされている Parquet 標準に従うか、 ACID 準拠のデルタ形式にデータを移行することをお勧めします。
ヒント
データ マップの場合
- SPN にワークスペースのアクセス許可があることを確認します。
- スキャン接続で SPN が使用されていることを確認します。
- 初めて Lakehouse スキャンを設定する場合は、フル スキャンを実行することをお勧めします。
- 取り込まれた資産が更新または更新されたことを確認する
統合カタログ
- DQ 接続では、MSI 資格情報を使用する必要があります。
- Lakehouse データ DQ スキャンを初めてテストするための新しいデータ製品を作成するのが理想的です
- 取り込まれたデータ資産を追加し、データ資産が更新されることをチェックします。
- 実行プロファイルを試してください。成功した場合は、DQ ルールの実行を試してください。 成功しない場合は、資産スキーマ (スキーマ> スキーマ管理インポート スキーマ) を更新してみてください
- 一部のユーザーは、すべてがゼロから機能チェックするために、新しい Lakehouse とサンプル データを作成する必要がありました。 場合によっては、Data Map で以前に取り込まれた資産を操作すると、エクスペリエンスの一貫性が保たれない場合があります。