高速 R-CNN を使用した物体検出
目次
まとめ

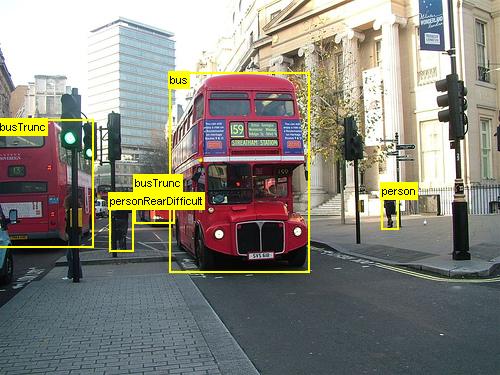
このチュートリアルでは、BrainScript と cntk.exe で CNTK Fast R-CNN を使用する方法について説明します。 ここでは、CNTK Python API を使用した高速 R-CNN について説明 します。
上記は、このチュートリアルで使用する食料品データセット (最初の画像) と Pascal VOC データセット (2 番目の画像) の画像とオブジェクト注釈の例です。
高速R-CNN は、2015年に ロス・ギルシック が提案した物体検出アルゴリズムです。 この論文はICCV 2015に受理され https://arxiv.org/abs/1504.08083、. 高速 R-CNN は、以前の作業に基づいて構築され、深い畳み込みネットワークを使用してオブジェクト提案を効率的に分類します。 以前の作業と比較して、Fast R-CNN では、畳み込みレイヤーからの計算を再利用できる 対象領域プール スキームが採用されています。
その他の資料: CNTK Fast R-CNN と BrainScript を使用した物体検出の詳細なチュートリアル (オプションの SVM トレーニングとトレーニング済みモデルを Rest API として公開する方法を含む) については、こちらを参照してください。
セットアップ
この例のコードを実行するには、CNTK Python 環境が必要です (セットアップのヘルプについては 、こちらを 参照してください)。 さらに、いくつかの追加パッケージをインストールする必要があります。 FastRCNN フォルダーに移動し、次を実行します。
pip install -r requirements.txt
既知の問題: scikit-learn をインストールするには、Anaconda Python を使用する場合に実行 conda install scikit-learn する必要がある場合があります。
これらの例を実行するには、さらにScikit-Imageと OpenCV が必要になります。
対応するホイールパッケージをダウンロードし、手動でインストールしてください。 Linux では、次のことができます conda install scikit-image opencv。
Windows ユーザーの場合は、次のページにアクセス http://www.lfd.uci.edu/~gohlke/pythonlibs/してダウンロードします。
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
それぞれのホイール バイナリをダウンロードしたら、次のコマンドを使用してインストールします。
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[!注]: スクリプトの実行時に「 過去に名前が付いたモジュールがありません」という メッセージが表示された場合は、実行 pip install futureしてください。
このチュートリアル コードでは、 utils の下に必要な高速 R-CNN DLL ファイルがこれらのバージョン用に事前構築されているため、Python 3.5 または 3.6 の 64 ビット バージョンを使用していることを前提としています。 タスクで別の Python バージョンを使用する必要がある場合は、これらの DLL ファイルを正しい環境で再コンパイルしてください ( 以下を参照)。
さらに、このチュートリアルでは、 cntk.exeが存在するフォルダーが PATH 環境変数にあることを前提としています。 (フォルダーを PATH に追加するには、コマンド ラインから次のコマンドを実行します (コンピューター上にcntk.exeフォルダーが C:\src\CNTK\x64\Release であると仮定します)。 set PATH=C:\src\CNTK\x64\Release;%PATH%
境界ボックス回帰と非最大抑制用の事前コンパイル済みバイナリ
このフォルダー Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils には、Fast R-CNN を実行するために必要な事前コンパイル済みバイナリが含まれています。 リポジトリに現在含まれているバージョンは Python 3.5 と 3.6 で、すべて 64 ビットです。 別のバージョンが必要な場合は、次の手順に従ってコンパイルできます。
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmake- 代わりに
make、同じフォルダーから実行python setup.py build_ext --inplaceできます。 Windows では、lib/setup.py で追加のコンパイル引数をコメントアウトする必要がある場合があります。
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]- 代わりに
生成された
cython_bboxバイナリをcython_nmsコピー先$FRCN_ROOT/lib/utilsにコピーします$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils。
データとベースライン モデルの例
Fast-R-CNN トレーニングの基礎として、事前トレーニング済みの AlexNet モデルを使用します。 事前トレーニング済みの AlexNet は、https://www.cntk.ai/Models/AlexNet/AlexNet.model でモデル $CNTK_ROOT/PretrainedModelsを保存してください。 データをダウンロードするには、次を実行してください
python install_grocery.py
フォルダーから。Examples/Image/DataSets/Grocery
おもちゃの例を実行する
おもちゃの例では、CNTK Fast R-CNN モデルをトレーニングして、冷蔵庫内の食料品を検出します。
すべての必要なスクリプトは次のとおりです $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript。
クイック ガイド
おもちゃの例を実行するには、in が PARAMETERS.pydataset"Grocery".
- 実行
A1_GenerateInputROIs.pyして、トレーニングとテスト用の入力 ROI を生成します。 - cntk.exeと BrainScript を使用してトレーニングとテストを実行
A2_RunWithBSModel.pyします。 - トレーニング済みモデルの mAP (平均平均精度) を計算するために実行
A3_ParseAndEvaluateOutput.pyします。
スクリプト A3 からの出力には、次のものが含まれている必要があります。
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
境界ボックスと予測ラベルを視覚化するには、実行 B3_VisualizeOutputROIs.py できます (画像をクリックして拡大します)。





ステップの詳細
A1: スクリプト A1_GenerateInputROIs.py は、最初に 選択的検索を使用して各画像の ROI 候補を生成します。
次に、入力cntk.exeとして CNTK テキスト形式で格納します。
さらに、画像とグラウンド トゥルース ラベルに必要な CNTK 入力ファイルが生成されます。
このスクリプトでは、フォルダーの下に次のフォルダーとファイルが FastRCNN 生成されます。
proc- 生成されたコンテンツのルート フォルダー。grocery_2000- ROI を使用する2000例で生成されたすべてのフォルダーとファイルがgrocery含まれます。 別の数の ROIs を使用して再度実行すると、フォルダー名がそれに応じて変更されます。rois- テキスト ファイルに格納されている各画像の生の ROI 座標が含まれます。cntkFiles- 画像 (および)、ROI 座標 ()、およびtest.txtROI ラベルxx.roilabels.txt(train.txtxx.rois.txt)traintestの書式設定された CNTK 入力ファイルが含まれています。 (形式の詳細については 、以下を参照してください)。
すべてのパラメーターは、たとえば、トレーニングとテストに PARAMETERS.py使用される ROI の数を設定するための変更 cntk_nrRois = 2000 に含まれています。 パラメーターについては、以下の「 パラメーター」 セクションで説明します。
A2: スクリプト A2_RunWithBSModel.py は、cntk.exeと BrainScript 構成ファイル (構成の詳細) を使用して cntk を実行します。
トレーニング済みのモデルは、対応するprocサブフォルダーcntkFiles/Outputのフォルダーに格納されます。
トレーニング済みモデルは、トレーニング セットとテスト セットの両方で個別にテストされます。
各画像と対応する各 ROI のテスト中に、ラベルが予測され、ファイル test.z と train.z フォルダーに cntkFiles 格納されます。
A3: 評価ステップでは、CNTK 出力が解析され、 mAP が計算され、予測結果とグラウンド トゥルース注釈が比較されます。
重複する ROI をマージするには、非最大抑制が使用されます。 非最大抑制のしきい値は、(詳細) でPARAMETERS.py設定できます。
その他のスクリプト
データを視覚化および分析するために実行できるオプションのスクリプトは 3 つあります。
B1_VisualizeInputROIs.pyは候補入力 ROI を視覚化します。B2_EvaluateInputROIs.pyは、候補の ROIs に関するグランド トゥルースの ROIs のリコールを計算します。B3_VisualizeOutputROIs.py境界ボックスと予測ラベルを視覚化します。
Pascal VOC を実行する
Pascal VOC (PASCAL ビジュアル オブジェクト クラス) データは、オブジェクト クラス認識用の標準化された画像の既知のセットです。 Pascal VOC データでの CNTK Fast R-CNN のトレーニングまたはテストには、少なくとも 4 GB の RAM を備えた GPU が必要です。 または、CPU を使用して実行することもできますが、 時間 がかかります。
Pascal VOC データの取得
2007 (trainval and test) と 2012 (trainval) データと、元の論文で使用されている事前計算済みの ROI が必要です。
以下で説明するフォルダー構造に従う必要があります。
このスクリプトでは、Pascal データが .$CNTK_ROOT/Examples/Image/DataSets/Pascal
別のフォルダを使用している場合は、それに対応して設定pascalDataDirPARAMETERS.pyしてください。
- 2012 年のトレーニングデータをダウンロードして開梱する
DataSets/Pascal/VOCdevkit2012 - 2007 年のトレーニング用データをダウンロードしてアンパックし、
DataSets/Pascal/VOCdevkit2007 - 2007 テスト データをダウンロードして同じフォルダーに展開する
DataSets/Pascal/VOCdevkit2007 - 事前計算済みの ROI をダウンロードして開梱する
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
フォルダーは VOCdevkit2007 次のようになります (2012 の場合と同様)。
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Pascal VOC での CNTK の実行
Pascal VOC データで実行するには、in が PARAMETERS.pydataset に "pascal"設定されていることを確認します。
- ダウンロードした ROI データからトレーニングとテストのために CNTK 形式の入力ファイルを生成するために実行
A1_GenerateInputROIs.pyします。 - 高速 R-CNN モデルとコンピューティング テスト結果をトレーニングするために実行
A2_RunWithBSModel.pyします。 - トレーニング済みモデルの mAP (平均平均精度) を計算するために実行
A3_ParseAndEvaluateOutput.pyします。- これは進行中であり、新しいベースライン モデルをトレーニングしているため、結果は暫定的であることに注意してください。
- エンコード エラーを回避するには、ファイル fastRCNN/pascal_voc.py と fastRCNN/voc_eval.py の CNTK マスターの最新バージョンを必ず使用してください。
独自のデータでトレーニングする
カスタム データセットを準備する
オプション #1: Visual オブジェクトタグ付けツール (推奨)
Visual Object Tagging Tool (VOTT) は、ビデオと画像のアセットにタグ付けするためのクロス プラットフォーム注釈ツールです。

VOTT には、次の 機能があります。
- Camshift 追跡アルゴリズムを使用した、ビデオ内のオブジェクトのコンピューター支援タグ付けと追跡。
- オブジェクト検出モデルをトレーニングするために、タグと資産を CNTK Fast-RCNN 形式にエクスポートします。
- トレーニング済みの CNTK 物体検出モデルを新しいビデオで実行および検証して、より強力なモデルを生成します。
VOTT で注釈を付ける方法:
オプション #2: 注釈スクリプトの使用
独自のデータ セットで CNTK Fast R-CNN モデルをトレーニングするために、画像の四角形の領域に注釈を付け、これらの領域にラベルを割り当てる 2 つのスクリプトを提供します。
スクリプトは、Fast R-CNN (A1_GenerateInputROIs.py) を実行する最初の手順で必要に応じて、正しい形式で注釈を格納します。
まず、次のフォルダー構造にイメージを格納します
<your_image_folder>/negative- オブジェクトを含まないトレーニングに使用されるイメージ<your_image_folder>/positive- オブジェクトを含むトレーニングに使用されるイメージ<your_image_folder>/testImages- オブジェクトを含むテストに使用されるイメージ
負の画像の場合は、注釈を作成する必要はありません。 他の 2 つのフォルダーでは、指定されたスクリプトを使用します。
- 画像に境界ボックスを描画するために実行
C1_DrawBboxesOnImages.pyします。- 実行する前のスクリプト セット
imgDir = <your_image_folder>(/positiveまたは/testImages) 内。 - マウス カーソルを使用して注釈を追加します。 イメージ内のすべてのオブジェクトに注釈が付けられたら、キー 'n' を押すと .bboxes.txt ファイルが書き込まれた後、次の画像に進み、'u' は最後の四角形を元に戻す (削除) し、'q' は注釈ツールを終了します。
- 実行する前のスクリプト セット
- 境界ボックスにラベルを割り当てるには、実行
C2_AssignLabelsToBboxes.pyします。- 実行前のスクリプト セット
imgDir = <your_image_folder>(/positiveまたは/testImages) で... - ...たとえば
classes = ("dog", "cat", "octopus")、オブジェクト カテゴリを反映するようにスクリプト内のクラスを調整します。 - スクリプトは、各画像に対して手動で注釈付けされた四角形を読み込み、1 つずつ表示し、ウィンドウの左側にあるそれぞれのボタンをクリックしてオブジェクト クラスを指定するようにユーザーに求めます。 "未決定" または "除外" としてマークされたグラウンド トゥルース注釈は、それ以降の処理から完全に除外されます。
- 実行前のスクリプト セット
カスタム データセットでトレーニングする
スクリプト A1 から A3 を使用して CNTK Fast R-CNN を実行する前に、データ セットを次に追加する PARAMETERS.py必要があります。
dataset = "CustomDataset"を設定します- Python クラス
CustomDatasetの下にデータ セットのパラメーターを追加します。 からパラメーターをコピーすることから始めることができます。GroceryParameters- オブジェクト カテゴリを反映するように クラス を調整します。 上記の例に従うと、次のようになります
self.classes = ('__background__', 'dog', 'cat', 'octopus')。 self.imgDir = <your_image_folder>を設定します。- 必要に応じて、ROI の生成や排除など、より多くのパラメーターを調整できます ( 「パラメーター」 セクションを参照)。
- オブジェクト カテゴリを反映するように クラス を調整します。 上記の例に従うと、次のようになります
あなた自身のデータでトレーニングする準備ができました! (おもちゃの例と 同じ手順 を使用します)。
技術的な詳細
パラメーター
の主なパラメーター PARAMETERS.py は次のとおりです。
dataset- 使用するデータ セットcntk_nrRois- トレーニングとテストに使用する ROI の数nmsThreshold- 非最大抑制しきい値 (範囲 [0,1])。 低いほど、より多くのROIが組み合わされます。 評価と視覚化の両方に使用されます。
ROI 生成のすべてのパラメーター (最小および最大幅、高さなど) は、Python クラスParametersの下でPARAMETERS.py説明されています。 これらはすべて、妥当な既定値に設定されます。
使用しているデータ セットに # project-specific parameters 対応するセクションで上書きできます。
CNTK の構成
Fast R-CNN のトレーニングとテストに使用される CNTK BrainScript 構成ファイルは fastrcnn.cntk です。
ネットワークを構築する部分は、コマンドのBrainScriptNetworkBuilderTrainセクションです。
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
最初の行では、事前トレーニング済みの AlexNet が基本モデルとして読み込まれます。 ネットワークの次の 2 つの部分が複製されます。 convLayers 一定の重みを持つ畳み込み層が含まれています。つまり、それ以上トレーニングされていません。
fcLayers には、事前トレーニング済みの重みを持つ完全に接続されたレイヤーが含まれており、さらにトレーニングされます。
ノード名 network.featuresなどは、 network.conv5_y cntk.exe呼び出しのログ出力 (スクリプトのログ出力 A2_RunWithBSModel.py に含まれる) を調べることから派生できます。
model definition(model (features, rois) = ...) はまず、チャネルとピクセルごとに 114 を減算して特徴を正規化します。
次に、正規化された特徴が次にconvLayers続いてプッシュされ、ROIPooling最後に .fcLayers
ROI プーリング レイヤーの出力図形 (幅:高さ) は、AlexNet モデルから事前にトレーニングfcLayersされた図形のサイズであるため、設定(6:6)されます。 の出力 fcLayers は、各 ROI のラベル (NumLabels) ごとに 1 つの値を予測する高密度レイヤーに送られます。
次の 6 行で入力が定義されます。
- サイズ 1000 x 1000 x 3 (
$ImageH$:$ImageW$:$ImageC$) の画像。 - 各 ROI のグラウンド トゥルース ラベル (
$NumLabels$:$NumTrainROIs$) - および (x、y、w、h) に対応する ROI (
4:$NumTrainROIs$) あたりの 4 つの座標は、すべて画像の全幅と高さに対して相対的です。
z = model (features, rois) は、入力イメージと ROI を定義されたネットワーク モデルにフィードし、出力 zを割り当てます。
ROI ごとの予測エラーを考慮するために、条件 (CrossEntropyWithSoftmax) とエラー (ClassificationError) の両方が指定されます axis = 1 。
CNTK 構成のリーダー セクションを次に示します。 次の 3 つの逆シリアライザーを使用します。
ImageDeserializerを使用してイメージ データを読み取る。 画像ファイル名train.txtを取得し、縦横比を維持しながらイメージを目的の幅と高さにスケーリングし(空の領域114を埋め込む)、テンソルを正しい入力形状に変換します。- 1 つは
CNTKTextFormatDeserializerROI 座標を読み取りますtrain.rois.txt。 - 1 秒で
CNTKTextFormatDeserializerROI ラベルを読み取りますtrain.roislabels.txt。
入力ファイル形式については、次のセクションで説明します。
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
CNTK 入力ファイル形式
CNTK Fast R-CNN には、上記の 3 つの逆シリアライザーに対応する 3 つの入力ファイルがあります。
train.txtには、最初にシーケンス番号、次に画像ファイル名、最後に0(現在は ImageReader の従来の理由から必要です) が含まれています。
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(CNTK テキスト形式) は、最初にシーケンス番号を各行に含み、その後に|rois識別子を続けて番号のシーケンスを格納します。 これらは、ROI の (x、y、w、h) に対応する 4 つの数値のグループであり、すべて画像の全幅と高さに対して相対的です。 1 行あたり合計 4 * rois の数があります。
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(CNTK テキスト形式) は、最初にシーケンス番号を各行に含み、その後に|roiLabels識別子を続けて番号のシーケンスを格納します。 これらは、1 つのホットな表現でグラウンド トゥルース クラスをエンコードする ROI ごとに、ラベル数の数値 (ゼロまたは 1) のグループです。 1 行あたりのラベル数 * rois 数の合計があります。
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
アルゴリズムの詳細
高速 R-CNN
物体検出用のR-CNNは、2014年に ロス・ギルシックらによって初めて発表され、 パスカルVOCという分野の主要な物体認識課題の1つで、以前の最先端のアプローチを上回っています。 それ以来、高速 R-CNN と高速 R-CNN の 2 つのフォローアップ ペーパーが公開されました。
R-CNN の基本的な考え方は、もともと何百万もの注釈付き画像を使用して画像分類用にトレーニングされたディープ ニューラル ネットワークを取得し、物体検出の目的で変更することです。 最初の R-CNN ペーパーからの基本的な考え方は、次の図に示されています (このペーパーから取り上げられます): (1) 入力画像を指定すると、最初の手順で (2) 多数のリージョン提案が生成されます。 (3) これらのリージョン提案または関心領域 (ROI) は、それぞれ独立してネットワークを介して送信され、各 ROI に対して 4096 個の浮動小数点値などのベクトルが出力されます。 最後に、(4) 4096 float ROI 表現を入力として受け取り、ラベルと信頼度を各 ROI に出力する分類子が学習されます。
この方法は精度の点では適切に機能しますが、ニューラル ネットワークは ROI ごとに評価する必要があるため、計算には非常にコストがかかります。 高速 R-CNN は、ほとんどのネットワーク (具体的には畳み込みレイヤー) をイメージごとに 1 回評価するだけで、この欠点に対処します。 著者によると、これはテスト中に213倍の高速化と、精度を失うことなくトレーニング中に9倍の高速化につながります。 これは、ROI を畳み込みフィーチャ マップに投影し、最大プーリングを実行して、次のレイヤーが期待する目的の出力サイズを生成する ROI プール レイヤーを使用して実現されます。 このチュートリアルで使用する AlexNet の例では、ROI プーリング レイヤーは、最後の畳み込みレイヤーと最初の完全に接続されたレイヤーの間に配置されます ( BrainScript コードを参照)。
R-CNN の論文で使用される元の Caffe の実装は、GitHub で確認できます。 RCNN、 Fast R-CNN、 高速 R-CNN。 このチュートリアルでは、これらのリポジトリのコードの一部を使用します。特に SVM のトレーニングとモデルの評価には特に (ただし、排他的ではありません) 。
SVM と NN のトレーニング
Patrick Buehler は、CNTK Fast R-CNN 出力で SVM をトレーニングする方法 (最後に完全に接続されたレイヤーの 4096 機能を使用) に関する説明と、 ここでの長所と短所に関するディスカッションを提供します。
選択的検索
選択的検索 は、実際のオブジェクトのクラスに関係なく、画像内で可能なオブジェクトの場所の大規模なセットを検索するためのメソッドです。 画像ピクセルをセグメントにクラスタリングし、階層クラスタリングを実行して、同じオブジェクトのセグメントをオブジェクト提案に結合することで機能します。



選択的検索から検出された ROI を補完するために、さまざまなスケールと縦横比で画像を均一にカバーする ROI を追加します。 最初の図は、選択検索の出力例を示しています。この例では、可能な各オブジェクトの場所が緑色の四角形で視覚化されています。 小さすぎる、大きすぎるなどの ROI は破棄され (2 番目の画像)、最終的にイメージを一様にカバーする ROI が追加されます (3 番目の画像)。 次に、これらの四角形は、R-CNN パイプラインで目的のリージョン (ROI) として使用されます。
ROI 生成の目標は、イメージ内のオブジェクトをできるだけ多くカバーする、小さな ROI のセットを見つけることです。 この計算は十分に迅速に行う必要があり、同時に異なるスケールと縦横比でオブジェクトの場所を検索する必要があります。 選択的検索は、このタスクに対して良好なパフォーマンスを発揮し、トレードオフを速めるのに十分な精度で示されました。
NMS (非最大抑制)
物体検出方法は、多くの場合、画像内の同じ物体を完全または部分的にカバーする複数の検出を出力します。
オブジェクトをカウントし、イメージ内の正確な場所を取得できるようにするには、これらの ROI をマージする必要があります。
これは従来、非最大抑制 (NMS) と呼ばれる手法を使用して行われます。 使用している NMS のバージョン (および R-CNN パブリケーションでも使用されていた) は、ROI をマージするのではなく、オブジェクトの実際の場所に最適な ROI を特定し、他のすべての ROI を破棄しようとします。 これは、信頼度が最も高い ROI を繰り返し選択し、この ROI と大幅に重複し、同じクラスに分類されている他のすべての ROI を削除することによって実装されます。 重複のしきい値は、(詳細) でPARAMETERS.py設定できます。
検出結果の前 (最初の画像) と後 (2 番目の画像) 非最大抑制:

mAP (平均平均精度)
トレーニングが完了すると、精度、再現率、精度、領域アンダーカーブなど、さまざまな基準を使用してモデルの品質を測定できます。Pascal VOC オブジェクト認識チャレンジに使用される一般的なメトリックは、各クラスの平均精度 (AP) を測定することです。 平均精度の次の説明は 、エバリンガムらから取られます。 平均平均精度 (mAP) は、すべてのクラスの AP に対する平均を取得して計算されます。
特定のタスクとクラスの場合、精度/再現率曲線は、メソッドのランク付けされた出力から計算されます。 リコールは、特定のランクの上にランク付けされたすべての肯定的な例の割合として定義されます。 有効桁数は、正のクラスからのランクを超えるすべての例の割合です。 AP は精度/リコール曲線の形状を要約し、11 の等間隔リコール レベル [0,0.1, . . . ,1]:
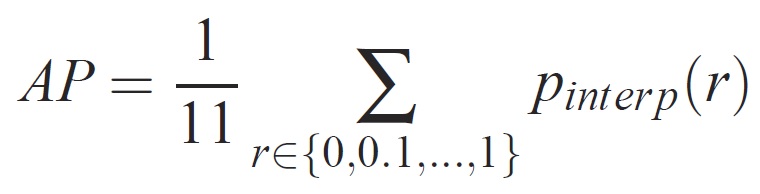
各リコール レベル r の有効桁数は、対応するリコールが r を超えるメソッドに対して測定された最大有効桁数を取ることによって補間されます。
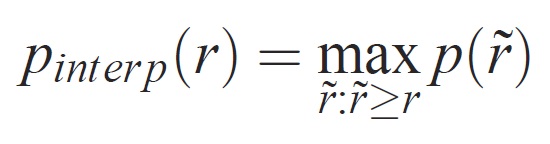
ここで p( ̃r) は、リコール ̃r で測定された精度です。 この方法で精度/リコール曲線を補間する目的は、例のランク付けの小さなバリエーションによって引き起こされる、精度/再現率曲線の "ウィグル" の影響を減らすことです。 高いスコアを取得するには、メソッドがすべてのレベルのリコールで精度を持つ必要があります。これにより、精度の高い例のサブセットのみを取得するメソッド (たとえば、車の側面図) が罰されます。