高速 R-CNN を使用した物体検出
目次
まとめ

このチュートリアルでは、CNTK Python API で Fast R-CNN を使用する方法について説明します。 BrainScript と cnkt.exe を使用した高速 R-CNN について説明 します。
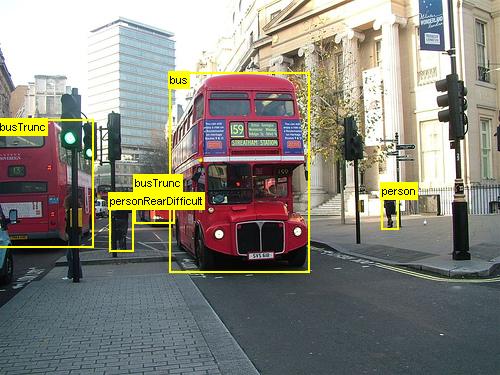
上記は、このチュートリアルで使用する食料品データセット (左) と Pascal VOC データ セット (右) の画像とオブジェクト注釈の例です。
高速R-CNN は、2015年に ロス・ギルシック によって提案された物体検出アルゴリズムです。 この論文はICCV 2015に受け入れられ、アーカイブされています https://arxiv.org/abs/1504.08083. 高速 R-CNN は、以前の作業に基づいて構築され、深い畳み込みネットワークを使用してオブジェクト提案を効率的に分類します。 以前の作業と比較して、Fast R-CNN は、畳み込みレイヤーからの計算を再利用できる 対象領域プール スキームを採用しています。
セットアップ
この例のコードを実行するには、CNTK Python 環境が必要です (セットアップのヘルプについては 、こちらを 参照してください)。 cntk Python 環境に次の追加パッケージをインストールしてください
pip install opencv-python easydict pyyaml dlib
境界ボックス回帰と非最大抑制用の事前コンパイル済みバイナリ
このフォルダー Examples\Image\Detection\utils\cython_modules には、高速 R-CNN を実行するために必要な事前コンパイル済みバイナリが含まれています。 リポジトリに現在含まれているバージョンは、Windows 用 Python 3.5、Python 3.5、Linux 用 3.6、すべて 64 ビットです。 別のバージョンが必要な場合は、次の手順に従ってコンパイルできます。
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
生成された cython_bbox バイナリと cpu_nms (または gpu_nms) バイナリのコピー元を $FRCN_ROOT/lib/utils コピーします $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules。
データとベースライン モデルの例
事前トレーニング済みの AlexNet モデルを Fast-R-CNN トレーニングの基礎として使用します (VGG またはその他の基本モデルの場合は、 別の基本モデルの使用を参照してください)。 サンプル データセットと事前トレーニング済みの AlexNet モデルの両方をダウンロードするには、FastRCNN フォルダーから次の Python コマンドを実行します。
python install_data_and_model.py
- 別の基本モデルを使用する方法について説明します
- Pascal VOC データで高速 R-CNN を実行する方法について説明します
- 独自のデータで高速 R-CNN を実行する方法について説明します
おもちゃの例を実行する
高速 R-CNN 実行をトレーニングして評価するには
python run_fast_rcnn.py
基本モデルとして AlexNet を使用する 2000 ROIs を使用した Grocery でのトレーニングの結果は、次のようになります。
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
フォルダーから開 FastRCNN_config.py いて設定した画像の予測境界ボックスとラベルを FastRCNN 視覚化するには
__C.VISUALIZE_RESULTS = True
実行すると、イメージがフォルダーpython run_fast_rcnn.pyにFastRCNN/Output/Grocery/保存されます。
パスカル VOC でトレーニングする
Pascal データをダウンロードし、CNTK 形式で Pascal の注釈ファイルを作成するには、次のスクリプトを実行します。
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
のdataset_cfg方法run_fast_rcnn.pyをget_configuration()変更します。
from utils.configs.Pascal_config import cfg as dataset_cfg
これで、Pascal VOC 2007 データを使用して python run_fast_rcnn.pyトレーニングするように設定されています。 トレーニングに時間がかかる場合があることに注意してください。
独自のデータでトレーニングする
カスタム データセットを準備する
オプション #1: Visual オブジェクトタグ付けツール (推奨)
Visual Object Tagging Tool (VOTT) は、ビデオと画像のアセットにタグ付けするためのクロス プラットフォーム注釈ツールです。

VOTT には、次の 機能があります。
- Camshift 追跡アルゴリズムを使用した、ビデオ内のオブジェクトのコンピューター支援タグ付けと追跡。
- オブジェクト検出モデルをトレーニングするために、タグと資産を CNTK Fast-RCNN 形式にエクスポートします。
- トレーニング済みの CNTK 物体検出モデルを新しいビデオで実行および検証して、より強力なモデルを生成します。
VOTT で注釈を付ける方法:
オプション #2: 注釈スクリプトの使用
独自のデータ セットで CNTK Fast R-CNN モデルをトレーニングするために、画像の四角形の領域に注釈を付け、これらの領域にラベルを割り当てる 2 つのスクリプトを提供します。
スクリプトは、Fast R-CNN (A1_GenerateInputROIs.py) を実行する最初の手順で必要に応じて、正しい形式で注釈を格納します。
まず、次のフォルダー構造にイメージを格納します
<your_image_folder>/negative- オブジェクトを含まないトレーニングに使用されるイメージ<your_image_folder>/positive- オブジェクトを含むトレーニングに使用されるイメージ<your_image_folder>/testImages- オブジェクトを含むテストに使用されるイメージ
負の画像の場合は、注釈を作成する必要はありません。 他の 2 つのフォルダーでは、指定されたスクリプトを使用します。
- 画像に境界ボックスを描画するために実行
C1_DrawBboxesOnImages.pyします。- 実行する前のスクリプト セット
imgDir = <your_image_folder>(/positiveまたは/testImages) 内。 - マウス カーソルを使用して注釈を追加します。 イメージ内のすべてのオブジェクトに注釈が付けられたら、キー 'n' を押すと .bboxes.txt ファイルが書き込まれた後、次の画像に進み、'u' は最後の四角形を元に戻す (削除) し、'q' は注釈ツールを終了します。
- 実行する前のスクリプト セット
- 境界ボックスにラベルを割り当てるには、実行
C2_AssignLabelsToBboxes.pyします。- 実行前のスクリプト セット
imgDir = <your_image_folder>(/positiveまたは/testImages) で... - ...たとえば
classes = ("dog", "cat", "octopus")、オブジェクト カテゴリを反映するようにスクリプト内のクラスを調整します。 - スクリプトは、各画像に対して手動で注釈付けされた四角形を読み込み、1 つずつ表示し、ウィンドウの左側にあるそれぞれのボタンをクリックしてオブジェクト クラスを指定するようにユーザーに求めます。 "未決定" または "除外" としてマークされたグラウンド トゥルース注釈は、それ以降の処理から完全に除外されます。
- 実行前のスクリプト セット
カスタム データセットでトレーニングする
説明したフォルダー構造にイメージを格納し、それらに注釈を付けた後、実行してください
python Examples/Image/Detection/utils/annotations/annotations_helper.py
そのスクリプト内のフォルダーをデータ フォルダーに変更した後。 最後に、既存の MyDataSet_config.py 例に utils\configs 従ってフォルダーに作成します。
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
高速 R-CNN では使用されず、高速 R-CNN でのみ使用されることに __C.CNTK.PROPOSAL_LAYER_SCALES 注意してください。
データの高速 R-CNN をトレーニングして評価するには、dataset_cfg次のrun_fast_rcnn.py方法でget_configuration()変更します。
from utils.configs.MyDataSet_config import cfg as dataset_cfg
を実行 python run_fast_rcnn.pyします。
技術的な詳細
高速 R-CNN アルゴリズムについては、「 アルゴリズムの詳細 」セクションで、CNTK Python API での実装方法の概要と共に説明します。 このセクションでは、Fast R-CNN の構成と、さまざまな基本モデルの使用方法について説明します。
パラメーター
パラメーターは、次の 3 つの部分にグループ化されます。
- 検出パラメーター (参照
FastRCNN/FastRCNN_config.py) - データ セット パラメーター (例
utils/configs/Grocery_config.pyを参照) - 基本モデル パラメーター (例
utils/configs/AlexNet_config.pyを参照)
3 つの部分が読み込まれ、メソッドrun_fast_rcnn.pyにget_configuration()マージされます。 このセクションでは、検出パラメーターについて説明します。 データ セット パラメーターについては 、ここで説明します。基本モデル パラメーター については、ここで説明します。 次に、最も重要なパラメーターを説明します FastRCNN_config.py。 すべてのパラメーターもファイルにコメント化されます。 この構成では、 EasyDict 入れ子になったディクショナリに簡単にアクセスできるパッケージが使用されます。
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
ROI 提案は、パッケージからの dlib 選択的検索実装を使用して、最初のエポックでその場で計算されます。 生成される提案の数は、パラメーターによって __C.NUM_ROI_PROPOSALS 制御されます。 2000 件程度の提案を使用することをお勧めします。 回帰ヘッドは、少なくとも __C.BBOX_THRESHグラウンド トゥルース ボックスと重複 (IoU) を持つ ROI でのみトレーニングされます。
__C.INPUT_ROIS_PER_IMAGE は、画像ごとのグラウンド トゥルース注釈の最大数を指定します。 現在、CNTK では最大数を設定する必要があります。 注釈が少ない場合は、内部的に埋め込まれます。 __C.IMAGE_WIDTH は __C.IMAGE_HEIGHT 、入力イメージのサイズ変更と埋め込みに使用されるディメンションです。
__C.TRAIN.USE_FLIPPED = True は、すべての画像を他のすべてのエポックに反転することでトレーニング データを強化します。つまり、最初のエポックにはすべての通常の画像があり、2 番目のエポックにはすべての画像が反転されます。 __C.TRAIN_CONV_LAYERS は、入力から畳み込みフィーチャ マップまでの畳み込みレイヤーをトレーニングするか固定するかを決定します。 conv レイヤーの重みを固定することは、基本モデルからの重みが取得され、トレーニング中に変更されないことを意味します。 (トレーニングする conv レイヤーの数を指定することもできます。 「別の基本モデルの使用」セクションを参照してください)。
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD は、評価で重複する予測境界ボックスを破棄するために使用される NMS しきい値です。 しきい値を小さくすると、削除が少なくなり、最終的な出力で予測される境界ボックスが増えます。 リーダーを設定 __C.USE_PRECOMPUTED_PROPOSALS = True すると、テキスト ファイルから事前計算済みの ROI が読み取られます。 たとえば、Pascal VOC データのトレーニングに使用します。 ファイル名 __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE とで __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE 指定されています Examples/Image/Detection/utils/configs/Pascal_config.py。
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
上記のパラメーターは、dlib の選択的検索を構成しています。 詳細については 、dlib のホームページを参照してください。 次の追加パラメーターは、生成された ROIs w.r.t. の最小および最大側長、面積、縦横比をフィルター処理するために使用されます。
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
選択的検索で要求された値よりも多くの ROI が返される場合は、ランダムにサンプリングされます。 返される ROI が少ない場合は、指定した値を使用して、通常のグリッドに追加の ROI が生成されます __C.roi_grid_aspect_ratios。
別の基本モデルを使用する
別の基本モデルを使用するには、次の方法で別のrun_fast_rcnn.pyモデル構成を選択するget_configuration()必要があります。 すぐに 2 つのモデルがサポートされます。
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
VGG16 モデルをダウンロードするには、次のダウンロード スクリプト <cntkroot>/PretrainedModelsを使用してください。
python download_model.py VGG16_ImageNet_Caffe
別の異なる基本モデルを使用する場合は、たとえば、構成ファイル utils/configs/VGG16_config.py をコピーし、ベース モデルに従って変更する必要があります。
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
基本モデルのノード名を調査するには、次のメソッドcntk.logging.graphをplot()使用します。 CNTK での roi プールはまだ roi 平均プーリングをサポートしていないため、ResNet モデルは現在サポートされていないことに注意してください。
アルゴリズムの詳細
高速 R-CNN
物体検出用のR-CNNは、2014年に ロス・ギルシックらによって初めて発表され、 パスカルVOCという分野の主要な物体認識課題の1つで、以前の最先端のアプローチを上回っています。 それ以来、高速 R-CNN と高速 R-CNN の 2 つのフォローアップ ペーパーが公開されました。
R-CNN の基本的な考え方は、もともと何百万もの注釈付き画像を使用して画像分類用にトレーニングされたディープ ニューラル ネットワークを取得し、物体検出の目的で変更することです。 最初の R-CNN ペーパーからの基本的な考え方は、次の図に示されています (このペーパーから取り上げられます): (1) 入力画像を指定すると、最初の手順で (2) 多数のリージョン提案が生成されます。 (3) これらのリージョン提案または関心領域 (ROI) は、それぞれ独立してネットワークを介して送信され、各 ROI に対して 4096 個の浮動小数点値などのベクトルが出力されます。 最後に、(4) 4096 float ROI 表現を入力として受け取り、ラベルと信頼度を各 ROI に出力する分類子が学習されます。

この方法は精度の点では適切に機能しますが、ニューラル ネットワークは ROI ごとに評価する必要があるため、計算には非常にコストがかかります。 高速 R-CNN は、ほとんどのネットワーク (具体的には畳み込みレイヤー) をイメージごとに 1 回評価するだけで、この欠点に対処します。 著者によると、これはテスト中に213倍の高速化と、精度を失うことなくトレーニング中に9倍の高速化につながります。 これは、ROI を畳み込みフィーチャ マップに投影し、最大プーリングを実行して、次のレイヤーが期待する目的の出力サイズを生成する ROI プール レイヤーを使用して実現されます。
このチュートリアルで使用する AlexNet の例では、ROI プーリング レイヤーは、最後の畳み込みレイヤーと最初の完全に接続されたレイヤーの間に配置されます。 以下に示す CNTK Python API コードでは、 conv_layers ネットワークの 2 つの部分 、および fc_layers. 次に、入力画像が最初に正規化され、レイヤーと予測ヘッドとfc_layers回帰ヘッドが追加conv_layersroipoolingされ、それぞれ候補 ROI ごとのクラス ラベルと回帰係数が予測されます。
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
R-CNN の論文で使用される元の Caffe の実装は、GitHub で確認できます。 RCNN、 Fast R-CNN、 高速 R-CNN。
SVM と NN のトレーニング
Patrick Buehler は、CNTK Fast R-CNN 出力で SVM をトレーニングする方法 (最後に完全に接続されたレイヤーの 4096 機能を使用) に関する説明と、 ここでの長所と短所に関するディスカッションを提供します。
選択的検索
選択的検索 は、実際のオブジェクトのクラスに関係なく、画像内で可能なオブジェクトの場所の大規模なセットを検索するためのメソッドです。 画像ピクセルをセグメントにクラスタリングし、階層クラスタリングを実行して、同じオブジェクトのセグメントをオブジェクト提案に結合することで機能します。



選択的検索から検出された ROI を補完するために、さまざまなスケールと縦横比で画像を均一にカバーする ROI を追加します。 左側の画像は、選択検索の出力例を示しています。この例では、可能な各オブジェクトの場所が緑色の四角形で視覚化されています。 小さすぎる、大きすぎるなどの ROI は破棄 (中央) され、最終的にイメージを一様にカバーする ROI が追加されます (右)。 次に、これらの四角形は、R-CNN パイプラインで目的のリージョン (ROI) として使用されます。
ROI 生成の目標は、イメージ内のオブジェクトをできるだけ多くカバーする、小さな ROI のセットを見つけることです。 この計算は十分に迅速に行う必要があり、同時に異なるスケールと縦横比でオブジェクトの場所を検索する必要があります。 選択的検索は、このタスクに対して良好なパフォーマンスを発揮し、トレードオフを速めるのに十分な精度で示されました。
NMS (非最大抑制)
物体検出方法は、多くの場合、画像内の同じ物体を完全または部分的にカバーする複数の検出を出力します。
オブジェクトをカウントし、イメージ内の正確な場所を取得できるようにするには、これらの ROI をマージする必要があります。
これは従来、非最大抑制 (NMS) と呼ばれる手法を使用して行われます。 使用している NMS のバージョン (および R-CNN パブリケーションでも使用されていた) は、ROI をマージするのではなく、オブジェクトの実際の場所に最適な ROI を特定し、他のすべての ROI を破棄しようとします。 これは、信頼度が最も高い ROI を繰り返し選択し、この ROI と大幅に重複し、同じクラスに分類されている他のすべての ROI を削除することによって実装されます。 重複のしきい値は、(詳細) でPARAMETERS.py設定できます。
検出結果の前 (左) と後 (右) 非最大抑制:


mAP (平均平均精度)
トレーニングが完了すると、精度、再現率、精度、領域アンダーカーブなど、さまざまな基準を使用してモデルの品質を測定できます。Pascal VOC オブジェクト認識チャレンジに使用される一般的なメトリックは、各クラスの平均精度 (AP) を測定することです。 平均精度の次の説明は 、エバリンガムらから取られます。 平均平均精度 (mAP) は、すべてのクラスの AP に対する平均を取得して計算されます。
特定のタスクとクラスの場合、精度/再現率曲線は、メソッドのランク付けされた出力から計算されます。 リコールは、特定のランクの上にランク付けされたすべての肯定的な例の割合として定義されます。 有効桁数は、正のクラスからのランクを超えるすべての例の割合です。 AP は精度/リコール曲線の形状を要約し、11 の等間隔リコール レベル [0,0.1, . . . ,1]:
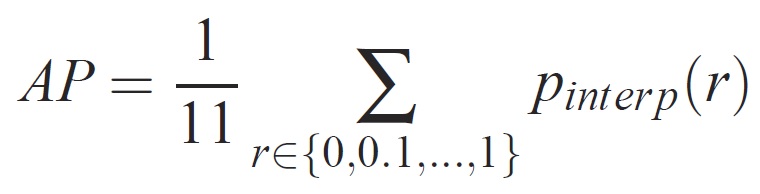
各リコール レベル r の有効桁数は、対応するリコールが r を超えるメソッドに対して測定された最大有効桁数を取ることによって補間されます。
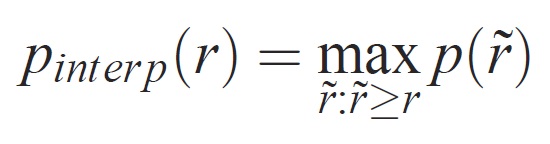
ここで p( ̃r) は、リコール ̃r で測定された精度です。 この方法で精度/リコール曲線を補間する目的は、例のランク付けの小さなバリエーションによって引き起こされる、精度/再現率曲線の "ウィグル" の影響を減らすことです。 高いスコアを取得するには、メソッドがすべてのレベルのリコールで精度を持つ必要があります。これにより、精度の高い例のサブセットのみを取得するメソッド (たとえば、車の側面図) が罰されます。