Azure Data Lake Analytics にジョブ ブラウザーとジョブ ビューを使用する
重要
Azure Data Lake Analytics は 2024 年 2 月 29 日に廃止されました。 このお知らせで詳細を学びましょう。
データ分析の場合、組織は Azure Synapse Analytics または Microsoft Fabric を使用できます。
Azure Data Lake Analytics サービスは、送信されたジョブをクエリ ストアにアーカイブします。 この記事では、Azure Data Lake Tools for Visual Studio でジョブ ブラウザーとジョブ ビューを使用して、ジョブの履歴情報を検索する方法について説明します。
既定では、Data Lake Analytics サービスはジョブを 30 日間アーカイブします。 有効期限は、カスタマイズされた有効期限ポリシーを構成することで、Azure portal から構成できます。 有効期限が切れた後、ジョブ情報にアクセスすることはできません。
前提条件
Data Lake Tools for Visual Studio の前提条件を参照してください。
ジョブ ブラウザーを開く
Visual Studio で サーバー エクスプローラー>Azure>Data Lake Analytics>Jobs を使用してジョブ ブラウザーにアクセスします。 ジョブ ブラウザーを使用すると、Data Lake Analytics アカウントのクエリ ストアにアクセスできます。 ジョブ ブラウザーの左側にクエリ ストアが表示され、基本的なジョブ情報が表示され、右側にジョブ ビューに詳細なジョブ情報が表示されます。
職務一覧
ジョブ ビューには、ジョブの詳細情報が表示されます。 ジョブを開くには、ジョブ ブラウザーでジョブをダブルクリックするか、[ジョブ ビュー] をクリックして Data Lake メニューからジョブを開きます。 ジョブの URL が入力されたダイアログが表示されます。
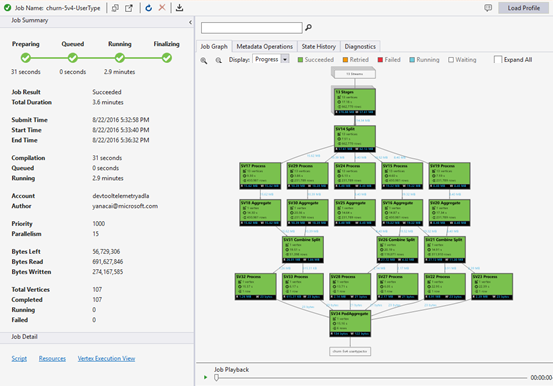
ジョブ ビューには次のものが含まれます。
ジョブの概要
ジョブ ビューを更新して、ジョブの実行に関するより新しい情報を表示します。
ジョブの状態 (グラフ):
ジョブステータスはジョブフェーズの概要を説明します。
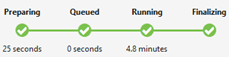
準備中: スクリプトをクラウドにアップロードし、コンパイル サービスを使用してスクリプトをコンパイルおよび最適化します。
ジョブがキュー待ちになるのは、十分なリソースを待っている場合や、アカウントごとの最大同時実行ジョブ数の制限を超えた場合です。 優先順位の設定は、キューに入れたジョブのシーケンスを決定します。数値が小さい場合は、優先順位が高くなります。
実行中: ジョブは実際に Data Lake Analytics アカウントで実行されています。
最終処理: ジョブが完了しています (ファイルの最終処理など)。
作業はすべてのフェーズで失敗する可能性があります。 たとえば、準備フェーズのコンパイル エラー、キューに入ったフェーズでのタイムアウト エラー、実行中フェーズでの実行エラーなどです。
基本情報
基本的なジョブ情報は、[ジョブの概要] パネルの下部に表示されます。
![テキスト ボックスに説明がある [ジョブの概要] を示すスクリーンショット。](media/data-lake-analytics-data-lake-tools-view-jobs/data-lake-tools-job-info.png)
- ジョブの結果: 成功または失敗しました。 ジョブは、すべてのフェーズで失敗する可能性があります。
- 合計期間: 送信時間と終了時刻の間の壁時計時間 (期間)。
- 合計コンピューティング時間: すべての頂点実行時間の合計。ジョブが 1 つの頂点でのみ実行される時間と見なすことができます。 頂点に関するより詳しい情報は、「Total Vertices」を参照してください。
- 送信/開始/終了時刻: Data Lake Analytics サービスがジョブの送信を受け取るか、ジョブの実行を開始するか、ジョブを正常に終了しないかの時刻。
- コンパイル/キュー/実行中: 準備/キュー/実行中フェーズで費やされたウォール クロック時間。
- アカウント: ジョブの実行に使用される Data Lake Analytics アカウント。
- 作成者: ジョブを送信したユーザー。実際のユーザーのアカウントまたはシステム アカウントを指定できます。
- 優先順位: 仕事の優先度。 数値が小さい方が優先度が高くなります。 これは、キュー内のジョブのシーケンスにのみ影響します。 優先度を高く設定しても、実行中のジョブは優先されません。
- 並列処理: 要求された同時 Azure Data Lake Analytics ユニット (ADLAU) の最大数 (頂点とも呼ばれます)。 現在、1 つの頂点は 2 つの仮想コアと 6 GB の RAM を持つ 1 つの VM に相当しますが、これは将来の Data Lake Analytics 更新プログラムでアップグレードされる可能性があります。
- 残りバイト数: ジョブが完了するまで処理する必要があるバイト数。
- 読み取り/書き込みバイト数: ジョブの実行開始後に読み取り/書き込まれたバイト数。
- 頂点の合計数: ジョブは多数の作業に分割され、各作業は頂点と呼ばれます。 この値は、仕事が構成される作業の数を示します。 頂点は基本的なプロセス ユニット (Azure Data Lake Analytics Unit (ADLAU) とも呼ばれます) と見なすことができます。頂点は並列処理で実行できます。
- 完了/実行中/失敗: 完了/実行中/失敗した頂点の数。 頂点は、ユーザー コードとシステムエラーの両方によって失敗する可能性がありますが、システムは失敗した頂点を数回自動的に再試行します。 再試行後も頂点が失敗した場合、ジョブ全体が失敗します。
ジョブ グラフ
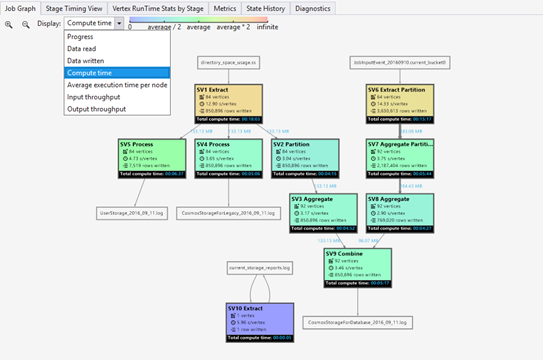
U-SQL スクリプトは、入力データを出力データに変換するロジックを表します。 スクリプトは、準備フェーズでコンパイルされ、物理実行プランに最適化されます。 ジョブ グラフは、物理実行プランを表示することです。 次の図にこのプロセスを示します。
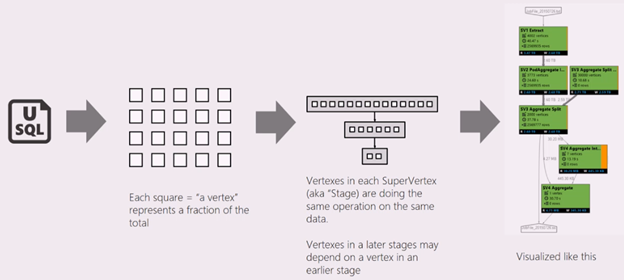
仕事は多くの作業に細かく分けられます。 各作業は頂点と呼ばれます。 頂点はスーパー頂点 (ステージとも呼ばれます) としてグループ化され、ジョブ グラフとして視覚化されます。 ジョブ グラフの緑色のステージプラカードはステージを示します。
ステージ内のすべての頂点は、同じデータの異なる部分で同じ種類の作業を行います。 たとえば、1 TB のデータを含むファイルがあり、そこから何百もの頂点が読み取られている場合、各頂点はチャンクを読み取っています。 これらの頂点は同じステージにグループ化され、同じ入力ファイルのさまざまな部分で同じ作業を行います。
-
特定の段階では、いくつかの数字がプラカードに表示されます。
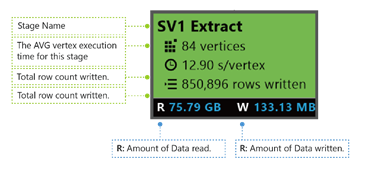
SV1 抽出: ステージの名前。番号と操作メソッドによって名前が付けられます。
84 個の頂点: このステージの頂点の合計数。 この図は、このステージで分割される作業の数を示しています。
12.90 秒/頂点: このステージの平均頂点実行時間。 この値は、頂点の実行時間の合計 / 頂点の総数で計算されます。 つまり、並列処理で実行されるすべての頂点を割り当てることができる場合、ステージ全体は 12.90 秒で完了します。 また、この段階のすべての作業が順次行われる場合、コストは #vertices * AVG 時間になります。
850,895 行の書き込み: このステージで書き込まれた合計行数。
R/W: このステージで読み取り/書き込まれたデータの量 (バイト単位)。
色: ステージでは、異なる頂点の状態を示すために色が使用されます。
- 緑は、頂点が成功したことを示します。
- オレンジは、頂点が再試行されたことを示します。 再試行された頂点は失敗しましたが、システムによって自動的かつ正常に再試行され、ステージ全体が正常に完了します。 頂点が再試行しても失敗した場合は、色が赤になり、ジョブ全体が失敗します。
- 赤は失敗したことを示します。これは、特定の頂点がシステムによって数回再試行されたが、それでも失敗したことを意味します。 このシナリオでは、ジョブ全体が失敗します。
- 青は、特定の頂点が実行されていることを意味します。
- 白は頂点が待機中であることを示します。 ADLAU が使用可能になると、頂点がスケジュールされるのを待っているか、入力データの準備ができていない可能性があるため、入力を待機している可能性があります。
ステージの詳細を確認するには、マウスカーソルを特定の場所に合わせます。
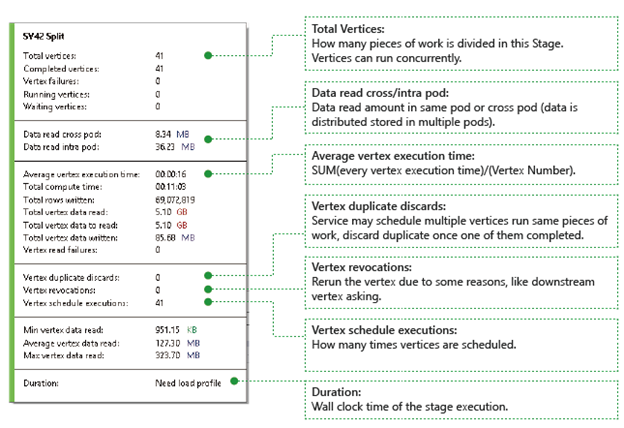
頂点: 頂点の詳細 (たとえば、頂点の総数、完了した頂点の数、失敗した頂点、実行中/待機中など) を記述します。
異なるポッド間および同一ポッド内でのデータ読み取り: ファイルとデータは、分散ファイルシステム内の複数のポッドに格納されています。 ここでの値は、同じポッドまたはクロス ポッドで読み取られたデータの量を示しています。
合計コンピューティング時間: ステージ内のすべての頂点実行時間の合計を、ステージ内のすべての作業が 1 つの頂点でのみ実行される場合にかかる時間と見なすことができます。
データと行の書き込み/読み取り: 読み取り/書き込み済み、または読み取りが必要なデータまたは行の量を示します。
頂点読み取りエラー: データの読み取り中に失敗した頂点の数について説明します。
頂点の重複破棄: 頂点の実行速度が遅すぎると、同じ処理を実行するように複数の頂点がスケジュールされる可能性があります。 いずれかの頂点が正常に完了すると、冗長な頂点は破棄されます。 頂点の重複破棄は、ステージ内で重複として破棄された頂点の数を記録します。
頂点の無効化: 頂点は処理されましたが、何らかの理由で後で再実行されることがあります。 たとえば、下流の頂点が中間入力データを失うと、アップストリームの頂点に再実行を求められます。
頂点スケジュールの実行: 頂点がスケジュールされた合計時間。
最小/平均/最大頂点データ読み取り: すべての頂点読み取りデータの最小/平均/最大値。
期間: ステージに要するウォール クロック時間。この値を表示するにはプロファイルを読み込む必要があります。
ジョブ再実行
Data Lake Analytics はジョブを実行し、頂点の開始、停止、失敗、再試行の方法など、ジョブの情報を実行している頂点をアーカイブします。すべての情報は、クエリ ストアに自動的に記録され、ジョブ プロファイルに格納されます。 ジョブ ビューの [プロファイルの読み込み] を使用してジョブ プロファイルをダウンロードし、ジョブ プロファイルのダウンロード後にジョブの再生を表示できます。
ジョブの再生は、クラスターで何が起こったかを理想的に表現した可視化です。 ジョブの実行の進行状況を監視し、パフォーマンスの異常とボトルネックを非常に短時間で視覚的に検出するのに役立ちます (通常は 30 秒未満)。
ジョブヒートマップ表示
ジョブ ヒート マップは、ジョブ グラフの [表示] ドロップダウンから選択できます。
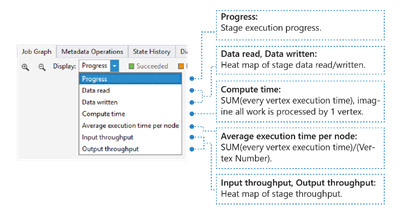
ジョブの I/O、時間、スループットのヒート マップが表示され、ジョブがほとんどの時間を費やしている場所や、ジョブが I/O 境界ジョブであるかどうかを確認できます。
- 進行状況: ジョブ実行の進行状況。ステージ情報の情報を参照してください。
- データの読み取り/書き込み: 各ステージで読み取り/書き込まれた合計データのヒート マップ。
- 計算時間: SUM のヒート マップ (頂点の実行時間ごと) は、ステージ内のすべての作業が 1 つの頂点のみで実行される場合にかかる時間と考えることができます。
- ノードあたりの平均実行時間: SUM のヒート マップ (各頂点実行時間) / (頂点番号)。 つまり、並列処理で実行されるすべての頂点を割り当てることができる場合、ステージ全体がこの時間枠で実行されます。
- 入出力スループット: 各ステージの入出力スループットのヒート マップで、ジョブが I/O バインド ジョブであるかどうかを確認できます。
-
メタデータ演算
データベースの作成、テーブルの削除など、U-SQL スクリプトで一部のメタデータ操作を実行できます。これらの操作は、コンパイル後のメタデータ操作に表示されます。 ここでは、アサーションを見つけたり、エンティティを作成したり、削除したりできます。

州の歴史
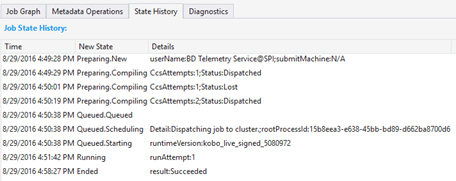
状態履歴はジョブの概要でも視覚化されますが、詳細についてはここで確認できます。 ジョブの準備、キューへの登録、実行の開始、終了などの詳細情報を確認できます。 また、ジョブがコンパイルされた回数 (CcsAttempts: 1)、ジョブが実際にクラスターにディスパッチされたタイミング (詳細: クラスターへのジョブのディスパッチ) も確認できます。
診断
このツールは、ジョブの実行を自動的に診断します。 ジョブでエラーやパフォーマンスの問題が発生すると、アラートが表示されます。 ここで完全な情報を取得するには、プロファイルをダウンロードする必要があることに注意してください。
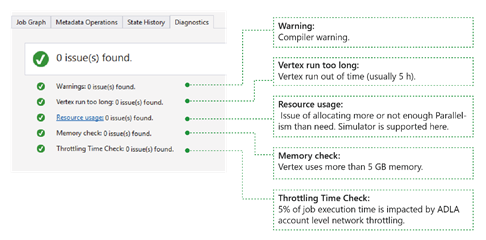
- 警告: 警告がここに表示され、コンパイラの警告が表示されます。 アラートが表示されたら、"x issue(s)" リンクを選択して詳細を確認できます。
- 頂点の実行時間が長すぎます。頂点が時間切れ (たとえば 5 時間) になると、問題がここに表示されます。
- リソース使用量: 必要以上に並列処理を割り当てた場合、または十分でない場合は、ここで問題が見つかります。 また、[リソース使用量] を選択して詳細を表示し、What-If シナリオを実行して、より適切なリソース割り当てを見つけることができます (詳細については、このガイドを参照してください)。
- メモリ チェック: 頂点で 5 GB を超えるメモリが使用されている場合は、ここで問題が見つかります。 システムの制限よりも多くのメモリを使用すると、ジョブの実行がシステムによって強制終了される可能性があります。
Job Detail (ジョブの詳細)
ジョブの詳細には、スクリプト、リソース、頂点実行ビューなど、ジョブの詳細情報が表示されます。
スクリプト
ジョブの U-SQL スクリプトはクエリ ストアに格納されます。 元の U-SQL スクリプトを表示し、必要に応じて再送信できます。
リソース
クエリ ストアに格納されているジョブ コンパイル出力は、[リソース] を使用して検索できます。 たとえば、ジョブ グラフ、登録したアセンブリなどをここに表示するために使用される "algebra.xml" を見つけることができます。
頂点実行ビュー
頂点の実行の詳細が表示されます。 ジョブ プロファイルは、読み取り/書き込みデータの合計、ランタイム、状態など、すべての頂点実行ログをアーカイブします。このビューを使用すると、ジョブの実行方法の詳細を確認できます。 詳細については、「 Data Lake Tools for Visual Studio での頂点実行ビューの使用」を参照してください。
次のステップ
- 診断情報をログに記録するには、Azure Data Lake Analytics の診断ログへのアクセスに関するページを参照してください。
- より複雑なクエリを表示する場合は、「 チュートリアル: Azure Data Lake Analytics を使用して Web サイトのログを分析する」をご覧ください。
- 頂点実行ビューを使用するには、「Data Lake Tools for Visual Studio で頂点実行ビューを使用する」を参照してください。