Azure Data Lake Tools for Visual Studioを使用して Azure Data Lake Analyticsのデータ スキューの問題を解決する
重要
Azure Data Lake Analytics 2024 年 2 月 29 日に廃止されました。 詳細については、このお知らせを参照してください。
データ分析の場合、organizationでは Azure Synapse Analytics または Microsoft Fabric を使用できます。
データ スキュー問題とは何ですか。
簡単に言うと、データ スキューとは過度に表現された値のことです。 税申告を監査するために 50 人の税務審査官を割り当て、米国の州ごとに 1 人の審査官を割り当てたとします。 ワイオミング州の審査官は、母集団が小さいため、ほとんど行う必要はありません。 しかしカリフォルニア州では人口が多いため、調査官は常に忙しい状態です。

このケースでは、データが調査官に均等に分散されていないので、調査官の作業量にばらつきが生じます。 ジョブの実行でも、こうした状況が頻繁に起きているでしょう。 技術的に言うと、1 つの頂点に与えられるデータが他の頂点よりはるかに多いので、その頂点は他よりも長く実行することになり、結果的にジョブ全体の進行が遅くなります。 そのうえ、いくつかの頂点に実行限度 5 時間やメモリ制限 6 GBといった制限があれば、ジョブが失敗する可能性があります。
データ スキュー問題を解決する
Azure Data Lake Tools for Visual Studioと Visual Studio Code は、ジョブにデータ スキューの問題があるかどうかを検出するのに役立ちます。
- Azure Data Lake Tools for Visual Studio をインストールする
- Azure Data Lake Tools for Visual Studio コードをインストールする
問題がある場合は、ここに示した解決策を試みることで解決できます。
解決策 1: テーブルのパーティションを改善する
オプション 1: 傾斜したキーの値を事前にフィルター処理する
ビジネス ロジックに影響しない場合は、より高い頻度の値を事前にフィルター処理できます。 たとえば、列 GUID に 000-000-000 が多い場合は、その値を集計したくない場合があります。 集計前に「WHERE GUID != “000-000-000”」と入力して、頻度の高い値をフィルター処理することができます。
オプション 2:別のパーティションまたはディストリビューション キーを選択する
前述の例では、国や地域全体の税務監査状況だけを確認するのであれば、ID 番号をキーとして選択してデータ分散を改善することができます。 異なるパーティションやディストリビューション キーを選択することでデータをより均等に分散できる場合もありますが、それがビジネス ロジックに影響を与えないように注意する必要があります。 たとえば、各州の納税額の合計を計算するには、州 をパーティション キーとして指定します。 問題が改善されない場合は、オプション 3 を試してみます。
オプション 3:パーティション キーまたはディストリビューション キーを追加する
州 のみをパーティション キーとして使用する代わりに、パーティションに 2 つ以上のキーを使用することができます。 たとえば、データ パーティションのサイズを小さくし、データをより均等に分散するために、別のパーティション キーとして ZIP コード を追加することを検討してください。
オプション 4:ラウンドロビン分散を使用する
パーティションとディストリビューションに適切なキーが見つからない場合は、ラウンドロビン分散の使用を試みることができます。 ラウンドロビン分散はすべての行を均等に処理し、対応するバケットにランダムに配置します。 データは均等に分散されますが、地域情報を失い、一部の操作においてジョブのパフォーマンスが削減されるという欠点もあります。 さらに、歪んだキーの集計を行う場合は、データ スキューの問題が解決しません。 ラウンドロビン分散の詳細については、「 CREATE TABLE (U-SQL): スキーマを使用したテーブルの作成」の「U-SQL テーブルディストリビューション」セクションを参照してください。
解決策 2: クエリ プランを改善する
オプション 1: CREATE STATISTICS ステートメントを使用する
U-SQL では、CREATE STATISTICS ステートメントをテーブルで提供します。 このステートメントは、テーブルに格納されているデータ特性 (値の分布など) に関する詳細情報をクエリ オプティマイザーに提供します。 ほとんどのクエリでは、クエリ オプティマイザーは高品質のクエリ プランに必要な統計情報を既に生成しています。 場合によっては、CREATE STATISTICS を使用して統計を作成したり、クエリデザインを変更したりして、クエリのパフォーマンスを向上させる必要がある場合があります。 詳細については、「CREATE STATISTICS (U-SQL)」ページを参照してください。
コード例:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Note
統計情報は自動的には更新されません。 テーブル内のデータを更新しても、統計を再作成しなければ、クエリ パフォーマンスが低下することがあります。
オプション 2:SKEWFACTOR を使用する
上記の例で各州の税を合計する場合、州ごとにグループ化する以外の選択肢はありません。これはデータ スキュー問題の影響を受けます。 ただし、クエリにデータ ヒントを指定してキーのデータ スキューを識別することにより、オプティマイザー実行プランを準備できます。
通常、パラメーターを 0.5 と 1 に設定できます。0.5 は大きな傾斜ではなく、1 つは大きな傾斜を意味します。 ヒントは、現在のステートメント、およびすべてのダウンストリーム ステートメントの実行プランの最適化に影響を与えるため、傾斜キーの集計があり得る場合は、必ず事前にヒントを追加しておいてください。
SKEWFACTOR (columns) = x
指定された列に 0 (スキューなし) から 1 (大きな傾斜) までのスキュー係数 x があることを示すヒントを提供します。
コード例:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
オプション 3:ROWCOUNT を使用する
SKEWFACTOR に加えて、特定の傾斜キー結合については、結合された一方の行セットが小さいことがわかっている場合、JOIN の前に U-SQL ステートメントに ROWCOUNT のヒントを追加してオプティマイザーに認識させることができます。 これによりオプティマイザーは、ブロードキャストの結合方法を選択してパフォーマンスを改善することができます。 ROWCOUNT ではデータ スキューの問題は解決されませんが、追加のヘルプが提供される可能性があることに注意してください。
OPTION(ROWCOUNT = n)
推定の整数行数を指定して、JOIN の前の小さな行セットを識別します。
コード例:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
解決策 3: ユーザー定義レジューサーおよびコンバイナーを改善する
複雑な処理ロジックに対応するユーザー定義演算子を構築することもあるでしょう。適切に構築されたレジューサーおよびコンバイナーは、一部のケースにおいてデータ スキュー問題を軽減する場合があります。
オプション 1: 可能な限り再帰的なレジューサーを使用する
既定では、ユーザー定義レジューサーは非回復モードで実行されます。つまり、キーの削減作業は 1 つの頂点に分散されます。 しかし、データがスキューされている場合、膨大なデータ セットが 1 つの頂点で処理され、長いあいだ実行されることがあります。
パフォーマンスを向上させるためには、属性をコードに追加して、再帰的なモードで実行するレジューサを定義することができます。 そして、膨大なデータ セットを複数の頂点に分散して並行処理し、ジョブを高速化することができます。
非回復性レジューサーを再帰的に変更するには、アルゴリズムが関連付けられていることを確認する必要があります。 たとえば、合計は連想であり、中央値は関連付けられません。 また、レジューサーの入力および出力が同じスキーマを保持することを確認する必要があります。
再帰的なレジューサーの属性:
[SqlUserDefinedReducer(IsRecursive = true)]
コード例:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
オプション 2:可能な限り行レベルのコンバイナー モードを使用する
特定の傾斜キーを結合する場合の ROWCOUNT ヒントと同様に、コンバイナー モードでは、膨大な量の傾斜キー値のセットを複数の頂点に分散するよう試み、作業を同時に実行できるようにします。 コンバイナー モードではデータ スキューの問題を解決できませんが、大きなスキュー キー値セットに関する追加のヘルプを提供できます。
既定では、コンバイナー モードは Full です。つまり、左側の行セットと右の行セットを区切ることはできません。 モードを左/右/内部として設定すると、行レベルの結合が有効になります。 システムは対応する行セットを分離し、それらを並列で実行している複数の頂点に分散します。 ただし、コンバイナー モードを構成する前に、対応する行セットを分割できるかどうかを必ず確認してください。
次の例では、分割さた左の行セットを示します。 出力行はいずれも、左側の単一の入力行に依存し、また、キー値の同じ右側の行すべてにも依存する可能性があります。 コンバイナー モードを左として設定した場合、システムは巨大な左側の行セットをより小さな行セットに分割し、それらを複数の頂点に割り当てます。
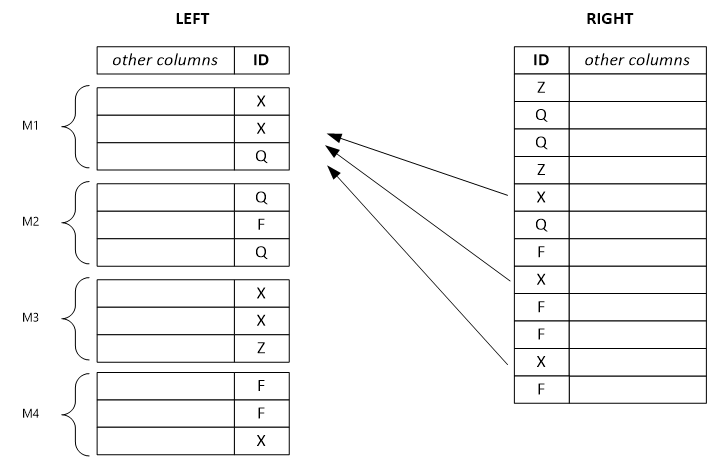
Note
間違ったコンバイナー モードを設定すると、組み合わせは効率が低下し、正しくない結果となる可能性があります。
コンバイナー モードの属性:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): 出力行がいずれも、キー値が同じ左右の入力行すべてに依存する可能性があります。
SqlUserDefinedCombiner(Mode=CombinerMode.Left): 出力行がいずれも、左側の単一の入力行に依存します (また、キー値が同じ右側の行すべてにも依存する可能性があります)。
qlUserDefinedCombiner(Mode=CombinerMode.Right): 出力行がいずれも、右側の単一の入力行に依存します (また、キー値が同じ左側の行すべてにも依存する可能性があります)。
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): 出力行がいずれも、値が同じである左側および右側の単一の入力行に依存します。
コード例:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}