自動集計を構成する
自動集計の構成には、サポートされている DirectQuery セマンティック モデルのトレーニングの有効化と、1 つまたは複数のスケジュールされた更新の構成が含まれます。 トレーニングと更新操作を数回繰り返した後、セマンティック モデルの設定に戻り、メモリ内集計キャッシュを使用するレポート クエリの割合を微調整できます。 これらの手順を完了する前に、必ず「自動集計」で説明されている機能と制限事項を十分理解してください。
有効にする
自動集計を有効にするには、セマンティック モデル所有者権限が必要です。 ワークスペース管理者は、セマンティック モデル所有者権限を引き継ぐことができます。
セマンティック モデルの設定で、[スケジュールされた更新とパフォーマンスの最適化] を展開します。
[自動集計のトレーニング] を [オン] に切り替えます。 切り替えが灰色表示されている場合は、セマンティック モデルのデータ ソース資格情報を確実に構成し、サインインしていることを確認してください。

[スケジュールを更新] で、更新頻度とタイム ゾーンを指定します。 [スケジュールを更新] コントロールが無効になっている場合は、ゲートウェイ接続 (必要な場合) とデータ ソース資格情報を含むデータ ソース構成を確認します。
[別の時刻を追加] を選択してから、1 つまたは複数の更新を指定します。
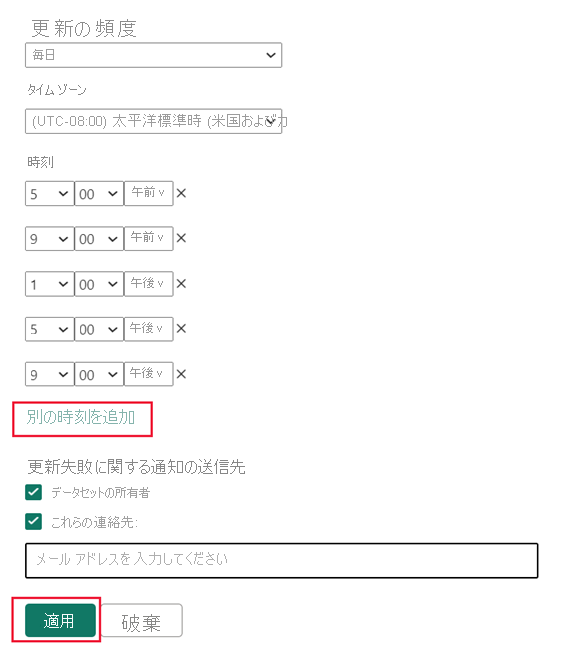
少なくとも 1 つの更新をスケジュールする必要があります。 選択する頻度の最初の更新には、''トレーニング'' 操作と、新しい集計と更新された集計をメモリ内キャッシュに読み込む更新の両方が含まれます。 集計キャッシュにヒットするレポート クエリで、バックエンド データ ソースと最も同期している結果が取得されるように、より多くの更新をスケジュールします。 詳しくは、「更新操作」を参照してください。
[適用] を選択します。
オンデマンドのトレーニングと更新
選択した頻度での最初の ''スケジュールされた'' 更新操作には、トレーニング操作が含まれます。 そのトレーニング操作が 60 分の制限時間以内に完了しない場合、後続の更新操作でキャッシュ内の集計の読み込みや更新は行われません。 次のトレーニング操作は、選択した頻度の最初の更新操作まで実行されません。
このような場合は、1 つまたは複数の ''オンデマンド'' トレーニングおよび更新操作を手動で実行してトレーニングを完全に完了し、キャッシュ内の集計を読み込むか更新することができます。 たとえば、更新履歴を確認するときに、1 日 (頻度) の最初の ''スケジュールされた'' トレーニングと更新操作が制限時間内に完了せず、トレーニング操作を含む次の日のスケジュールされた更新が実行されるのを待ちたくない場合は、1 つまたは複数のオンデマンド トレーニングおよび更新操作を実行して、データ クエリ ログを完全に処理し (トレーニング)、集計をキャッシュに読み込む (更新) ことができます。
オンデマンドのトレーニングおよび更新操作を実行するには、[今すぐトレーニングして更新] を選択します。 確実にオンデマンドのトレーニング操作が正常に完了するように、更新履歴を常に確認してください。 そうでない場合は、トレーニングが正常に完了し、キャッシュの集計が読み込まれるか更新されるまで、別のトレーニング操作と更新操作を実行します。
[今すぐトレーニングして更新する] を実行すると、メモリ内キャッシュからの集計を使用するレポート クエリの割合を微調整する場合にも役立つことがあります。 オンデマンドの今すぐトレーニングして更新する操作を実行することで、新しい割合設定でトレーニング操作が制限時間内に完了できるかどうかをより迅速に判断できます。
トレーニングおよび更新の操作には、スケジュールされたものであるかオンデマンドのものであるかに関係なく、Power BI サービスとデータ ソース システムの両方で多くのプロセスとリソースが使用されることに注意してください。 リソースへの影響が最も少ない時間を選んでください。
微調整
ユーザー定義とシステム生成の集計テーブルはいずれもモデルの一部であり、モデルのサイズに関係し、既存の Power BI モデル サイズ制約の対象となります。 集計処理ではリソースも消費され、モデルの更新期間に影響します。 最適な構成では、トレーニングおよび更新時間の短縮とシステム リソースの負担の軽減と引き換えに外れ値やアドホック クエリでより遅い結果を受け入れながら、最も頻繁に使用されるレポート クエリではメモリ内集計キャッシュからの事前に集計された結果を提供することのバランスを取ります。
割合を調整する
既定では、メモリ内キャッシュからの集計を使用するレポート クエリの割合を決定する集計キャッシュ設定は 75% です。 割合を増やすと、より多くのレポート クエリが上位にランク付けされるため、それらの集計がメモリ内集計キャッシュに含まれます。 割合が高いほどメモリ内キャッシュから応答されるクエリが多くなることを意味する場合がありますが、トレーニングと更新の時間が長くなることを意味する場合もあります。 一方、低い割合に調整すると、トレーニングと更新の時間が短縮され、リソース使用率が低下することを意味する場合がありますが、レポートの視覚化のパフォーマンスが低下する可能性があります。これは、レポート クエリを代わりにデータ ソースにラウンドトリップする必要があるので、メモリ内集計キャッシュで応答されるレポート クエリが少なくなるためです。
システムでキャッシュに含める最適な集計を決定できるようにするには、まず最も頻繁に使用されるレポート クエリ パターンを認識する必要があります。 集計キャッシュを使用するクエリの割合を調整する前に、必ずトレーニングと更新操作を数回完了するようにしてください。 これにより、トレーニング アルゴリズムで、より広範な期間にレポート クエリを分析し、適宜、自己調整する時間が得られます。 たとえば、毎日の頻度で更新をスケジュールした場合は、丸 1 週間待つことをお勧めします。 ユーザーのレポート パターンが、ある曜日では他の曜日と異なる場合があります。
割合を調整するには
セマンティック モデルの設定で、[スケジュールされた更新とパフォーマンスの最適化] を展開します。
[クエリ カバレッジ] で、[集計キャッシュを使用するクエリの割合を調整する] スライダーを使用して、目的の値に対する割合を増減します。 割合を調整すると、[クエリ パフォーマンスへの影響] リフト チャートにクエリの推定応答時間が示されます。

[今すぐトレーニングして更新する] または [適用] を選択します。
クエリ パフォーマンスへの影響を推定する
[クエリ パフォーマンスへの影響] リフト チャートには、キャッシュされた集計を使用するクエリの割合の関数として、レポート クエリの推定実行時間が示されます。 少なくとも 1 つのトレーニングと更新操作が実行されるまで、グラフにはすべてのメトリックに対して最初に 0.0 が表示されます。 このグラフは、最初のトレーニングと更新操作の後、メモリ内集計キャッシュを使用するクエリの割合を調整すると、クエリ応答がさらに向上する可能性があるかどうかを判断するのに役立つ場合があります。
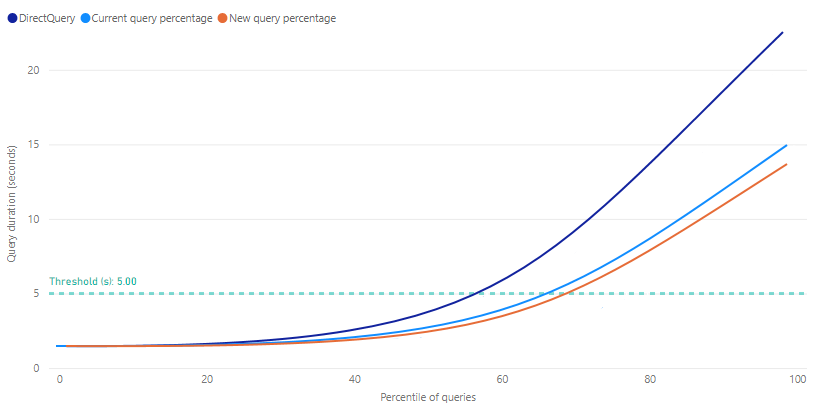
しきい値はリフト チャートのマーカー線として表示され、レポートのターゲット クエリ応答時間を示します。 その後、集計キャッシュを使用するクエリの割合を微調整して、目的のしきい値を満たす新しいクエリの割合を決定できます。
メトリック
DirectQuery - DirectQuery を使用してデータ ソースとの間で送信および返されるレポート クエリの推定期間 (秒)。 メモリ内集計キャッシュで応答できないクエリは通常、この推定値内になります。
現在のクエリの割合 - 最新のトレーニングと更新操作の割合設定に基づいて、メモリ内集計キャッシュから応答されたレポート クエリの推定期間 (秒)。
新しいクエリの割合 - 新しく選択された割合のメモリ内集計キャッシュから応答されたレポート クエリの推定期間 (秒)。 割合スライダーが変更されると、このメトリックに潜在的な変更が反映されます。
無効にする
自動集計を無効にするには、モデル所有者権限が必要です。 ワークスペース管理者は、セマンティック モデル所有者権限を引き継ぐことができます。
無効にするには、[自動集計のトレーニング] を [オフ] に切り替えます。
トレーニングを無効にすると、自動集計テーブルを削除するオプションの選択を求められます。
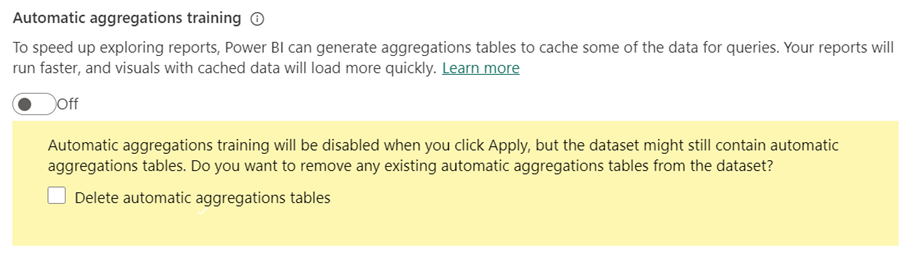
既存の自動集計テーブルを削除 ''しない'' ことを選択した場合、テーブルはモデル内に残り、引き続き更新されます。 しかし、トレーニングが無効になっているため、新しい集計は追加されません。 Power BI では、可能な限り、集計クエリ結果を取得するために既存のテーブルが引き続き使用されます。
テーブルを削除することを選択した場合、モデルは元の状態に戻ります。自動集計は行われません。
適用を選択します。