自動集計
自動集計では、レポート クエリのパフォーマンスが最大になるように、最新の機械学習 (ML) を使用して、DirectQuery のセマンティック モデルが継続的に最適化されます。 自動集計は、Power BI 用の複合モデルで最初に導入された既存のユーザー定義集計インフラストラクチャを基にして構築されています。 ユーザー定義集計とは異なり、自動集計の構成と保守には、広範なデータ モデリングとクエリ最適化のスキルは必要ありません。 自動集計は、自己トレーニングと自己最適化の両方を備えています。 これを使うと、モデル所有者のスキル レベルに関係なく、クエリのパフォーマンスを高め、大規模なモデルのレポートをより高速に視覚化することができます。
自動集計では:
- レポートの視覚化の高速化 - 最適な割合のレポート クエリが、バックエンドのデータ ソース システムではなく、自動的に管理されるメモリ内集計キャッシュによって返されます。 メモリ内キャッシュから返されない外れ値クエリは、DirectQuery を使ってデータ ソースに直接渡されます。
- バランスの取れたアーキテクチャ - 純粋な DirectQuery モードと比較すると、ほとんどのクエリ結果は、Power BI クエリ エンジンとメモリ内集計キャッシュによって返されます。 レポート作成のピーク時にデータ ソース システムにかかるクエリ処理の負荷を、大幅に削減できます。つまり、データ ソース バックエンドのスケーラビリティが向上します。
- 簡単なセットアップ - モデルの所有者は、自動集計トレーニングを有効にし、モデルの 1 つ以上の更新をスケジュールできます。 最初のトレーニングと更新で、自動集計により集計フレームワークと最適な集計の作成が開始されます。 システムは、時間と共に自動的にチューニングされます。
- 細かいチューニング - モデルの設定のシンプルで直感的なユーザー インターフェイスを使用して、メモリ内集計キャッシュから返されるクエリの割合を変えてパフォーマンスの向上を見積もり、さらに向上するよう調整を行うことができます。 1 つのスライド バー コントロールを使って、環境に合った微調整を簡単に行うことができます。
必要条件
サポートされているプラン
自動集計は、Power BI Premium Per Capacity、Premium Per User、Power BI Embedded の各モデルでサポートされています。
サポートされるデータ ソース
自動集計は、次のデータ ソースでサポートされています。
- Azure SQL Database
- Azure Synapse 専用 SQL プール
- SQL Server 2019 以降
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
サポートされているモード
自動集計は、DirectQuery モード モデルでサポートされています。 インポート テーブルと DirectQuery 接続の両方を使う複合モデル モデルがサポートされています。 自動集計は、DirectQuery 接続でのみサポートされています。
アクセス許可
自動集計を有効にして構成するには、モデル所有者である必要があります。 ワークスペース管理者は、所有者として引き継ぎ、自動集計の設定を構成できます。
自動集計を構成する
自動集計は、モデルの設定で構成します。 構成は簡単です - 自動集計のトレーニングを有効にし、1 つまたは複数の更新をスケジュールします。 モデルの自動集計を構成する前に、この記事をよく読んでください。 自動集計のしくみがよくわかり、自動集計が環境に合っているかどうかを判断する際に役に立ちます。 自動集計のトレーニングを有効にし、更新スケジュールを構成して、環境に合わせて微調整する手順を実行できる状態になったら、「自動集計を構成する」を参照してください。
メリット
DirectQuery を使うと、モデルのユーザーがレポートを開いたり、レポートの視覚エフェクトを操作したりするたびに、Data Analysis Expressions (DAX) クエリがクエリ エンジンに渡され、次に SQL クエリとしてバックエンド データ ソースに渡されます。 そのデータ ソースで各クエリの結果が計算されて返されます。 メモリ内に格納されるインポート モードのモデルと比較すると、DirectQuery データ ソースのラウンドトリップでは、時間と処理がどちらも増え、多くの場合、レポートの視覚化で使用されているクエリの応答時間が遅くなる可能性があります。
DirectQuery モデルに対して自動集計を有効にすると、データ ソース クエリのラウンドトリップがなくなることで、レポート クエリのパフォーマンスが向上します。 事前に集計されたクエリ結果が、データ ソースによって送信および返信されるのではなく、メモリ内の集計キャッシュによって自動的に返されます。 メモリ内集計キャッシュ内に事前に集計されるデータの量は、データ ソースのファクト テーブルと詳細テーブルに保持されているデータの量のごく一部です。 その結果、レポート クエリのパフォーマンスが向上するだけでなく、バックエンド データ ソース システムに対する負荷も軽減されます。 自動集計を使用すると、純粋な DirectQuery モードと同様に、メモリ内キャッシュに含まれていない集計を必要とするレポート クエリとアドホック クエリの一部だけが、バックエンド データ ソースに渡されます。
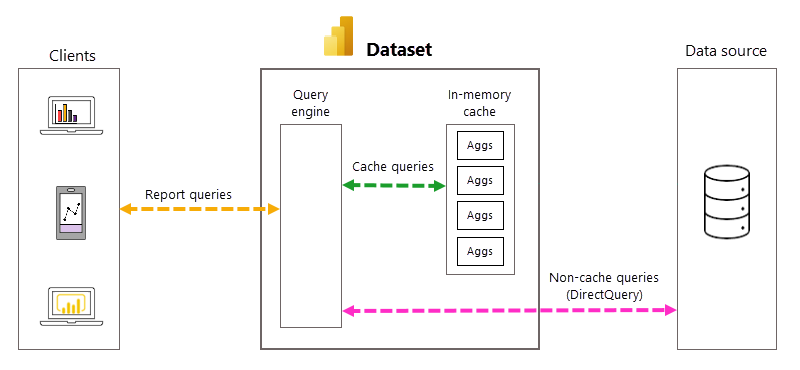
自動的なクエリと集計の管理
自動集計を使うと、ユーザー定義集計テーブルを作成する必要がなくなり、事前集計データ ソリューションの実装が大幅に簡素化されますが、基になるプロセスと依存関係についての深い知識は、自動集計のしくみを理解するのに役立ちます。 Power BI による自動集計の作成と管理には、次のものが利用されます。
クエリ ログ
Power BI では、クエリ ログを使用してモデル クエリとユーザー レポート クエリが追跡されます。 Power BI によって、モデルごとに、7 日分のクエリ ログ データが保持されます。 クエリ ログ データは毎日ロールフォワードされます。 クエリ ログはセキュリティで保護されており、ユーザーが見たり、XMLA エンドポイントを通してアクセスしたりすることはできません。
トレーニング操作
ユーザーが選んだ頻度 (日または週) での最初のスケジュールされたモデル更新操作の一部として、Power BI によって最初に開始されるトレーニング操作により、クエリ ログが評価されて、メモリ内集計キャッシュ内の集計が変化するクエリ パターンに適合されます。 メモリ内集計テーブルが作成、更新、または削除され、特殊なクエリがデータ ソースに送信されて、キャッシュに含める集計が決定されます。 ただし、トレーニングの間は、計算された集計データがメモリ内キャッシュに読み込まれることはありません。集計データが読み込まれるのは、後続の更新操作の間です。
たとえば、頻度として日を選び、更新を午前 4:00、午前 9:00、午後 2:00、午後 7:00 にスケジュールした場合、毎日午前 4:00 の更新だけに、トレーニング操作 "および" 更新操作の両方が含まれます。 その日の午前 9 時、午後 2 時、午後 7 時にスケジュールされている後続の更新は、キャッシュ内の既存の集計を更新する "更新のみの操作" です。
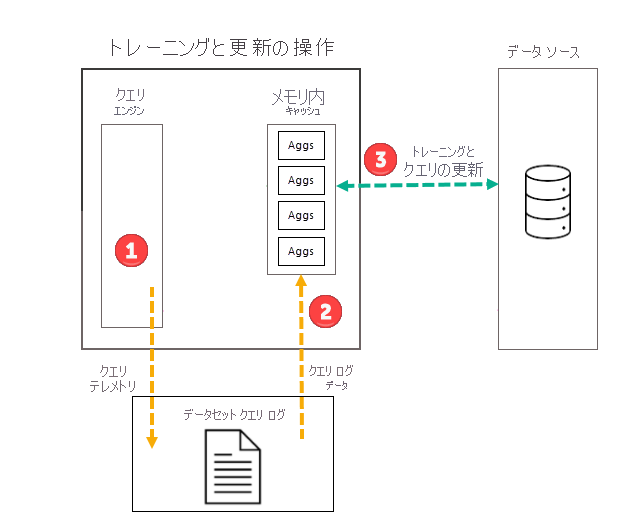
トレーニング操作によって評価されるのはクエリ ログの過去のクエリですが、結果は十分に正確で、将来のクエリが確実にカバーされます。 ただし、新しいクエリはクエリ ログから得られたものと異なる可能性があるため、将来のクエリがメモリ内集計キャッシュによって返される保証はありません。 メモリ内集計キャッシュによって返されないクエリは、DirectQuery を使用してデータ ソースに渡されます。 それらの新しいクエリの頻度とランク付けによっては、それらに対する集計が、次のトレーニング操作でメモリ内集計キャッシュに含められる可能性があります。
トレーニング操作には 60 分の時間制限があります。 トレーニングで、制限時間内にクエリ ログ全体を処理できない場合は、モデルの更新履歴に通知がログされ、次回起動時にトレーニングが再開されます。 クエリ ログ全体が処理されると、トレーニング サイクルが完了し、既存の自動集計が置き換えられます。
更新操作
先ほど説明したように、選択された頻度の最初のスケジュールされた更新の一環としてトレーニング操作が完了した後は、Power BI によって実行される更新操作により、新しい集計データと更新された集計データのクエリが行われてメモリ内集計キャッシュに読み込まれ、(トレーニング アルゴリズムによって決定される) 十分高いランクではなくなった集計が削除されます。 選択された日または週の頻度での後続の更新はすべて、データ ソースのクエリが実行されてキャッシュ内の既存の集計データが更新される "更新のみの操作" です。 上の例を使うと、その日の午前 9:00、午後 2:00、午後 7:00 にスケジュールされた更新は、更新のみの操作です。
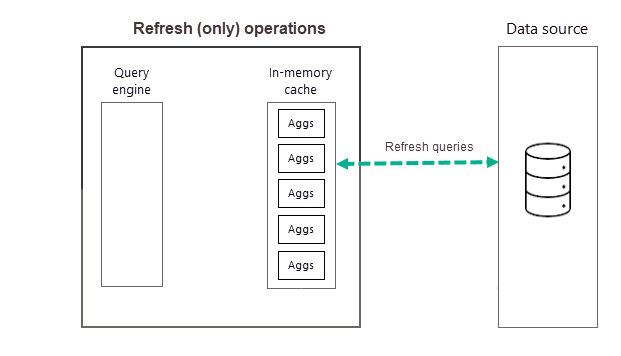
1 日 (または 1 週間) を通して定期的にスケジュールされた更新により、キャッシュ内の集計データは、バックエンド データ ソースのデータで最新の状態に維持されます。 モデル設定を使用すると、1 日あたり最大 48 回の更新をスケジュールし、集計キャッシュによって返されるレポート クエリの結果が、バックエンド データ ソースの最新の更新されたデータに基づいて取得されるようにできます。
注意事項
トレーニングと更新の操作には、Power BI サービスとデータ ソース システムの両方で、多くのプロセスとリソースが使用されます。 集計を使用するクエリの割合を増やすと、トレーニングと更新の操作中にデータ ソースでクエリされて計算される必要がある集計が増え、システム リソースが過剰に使用される可能性が高くなり、タイムアウトが発生するおそれがあります。 詳細については、「微調整」を参照してください。
オンデマンドのトレーニング
前述のように、1 つのデータ更新サイクルの時間制限内でトレーニング サイクルが完了しない場合があります。 トレーニングを含む次のスケジュールされた更新サイクルまで待ちたくない場合は、モデル設定の [トレーニングと今すぐ更新] を選んで、オンデマンドで自動集計トレーニングをトリガーすることもできます。 [今すぐトレーニングして更新する] を使うと、トレーニング操作と更新操作の両方がトリガーされます。 必要に応じて、他のオンデマンドのトレーニングと更新操作をオンデマンドで実行する前に、モデルの更新履歴を見て現在の操作が完了しているか確認します。
更新履歴
各更新操作は、モデルの更新履歴に記録されます。 構成されたクエリの割合で消費されるキャッシュ内のメモリ集計の数など、各更新に関する重要な情報が示されます。 更新履歴を表示するには、モデルの設定ページで [更新履歴] を選びます。 もう少しドリルダウンする場合は、詳細の [表示] を選びます。

更新履歴を定期的に調べることで、スケジュールされた更新操作が許容期間内に完了していることを確認できます。 次のスケジュールされた更新が始まる前に、更新操作が正常に完了していることを確認します。
トレーニングと更新の失敗
Power BI によるトレーニングと更新の操作は、ユーザーが選んだ日または週の頻度に対して最初のスケジュールされた更新の一部として実行されますが、これらの操作は別のトランザクションとして実装されます。 トレーニング操作で、制限時間内にクエリ ログを完全に処理できない場合、Power BI では、前のトレーニング状態を使って既存の集計 (および複合モデルの通常のテーブル) の更新を続行します。 この場合、更新履歴には更新が成功したことが示され、次にトレーニングが開始されたときに、トレーニングによってクエリ ログの処理が再開されます。 クライアント レポートのクエリ パターンが変更され、集計がまだ調整されていない場合、クエリのパフォーマンスは最善ではないかもしれませんが、それでも、達成されるパフォーマンス レベルは、集計が行われない純粋な DirectQuery モデルよりはるかに優れているはずです。
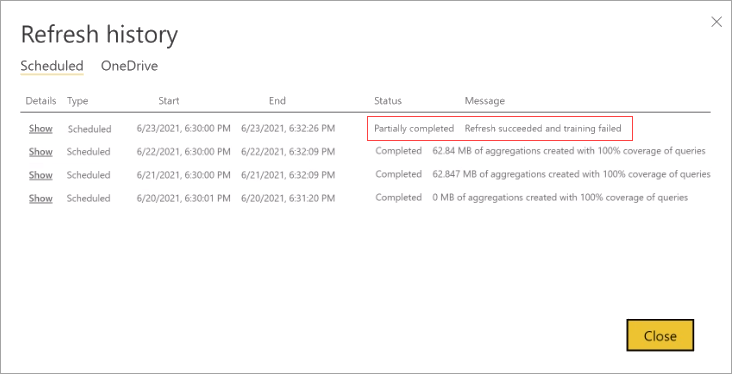
トレーニング操作でクエリ ログの処理を完了するために必要なサイクルが多すぎる場合は、モデルの [設定] でメモリ内集計キャッシュを使用するクエリの割合を減らすことを検討してください。 このようにすると、キャッシュに作成される集計の数は減りますが、トレーニングと更新の操作を完了するための時間的余裕は増えます。 詳細については、「微調整」を参照してください。
トレーニングが成功しても更新が失敗した場合は、結果としてメモリ内集計キャッシュを使用できなくなるので、更新全体が失敗としてマークされます。
更新をスケジュールするときに、更新が失敗した場合のメール通知を指定できます。
ユーザー定義集計と自動集計
Power BI のユーザー定義集計は、モデル内の非表示の集計テーブルに基づいて手動で構成できます。 ユーザー定義集計の構成は複雑なことが多く、データ モデリングとクエリ最適化に関して一段と高いレベルのスキルが要求されます。 一方、自動集計では、このような複雑さは、AI 駆動型システムの一部として解消されます。 変化することのないユーザー定義集計とは異なり、Power BI によって継続的にクエリ ログが保持され、それらのログから、機械学習 (ML) の予測モデリング アルゴリズムに基づいてクエリ パターンが決定されます。 クエリ パターン分析に基づいて事前集計データが計算されて、メモリ内に格納されます。 自動集計の場合、モデルは自己トレーニングと自己最適化の両方を備えています。 クライアントのレポート クエリ パターンが変化すると、自動集計によって調整され、優先順位を付けられて、最も頻繁に使用される集計がキャッシュされます。
自動集計は、既存のユーザー定義集計インフラストラクチャの上に構築されているので、同じモデルでユーザー定義集計と自動集計の両方を一緒に使用することができます。 熟練したデータ モデラーは、DirectQuery、インポート (増分更新の有無にかかわらず)、またはデュアル ストレージ モードを使用して、テーブルの集計を定義できますが、同時に、ユーザー定義の集計テーブルにヒットしない DirectQuery 接続によるクエリについてはいっそう自動的に集計される利点もあります。 この柔軟性により、クエリの負荷を減らしてボトルネックを避けることができるバランスの取れたアーキテクチャを実現できます。
自動集計トレーニング アルゴリズムによってメモリ内キャッシュに作成される集計は、System 集計として識別されます。 レポート クエリが分析され、モデルに最適な集計を維持するために調整が行われるとき、トレーニング アルゴリズムによって作成および削除されるのは、そのような System 集計のみです。 ユーザー定義集計と自動集計はどちらも、更新に合わせて更新されます。 自動集計処理に含まれるのは、自動集計によって作成されて、システム生成集計としてマークされた集計のみです。
クエリ キャッシュと自動集計
Power BI Premium では、クエリの結果を維持するために Power BI Premium および Embedded でのクエリ キャッシュもサポートされています。 クエリ キャッシュは、自動集計とは別の機能です。 クエリ キャッシュの場合は、Power BI Premium によってローカル キャッシュ サービスを使用してキャッシュが実装されますが、自動集計はモデル レベルで実装されます。 クエリ キャッシュでサービスによってキャッシュされるのは、レポート ページの最初の読み込みのためのクエリだけなので、ユーザーがレポートを操作するときのクエリのパフォーマンスは向上しません。 これに対し、自動集計では、ユーザーがレポートを操作するときに生成されるクエリなど、集計クエリの結果が事前にキャッシュされるので、ほとんどのレポート クエリが最適化されます。 1 つのモデルに対してクエリ キャッシュと自動集計の両方を有効にできますが、そうする必要はおそらくありません。
Log Analytics を使用して監視する
Azure Log Analytics (LA) は、Azure Monitor 内のサービスであり、アクティビティ ログを保存するために Power BI で使用できます。 Azure Monitor スイートを使用すると、Azure やオンプレミスの環境からテレメトリ データを収集し、分析して、アクションを実行することができます。 それによって提供される長期的なストレージ、アドホック クエリ インターフェイス、API アクセスを使用して、データをエクスポートし、他のシステムと統合することができます。 詳細については、「Power BI で Azure Log Analytics を使用する」を参照してください。
Azure LA アカウントを使用して Power BI が構成されている場合は、「Power BI 用に Azure Log Analytics を構成する」で説明されているように、自動集計の成功率を分析できます。 特に、レポート クエリへの応答がメモリ内キャッシュから取得されたかどうかを判断できます。
この機能を使うには、この Power BI ブログ記事で説明されているように、PBIT テンプレートをダウンロードして、それを Log Analytics アカウントに接続します。 レポートでは、概要ビュー、DAX クエリ レベル ビュー、SQL クエリ レベル ビューの 3 つの異なるレベルで、データを表示できます。
次の図は、すべてのクエリの概要ページを示したものです。 見るとわかるように、マークされたグラフでは、集計によって満たされたクエリの総数と、データ ソースを利用する必要があったクエリの数の割合が示されています。
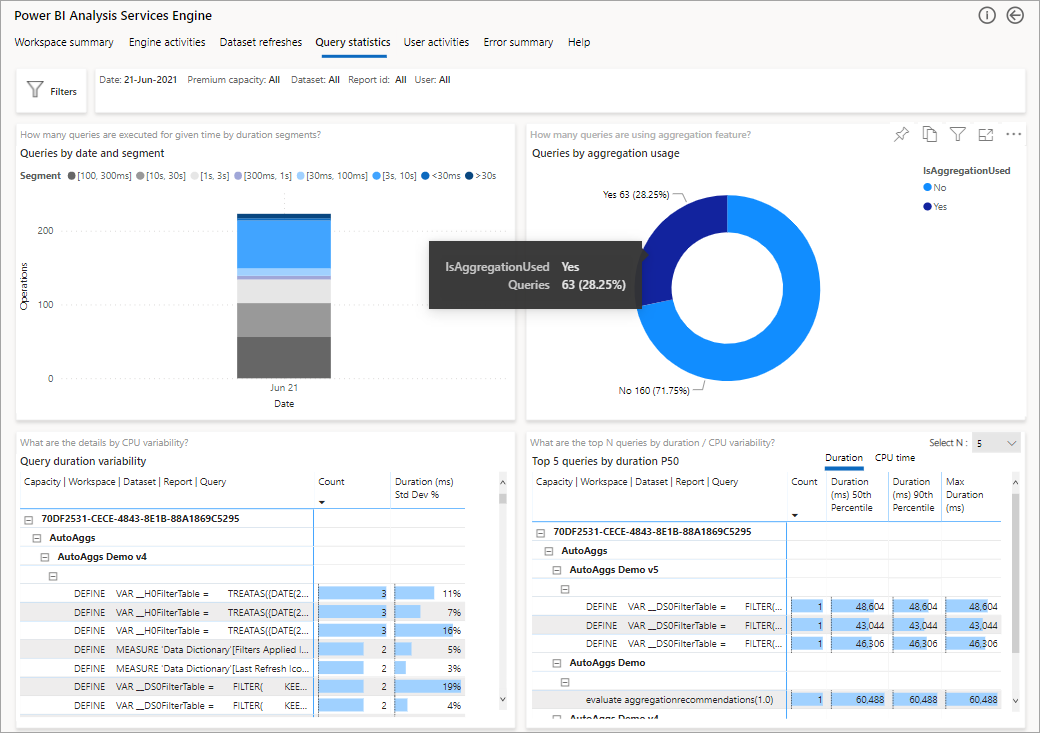
詳細な分析の次のステップでは、DAX クエリ レベルでの集計の使用を調べます。 一覧 (左下) の DAX クエリを右クリックして >[ドリルスルー]>[クエリ履歴] を選択します。
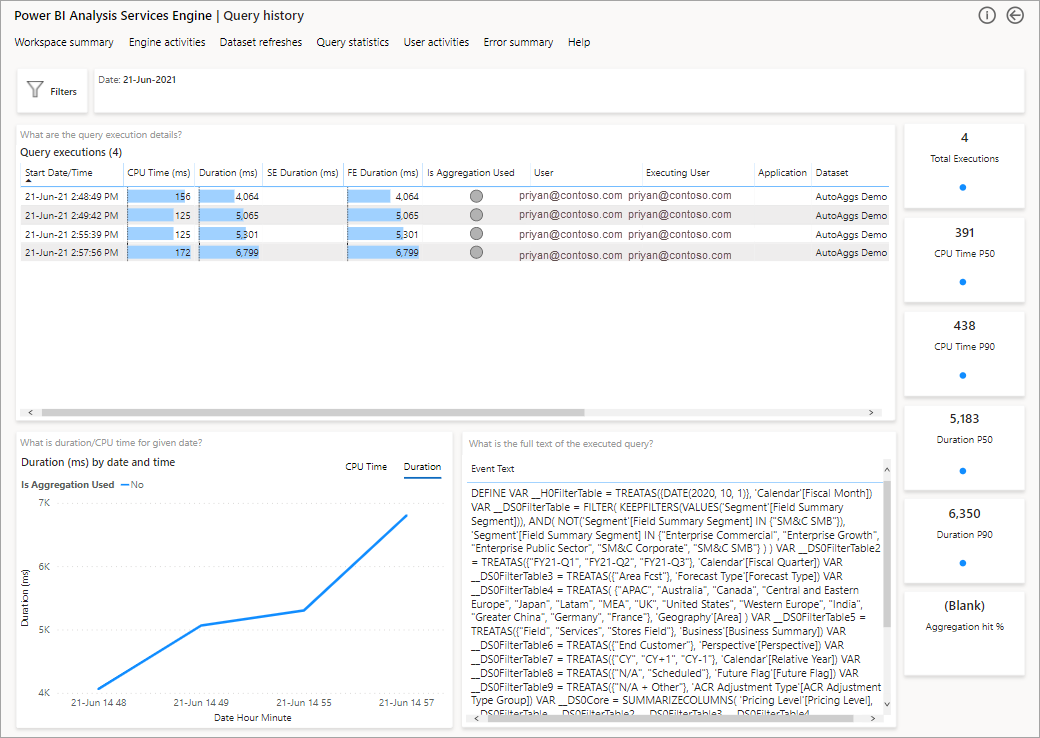
これにより、すべての関連するクエリの一覧が表示されます。 次のレベルにドリルスルーすると、集計の詳細が表示されます。
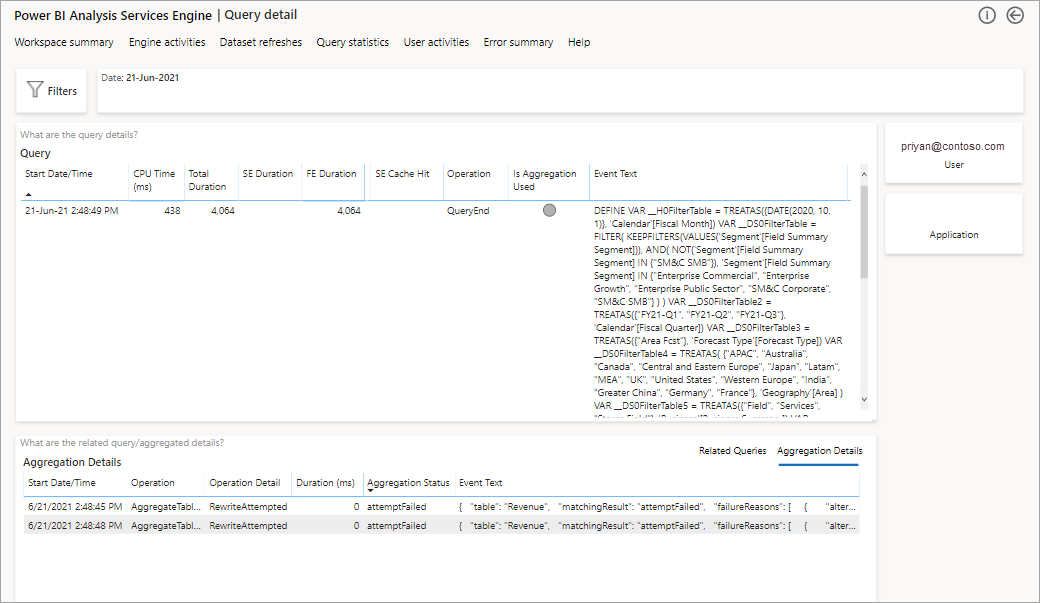
アプリケーション ライフサイクル管理
開発からテストまで、そしてテストから運用まで、自動集計が有効になっているモデルには、ALM ソリューションに関して特別な要件があります。
デプロイ パイプライン
デプロイ パイプラインを使う場合、Power BI で、モデルとそのモデル構成を、現在のステージからターゲット ステージにコピーできます。 ただし、自動集計の設定は現在のステージからターゲット ステージに転送されないため、ターゲット ステージで設定し直す必要があります。 デプロイ パイプライン REST API を使用して、プログラムでコンテンツをデプロイすることもできます。 このプロセスの詳細については、API と DevOps を使用したデプロイ パイプラインの自動化に関する記事を参照してください。
カスタム ALM ソリューション
XMLA エンドポイントに基づくカスタム ALM ソリューションを使用する場合は、ソリューションで、システム生成とユーザー作成の集計テーブルを、モデルのメタデータの一部としてコピーできる可能性があることに留意してください。 ただし、ターゲット ステージの各デプロイ ステップの後で、自動集計を手動で有効にする必要があります。 既存のモデルを上書きする場合、Power BI によって構成が保持されます。
Note
Power BI Desktop (.pbix) ファイルの一部としてモデルをアップロードまたは再発行すると、Power BI により既存のモデルがターゲット ワークスペース内のすべてのメタデータとデータで置き換えられるため、システムによって作成された集計テーブルは失われます。
モデルの変更
XMLA エンドポイントによって有効にされた自動集計でモデルが変更されると (テーブルの追加や削除など)、Power BI により、必要性や関連性がある可能性のある既存の集計は保持され、そうでないものは削除されます。 次のトレーニング フェーズがトリガーされるまで、クエリのパフォーマンスが影響を受ける可能性があります。
メタデータの要素
自動集計が有効になっているモデルには、システムで生成された固有の集計テーブルが含まれます。 ユーザーがレポート ツールで集計テーブルを見ることはできません。 Analysis Services クライアント ライブラリ バージョン 19.22.5 以降のツールと XMLA エンドポイントを使って確認できます。 自動集計が有効になっているモデルを使用する場合は、データ モデリングと管理のツールを、最新バージョンのクライアント ライブラリにアップグレードしてください。 SQL Server Management Studio (SSMS) の場合は、SSMS バージョン 18.9.2 以降にアップグレードします。 以前のバージョンの SSMS では、テーブルを列挙したり、これらのモデルをスクリプト化したりすることはできません。
自動集計テーブルは、SystemManaged テーブル プロパティによって識別されます。これは、Analysis Services クライアント ライブラリ バージョン 19.22.5 以降で表形式オブジェクト モデル (TOM) に新しく追加されたものです。 次のコード スニペットを使うと、自動集計テーブルに対しては SystemManaged プロパティが true に設定され、通常のテーブルに対しては false に設定されます。
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
このスニペットを実行すると、モデルに現在含まれている自動集計テーブルがコンソールに出力されます。
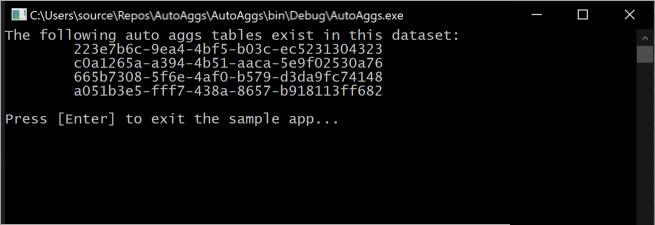
ただし、トレーニング操作によってメモリ内集計キャッシュに含めるのに最適な集計が決定されるため、集計テーブルは常に変化していることに注意してください。
重要
自動集計のシステム生成テーブル オブジェクトは、Power BI によって完全に管理されます。 これらのテーブルを自分で削除したり変更したりしないでください。 それを行うと、パフォーマンスが低下する可能性があります。
モデルの構成は、Power BI によってモデルの外部で保持されます。 モデルにシステム管理の集計テーブルがあったとしても、モデルで実際に自動集計トレーニングが有効になっているとは限りません。 つまり、自動集計が有効になっているモデルの完全なモデル定義をスクリプト化し、モデルの新しいコピーを (異なる名前、ワークスペース、容量で) 作成した場合、結果として得られる新しいモデルでは自動集計トレーニングが有効になっていません。 モデルの [設定] で新しいモデルに対して自動集計トレーニングを有効にする必要があります。
考慮事項と制限事項
自動集計を使用する場合、次の点に注意してください。
- 集計で、動的 M クエリ パラメーターはサポートされていません。
- 初期トレーニング フェーズの間に生成される SQL クエリによって、データ ウェアハウスに大きな負荷がかかる可能性があります。 トレーニングが不完全な状態で終了し続け、データ ウェアハウス側でクエリにタイムアウトが発生していることを確認できる場合は、トレーニングの負荷に合わせてデータ ウェアハウスを一時的にスケールアップすることを検討してください。
- メモリ内集計キャッシュに格納されている集計は、データ ソースの最新のデータで計算されていない場合があります。 純粋な DirectQuery とは異なり、通常のインポート テーブルと同様に、データ ソースでの更新と、メモリ内集計キャッシュに格納される集計データの間には、待ち時間があります。 常にある程度の待ち時間がありますが、有効な更新スケジュールによって軽減できます。
- パフォーマンスをさらに最適化するには、すべてのディメンション テーブルをデュアル モードに設定し、ファクト テーブルは DirectQuery モードのままにします。
- Power BI Pro、Azure Analysis Services、または SQL Server Analysis Services では、自動集計を使用できません。
- Power BI では、自動集計が有効になっているモデルのダウンロードはサポートされません。 Power BI Desktop (.pbix) ファイルを Power BI にアップロードまたは発行した後、自動集計を有効にした場合、その PBIX ファイルはダウンロードできなくなります。 PBIX ファイルのコピーをローカル環境に保持するようにしてください。
- Azure Synapse Analytics の外部テーブルでの自動集計はサポートされていません。 次の SQL クエリを使うと、Synapse の外部テーブルを列挙できます:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables。 - 自動集計は、拡張メタデータを使用するモデルでのみ使用できます。 古いモデルで自動集計を有効にする場合は、まず、モデルを拡張メタデータにアップグレードします。 詳細については、「拡張モデル メタデータの使用」を参照してください。
- DirectQuery データ ソースがシングル サインオン用に構成されており、ユーザーがアクセスできるデータを制限するために動的データ ビューまたはセキュリティ コントロールが使用されている場合は、自動集計を有効にしないでください。 これらのデータ ソース レベルの制御は自動集計によって認識されないため、ユーザーごとに正しいデータを確実に提供することはできません。 トレーニングでは、シングル サインオン用に構成されたデータ ソースが検出され、このデータ ソースを使用するテーブルがスキップされたという警告を、更新履歴内にログします。 可能であれば、これらのデータ ソースで SSO を無効にして、自動集計が提供するクエリ パフォーマンスの最適化を最大限にします。
- モデルにハイブリッド テーブルのみが含まれている場合は、不要な処理オーバーヘッドを回避するために、自動集計を有効にしないでください。 ハイブリッド テーブルでは、インポート パーティションと DirectQuery パーティションの両方が使用されます。 一般的なシナリオは、リアルタイム データを使用した増分更新です。この場合、前回のデータ更新後に発生したデータ ソースから、DirectQuery パーティションによってトランザクションがフェッチされます。 ただし、更新中には、Power BI によって集計がインポートされます。 自動集計には、最後のデータ更新後に発生したトランザクションを含めることができません。 トレーニングでは、ハイブリッド テーブルが検出され、スキップされたという警告を更新履歴にログします。
- 計算列は自動集計では考慮されません。 2 つの DirectQuery テーブルの複数の列に基づいてリレーションシップを作成するために、
COMBINEVALUESDAX 関数を使用するなど、DirectQuery モードで計算列を使った場合、対応するレポート クエリでメモリ内集計キャッシュはヒットしません。 - 自動集計は、Power BI サービスでのみ使用できます。 Power BI Desktop では、システム生成の集計テーブルは作成されません。
- 自動集計が有効になっているモデルのメタデータを変更した場合、次のトレーニング プロセスがトリガーされるまで、クエリのパフォーマンスが低下する可能性があります。 ベスト プラクティスとして、自動集計を削除し、変更を行ってから、再度トレーニングする必要があります。
- 自動集計を無効にして、モデルをクリーンアップしている場合を除き、システム生成の集計テーブルを変更または削除しないでください。 これらのオブジェクトは、システムによって管理されます。
コミュニティ
Power BI には、MVP、BI プロフェッショナル、および同僚がディスカッション グループ、ビデオ、ブログなどの専門知識を共有する、活気のあるコミュニティがあります。 自動集計について学習する場合は、以下の他のリソースを確認してください。