医療データ ソリューションで非構造化臨床メモのエンリッチメント (プレビュー) を使用する
[この記事はプレリリース ドキュメントであり、変更されることがあります。]
注意
このコンテンツは現在更新中です。
非構造化臨床メモのエンリッチメント (プレビュー) では、Azure AI Language の Text Analytics for health サービスを使用して、非構造化臨床メモから主要な高速ヘルスケア相互運用性リソース (FHIR) エンティティを抽出します。 これらの臨床ノートから構造化データを作成します。 次に、この構造化データを分析して、患者の健康状態を改善するための分析情報、予測、品質基準を得ることができます。
この機能の詳細と、その展開と構成の方法については、以下を参照してください:
非構造化臨床メモのエンリッチメント (プレビュー) は、医療データ ファンデーション機能に直接依存しています。 まず、医療データ ファンデーション パイプラインが正常に設定および実行されていることを確認します。
前提条件
- Microsoft Fabric に医療データ ソリューションを展開する
- 医療データ ファンデーションの展開 で、基盤となるノートブックとパイプラインをインストールする。
- Azure Language サービスを設定する の説明に従って、Azure Language サービスを設定します。
- 非構造化臨床メモのエンリッチメント (プレビュー) を展開および構成する
- OMOP 変換を展開および構成します。 この手順は必須ではありません。
NLP インジェスト サービス
healthcare#_msft_ta4h_silver_ingestion ノートブックは、医療データ ソリューション ライブラリの NLPIngestionService モジュールを実行して、Text Analytics for health サービスを呼び出します。 このサービスは、FHIR リソース DocumentReference.Content から非構造化臨床メモを抽出して、フラット化された出力を作成します。 詳細については、ノートブック構成を確認する を参照してください。
シルバー レイヤーのデータ ストレージ
自然言語処理 (NLP) API 分析の後、構造化およびフラット化された出力は、healthcare#_msft_silver レイクハウス内の次のネイティブ テーブルに格納されます。
- nlpentity: 非構造化臨床ノートから抽出したフラット化されたエンティティが含まれます。 各行は、テキスト分析の実行後に非構造化テキストから抽出した 1 つの語句です。
- nlprelationship: 抽出したエンティティ間の関連付けを提供します。
- nlpfhir: FHIR 出力バンドルが JSON 文字列として含まれます。
最後に更新されたタイムスタンプを追跡するために、NLPIngestionService は 3 つのシルバー レイクハウス テーブルすべての parent_meta_lastUpdated フィールドを使用します。 この追跡により、親リソースであるソース ドキュメント DocumentReference が最初に格納され、参照整合性が維持されます。 このプロセスは、データの不整合や孤立したリソースを防ぐのに役立ちます。
重要
現在、Text Analytics for health は、UMLS メタシソーラス ボキャブラリ ドキュメント に記載されている語彙を返します。 これらのボキャブラリのガイダンスについては、UMLS からのデータのインポート を参照してください。
プレビュー リリースでは、Observational Health Data Sciences and Informatics (OHDSI) のガイダンスに基づいて、OMOP サンプル データセットに含まれる SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms)、LOINC (Logical Observation Identifiers, Names, and Codes)、および RxNorm の用語を使用します。
OMOP 変換
Microsoft Fabric の医療データ ソリューションは、Observational Medical Outcomes Partnership (OMOP) 変換のための別の機能も提供します。 この機能を実行すると、シルバー レイクハウスから OMOP ゴールド レイクハウスへの基になる変換によって、非構造化臨床メモ分析の構造化およびフラット化された出力も変換されます。 この変換では、シルバー レイクハウスの nlpentity テーブルから読み取り、出力を OMOP ゴールド レイクハウスの NOTE_NLP テーブルにマップします。
詳細については、OMOP 変換の概要 をご覧ください。
以下に、構造化 NLP 出力のスキーマと、対応する NOTE_NLP 列の OMOP 共通データ モデルへのマッピングを示します。
| フラット化されたドキュメント参照 | プロパティ | Note_NLP マッピング | サンプル データ |
|---|---|---|---|
| id | エンティティの一意識別子。 parent_id、offset、length の複合キー。 |
note_nlp_id |
1380 |
| parent_id | 用語の抽出元であるフラット化された documentreferencecontent テキストへの外部キー。 | note_id |
625 |
| テキスト | ドキュメントに表示されるエンティティ テキスト。 | lexical_variant |
既知のアレルギーなし |
| ページ | 入力 documentreferencecontent テキスト で抽出された用語の文字オフセット。 | offset |
294 |
| data_source_entity_id | 指定されたソース カタログ内のエンティティの ID。 | note_nlp_concept_idおよびnote_nlp_source_concept_id |
37396387 |
| nlp_last_executed | documentreferencecontent テキスト分析処理の日付。 | nlp_date_timeおよびnlp_date |
2023-05-17T00:00:00.0000000 |
| モデル | NLP システムの名前とバージョン (Text Analytics for health NLP システムの名前とバージョン)。 | nlp_system |
MSFT TA4H |

Text Analytics for health のサービス制限
- ドキュメントあたりの最大文字数は 125,000 文字に制限されています。
- 要求全体に含まれるドキュメントの最大サイズは 1 MB に制限されています。
- 要求あたりのドキュメントの最大数は、次のように制限されています:
- Web ベース API の場合 25。
- コンテナーの場合 1000。
ログを有効にする
Text Analytics for health API の要求と応答のログを有効にするには、次の手順に従います:
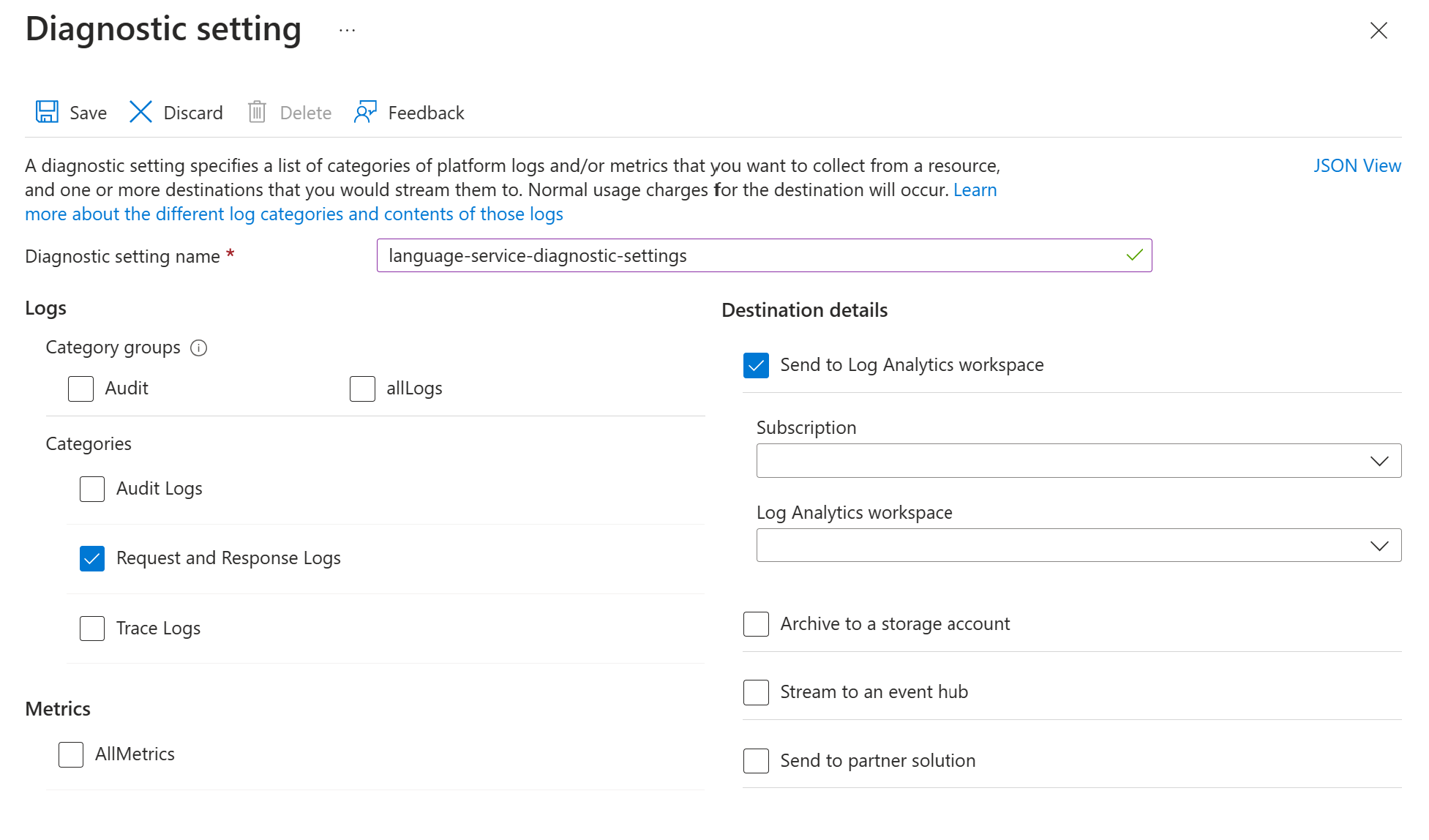
Azure AI サービスの診断ログを有効にする の手順に従って、 Azure Language サービス リソースの診断設定を有効にします。 このリソースは、Azure Language サービスの設定 の展開手順で作成したものと同じ言語サービスです。
- 診断設定名を入力します。
- カテゴリを 要求ログと応答ログ に設定します。
- 展開先の詳細については、Log Analytics ワークスペースに送信 を選択し、必要な Log Analytics ワークスペースを選択します。 ワークスペースがない場合は、プロンプトに従って作成します。
- 設定を保存します。
NLP インジェスト サービス ノートブックの NLP 構成 セクションに移動します。 構成パラメーター
enable_text_analytics_logsの値をTrueに更新します。 このノートブックの詳細については、ノートブック構成を確認する を参照してください。

Azure Log Analytics でログを表示する
ログ分析データを調べるには:
- Log Analytics ワークスペースに移動します。
- ログ を検索して選択します。 このページから、ログに対してクエリを実行できます。
サンプル クエリ
以下は、ログ データを調べるために使用できる基本的な Kusto クエリです。 このサンプル クエリでは、エラーの種類別にグループ化された、前日に Azure Cognitive Services リソース プロバイダーから失敗したすべての要求を取得します:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature