Tidyverse を使用する
Tidyverse は、データ サイエンティストが日常的なデータ分析でよく使用する R パッケージのコレクションです。 これには、データ インポート (readr)、データの視覚化 (ggplot2)、データ操作 (dplyr、tidyr)、関数型プログラミング (purrr)、モデル構築 (tidymodels) などのパッケージが含まれます。tidyverse 内のパッケージは、シームレスに連携し、設計原則の一貫したセットに従うように設計されています。
Microsoft Fabric では、ランタイムのリリースごとに最新の安定したバージョンの tidyverse が配布されます。 使い慣れた R パッケージをインポートして使用を開始します。
前提条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
![[エクスペリエンス スイッチャー メニュー] で Data Science を選択するところを示すスクリーンショット。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
ノートブックを開くか作成します。 方法については、「Microsoft Fabric ノートブックの使用方法」をご覧ください。
言語オプションを [SparkR (R)] に設定することで、主要言語を変更します。
ノートブックをレイクハウスにアタッチします。 左側にある [追加] を選択して、既存のレイクハウスを追加するか、レイクハウスを作成します。
tidyverse の読み込み
# load tidyverse
library(tidyverse)
データのインポート
readr は、CSV、TSV、固定幅ファイルなどの長方形データ ファイルを読み取るためのツールを提供する R パッケージです。 readr は、関数 read_csv() および read_tsv() の提供や CSV ファイルと TSV ファイルの読み取りなど、四角形のデータ ファイルを読み取るための高速でわかりやすい方法を提供します。
最初に R data.frame を作成し、readr::write_csv() を使用して lakehouse に書き込み、readr::read_csv() を使用して読み戻してみましょう。
Note
readr を使用してレイクハウス ファイルにアクセスするには、ファイル API パスを使用する必要があります。 レイクハウス エクスプローラーで、アクセスするファイルまたはフォルダーを右クリックし、コンテキスト メニューからファイル API パス をコピーします。
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
次に、ファイル API パスを使用してレイクハウスにデータを書き込みます。
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
レイクハウスからデータを読み取ります。
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
データの整理
tidyr は、乱雑なデータを操作するためのツールを提供する R パッケージです。 tidyr のメイン関数は、データを整然とした形式に整形するのに役立ちます。 データの整理には特定の構造があり、各変数が列、各観測値が行になっているため、R やその他のツールのデータを簡単に操作できます。
たとえば、gather() の tidyr 関数を使用して、ワイド データを長いデータに変換できます。 次に例を示します。
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
関数型プログラミング
purrr は、関数とベクトルを操作するための完全で一貫性のあるツール セットを提供することで、R の関数型プログラミング ツールキットを強化する R パッケージです。 purrr を開始するのに最適な場所は、多くの for ループを、より簡潔で読みやすいコードに置き換えることができる map() 関数ファミリです。 map() を使用してリストの各要素に関数を適用する例を次に示します:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
データの操作
dplyr は、名前に基づいて変数を選択する、値に基づいてケースを選択する、複数の値を 1 つの要約に減らす、行の順序を変更するなど、最も一般的なデータ操作の問題を解決するのに役立つ一貫した動詞セットを提供する R パッケージです。次に例をいくつか示します。
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
データのビジュアル化
ggplot2 は、『Grammar of Graphics』に基づいて、宣言的にグラフィックスを作成するための R パッケージです。 データを提供し、変数を美学にマップする方法、使用するグラフィカルプリミティブを ggplot2 に指示し、詳細を処理します。 次に例をいくつか示します。
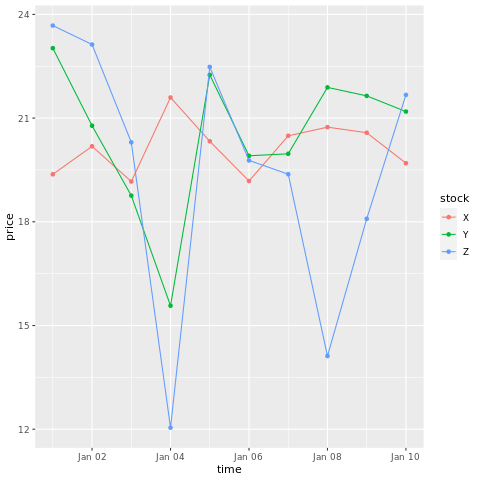
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
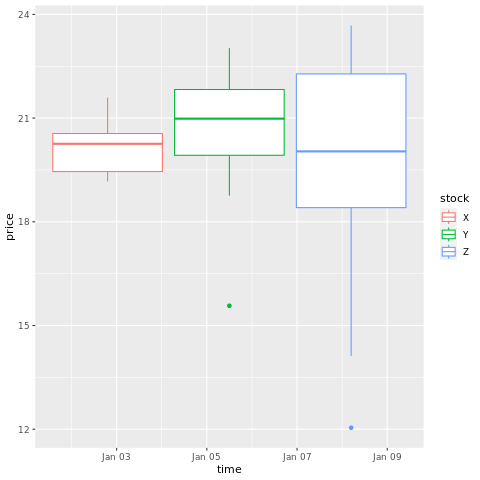
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
モデル構築
tidymodels フレームワークは、tidyverse 原則を使用したモデリングと機械学習のためのパッケージのコレクションです。 トレーニング/テスト データセットのサンプル分割については rsample、モデル仕様については parsnip、データの前処理については recipes、ワークフローのモデル化については workflows、ハイパーパラメーターのチューニングについては tune、モデル評価については yardstick、モデル出力の整理については broom、チューニング パラメーターについては dials など、広範なモデル構築タスクのコア パッケージの一覧を網羅しています。 パッケージの詳細については、tidymodels の Web サイトを参照してください。 重量 (wt) に基づいて車の 1 ガロンあたりのマイル数 (mpg) を予測する線形回帰モデルを構築する例を次に示します:
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
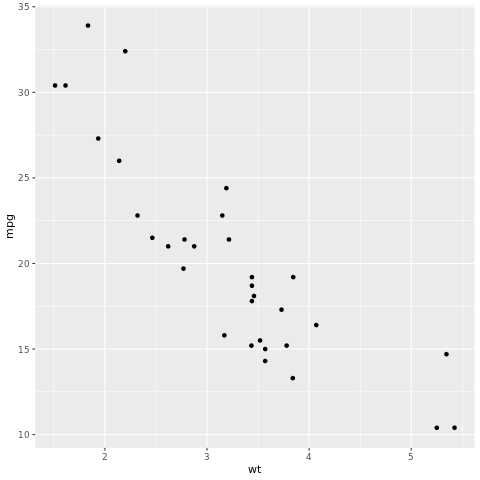
散布図から、リレーションシップはほぼ線形に見え、分散は一定に見えます。 線形回帰を使用してこれをモデル化してみましょう。
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
線形回帰モデルを適用して、テスト データセットで予測します。
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
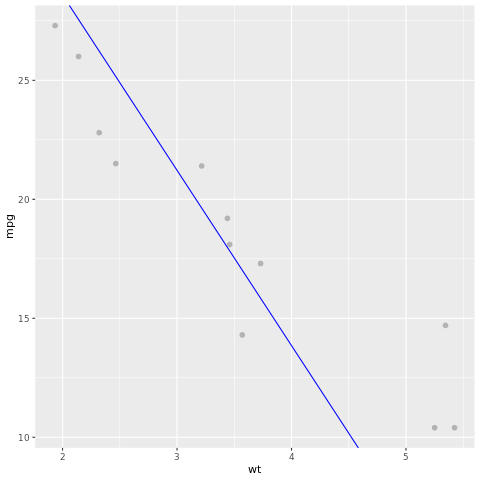
モデルの結果を見てみましょう。 モデルを折れ線グラフとして描画し、テスト グラウンド トゥルース データを同じグラフ上のポイントとして描画できます。 モデルは適切のようです。
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")