チュートリアル: R を使用してフライト遅延を予測する
このチュートリアルでは、Microsoft Fabric の Synapse Data Science ワークフローのエンド ツー エンドの例を示します。 nycflights13 データと R を使用して、飛行機が 30 分以上遅れて到着するかを予測します。 次に、予測結果を使用して対話型の Power BI ダッシュボードを作成します。
このチュートリアルでは、次の方法について説明します。
- tidymodels パッケージ (レシピ、parsnip、rsample、ワークフロー) を使用して、データを処理し、機械学習モデルをトレーニングします。
- 出力データをデルタ テーブルとしてレイクハウスに書き込む
- Power BI ビジュアル レポートを作成して、その lakehouse 内のデータに直接アクセスする
前提 条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
ノートブックを開くか作成する。 方法については、「Microsoft Fabric Notebooksを使用する方法」を参照してください。
言語オプションを SparkR (R) に設定して、プライマリ言語を変更します。
ノートブックをレイクハウスにアタッチします。 左側にある [追加] を選択して、既存のレイクハウスを追加するか、新しくレイクハウスを作成します。
パッケージをインストールする
このチュートリアルのコードを使用するには、nycflights13 パッケージをインストールします。
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
データを探索する
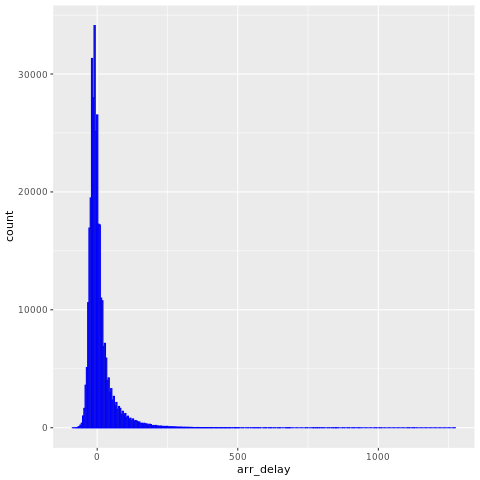
nycflights13 データには、2013 年にニューヨーク市近くに到着した 325,819 便に関する情報が含まれます。 まず、フライト遅延の分布を表示します。 このグラフは、到着遅延の分布が右に歪んでいることを示しています。 高い値には長い尾があります。
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
データを読み込み、変数にいくつかの変更を加えます。
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
モデルを構築する前に、前処理とモデリングの両方で重要な特定の変数をいくつか検討してください。
変数 arr_delay は因子変数です。 ロジスティック回帰モデルのトレーニングでは、結果変数が因子変数であることが重要です。
glimpse(flight_data)
このデータセット内のフライトの約 16% が 30 分以上遅れて到着しました。
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
dest 機能には、104 のフライト目的地があります。
unique(flight_data$dest)
16 個の異なるキャリアがあります。
unique(flight_data$carrier)
データを分割する
1 つのデータセットを 2 つのセット (トレーニング セットと テスト セット) に分割します。 トレーニング データセットの元のデータセットのほとんどの行を (ランダムに選択されたサブセットとして) 保持します。 トレーニング データセットを使用してモデルに合わせ、テスト データセットを使用してモデルのパフォーマンスを測定します。
rsample パッケージを使用して、データを分割する方法に関する情報を含むオブジェクトを作成します。 次に、さらに 2 つの rsample 関数を使用して、トレーニング セットとテスト セット用の DataFrame を作成します。
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
レシピとロールを作成する
単純なロジスティック回帰モデルのレシピを作成します。 モデルをトレーニングする前に、レシピを使用して新しい予測器を作成し、モデルに必要な前処理を実行します。
update_role() 関数を使用して、flight と time_hour が変数であり、カスタム ロールが IDと呼ばれることがレシピに認識されるようにします。 ロールには任意の文字値を指定できます。 この数式には、arr_delay以外のトレーニング セット内のすべての変数が予測変数として含まれます。 レシピはこれら 2 つの ID 変数を保持しますが、結果または予測変数として使用しません。
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
変数とロールの現在のセットを表示するには、summary() 関数を使用します。
summary(flights_rec)
機能を作成する
モデルを改善するために特徴エンジニアリングを行います。 フライトの日付が到着遅延の可能性に妥当な影響を与える可能性があります。
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
モデルにとって重要である可能性がある日付から派生したモデル用語を追加するのに役立つ場合があります。 1 つの日付変数から次の意味のある特徴を派生させます。
- 曜日
- 月
- 日付が休日に対応しているかどうか
レシピに次の 3 つの手順を追加します。
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
レシピを使用してモデルを適合させる
ロジスティック回帰を使用して、フライト データをモデル化します。 まず、parsnip パッケージを使用してモデル仕様を構築します。
lr_mod <-
logistic_reg() %>%
set_engine("glm")
workflows パッケージを使用して、parsnip モデル (lr_mod) をレシピ (flights_rec) とバンドルします。
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
モデルをトレーニングする
この関数はレシピを準備し、結果の予測器からモデルをトレーニングできます。
flights_fit <-
flights_wflow %>%
fit(data = train_data)
ヘルパー関数 xtract_fit_parsnip() と extract_recipe() を使用して、ワークフローからモデルまたはレシピ オブジェクトを抽出します。 この例では、適合したモデル オブジェクトをプルし、broom::tidy() 関数を使用して、モデル係数の整然とした表示を取得します。
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
結果を予測する
predict() への 1 回の呼び出しでは、トレーニング済みのワークフロー (flights_fit) を使用して、見えないテスト データで予測を行います。 predict() メソッドは、レシピを新しいデータに適用し、適合モデルに結果を渡します。
predict(flights_fit, test_data)
predict() から出力を取得して、予測されたクラス (late と on_time) を返します。 ただし、各フライトの予測クラス確率については、モデルと augment() を使用し、テスト データと組み合わせて、それらを一緒に保存します。
flights_aug <-
augment(flights_fit, test_data)
データを確認します。
glimpse(flights_aug)
モデルを評価する
これで予測されたクラスの確率が表示されます。 最初の数行では、モデルは 5 つのオンタイム フライトを正しく予測しました (.pred_on_time の値は p > 0.50)。 ただし、予測する行は合計 81,455 行あります。
結果変数 arr_delayの真の状態と比較して、モデルが到着遅延をどの程度予測したかを示すメトリックが必要です。
メトリックとして、曲線レシーバ動作特性 (AUC-ROC) の下の領域を使用します。 yardstick パッケージから、roc_curve() と roc_auc()を使用して計算します。
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Power BI レポートを作成する
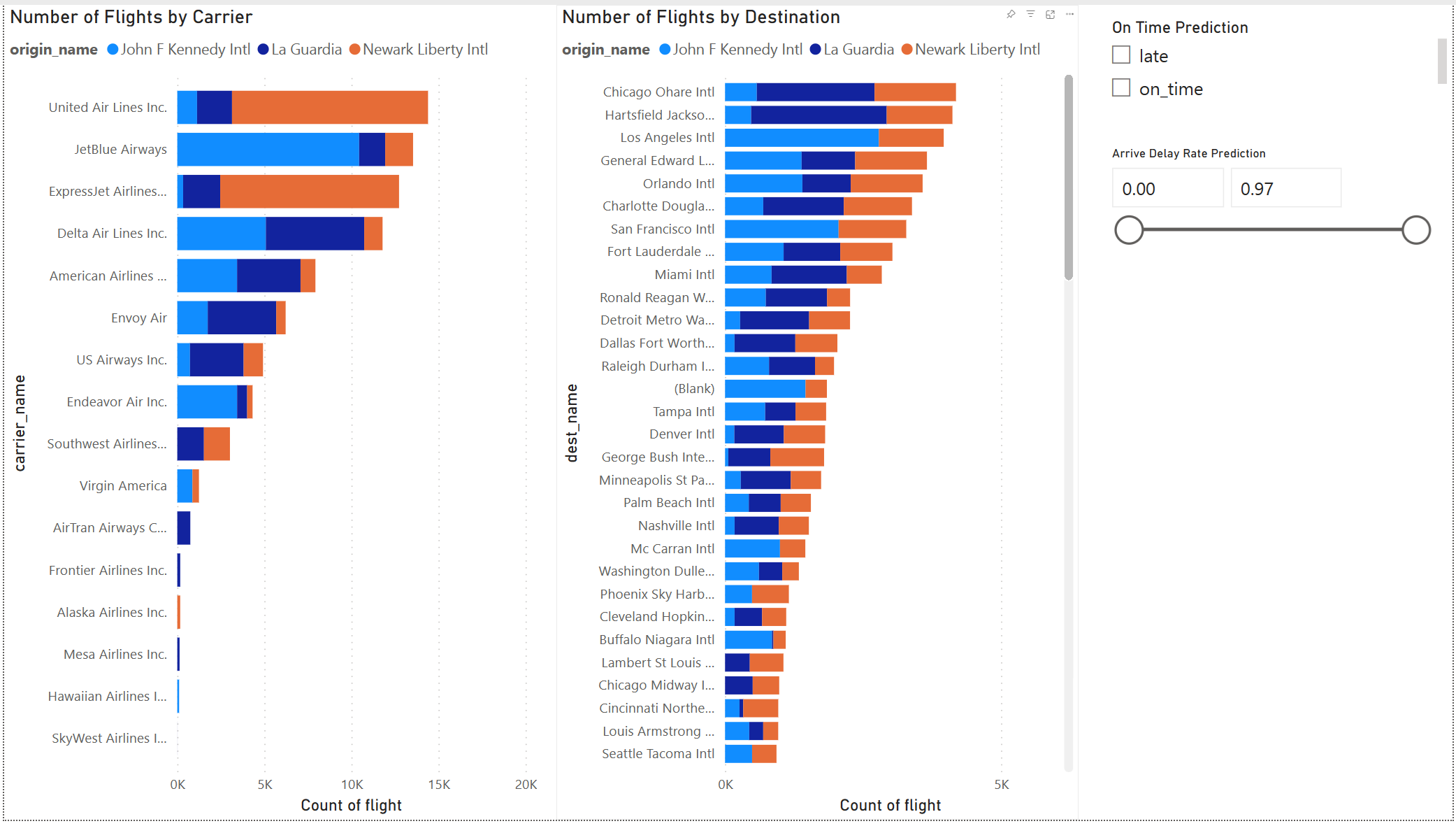
モデルの結果は適切のようです。 フライト遅延予測の結果を使用して、対話型の Power BI ダッシュボードを作成します。 ダッシュボードには、航空会社別のフライト数と目的地別のフライト数が表示されます。 ダッシュボードは、遅延予測結果でフィルター処理できます。
予測結果データセットにキャリア名と空港名を含めます。
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
データを確認します。
glimpse(flights_clean)
データを Spark DataFrame に変換します。
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
レイクハウスのデルタ テーブルにデータを書き込みます。
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
デルタ テーブルを使用してセマンティック モデルを作成します。
左側で OneLake を選択します。
ノートブックにアタッチしたレイクハウスを選択する
[開く] を選択します
新しいセマンティック モデル 選択する
新しいセマンティック モデル nycflight13 を選択し、確認 を選んでください。
セマンティック モデルが作成されます。 新しいレポート を選択する
[データ] ペインおよび [視覚化] ペインからフィールドを選択またはドラッグして、レポートキャンバスに移動し、レポートを作成します。
このセクションの先頭に表示されるレポートを作成するには、次の視覚化とデータを使用します。
 積み上げ横棒グラフ:
積み上げ横棒グラフ:- Y 軸: carrier_name
- X 軸: flight。 集計に [カウント] を選択します
- 凡例: origin_name
- 積み上げ横棒グラフ:
- Y 軸: dest_name
- X 軸: flight。 集計のために を選択し、 をカウントします
- 凡例: origin_name
 次のスライサー:
次のスライサー:- フィールド: _pred_class
- 次のスライサー:
- フィールド: _pred_late