レイクハウスのエンドツーエンド シナリオ: 概要とアーキテクチャ
Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンスまでのすべてをカバーする企業向けのオールインワン分析ソリューションです。 データ レイク、Data Engineering、データ統合などのサービスが、包括的なスイートとしてすべて 1 か所で提供されます。 詳細については、「Microsoft Fabric とは?」を参照してください。
このチュートリアルでは、データの取得からデータの消費までのエンドツーエンドのシナリオを説明します。 これは、さまざまなエクスペリエンスとそれらの統合方法、このプラットフォームでの作業に伴うプロフェッショナルおよび市民開発者のエクスペリエンスなど、Fabric の基本的な理解を構築するのに役立ちます。 このチュートリアルは、参照アーキテクチャ、機能の完全な一覧、または特定のベスト プラクティスの推奨事項を意図したものではありません。
レイクハウスのエンド ツー エンドのシナリオ
従来、組織はトランザクションおよび構造化データ分析のニーズに対応するため、最新のデータ ウェアハウスを構築してきました。 また、ビッグデータ (半/非構造化) データ分析のニーズに対応するデータ レイクハウスもあります。 これら 2 つのシステムは並行して実行され、サイロ化、データの重複が発生し、総所有コストが増加しました。
データ ストアの統合と Delta Lake 形式での標準化を備えた Fabric により、サイロを排除し、データの重複を取り除き、総所有コストを大幅に削減できます。
Fabric が提供する柔軟性を利用して、レイクハウス アーキテクチャまたはデータ ウェアハウス アーキテクチャを実装したり、それらを組み合わせてシンプルな実装で両方の長所を最大限に活用したりできます。 このチュートリアルでは、小売組織を例として、そのレイクハウスを最初から最後まで構築します。 メダリオン アーキテクチャを使用しており、ブロンズ レイヤーには生データが含まれ、シルバー レイヤーには検証および重複除去されたデータが含まれ、ゴールド レイヤーには高度に精製されたデータが含まれます。 あらゆる業界のあらゆる組織に対して、同じアプローチを採用してレイクハウスを実装できます。
このチュートリアルでは、小売ドメインの架空の Wide World Importers 社の開発者が次の手順を実行する方法について説明します。
Power BI アカウントにサインインし、無料のMicrosoft Fabric 試用版にサインアップします。 Power BI ライセンスをお持ちでない場合は、Fabric 無料ライセンスにサインアップし、Fabric 試用版を開始できます。
組織向けにエンドツーエンドのレイクハウスを構築して実装します。
- Fabric ワークスペースを作成します。
- レイクハウスを作成します。
- データの取り込み、データの変換、レイクハウスへの読み込みを行います。 また、レイクハウス モードと SQL 分析エンドポイント モードの間でデータの 1 つのコピーである OneLake を調べることもできます。
- SQL 分析エンドポイントを使用してレイクハウスに接続し、DirectLake を使用して Power BI レポートを作成して、さまざまなディメンションにわたって販売データを分析します。
- 必要に応じて、パイプラインを使用してデータの取り込みと変換のフローを調整およびスケジュールできます。
ワークスペースやその他の項目を削除して、リソースをクリーンアップします。
アーキテクチャ
次の図は、レイクハウスのエンドツーエンドのアーキテクチャを示しています。 関連するコンポーネントを次の一覧に示します。
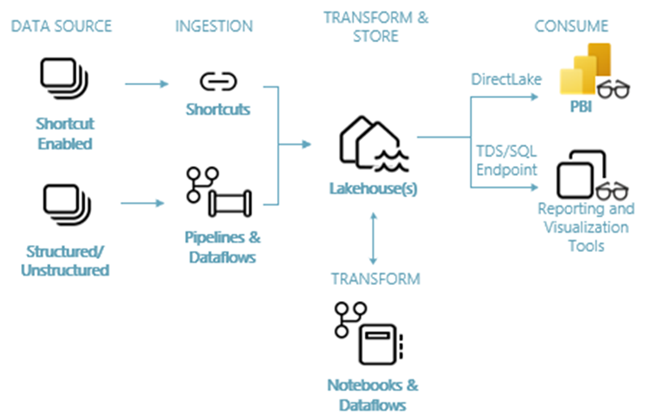
データ ソース: Fabric を使用すると、Azure Data Services だけでなく、他のクラウドベースのプラットフォームやオンプレミスのデータ ソースにすばやく簡単に接続でき、データの取り込みが効率化されます。
インジェスト: 200 を超えるネイティブ コネクタを使用して、組織に関する分析情報を迅速に構築できます。 これらのコネクタは Fabric パイプラインに統合されており、データフローによるユーザー フレンドリーなドラッグ アンド ドロップ データ変換を利用します。 さらに、Fabric のショートカット機能を使用すると、既存のデータをコピーまたは移動せずに接続できます。
変換と保存: Fabric は Delta Lake 形式を標準化しています。 これは、すべての Fabric エンジンが、データを複製することなく、OneLake に保存されている同じデータセットにアクセスして操作できることを意味します。 このストレージ システムは、組織の要件に応じて、メダリオン アーキテクチャまたはデータ メッシュを使用してレイクハウスを構築する柔軟性を提供します。 データ変換にはローコード エクスペリエンスとノーコード エクスペリエンスを選択でき、コードファースト エクスペリエンスではパイプライン/データフローまたはノートブック/Spark のいずれかを利用できます。
使用: Power BI では、レポートと視覚化のために Lakehouse のデータを使用できます。 各 Lakehouse には SQL 分析エンドポイントと呼ばれる TDS エンドポイントが組み込まれており、他のレポート ツールから簡単に接続して Lakehouse テーブル内のデータをクエリできます。 SQL 分析エンドポイントにより、ユーザーは SQL 接続機能を利用できます。
サンプル データセット
このチュートリアルでは、Wide World Importers (WWI) サンプル データベースを使用します。これは、次のチュートリアルでレイクハウスにインポートします。 レイクハウスのエンドツーエンドのシナリオでは、Fabric プラットフォームのスケールとパフォーマンス機能を調査するのに十分なデータを生成しました。
Wide World Importers (WWI) は、サンフランシスコ湾岸地域でノベルティ商品の輸入と販売を行っている卸売業者です。 卸売業者である WWI の顧客の多くは、個人に再販する企業です。 WWI は、専門店、スーパーマーケット、コンピューティング ストア、観光地の小売店、一部の個人など、米国全域の小売顧客に販売しています。 また、WWI に代わって製品の販売促進を行う代理店のネットワークを介して他の卸売業者にも販売しています。 会社のプロファイルと事業の詳細については、「Microsoft SQL 用 Wide World Importers サンプル データベース」を参照してください。
一般に、データはトランザクション システムまたは基幹業務アプリケーションからレイクハウスに持ち込まれます。 ただし、このチュートリアルではわかりやすくするために、WWI によって提供されるディメンション モデルを初期データ ソースとして使用します。 これをソースとして使用して、データをレイクハウスに取り込み、メダリオン アーキテクチャのさまざまな段階 (ブロンズ、シルバー、ゴールド) を通じて変換します。
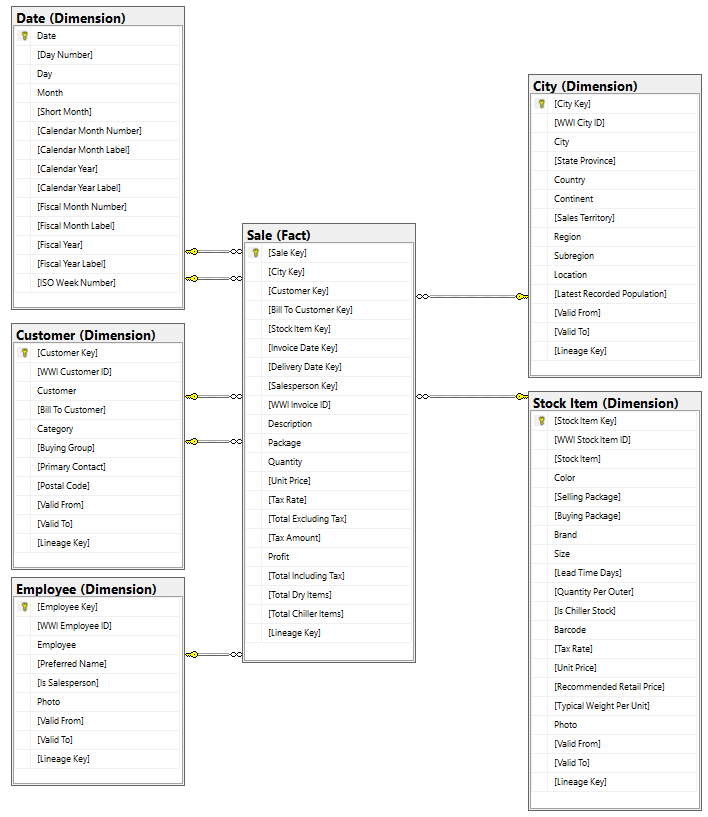
データ モデル
WWI ディメンション モデルには多数の ファクト テーブル が含まれていますが、このチュートリアルでは、Sale ファクト テーブルとその相関ディメンションを使用します。 次の例は、WWI データ モデルを示しています。
データと変換フロー
前述したように、このエンドツーエンドのレイクハウスを構築するために、 Wide World Importers (WWI) のサンプル データからのサンプル データを使用しています。 この実装では、すべてのテーブルのサンプル データが Parquet ファイル形式で Azure データ ストレージ アカウントに保存されます。 ただし、現実のシナリオでは、データは通常、さまざまなソースからさまざまな形式で生成されます。
次の図は、ソース、宛先、およびデータ変換を示しています。
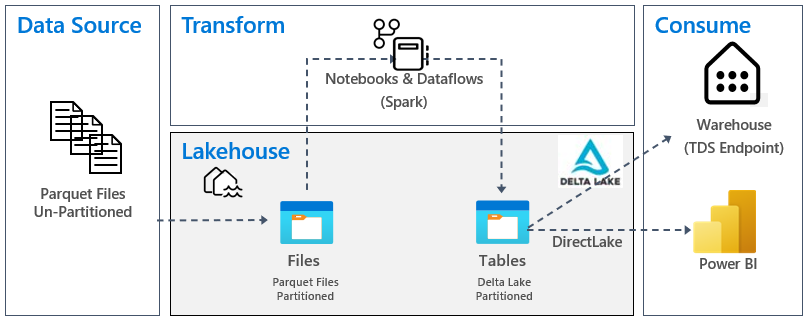
データ ソース: ソース データは Parquet ファイル形式であり、パーティション化されていない構造になっています。 テーブルごとにフォルダーに保存されます。 このチュートリアルでは、完全な履歴データまたはワンタイム データをレイクハウスに取り込むパイプラインを設定します。
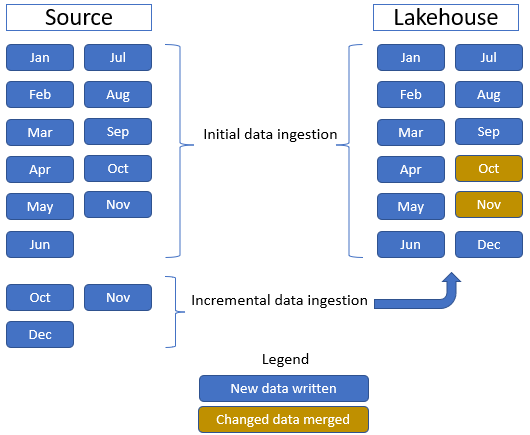
このチュートリアルでは、Sale ファクト テーブルを使用します。このテーブルには、11 か月分の履歴データを含む 1 つの親フォルダー (各月に 1 つのサブフォルダー) と、3 か月分の増分データを含む別のフォルダー (各月に 1 つのサブフォルダー) があります。 最初のデータ インジェスト中に、11 か月分のデータがレイクハウス テーブルに取り込まれます。 ただし、増分データが到着すると、10 月と 11 月の更新されたデータと 12 月の新しいデータが含まれます。10 月と 11 月のデータは既存のデータとマージされ、次の図に示すように、12 月の新しいデータがレイクハウス テーブルに書き込まれます。
レイクハウス: このチュートリアルでは、レイクハウスを作成し、レイクハウスのファイル セクションにデータを取り込み、レイクハウスのテーブル セクションにデルタ レイク テーブルを作成します。
変換: データの準備と変換には、2 つの異なるアプローチがあります。 コードファーストのエクスペリエンスを好むユーザーには Notebooks/Spark の使用法を示し、ローコードまたはノーコードのエクスペリエンスを好むユーザーにはパイプライン/データフローの使用法を示します。
使用: データ使用量を示すために、Power BI の DirectLake 機能を使用してレポート、ダッシュボードを作成し、レイクハウスからデータを直接クエリする方法を確認します。 さらに、TDS/SQL 分析エンドポイントを使用して、サードパーティのレポート ツールでデータを利用できるようにする方法を示します。 このエンドポイントを使用すると、ウェアハウスに接続し、分析用の SQL クエリを実行できます。