メダリオン レイクハウス アーキテクチャとは
このメダリオン アーキテクチャでは、レイクハウスの格納データの品質を示す一連のデータ レイヤーについて説明します。 Azure Databricks では、エンタープライズ データ製品の単一の信頼できるソースを構築するために、多層アプローチを採用することをお勧めします。
このアーキテクチャでは、データが複数の検証と変換のレイヤーを経て効率的な分析に最適なレイアウトで格納されるため、原子性、一貫性、分離性、持続性が保証されます。 ブロンズ (未加工)、シルバー (検証済み)、ゴールド (エンリッチ済み) という用語は、これらの各レイヤーのデータ品質を表しています。
データ設計パターンとしての Medallion アーキテクチャ
medallion アーキテクチャは、データを論理的に整理するために使用されるデータ設計パターンです。 その目標は、アーキテクチャの各レイヤー (ブロンズ ⇒ Silver ⇒ Gold レイヤー テーブルから) を流れるデータの構造と品質を段階的かつ段階的に向上することです。 Medallion アーキテクチャは、 マルチホップ アーキテクチャとも呼ばれます。
これらのレイヤーを通じてデータを進めることで、組織はデータの品質と信頼性を段階的に向上させ、ビジネス インテリジェンスや機械学習アプリケーションに適しています。
medallion アーキテクチャに従うことをお勧めしますが、要件ではありません。
| 質問 | 銅 | シルバー | ゴールド |
|---|---|---|---|
| このレイヤーでは何が起こりますか? | 生データ インジェスト | データのクリーニングと検証 | ディメンションモデリングと集計 |
| 目的のユーザーは誰ですか? | - データ エンジニア - データ操作 - コンプライアンスチームと監査チーム |
- データ エンジニア - データ アナリスト (詳細な分析に必要な詳細情報を保持する、より洗練されたデータセットには Silver レイヤーを使用します) - データ サイエンティスト (モデルの構築と高度な分析の実行) |
- ビジネス アナリストと BI 開発者 - データ サイエンティストと機械学習 (ML) エンジニア - 役員と意思決定者 - 運用チーム |
medallion アーキテクチャの例
このメダリオン アーキテクチャの例は、ビジネス オペレーション チームが使用するブロンズ、シルバー、ゴールドのレイヤーを示しています。 各レイヤーは、ops カタログの異なるスキーマに格納されます。
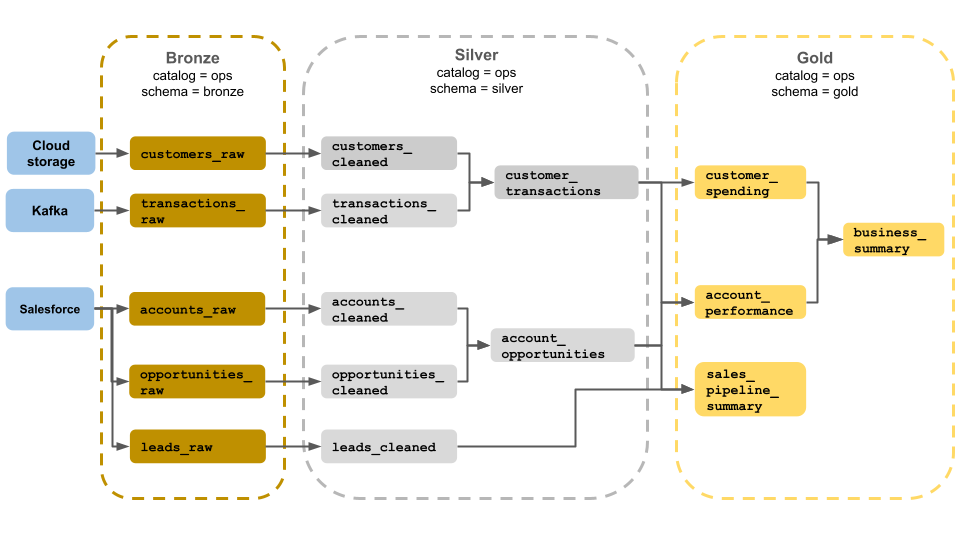
- ブロンズ レイヤー (
ops.bronze): クラウド ストレージ、Kafka、Salesforce から生データを取り込みます。 ここでは、データのクリーンアップや検証は実行されません。 - シルバー レイヤー (
ops.silver): このレイヤーでは、データのクリーンアップと検証が実行されます。- 顧客とトランザクションに関するデータは、null を削除し、無効なレコードを検疫することで消去されます。 これらのデータセットは、
customer_transactionsと呼ばれる新しいデータセットに結合されます。 データ サイエンティストは、このデータセットを予測分析に使用できます。 - 同様に、Salesforce の取引先企業と営業案件のデータセットは、アカウント情報で強化された
account_opportunitiesを作成するために結合されます。 leads_rawデータは、leads_cleanedと呼ばれるデータセットでクリーンアップされます。
- 顧客とトランザクションに関するデータは、null を削除し、無効なレコードを検疫することで消去されます。 これらのデータセットは、
- ゴールド レイヤー (
ops.gold): このレイヤーはビジネス ユーザー向けに設計されています。 含まれるデータセットは、シルバーとゴールドよりも少なくなります。customer_spending: 各顧客の平均支出と合計支出。account_performance: 各アカウントの毎日のパフォーマンス。sales_pipeline_summary: エンドツーエンドの販売パイプラインに関する情報。business_summary:エグゼクティブ スタッフの情報を集約しました。
ブロンズ レイヤーに生データを取り込む
ブロンズ レイヤーには、未加工の未検証のデータが含まれています。 ブロンズ レイヤーに取り込まれるデータには、通常、次の特性があります。
- データ ソースの生の状態を元の形式で格納および維持します。
- 増分的に追加され、時間の経過とともに増加します。
- アナリストやデータ サイエンティストによるアクセスではなく、シルバー テーブルのデータを強化するワークロードによる使用を目的としています。
- データの忠実性を維持しながら、信頼の単一のソースとして機能します。
- すべての履歴データを保持することで、再処理と監査を有効にします。
- クラウド オブジェクト ストレージ (S3、GCS、ADLS など)、メッセージ バス (Kafka、Kinesis など)、フェデレーション システム (Lakehouse フェデレーションなど) など、ソースからのストリーミング トランザクションとバッチ トランザクションを任意に組み合わせて使用できます。
データのクリーンアップまたは検証を制限する
最小データ検証は、ブロンズ レイヤーで実行されます。 Azure Databricks では、削除されたデータを確実に防ぎ、予期しないスキーマ変更から保護するために、ほとんどのフィールドを文字列、VARIANT、またはバイナリとして格納することをお勧めします。 メタデータ列 (データの実績やソースなど) が追加される場合があります (たとえば、 _metadata.file_name )。
シルバー レイヤーのデータを検証して重複を除去する
データのクリーンアップと検証は、シルバー レイヤーで実行されます。
ブロンズ レイヤーからシルバー テーブルを作成する
シルバー レイヤーを構築するには、1 つ以上のブロンズ テーブルまたはシルバー テーブルからデータを読み取り、シルバー テーブルにデータを書き込みます。
Azure Databricks では、インジェストから直接 Silver テーブルに書き込むのは推奨されません。 インジェストから直接書き込む場合は、スキーマの変更やデータ ソースのレコードの破損によるエラーが発生します。 すべてのソースが追加専用であると仮定して、ブロンズからのほとんどの読み取りをストリーミング読み取りとして構成します。 バッチ読み取りは、小さなデータセット (たとえば、小さなディメンション テーブル) 用に予約する必要があります。
シルバー レイヤーは、データの検証済み、クリーニング済み、エンリッチされたバージョンを表します。 シルバー レイヤー:
- 常に、各レコードの少なくとも 1 つの検証済みの非集計表現を含める必要があります。 集約表現が多くのダウンストリーム ワークロードを推進する場合、それらの表現はシルバー レイヤー内にある可能性がありますが、通常はゴールド レイヤーにあります。
- データ クレンジング、重複除去、正規化を実行する場所です。
- エラーと不整合を修正することで、データ品質を向上させます。
- ダウンストリーム処理のために、データをより消費型の形式に構造化します。
データ品質を適用する
シルバー テーブルでは、次の操作が実行されます。
- スキーマの適用
- null 値と欠損値の処理
- データ重複除去
- 順序が整え切れ、到着が遅れるデータの問題の解決
- データ品質チェックと適用
- スキーマの展開
- 型キャスト
- 結合
データのモデリングを開始する
入れ子になったデータまたは半構造化データを表す方法を選択するなど、シルバー レイヤーでデータ モデリングの実行を開始するのが一般的です。
- データ型
VARIANT使用します。 JSON文字列を使用します。- 構造体、マップ、配列を作成します。
- スキーマをフラット化するか、データを複数のテーブルに正規化します。
ゴールド レイヤーによる分析強化
ゴールド レイヤーは、ダウンストリームの分析、ダッシュボード、ML、アプリケーションを駆動するデータの高度に洗練されたビューを表します。 ゴールド レイヤー データは、多くの場合、特定の期間または地理的リージョンに対して高度に集計され、フィルター処理されます。 これには、ビジネス機能とニーズにマップされる意味的に意味のあるデータセットが含まれています。
ゴールド レイヤー:
- 分析とレポート用に調整された集計データで構成されます。
- ビジネス ロジックと要件に合わせて調整します。
- クエリとダッシュボードのパフォーマンスに最適化されています。
ビジネス ロジックと要件に合わせる
ゴールド レイヤーでは、リレーションシップを確立し、メジャーを定義することで、ディメンション モデルを使用してレポートと分析のデータをモデル化します。 ゴールドのデータにアクセスできるアナリストは、ドメイン固有のデータを見つけて質問に回答できる必要があります。
ゴールド レイヤーはビジネス ドメインをモデル化するため、人事、財務、IT など、さまざまなビジネス ニーズを満たすために複数のゴールド レイヤーを作成する顧客もいます。
分析とレポート用に調整された集計を作成する
組織では、多くの場合、平均、カウント、最大値、最小値などのメジャーの集計関数を作成する必要があります。 たとえば、ビジネスで週次売上合計に関する質問に回答する必要がある場合は、このデータを事前に集計する weekly_sales という具体化されたビューを作成して、アナリストや他のユーザーが頻繁に使用する具体化されたビューを再作成する必要がないようにすることができます。
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
クエリとダッシュボードのパフォーマンスを最適化する
パフォーマンスのためにゴールド レイヤー テーブルを最適化することをお勧めします。これらのデータセットは頻繁に照会されるためです。 通常、大量の履歴データはスライバー 層でアクセスされ、ゴールド レイヤーでは具体化されません。
データ インジェストの頻度を調整してコストを制御する
データを取り込む頻度を決定してコストを制御します。
| データ インジェストの頻度 | コスト | Latency | 宣言型の例 | 手続き型の例 |
|---|---|---|---|---|
| 継続的な増分インジェスト | より高い | より低い | - spark.readStream を使用してクラウド ストレージまたはメッセージ バスから取り込むストリーミング テーブル。- このストリーミング テーブルを更新する Delta Live Tables パイプラインは、継続的に実行されます。 - ノートブックの spark.readStream を使用してクラウド ストレージまたはメッセージ バスから Delta テーブルに取り込む構造化ストリーミング コード。- ノートブックは、継続的ジョブ トリガーを使用して Azure Databricks ジョブを使用して調整されます。 |
|
| トリガーされた増分インジェスト | より低い | より高い | - spark.readStreamを使用してクラウド ストレージまたはメッセージ バスから取り込むストリーミング テーブル。- このストリーミング テーブルを更新するパイプラインは、ジョブのスケジュールされたトリガーまたはファイル到着トリガーによってトリガーされます。 - Trigger.Available トリガーを持つノートブック内の構造化ストリーミング コード。- このノートブックは、ジョブのスケジュールされたトリガーまたはファイル到着トリガーによってトリガーされます。 |
|
| 手動インジェストによるバッチ インジェスト | より低い | 実行頻度が低いため、最も高くなります。 | - spark.readを使用したクラウド ストレージからのストリーミング テーブルの取り込み。- 構造化ストリーミングを使用しません。 代わりに、パーティションの上書きなどのプリミティブを使用して、パーティション全体を一度に更新します。 - 増分処理を設定するには、広範なアップストリーム アーキテクチャが必要です。これにより、構造化ストリーミングの読み取り/書き込みに似たコストが発生します。 - また、 datetime フィールドによってソース データをパーティション分割し、そのパーティションのすべてのレコードをターゲットに処理する必要があります。 |