レイクハウス チュートリアル: レイクハウスでデータを準備して変換する
このチュートリアルでは、Spark ランタイムでノートブックを使用して、Lakehouse 内の生データを変換および準備します。
前提条件
データを含む Lakehouse がない場合は、次の手順を実行する必要があります。
データを準備する
前のチュートリアルの手順で、生データがソースからレイクハウスの [ファイル] セクションに取り込まれました。 これで、そのデータを変換し、デルタ テーブルを作成するための準備を行うことができます。
Lakehouse Tutorial Source Code フォルダーからノートブックをダウンロードします。
ワークスペースから、
このコンピューターから ノートブック をインポートを選択します。 ランディング ページの上部にある [新規] セクションから [ノートブックのインポート] を選択します。
画面の右側に表示される [インポート状態] ウィンドウから [アップロード] を選択します。
このセクションの最初のステップでダウンロードしたすべてのノートブックを選択します。
![ダウンロードしたノートブックを見つける場所と [開く] ボタンを示すスクリーンショット。](media/tutorial-lakehouse-data-preparation/select-notebooks-open.png)
[開く] を選択します。 インポートの状態を示す通知がブラウザー ウィンドウの右上隅に表示されます。
インポートが成功したら、ワークスペースのアイテム ビューに移動し、新しくインポートされたノートブックを確認します。 [wwilakehouse] レイクハウスを選択して開きます。
wwilakehouse レイクハウスが開いたら、上部のナビゲーション メニューから [ノートブックを開く]>[既存のノートブック] を選択します。
既存のノートブックの一覧から、[01 - Delta テーブルの作成] ノートブックを選択し、[開く] を選択します。
レイクハウス [エクスプローラー] で開いているノートブックで、ノートブックが開いているレイクハウスに既にリンクされていることがわかります。
Note
Fabric には、最適化された Delta Lake ファイルを書き込むための V オーダー機能が用意されています。 多くの場合、V オーダーでは、最適化されていない Delta Lake ファイルと比較して、圧縮は 3 から 4 倍、パフォーマンスは最大 10 倍向上します。 Fabric の Spark は、128MB (既定値) のサイズのファイルを生成しながら、パーティションを動的に最適化します。 目標とするファイル サイズは、ワークロードの要件に応じて構成で変更することが可能です。
書き込みの最適化機能を備えた Apache Spark エンジンは、書き込まれるファイルの数を減らし、書き込まれるデータの個々のファイル サイズを大きくしようとします。
Lakehouse の [テーブル] セクションでデータをデルタ レイク テーブルとして書き込む前に、2 つの Fabric 機能 (V オーダー と 書き込みの最適化) を使用して、データ書き込みを最適化し、読み取りパフォーマンスを向上させます。 セッションでこれらの機能を有効にするには、ノートブックの最初のセルにこれらの構成を設定します。
ノートブックを起動し、すべてのセルを順番に実行するには、上部のリボン ([ホーム] の下) で [すべて実行] を選択します。 または、特定のセルからのコードのみを実行するには、ホバーしたときにセルの左側に表示される [実行] アイコンを選択するか、コントロールがセル内にあるときにキーボードの Shift + Enter キーを押します。
![コード セルと実行 [アイコン] を含む、Spark セッション構成画面のスクリーンショット。](media/tutorial-lakehouse-data-preparation/spark-session-run-execution.png)
セルを実行するときに、基になる Spark プールまたはクラスターの詳細を指定する必要はありませんでした。これは、Fabric がライブ プールを通じて提供するためです。 すべての Fabric ワークスペースには、ライブ プールと呼ばれる既定の Spark プールが付属しています。 つまり、ノートブックを作成するときに、Spark 構成やクラスターの詳細の指定について心配する必要はありません。 最初のノートブック コマンドを実行すると、ライブ プールが起動し、数秒で実行されます。 そして、Spark セッションが確立され、コードの実行が開始されます。 Spark セッションがアクティブな間、このノートブックでは、その後のコードの実行はほぼ瞬時に行われます。
次に、レイクハウスの [ファイル] セクションから生データを読み取り、変換の一環として日付要素ごとに列を追加します。 最後に、Spark API のパーティションを使用してデータを分割してから、新しく作成されたデータ要素の列 (Year と Quarter) に基づいてデルタ テーブルとして書き込みます。
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)ファクト テーブルが読み込まれると、残りのディメンションのデータの読み込みに進むことができます。 次のセルは、パラメータとして渡されるテーブル名ごとに、レイクハウスの [ファイル] セクションから生データを読み取る関数を作成します。 次に、ディメンション テーブルのリストを作成します。 最後に、テーブルのリストをループ処理し、入力パラメータから読み取られたテーブル名ごとにデルタ テーブルを作成します。 この例では、
Photoという名前の列は使用されていないため、スクリプトによって削除されることに注意してください。from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)作成されたテーブルを検証するには、wwilakehouse Lakehouse を右クリックして [更新] を選択します。 テーブルが表示されます。
ワークスペースのアイテム ビューに再度移動し、wwilakehouse レイクハウスを選択して開きます。
次に、2 つ目のノートブックを開きます。 レイクハウス ビューで、リボンから [ノートブックを開く]>[既存のノートブック] の順に選択します。
既存のノートブックの一覧から、[02 - データ変換 - ビジネス] ノートブックを選択して開きます。
![[既存のノートブックを開く] メニューのスクリーンショット。ノートブックを選択する場所を示しています。](media/tutorial-lakehouse-data-preparation/existing-second-notebook.png)
レイクハウス [エクスプローラー] で開いているノートブックで、ノートブックが開いているレイクハウスに既にリンクされていることがわかります。
組織には、Scala/Python を使用するデータ エンジニアと、SQL (Spark SQL または T-SQL) を使用する他のデータ エンジニアがいて、全員がすべて同じデータのコピーで作業している場合があります。 Fabric を使用すると、さまざまな経験や好みを持つこれらの異なるグループが作業や共同作業を行うことができます。 2 つの異なるアプローチにより、ビジネス集計が変換して生成されます。 パフォーマンスを損なうことなく、自分に合ったものを選択したり、好みに基づいてこれらのアプローチを組み合わせたりすることができます。
アプローチ #1 - PySpark を使用して、ビジネス集計を生成するためのデータを結合および集計します。 このアプローチは、プログラミング (Python または PySpark) のバックグラウンドを持つユーザーに推奨されます。
アプローチ #2 - Spark SQL を使用して、ビジネス集計を生成するためのデータを結合および集計します。 この方法は、SQL のバックグラウンドを持ち、Spark に移行しているユーザーに推奨されます。
アプローチ #1 (sale_by_date_city) - PySpark を使用して、ビジネス集計を生成するためのデータを結合および集計します。 次のコードでは、それぞれ既存のデルタ テーブルを参照する 3 つの異なる Spark データフレームを作成します。 次に、データフレームを使用してこれらのテーブルを結合し、グループ化を実行して集計を生成し、いくつかの列の名前を変更し、最後にデータを保持するために Lakehouse の [テーブル] セクションにデルタ テーブルとして書き込みます。
このセルでは、それぞれ既存のデルタ テーブルを参照する 3 つの異なる Spark データフレームを作成します。
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")同じセルに次のコードを追加し、前に作成したデータフレームを使用してこれらのテーブルを結合します。 グループ化して集計を生成し、いくつかの列の名前を変更し、最後にレイクハウスの [テーブル] セクションに Delta テーブルとして書き込みます。
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")アプローチ #2 (sale_by_date_employee) - Spark SQL を使用して、ビジネス集計を生成するためのデータを結合および集計します。 次のコードでは、3 つのテーブルを結合して一時的な Spark ビューを作成し、グループ化を実行して集計を生成し、いくつかの列の名前を変更します。 最後に、一時的な Spark ビューから読み取り、最後にデータを保持するために Lakehouse の [テーブル] セクションにデルタ テーブルとして書き込みます。
このセルでは、3 つのテーブルを結合して一時的な Spark ビューを作成し、グループ化を実行して集計を生成し、いくつかの列の名前を変更します。
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCこのセルでは、前のセルで作成した一時的な Spark ビューから読み取り、最後に Lakehouse の [テーブル] セクションにデルタ テーブルとして書き込みます。
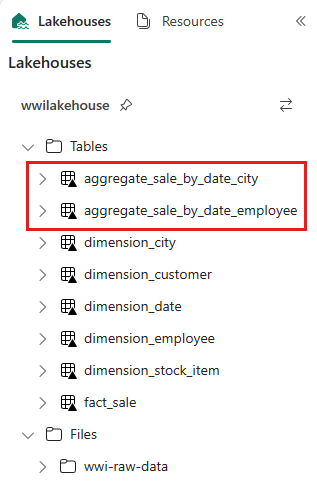
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")作成されたテーブルを検証するには、wwilakehouse Lakehouse を右クリックして [更新] を選択します。 集計テーブルが表示されます。
2 つのうち、どちらのアプローチでも同様の結果が得られます。 新しいテクノロジを学習したり、パフォーマンスを妥協したりする必要性を最小限に抑えるために、お客さまの背景や希望に最も合ったアプローチを選択してください。
お気づきのように、データをデルタ レイク ファイルとして書き込んでいます。 Fabric の自動テーブル検出と登録機能を取得して、メタストアに登録します。 SQL で使用するテーブルを作成するために CREATE TABLE ステートメントを明示的に呼び出す必要はありません。